intelligent trading bot
1.0.0
___ _ _ _ _ _ _____ _ _ ____ _
|_ _|_ __ | |_ ___| | (_) __ _ ___ _ __ | |_ |_ _| __ __ _ __| (_)_ __ __ _ | __ ) ___ | |_
| || '_ | __/ _ | | |/ _` |/ _ '_ | __| | || '__/ _` |/ _` | | '_ / _` | | _ / _ | __|
| || | | | || __/ | | | (_| | __/ | | | |_ | || | | (_| | (_| | | | | | (_| | | |_) | (_) | |_
|___|_| |_|_____|_|_|_|__, |___|_| |_|__| |_||_| __,_|__,_|_|_| |_|__, | |____/ ___/ __|
|___/ |___/
₿ Ξ ₳ ₮ ✕ ◎ ● Ð Ł Ƀ Ⱥ ∞ ξ ◈ ꜩ ɱ ε ɨ Ɓ Μ Đ ⓩ Ο Ӿ Ɍ ȿ
? Intelligente Handelssignale ? https://t.me/intelligent_trading_signals
Ziel des Projekts ist die Entwicklung eines intelligenten Handelsbots für den automatisierten Handel mit Kryptowährungen unter Verwendung modernster Algorithmen des maschinellen Lernens (ML) und Feature Engineering. Das Projekt bietet die folgenden Hauptfunktionen:
Der Signalisierungsdienst läuft in der Cloud und sendet seine Signale an diesen Telegram-Kanal:
? Intelligente Handelssignale ? https://t.me/intelligent_trading_signals
Jeder kann den Kanal abonnieren, um einen Eindruck von den Signalen zu bekommen, die dieser Bot generiert.
Derzeit ist der Bot mit den folgenden Parametern konfiguriert:
Es gibt Ruhephasen, wenn die Punktzahl unter dem Schwellenwert liegt und keine Benachrichtigungen an den Kanal gesendet werden. Wenn die Punktzahl über dem Schwellenwert liegt, wird jede Minute eine Benachrichtigung gesendet, die wie folgt aussieht:
₿ 24.518 ??? Punktzahl: -0,26
Die erste Zahl ist der letzte Schlusskurs. Der Wert von -0,26 bedeutet, dass der Preis sehr wahrscheinlich unter dem aktuellen Schlusskurs liegt.
Wenn der Score einen im Modell festgelegten Schwellenwert überschreitet, wird ein Kauf- oder Verkaufssignal generiert, was bedeutet, dass es ein guter Zeitpunkt für einen Handel ist. Solche Benachrichtigungen sehen wie folgt aus:
? KAUFEN: ₿ 24.033 Punktestand: +0,34
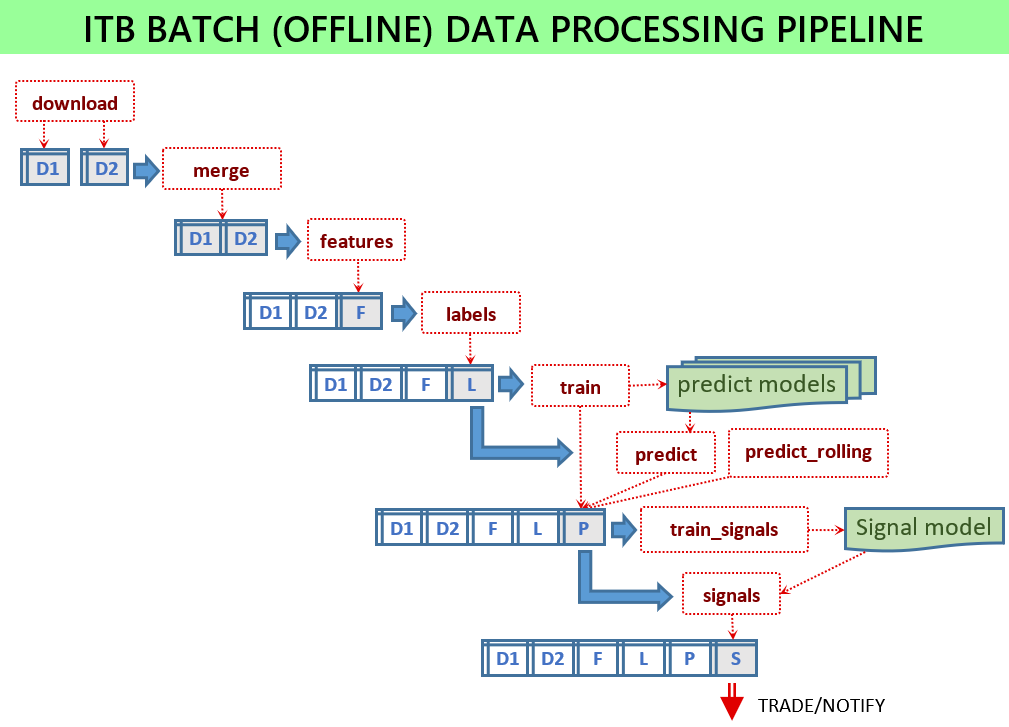
Damit der Signaldienst funktioniert, müssen eine Reihe von ML-Modellen trainiert und die Modelldateien für den Dienst verfügbar sein. Alle Skripte werden im Batch-Modus ausgeführt, indem einige Eingabedaten geladen und einige Ausgabedateien gespeichert werden. Die Batch-Skripte befinden sich im scripts .
