vit pytorch
1.9.1
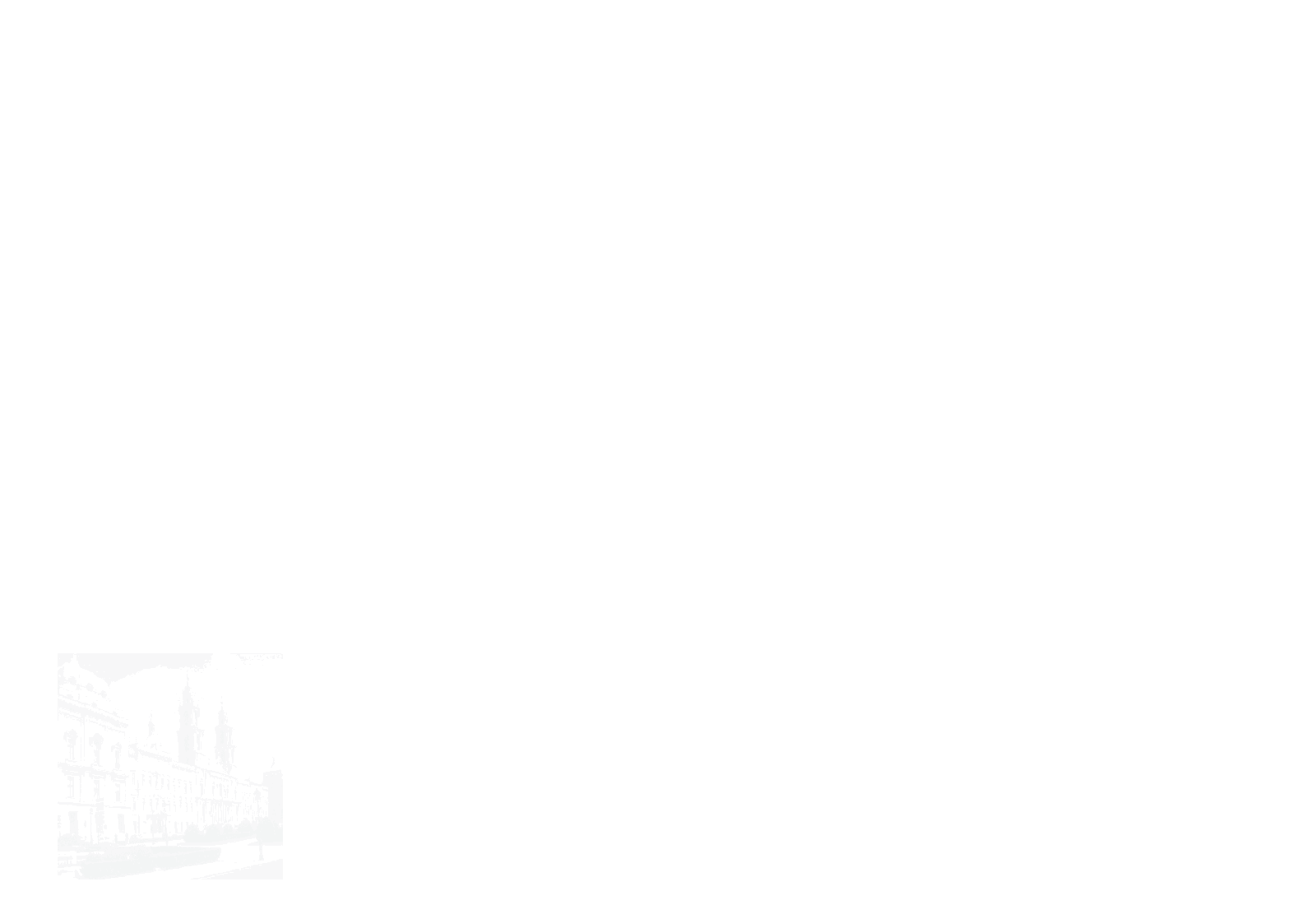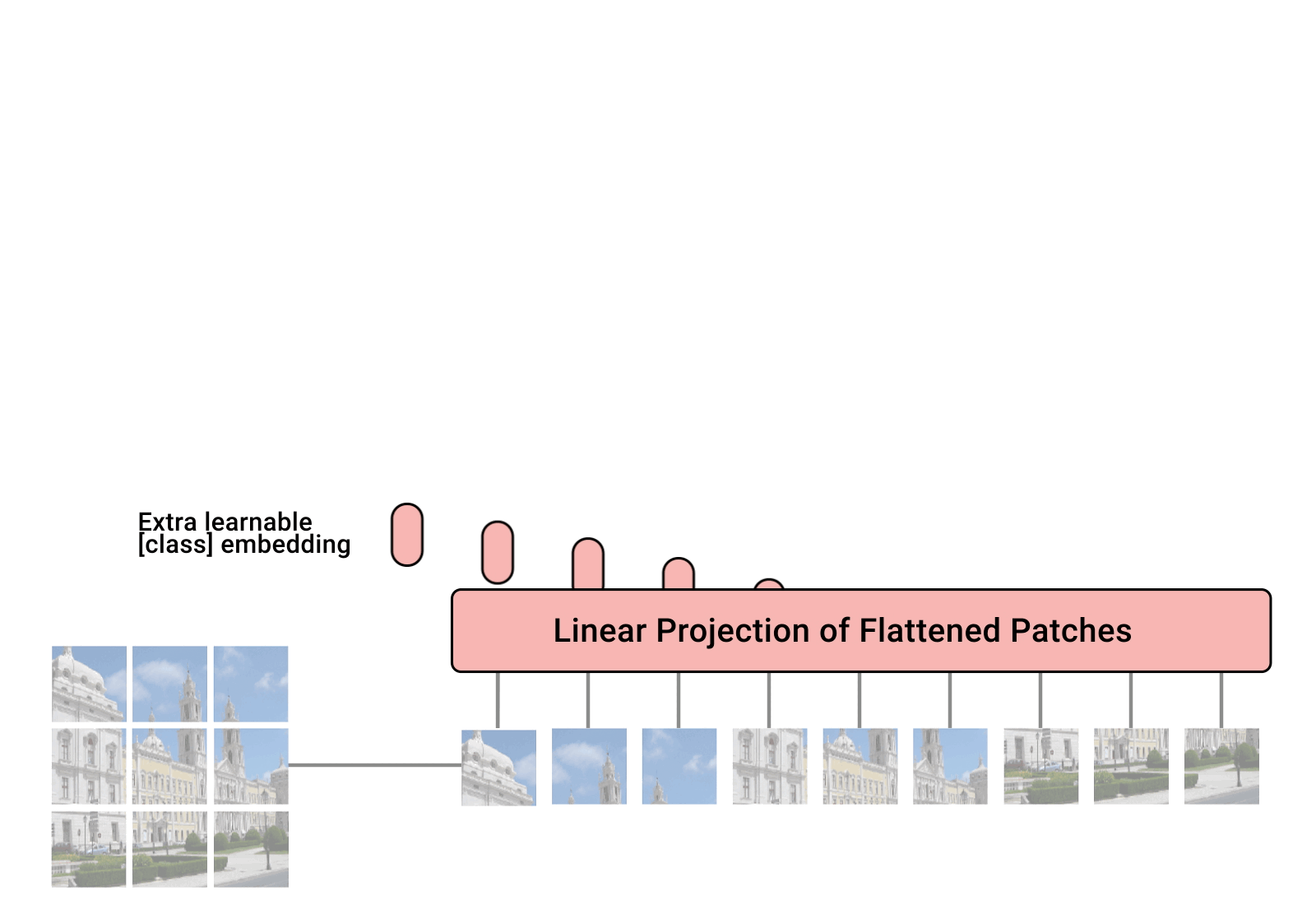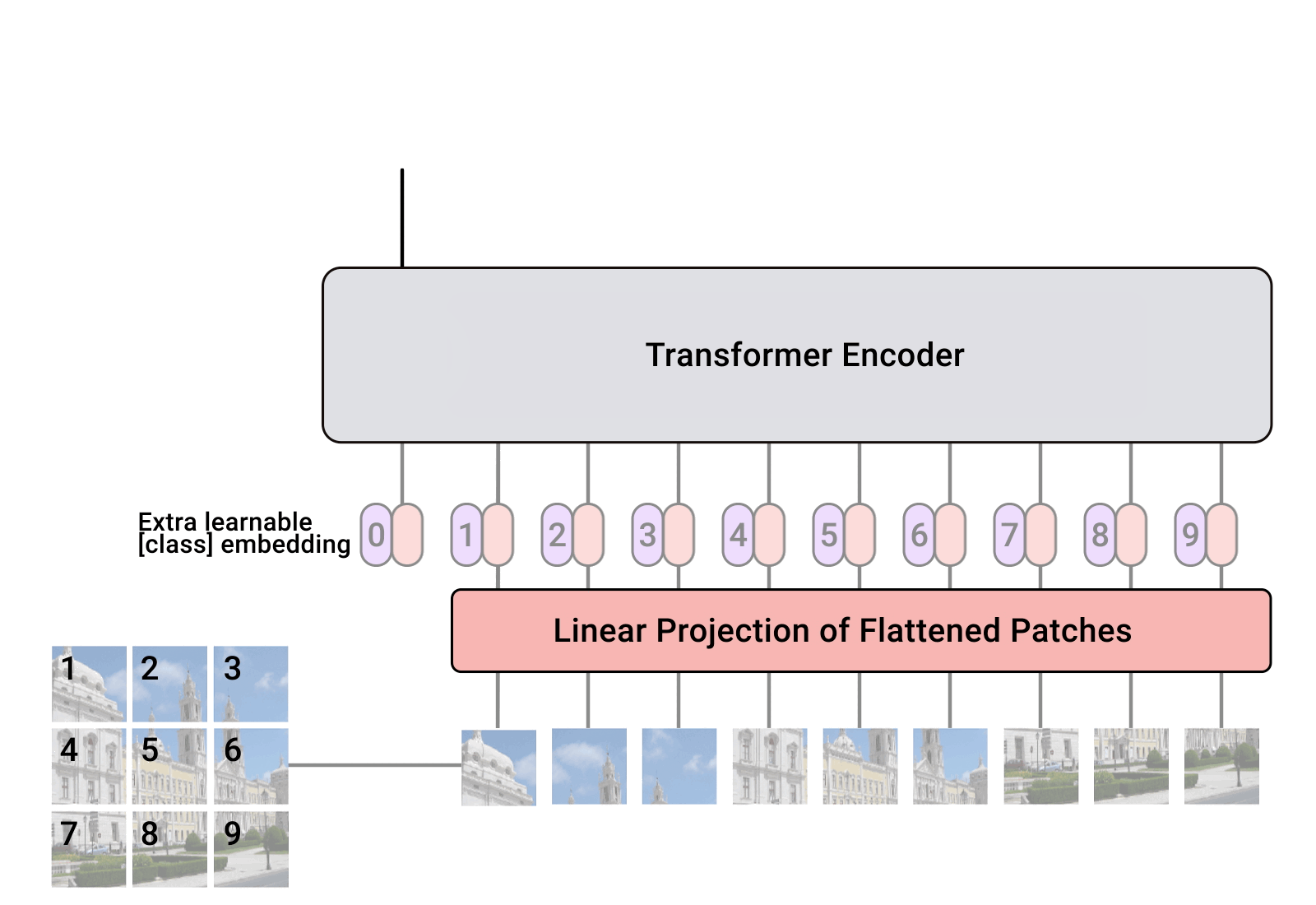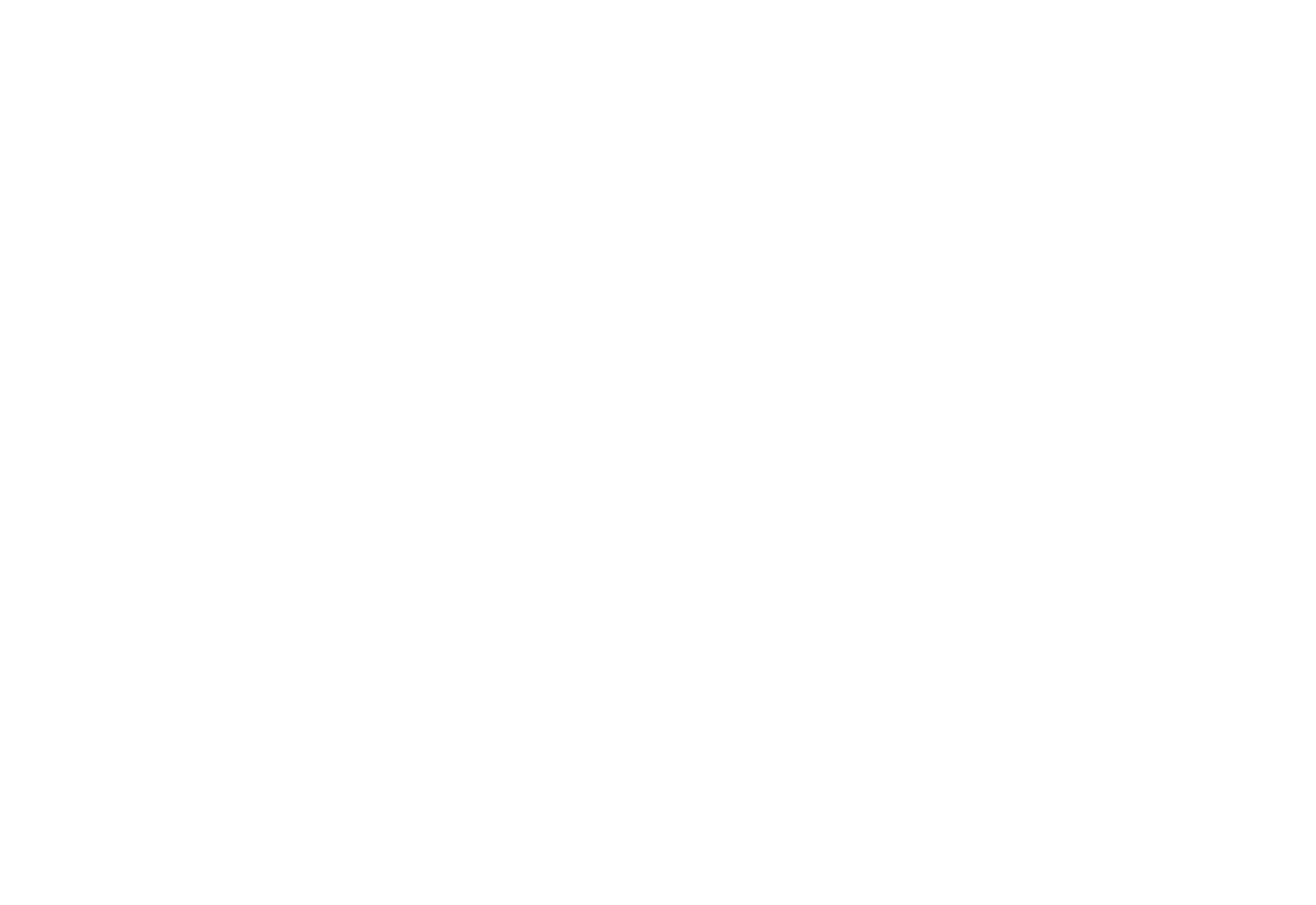
Implementierung von Vision Transformer, einer einfachen Möglichkeit, SOTA bei der Vision-Klassifizierung mit nur einem einzigen Transformer-Encoder zu erreichen, in Pytorch. Die Bedeutung wird im Video von Yannic Kilcher näher erläutert. Es gibt hier wirklich nicht viel zu programmieren, aber wir können es genauso gut für alle zugänglich machen, damit wir die Aufmerksamkeitsrevolution vorantreiben.
Eine Pytorch-Implementierung mit vorab trainierten Modellen finden Sie hier im Repository von Ross Wightman.
Das offizielle Jax-Repository ist hier.
Hier gibt es auch eine Tensorflow2-Übersetzung, erstellt vom Forscher Junho Kim!
Flachs-Übersetzung von Enrico Shippole!
