linformer pytorch
version
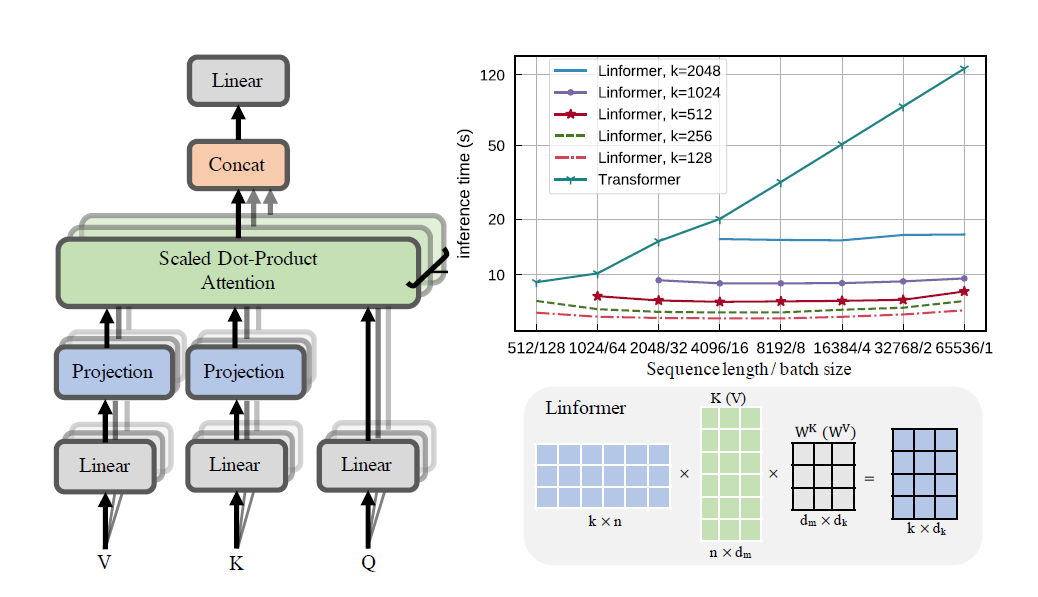
Eine praktische Umsetzung des Linformer-Papiers. Dabei handelt es sich um Aufmerksamkeit mit nur linearer Komplexität in n, wodurch auf moderner Hardware sehr lange Sequenzlängen (1 mil+) berücksichtigt werden können.
Bei diesem Repo handelt es sich um einen Transformer im „Attention Is All You Need“-Stil, komplett mit einem Encoder- und Decodermodul. Das Neue dabei ist, dass man nun die Aufmerksamkeitsrichtungen linear gestalten kann. Sehen Sie sich unten an, wie Sie es verwenden.
Dies wird derzeit auf Wikitext-2 validiert. Derzeit ist die Leistung auf dem gleichen Niveau wie andere Mechanismen mit geringer Aufmerksamkeit, wie zum Beispiel der Sinkhorn Transformer, aber die besten Hyperparameter müssen noch gefunden werden.
Auch eine Visualisierung der Köpfe ist möglich. Weitere Informationen finden Sie im Abschnitt „Visualisierung“ unten.
Ich bin nicht der Autor des Artikels.
1,23 Mio. Token
pip install linformer-pytorch
Alternativ,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Linformer-Sprachmodell
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer-Selbstaufmerksamkeit, Stapel von MHAttention und FeedForward s
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Linformer Multihead Aufmerksamkeit
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)Der lineare Aufmerksamkeitskopf, die Neuheit des Papiers
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)Ein Encoder-/Decodermodul.
Hinweis: Für kausale Sequenzen kann man im LinformerLM das Flag causal=True aktivieren, um die obere rechte Seite in der (n,k) -Aufmerksamkeitsmatrix auszublenden.
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) Eine einfache Möglichkeit, die E und F Matrizen abzurufen, kann durch Aufrufen der Funktion get_EF erfolgen. Als Beispiel für ein n von 1000 und ein k von 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) Mit dem method kann man die Methode festlegen, mit der der Linformer das Downsampling durchführt. Derzeit werden drei Methoden unterstützt:
learnable : Diese Downsampling-Methode erstellt ein lernbares n,k nn.Linear Modul.convolution : Diese Downsampling-Methode erstellt eine 1D-Faltung mit Schrittlänge und Kernelgröße n/k .no_params : Dadurch wird eine feste n,k -Matrix mit Werten von N(0,1/k) erstellt.In Zukunft werde ich möglicherweise Pooling oder etwas anderes einbeziehen. Aber im Moment sind das die Optionen, die es gibt.