Wenn alles konfiguriert ist, müssen folgende Skripte ausgeführt werden:
python -m scripts.download_binance -c config.jsonpython -m scripts.merge -c config.jsonpython -m scripts.features -c config.jsonpython -m scripts.labels -c config.jsonpython -m scripts.train -c config.jsonpython -m scripts.signals -c config.jsonpython -m scripts.train_signals -c config.json Ohne eine Konfigurationsdatei verwenden die Skripte die Standardparameter, was für Testzwecke nützlich ist und nicht dazu gedacht ist, eine gute Leistung anzuzeigen. Verwenden Sie Beispielkonfigurationsdateien, die für jede Version bereitgestellt werden, z. B. config-sample-v0.6.0.jsonc .
Der Hauptkonfigurationsparameter für beide Skripte ist eine Liste von Quellen in data_sources . Ein Eintrag in dieser Liste gibt eine Datenquelle sowie column_prefix an, das zur Unterscheidung von Spalten mit demselben Namen aus verschiedenen Quellen verwendet wird.
Laden Sie die neuesten historischen Daten herunter: python -m scripts.download_binance -c config.json
Führen Sie mehrere historische Datensätze zu einem Datensatz zusammen: python -m scripts.merge -c config.json
Dieses Skript ist für die Berechnung abgeleiteter Funktionen gedacht:
python -m scripts.features -c config.json Die Liste der zu generierenden Features wird über die Liste feature_sets in der Konfigurationsdatei konfiguriert. Wie Features generiert werden, wird durch den Feature-Generator definiert, der jeweils einige Parameter in seinem Konfigurationsabschnitt angibt.
talib Funktionsgenerator basiert auf der technischen Analysebibliothek TA-lib. Hier ein Beispiel seiner Konfiguration "config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]}itbstats Feature-Generator implementiert Funktionen, die in tsfresh zu finden sind, wie scipy_skew , scipy_kurtosis , lsbm (längster Schlag unter dem Mittelwert), fmax (erste Position des Maximums), mean , std , area , slope . Hier sind typische Parameter "config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]}itblib Funktionsgenerator ist in ITB implementiert, die meisten seiner Funktionen können jedoch (viel schneller) über talib generiert werdentsfresh generiert Funktionen aus der tsfresh-Bibliothek Dieses Skript ähnelt der Feature-Generierung, da es der Eingabedatei neue Spalten hinzufügt. Diese Spalten beschreiben jedoch etwas, das wir vorhersagen möchten und was bei der Ausführung im Online-Modus nicht bekannt ist. Es könnte sich zum Beispiel um eine Preiserhöhung in der Zukunft handeln:
python -m scripts.labels -c config.json Die Liste der zu generierenden Labels wird über die Liste label_sets in der Konfiguration konfiguriert. Ein Labelsatz verweist auf die Funktion, die zusätzliche Spalten generiert. Ihre Konfiguration ist den Feature-Konfigurationen sehr ähnlich.
highlow Label-Generator gibt „True“ zurück, wenn der Preis innerhalb eines zukünftigen Horizonts über dem angegebenen Schwellenwert liegthighlow2 Berechnet zukünftige Zuwächse (Abnahmen) unter der Bedingung, dass es vorher keine signifikanten Rückgänge (Zuwächse) gibt. Hier ist die typische Konfiguration "config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]}topbot Veraltettopbot2 Berechnet maximale und minimale Werte (gekennzeichnet als „True“). Jedes gekennzeichnete Maximum (Minimum) ist garantiert von Minimums (Maximums) umgeben, die niedriger (höher) als das angegebene Niveau sind. Über level wird die erforderliche Mindestdifferenz zwischen benachbarten Minima und Maxima vorgegeben. Der Toleranzparameter ermöglicht es, auch Punkte in der Nähe des Maximums/Minimums einzubeziehen. Hier ist eine typische Konfiguration "config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]} Dieses Skript verwendet die angegebenen Eingabefunktionen und Beschriftungen, um mehrere ML-Modelle zu trainieren:
python -m scripts.train -c config.jsonprediction-metrics.txt mit den Vorhersagewerten für alle ModelleKonfiguration:
model_store.py beschriebentrain_features angegebenlabels angegebenalgorithms angegeben Das Ziel dieses Schritts besteht darin, die von verschiedenen Algorithmen für verschiedene Labels generierten Vorhersagewerte zu aggregieren. Das Ergebnis ist eine Punktzahl, die im nächsten Schritt von den Signalregeln verbraucht werden soll. Die Aggregationsparameter werden im Abschnitt score_aggregation angegeben. Die buy_labels und sell_labels geben Eingabevorhersagewerte an, die vom Aggregationsverfahren verarbeitet werden. window ist die Anzahl der vorherigen Schritte, die für die fortlaufende Aggregation verwendet werden, und combine ist eine Möglichkeit, wie zwei Bewertungstypen (Kauf und Labels) zu einer Ausgabebewertung kombiniert werden.