$ pip install vit-pytorch import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) image_size : int.patch_size : int.image_size muss durch patch_size teilbar sein.n = (image_size // patch_size) ** 2 und n muss größer als 16 sein .num_classes : int.dim : int.nn.Linear(..., dim) .depth : int.heads : int.mlp_dim : int.channels : int, Standard 3 .dropout : Float zwischen [0, 1] , Standard 0. .emb_dropout : Float zwischen [0, 1] , Standard 0 .pool : Zeichenfolge, entweder cls Token-Pooling oder mean Pooling Ein Update von einigen der gleichen Autoren des Originalpapiers schlägt Vereinfachungen für ViT vor, die ein schnelleres und besseres Training ermöglichen.
Zu diesen Vereinfachungen gehören 2D-Sinus-Positionseinbettung, globales Durchschnittspooling (kein CLS-Token), kein Dropout, Stapelgrößen von 1024 statt 4096 und die Verwendung von RandAugment- und MixUp-Erweiterungen. Sie zeigen auch, dass ein einfacher linearer Kopf am Ende nicht wesentlich schlechter ist als der ursprüngliche MLP-Kopf
Sie können es verwenden, indem Sie SimpleViT wie unten gezeigt importieren
import torch
from vit_pytorch import SimpleViT
v = SimpleViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 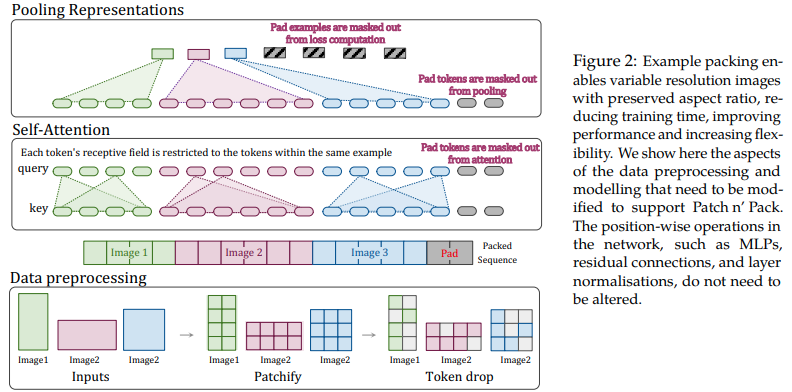
In diesem Artikel wird vorgeschlagen, die Flexibilität der Aufmerksamkeit und Maskierung für Sequenzen variabler Länge zu nutzen, um Bilder mit mehreren Auflösungen zu trainieren, die in einem einzigen Stapel verpackt sind. Sie zeichnen sich durch ein viel schnelleres Training und eine höhere Genauigkeit aus, wobei der einzige Nachteil eine zusätzliche Komplexität der Architektur und des Datenladens ist. Sie verwenden faktorisierte 2D-Positionskodierungen, Token-Drop sowie die Normalisierung von Abfrageschlüsseln.