Als Versuch, Speichereinsparungen weiter voranzutreiben, wurde das Konzept der Prüfpunktebenen eingeführt. Die aktuellen drei Prüfpunktebenen sind C0 , C1 und C2 . Wenn man die Checkpoint-Stufen erhöht, opfert man Geschwindigkeit zugunsten von Speichereinsparungen. Das heißt, Checkpoint-Level C0 ist am schnellsten, nimmt aber den meisten Platz auf der GPU ein, während C2 am langsamsten ist, aber am wenigsten Platz auf der GPU einnimmt. Die Details jeder Kontrollpunktebene lauten wie folgt:
C0 : Kein Checkpointing. Die Modelle laufen, während alle Aufmerksamkeitsköpfe und FF-Schichten im GPU-Speicher verbleiben.C1 : Überprüfen Sie jede MultiHead-Aufmerksamkeit sowie jede FF-Ebene. Dadurch sollte eine zunehmende depth nur minimale Auswirkungen auf das Gedächtnis haben.C2 : Zusammen mit den Optimierungen auf der C1 -Ebene einen Checkpoint für jeden Kopf in jeder MultiHead Attention-Schicht festlegen. Dadurch sollte eine Erhöhung nhead weniger Auswirkungen auf das Gedächtnis haben. Das Zusammenfügen der Köpfe mit torch.cat beansprucht jedoch immer noch viel Speicher, und dies wird hoffentlich in Zukunft optimiert.Leistungsdetails sind noch nicht bekannt, aber die Option besteht für Benutzer, die es ausprobieren möchten.
Ein weiterer Versuch, in der Arbeit Speicher zu sparen, bestand darin, die gemeinsame Nutzung von Parametern zwischen den Projektionen einzuführen. Dies wird in Abschnitt 4 des Papiers erwähnt; Insbesondere wurden von den Autoren vier verschiedene Arten der Parameterfreigabe diskutiert, die alle in diesem Repo implementiert wurden. Die erste Option beansprucht den meisten Speicher, jede weitere Option reduziert den notwendigen Speicherbedarf.
none : Dies ist keine Parameterfreigabe. Für jeden Kopf und für jede Schicht wird für jeden Kopf auf jeder Schicht eine neue E und eine neue F -Matrix berechnet.headwise : Jede Schicht hat eine eindeutige E und F -Matrix. Alle Köpfe in der Ebene teilen sich diese Matrix.kv : Jede Schicht hat eine eindeutige Projektionsmatrix P und E = F = P für jede Schicht. Alle Köpfe teilen sich diese Projektionsmatrix Playerwise : Es gibt eine Projektionsmatrix P , und jeder Kopf in jeder Schicht verwendet E = F = P Wie in der Arbeit begonnen, bedeutet dies, dass es für ein Netzwerk mit 12 Schichten und 12 Köpfen 288 , 24 , 12 bzw. 1 unterschiedliche Projektionsmatrizen gäbe.
Beachten Sie, dass mit der Option k_reduce_by_layer die Option layerwise nicht wirksam ist, da sie die Dimension von k für die erste Ebene verwendet. Wenn der Wert von k_reduce_by_layer größer als 0 ist, sollte daher höchstwahrscheinlich nicht die Option layerwise Freigabe verwendet werden.
Beachten Sie außerdem, dass diese Parameterfreigabe laut den Autoren in Abbildung 3 das Endergebnis nicht wirklich stark beeinflusst. Daher ist es vielleicht am besten, bei allem bei layerwise Freigabe zu bleiben, aber die Benutzer haben auch die Möglichkeit, es auszuprobieren.