Der durch das Aggregationsverfahren generierte Wert ist eine Zahl und das Ziel von Signalregeln besteht darin, Handelsentscheidungen zu treffen: Kaufen, verkaufen oder nichts tun. Die Parameter der Signalregeln sind im trade_model beschrieben.
Dieses Skript simuliert Trades mit vielen Kauf-/Verkaufssignalparametern und wählt dann die Signalparameter mit der besten Leistung aus:
python -m scripts.train_signals -c config.jsonDieses Skript startet einen Dienst, der regelmäßig ein und dieselbe Aufgabe ausführt: aktuelle Daten laden, Features generieren, Vorhersagen treffen, Signale generieren, Abonnenten benachrichtigen:
python -m service.server -c config.jsonEs gibt zwei Probleme:
python -m scripts.predict_rolling -c config.jsonpython -m scripts.train_signals -c config.jsonDie Konfigurationsparameter werden in zwei Dateien angegeben:
service.App.py im config der App -Klasse-c config.jsom Argument für die Dienste und Skripte. Die Werte aus dieser Konfigurationsdatei überschreiben diejenigen in der App.config wenn diese Datei in ein Skript oder einen Dienst geladen wird Hier sind einige der wichtigsten Felder (sowohl in App.py als auch in config.json ):
data_folder – Speicherort der Datendateien, die nur für Batch-Offline-Skripts benötigt werdensymbol ist es ein Handelspaar wie BTCUSDTlabels Liste der Spaltennamen, die als Labels behandelt werden. Wenn Sie ein neues Label definieren, das für das Training und dann für die Vorhersage verwendet wird, müssen Sie hier seinen Namen angebenalgorithms Liste der für das Training verwendeten Algorithmusnamentrain_features Liste aller Spaltennamen, die als Eingabemerkmale für Training und Vorhersage verwendet werden.buy_labels und sell_labels Listen der vorhergesagten Spalten, die für Signale verwendet werdentrade_model Parameter des Signalgebers (hauptsächlich einige Schwellenwerte)trader ist ein Abschnitt für Händlerparameter. Derzeit nicht gründlich getestet.collector Dieser Parameterabschnitt ist für Datenerfassungsdienste gedacht. Es gibt zwei Arten von Datenerfassungsdiensten: synchron mit regelmäßigen Anfragen an den Datenanbieter und asynchrone Streaming-Dienste, die sich beim Datenanbieter anmelden und Benachrichtigungen erhalten, sobald neue Daten verfügbar sind. Sie funktionieren, wurden jedoch nicht gründlich getestet und in den Hauptdienst integriert. Das aktuelle Hauptnutzungsmuster basiert auf manuellen Batch-Datenaktualisierungen, Funktionsgenerierung und Modelltraining. Ein Grund für diese Datenerfassungsdienste ist 1) schnellere Aktualisierungen und 2) Daten, die in der normalen API wie dem Orderbuch nicht verfügbar sind (es gibt einige Funktionen, die diese Daten verwenden, aber nicht in den Hauptworkflow integriert sind).Weitere Einzelheiten finden Sie in den Beispielkonfigurationsdateien und Kommentaren in App.config.
Der Signalgeber führt jede Minute die folgenden Schritte aus, um eine Vorhersage darüber zu treffen, ob der Preis wahrscheinlich steigen oder fallen wird:
Hinweise:
Starten des Dienstes: python3 -m service.server -c config.json
Der Händler funktioniert, ist aber nicht vollständig debuggt und insbesondere nicht auf Stabilität und Zuverlässigkeit getestet. Daher sollte es als Prototyp mit grundlegender Funktionalität betrachtet werden. Es ist derzeit in den Signaler integriert, sollte aber in einem besseren Design ein separater Dienst sein.
Backtesting
Externe Integrationen