Sie können es wie folgt verwenden
import torch
from vit_pytorch . na_vit import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
token_dropout_prob = 0.1 # token dropout of 10% (keep 90% of tokens)
)
# 5 images of different resolutions - List[List[Tensor]]
# for now, you'll have to correctly place images in same batch element as to not exceed maximum allowed sequence length for self-attention w/ masking
images = [
[ torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 )],
[ torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 )],
[ torch . randn ( 3 , 64 , 256 )]
]
preds = v ( images ) # (5, 1000) - 5, because 5 images of different resolution aboveOder wenn Sie möchten, dass das Framework die Bilder automatisch in Sequenzen variabler Länge gruppiert, die eine bestimmte maximale Länge nicht überschreiten
images = [
torch . randn ( 3 , 256 , 256 ),
torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ),
torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v (
images ,
group_images = True ,
group_max_seq_len = 64
) # (5, 1000) Wenn Sie schließlich eine Variante von NaViT mit verschachtelten Tensoren verwenden möchten (wodurch ein Großteil der Maskierung und Auffüllung vollständig entfällt), stellen Sie sicher, dass Sie Version 2.5 verwenden, und importieren Sie wie folgt
import torch
from vit_pytorch . na_vit_nested_tensor import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0. ,
emb_dropout = 0. ,
token_dropout_prob = 0.1
)
# 5 images of different resolutions - List[Tensor]
images = [
torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v ( images )
assert preds . shape == ( 5 , 1000 )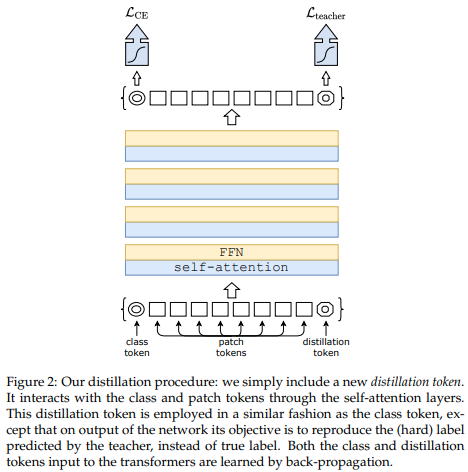
Ein kürzlich veröffentlichter Artikel hat gezeigt, dass die Verwendung eines Destillationstokens zum Destillieren von Wissen von Faltungsnetzen bis hin zu Vision-Transformatoren zu kleinen und effizienten Vision-Transformatoren führen kann. Dieses Repository bietet die Möglichkeit, die Destillation einfach durchzuführen.
ex. Destillieren von Resnet50 (oder einem beliebigen Lehrer) zu einem Vision-Transformator
import torch
from torchvision . models import resnet50
from vit_pytorch . distill import DistillableViT , DistillWrapper
teacher = resnet50 ( pretrained = True )
v = DistillableViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
distiller = DistillWrapper (
student = v ,
teacher = teacher ,
temperature = 3 , # temperature of distillation
alpha = 0.5 , # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch . randn ( 2 , 3 , 256 , 256 )
labels = torch . randint ( 0 , 1000 , ( 2 ,))
loss = distiller ( img , labels )
loss . backward ()
# after lots of training above ...
pred = v ( img ) # (2, 1000) Die DistillableViT -Klasse ist bis auf die Art und Weise, wie der Vorwärtsdurchlauf gehandhabt wird, mit ViT identisch. Daher sollten Sie in der Lage sein, die Parameter nach Abschluss des Destillationstrainings wieder in ViT zu laden.
Sie können auch die praktische Methode .to_vit für die DistillableViT -Instanz verwenden, um eine ViT -Instanz wiederherzustellen.
v = v . to_vit ()
type ( v ) # <class 'vit_pytorch.vit_pytorch.ViT'> In diesem Artikel wird darauf hingewiesen, dass es ViT schwerfällt, in größeren Tiefen (über 12 Schichten hinaus) zu agieren, und es wird vorgeschlagen, die Aufmerksamkeit jedes Kopfes nach Softmax als Lösung zu vermischen, was als „Re-Attention“ bezeichnet wird. Die Ergebnisse stimmen mit dem Talking Heads-Artikel von NLP überein.
Sie können es wie folgt verwenden
import torch
from vit_pytorch . deepvit import DeepViT
v = DeepViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) In diesem Artikel wird auch auf die Schwierigkeit hingewiesen, Sehtransformatoren in größeren Tiefen zu trainieren, und es werden zwei Lösungen vorgeschlagen. Zunächst wird vorgeschlagen, die Ausgabe des Restblocks pro Kanal zu multiplizieren. Zweitens wird vorgeschlagen, die Patches aufeinander abzustimmen und dem CLS-Token nur zu erlauben, sich um die Patches in den letzten Schichten zu kümmern.
Sie fügen auch Talking Heads hinzu und stellen Verbesserungen fest
Sie können dieses Schema wie folgt verwenden
import torch
from vit_pytorch . cait import CaiT
v = CaiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of transformer for patch to patch attention only
cls_depth = 2 , # depth of cross attention of CLS tokens to patch
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 # randomly dropout 5% of the layers
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 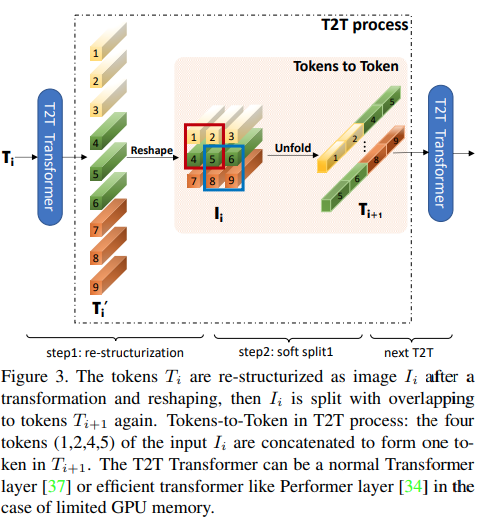
In diesem Artikel wird vorgeschlagen, dass die ersten paar Schichten die Bildsequenz durch Entfaltung heruntersampeln sollten, was zu überlappenden Bilddaten in jedem Token führt, wie in der Abbildung oben gezeigt. Sie können diese Variante des ViT wie folgt nutzen.
import torch
from vit_pytorch . t2t import T2TViT
v = T2TViT (
dim = 512 ,
image_size = 224 ,
depth = 5 ,
heads = 8 ,
mlp_dim = 512 ,
num_classes = 1000 ,
t2t_layers = (( 7 , 4 ), ( 3 , 2 ), ( 3 , 2 )) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) CCT schlägt kompakte Transformatoren vor, indem es Faltungen anstelle von Patching und Sequenz-Pooling verwendet. Dies ermöglicht der CCT eine hohe Genauigkeit und eine geringe Anzahl von Parametern.
Sie können dies mit zwei Methoden nutzen
import torch
from vit_pytorch . cct import CCT
cct = CCT (
img_size = ( 224 , 448 ),
embedding_dim = 384 ,
n_conv_layers = 2 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)
img = torch . randn ( 1 , 3 , 224 , 448 )
pred = cct ( img ) # (1, 1000) Alternativ können Sie eines von mehreren vordefinierten Modellen [2,4,6,7,8,14,16] verwenden, die die Anzahl der Schichten, die Anzahl der Aufmerksamkeitsköpfe, das MLP-Verhältnis und die Einbettungsdimension vordefinieren.
import torch
from vit_pytorch . cct import cct_14
cct = cct_14 (
img_size = 224 ,
n_conv_layers = 1 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)Das offizielle Repository enthält Links zu vorab trainierten Modellprüfpunkten.