Ein kleines Problem bei der aktuellen Implementierung des Linformers besteht darin, dass Ihre Sequenzlänge mit dem input_size Flag des Modells übereinstimmen muss. Der Padder füllt die Eingabegröße auf, sodass der Tensor in das Netzwerk eingespeist werden kann. Ein Beispiel:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 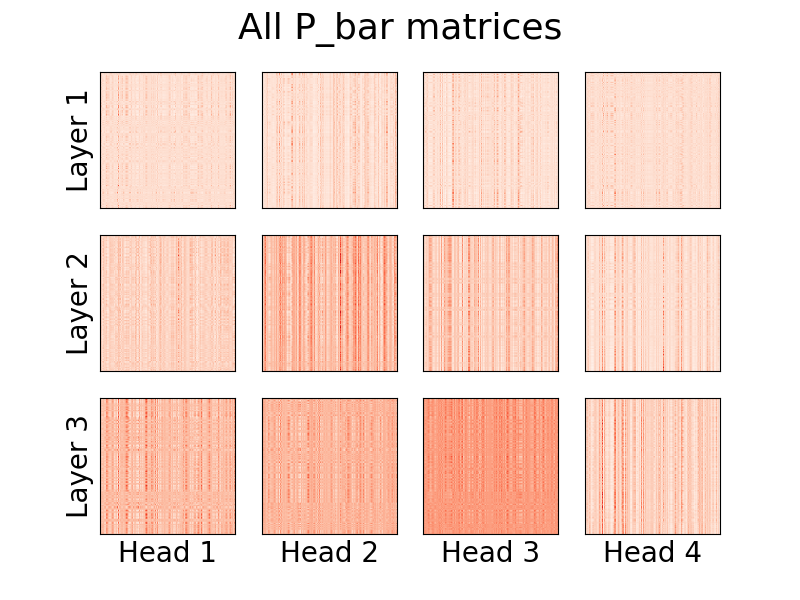
Ab Version 0.8.0 kann man nun die Aufmerksamkeitsköpfe des Linformers visualisieren! Um dies in Aktion zu sehen, importieren Sie einfach die Visualizer Klasse und führen Sie die Funktion plot_all_heads() aus, um ein Bild aller Aufmerksamkeitsköpfe auf jeder Ebene mit der Größe (n, k) anzuzeigen. Stellen Sie sicher, dass Sie im Vorwärtsdurchlauf visualize=True angeben, da dadurch die P_bar -Matrix gespeichert wird, sodass die Visualizer Klasse den Kopf ordnungsgemäß visualisieren kann.
Ein funktionierendes Beispiel des Codes finden Sie unten, und derselbe Code ist in ./examples/example_vis.py zu finden:
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)Eine ausführliche Erklärung, was diese Köpfe bedeuten, finden Sie in #15.
Ähnlich wie beim Reformer werde ich versuchen, ein Encoder/Decoder-Modul zu erstellen, damit die Schulung vereinfacht werden kann. Dies funktioniert wie 2 LinformerLM -Klassen. Parameter können für jeden einzeln angepasst werden, wobei der Encoder das Präfix enc_ für alle Hyperparameter und der Decoder das Präfix dec_ auf ähnliche Weise hat. Bisher ist folgendes umgesetzt:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )Ich plane, eine Möglichkeit zu finden, eine Textsequenz dafür zu generieren.
ff_intermediate Tuning Nun kann die Modelldimension in den Zwischenschichten unterschiedlich sein. Diese Änderung gilt für das ff-Modul und nur im Encoder. Wenn nun das Flag ff_intermediate nicht „None“ ist, sehen die Ebenen folgendermaßen aus:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
Im Gegensatz zu
channels -> ff_dim -> channels (For all layers)
input_size bzw. dim_k bearbeitet werden.apex sollten damit funktionieren, in der Praxis wurde es jedoch nicht getestet.input_size , k= dim_k und d= dim_d . LinformerEncDec -Klasse Dies ist das erste Mal, dass ich ein Ergebnis einer Arbeit reproduziere, daher können einige Dinge falsch sein. Wenn Sie ein Problem sehen, eröffnen Sie bitte ein Problem, und ich werde versuchen, daran zu arbeiten.
Vielen Dank an lucidrains, dessen andere Sparse-Attention-Repositories mir bei der Gestaltung dieses Linformer-Repo geholfen haben.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}„Hören Sie aufmerksam zu…“