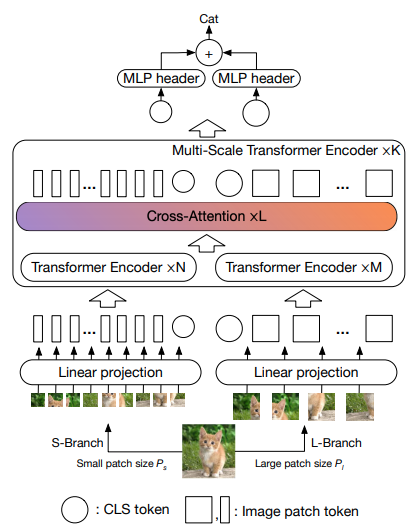
In diesem Artikel wird vorgeschlagen, dass zwei Vision-Transformatoren das Bild in unterschiedlichen Maßstäben verarbeiten und sich von Zeit zu Zeit gegenseitig um einen kümmern. Sie zeigen Verbesserungen gegenüber dem Basis-Vision-Transformator.
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 , # number of multi-scale encoding blocks
sm_dim = 192 , # high res dimension
sm_patch_size = 16 , # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2 , # high res depth
sm_enc_heads = 8 , # high res heads
sm_enc_mlp_dim = 2048 , # high res feedforward dimension
lg_dim = 384 , # low res dimension
lg_patch_size = 64 , # low res patch size
lg_enc_depth = 3 , # low res depth
lg_enc_heads = 8 , # low res heads
lg_enc_mlp_dim = 2048 , # low res feedforward dimensions
cross_attn_depth = 2 , # cross attention rounds
cross_attn_heads = 8 , # cross attention heads
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = v ( img ) # (1, 1000) 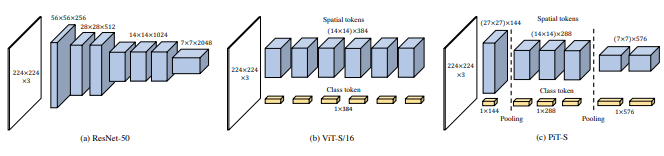
In diesem Artikel wird vorgeschlagen, die Token durch ein Pooling-Verfahren unter Verwendung von Tiefenfaltungen herunterzurechnen.
import torch
from vit_pytorch . pit import PiT
v = PiT (
image_size = 224 ,
patch_size = 14 ,
dim = 256 ,
num_classes = 1000 ,
depth = ( 3 , 3 , 3 ), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 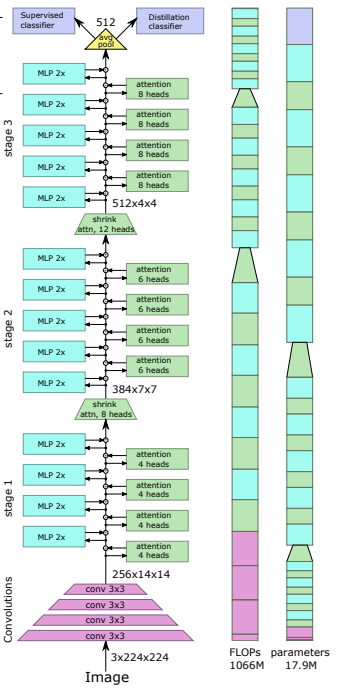
Dieses Papier schlägt eine Reihe von Änderungen vor, darunter (1) Faltungseinbettung anstelle von fleckenweiser Projektion (2) stufenweises Downsampling (3) zusätzliche Nichtlinearität in der Aufmerksamkeit (4) 2d relative Positionsverzerrungen anstelle der anfänglichen absoluten Positionsverzerrungen (5 ) Batchnorm anstelle von Layernorm.
Offizielles Repository
import torch
from vit_pytorch . levit import LeViT
levit = LeViT (
image_size = 224 ,
num_classes = 1000 ,
stages = 3 , # number of stages
dim = ( 256 , 384 , 512 ), # dimensions at each stage
depth = 4 , # transformer of depth 4 at each stage
heads = ( 4 , 6 , 8 ), # heads at each stage
mlp_mult = 2 ,
dropout = 0.1
)
img = torch . randn ( 1 , 3 , 224 , 224 )
levit ( img ) # (1, 1000) 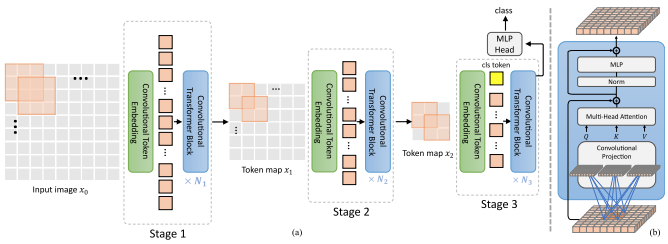
In diesem Artikel wird vorgeschlagen, Faltungen und Aufmerksamkeit zu vermischen. Insbesondere werden Faltungen verwendet, um das Bild/die Feature-Map in drei Stufen einzubetten und herunterzurechnen. Die Tiefenfaltung wird auch verwendet, um die Abfragen, Schlüssel und Werte zur Aufmerksamkeit zu projizieren.
import torch
from vit_pytorch . cvt import CvT
v = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 , # stage 1 - dimension
s1_emb_kernel = 7 , # stage 1 - conv kernel
s1_emb_stride = 4 , # stage 1 - conv stride
s1_proj_kernel = 3 , # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2 , # stage 1 - attention key / value projection stride
s1_heads = 1 , # stage 1 - heads
s1_depth = 1 , # stage 1 - depth
s1_mlp_mult = 4 , # stage 1 - feedforward expansion factor
s2_emb_dim = 192 , # stage 2 - (same as above)
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 , # stage 3 - (same as above)
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = v ( img ) # (1, 1000) 
In diesem Artikel wird vorgeschlagen, lokale und globale Aufmerksamkeit zusammen mit dem Positionskodierungsgenerator (vorgeschlagen in CPVT) und dem globalen Durchschnittspooling zu kombinieren, um die gleichen Ergebnisse wie Swin zu erzielen, ohne die zusätzliche Komplexität von verschobenen Fenstern, CLS-Tokens oder Positionseinbettungen.
import torch
from vit_pytorch . twins_svt import TwinsSVT
model = TwinsSVT (
num_classes = 1000 , # number of output classes
s1_emb_dim = 64 , # stage 1 - patch embedding projected dimension
s1_patch_size = 4 , # stage 1 - patch size for patch embedding
s1_local_patch_size = 7 , # stage 1 - patch size for local attention
s1_global_k = 7 , # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1 , # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128 , # stage 2 (same as above)
s2_patch_size = 2 ,
s2_local_patch_size = 7 ,
s2_global_k = 7 ,
s2_depth = 1 ,
s3_emb_dim = 256 , # stage 3 (same as above)
s3_patch_size = 2 ,
s3_local_patch_size = 7 ,
s3_global_k = 7 ,
s3_depth = 5 ,
s4_emb_dim = 512 , # stage 4 (same as above)
s4_patch_size = 2 ,
s4_local_patch_size = 7 ,
s4_global_k = 7 ,
s4_depth = 4 ,
peg_kernel_size = 3 , # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 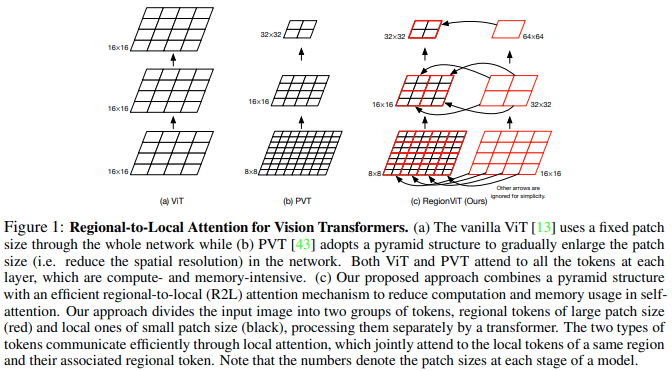
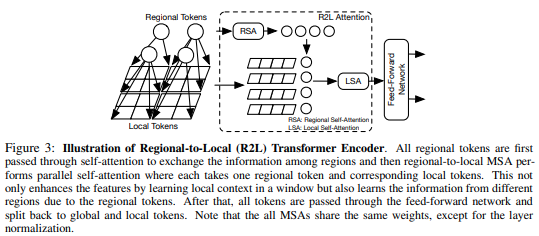
In diesem Artikel wird vorgeschlagen, die Feature-Map in lokale Regionen zu unterteilen, wobei die lokalen Token aufeinander achten. Jede lokale Region verfügt über einen eigenen regionalen Token, der dann alle lokalen Token sowie andere regionale Token verwaltet.
Sie können es wie folgt verwenden
import torch
from vit_pytorch . regionvit import RegionViT
model = RegionViT (
dim = ( 64 , 128 , 256 , 512 ), # tuple of size 4, indicating dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of the region to local transformer at each stage
window_size = 7 , # window size, which should be either 7 or 14
num_classes = 1000 , # number of output classes
tokenize_local_3_conv = False , # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False , # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 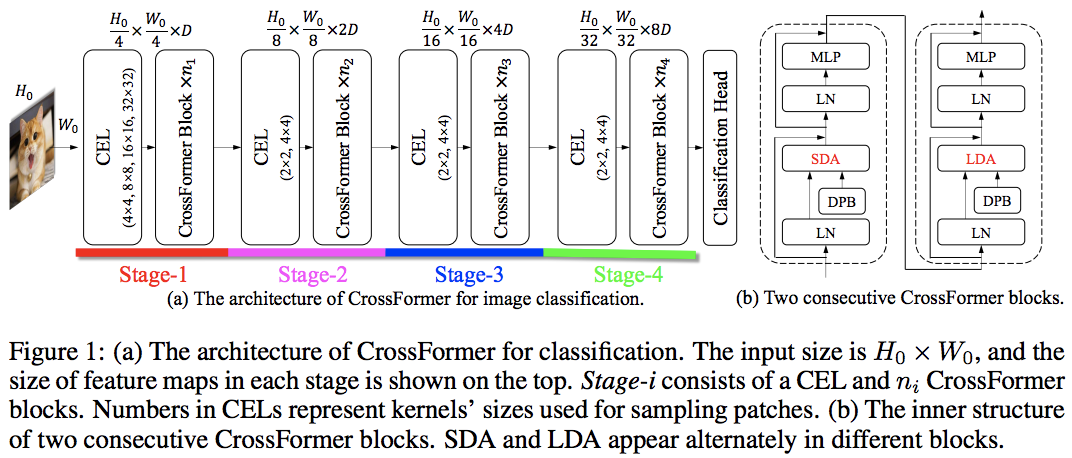
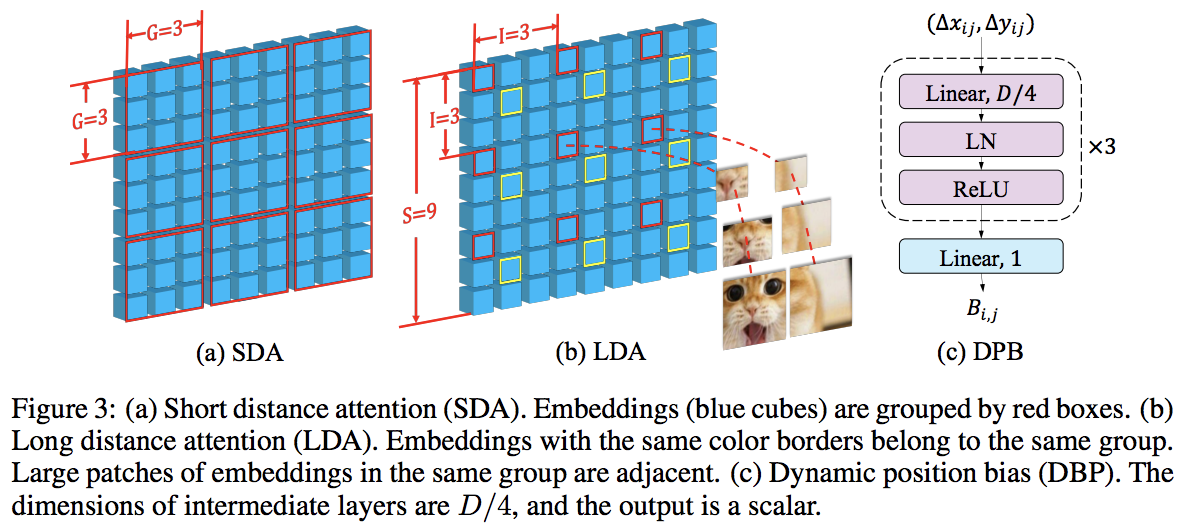
Dieses Papier übertrifft PVT und Swin durch abwechselnde lokale und globale Aufmerksamkeit. Die globale Aufmerksamkeit erfolgt zur Reduzierung der Komplexität über die gesamte Fensterdimension, ähnlich wie das Schema, das für die axiale Aufmerksamkeit verwendet wird.
Sie verfügen außerdem über eine skalenübergreifende Einbettungsschicht, von der sie gezeigt haben, dass sie eine generische Schicht ist, die alle Vision-Transformatoren verbessern kann. Außerdem wurde eine dynamische relative Positionsverzerrung formuliert, um die Verallgemeinerung des Netzes auf Bilder mit höherer Auflösung zu ermöglichen.
import torch
from vit_pytorch . crossformer import CrossFormer
model = CrossFormer (
num_classes = 1000 , # number of output classes
dim = ( 64 , 128 , 256 , 512 ), # dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of transformer at each stage
global_window_size = ( 8 , 4 , 2 , 1 ), # global window sizes at each stage
local_window_size = 7 , # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 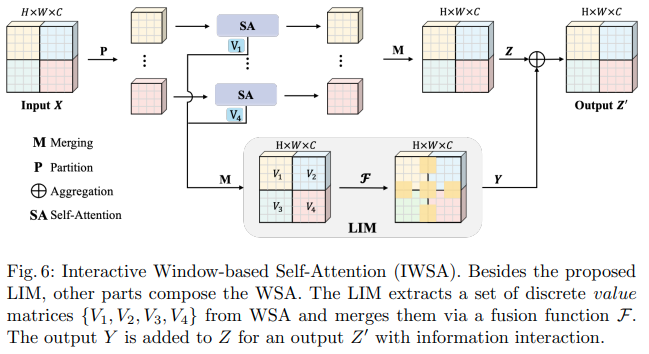
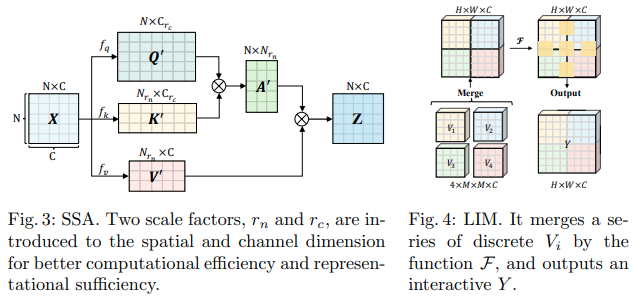
In diesem Bytedance AI-Papier werden die Module Scalable Self Attention (SSA) und Interactive Windowed Self Attention (IWSA) vorgeschlagen. Die SSA erleichtert die in früheren Phasen erforderliche Berechnung, indem sie die Schlüssel-/Wert-Feature-Map um einen Faktor reduziert ( reduction_factor ) und gleichzeitig die Dimension der Abfragen und Schlüssel moduliert ( ssa_dim_key ). Die IWSA führt Selbstaufmerksamkeit innerhalb lokaler Fenster durch, ähnlich wie andere Vision Transformer-Papiere. Sie fügen jedoch einen Rest der Werte hinzu, der durch eine Faltung der Kernelgröße 3 geleitet wird und die sie Local Interactive Module (LIM) nennen.
Sie behaupten in diesem Artikel, dass dieses Schema Swin Transformer übertrifft und auch eine konkurrenzfähige Leistung gegenüber Crossformer zeigt.
Sie können es wie folgt verwenden (z. B. ScalableViT-S)
import torch
from vit_pytorch . scalable_vit import ScalableViT
model = ScalableViT (
num_classes = 1000 ,
dim = 64 , # starting model dimension. at every stage, dimension is doubled
heads = ( 2 , 4 , 8 , 16 ), # number of attention heads at each stage
depth = ( 2 , 2 , 20 , 2 ), # number of transformer blocks at each stage
ssa_dim_key = ( 40 , 40 , 40 , 32 ), # the dimension of the attention keys (and queries) for SSA. in the paper, they represented this as a scale factor on the base dimension per key (ssa_dim_key / dim_key)
reduction_factor = ( 8 , 4 , 2 , 1 ), # downsampling of the key / values in SSA. in the paper, this was represented as (reduction_factor ** -2)
window_size = ( 64 , 32 , None , None ), # window size of the IWSA at each stage. None means no windowing needed
dropout = 0.1 , # attention and feedforward dropout
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = model ( img ) # (1, 1000) 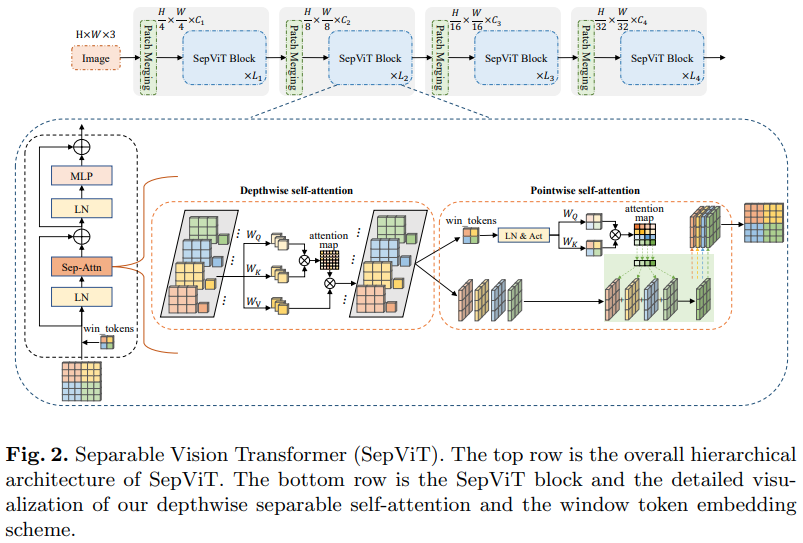
In einem weiteren AI-Artikel von Bytedance wird eine Tiefen-Punkt-Selbstaufmerksamkeitsschicht vorgeschlagen, die größtenteils von der tiefenweise trennbaren Faltung von Mobilenet inspiriert zu sein scheint. Der interessanteste Aspekt ist die Wiederverwendung der Feature-Map aus der Phase der tiefenweisen Selbstaufmerksamkeit als Werte für die punktweise Selbstaufmerksamkeit, wie im Diagramm oben dargestellt.
Ich habe beschlossen, nur die Version von SepViT mit dieser spezifischen Selbstaufmerksamkeitsschicht einzubeziehen, da die gruppierten Aufmerksamkeitsschichten weder bemerkenswert noch neu sind und die Autoren nicht klar waren, wie sie die Fenster-Tokens für die Gruppen-Selbstaufmerksamkeitsschicht behandelten. Außerdem scheint es so, als hätten sie Swin allein mit DSSA -Schicht schlagen können.
ex. SepViT-Lite
import torch
from vit_pytorch . sep_vit import SepViT
v = SepViT (
num_classes = 1000 ,
dim = 32 , # dimensions of first stage, which doubles every stage (32, 64, 128, 256) for SepViT-Lite
dim_head = 32 , # attention head dimension
heads = ( 1 , 2 , 4 , 8 ), # number of heads per stage
depth = ( 1 , 2 , 6 , 2 ), # number of transformer blocks per stage
window_size = 7 , # window size of DSS Attention block
dropout = 0.1 # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 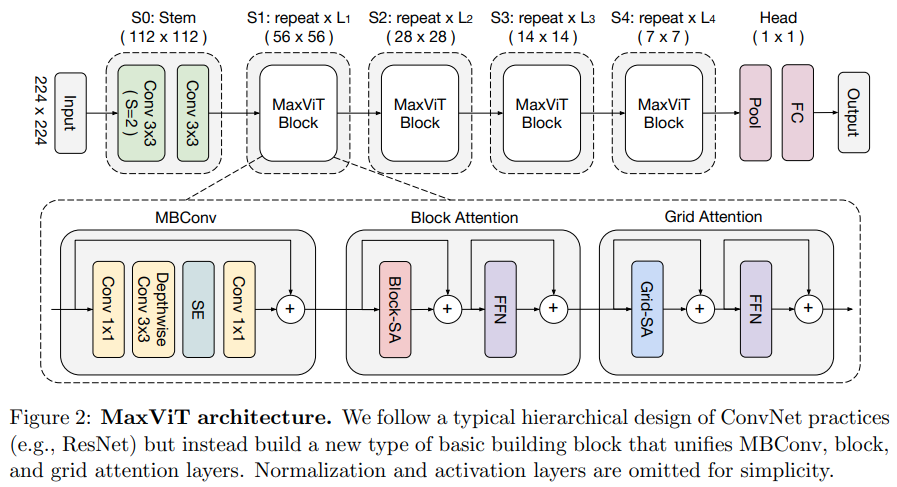
In diesem Artikel wird ein hybrides Faltungs-/Aufmerksamkeitsnetzwerk vorgeschlagen, bei dem MBConv von der Faltungsseite aus verwendet wird und dann die axiale, spärliche Block-/Gitteraufmerksamkeit blockiert wird.
Sie behaupten auch, dass dieser spezielle Vision-Transformator gut für generative Modelle (GANs) geeignet ist.
ex. MaxViT-S
import torch
from vit_pytorch . max_vit import MaxViT
v = MaxViT (
num_classes = 1000 ,
dim_conv_stem = 64 , # dimension of the convolutional stem, would default to dimension of first layer if not specified
dim = 96 , # dimension of first layer, doubles every layer
dim_head = 32 , # dimension of attention heads, kept at 32 in paper
depth = ( 2 , 2 , 5 , 2 ), # number of MaxViT blocks per stage, which consists of MBConv, block-like attention, grid-like attention
window_size = 7 , # window size for block and grids
mbconv_expansion_rate = 4 , # expansion rate of MBConv
mbconv_shrinkage_rate = 0.25 , # shrinkage rate of squeeze-excitation in MBConv
dropout = 0.1 # dropout
)
img = torch . randn ( 2 , 3 , 224 , 224 )
preds = v ( img ) # (2, 1000) 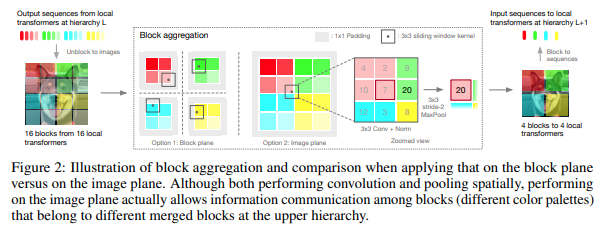
In diesem Artikel wurde beschlossen, das Bild in hierarchischen Stufen zu verarbeiten, wobei die Aufmerksamkeit nur auf die Token lokaler Blöcke gerichtet ist, die sich beim Aufstieg in der Hierarchie aggregieren. Die Aggregation erfolgt in der Bildebene und umfasst eine Faltung und einen anschließenden Maxpool, damit Informationen über die Grenze weitergeleitet werden können.
Sie können es mit dem folgenden Code verwenden (z. B. NesT-T)
import torch
from vit_pytorch . nest import NesT
nest = NesT (
image_size = 224 ,
patch_size = 4 ,
dim = 96 ,
heads = 3 ,
num_hierarchies = 3 , # number of hierarchies
block_repeats = ( 2 , 2 , 8 ), # the number of transformer blocks at each hierarchy, starting from the bottom
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = nest ( img ) # (1, 1000) 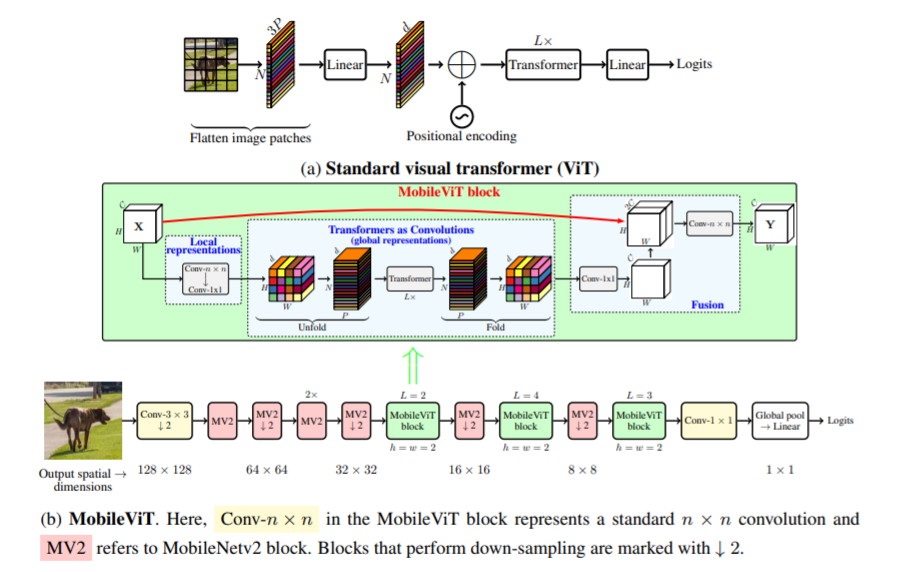
In diesem Artikel wird MobileViT vorgestellt, ein leichter und universeller Vision-Transformer für mobile Geräte. MobileViT bietet eine andere Perspektive für die globale Informationsverarbeitung mit Transformatoren.
Sie können es mit dem folgenden Code verwenden (z. B. mobilevit_xs)
import torch
from vit_pytorch . mobile_vit import MobileViT
mbvit_xs = MobileViT (
image_size = ( 256 , 256 ),
dims = [ 96 , 120 , 144 ],
channels = [ 16 , 32 , 48 , 48 , 64 , 64 , 80 , 80 , 96 , 96 , 384 ],
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = mbvit_xs ( img ) # (1, 1000) 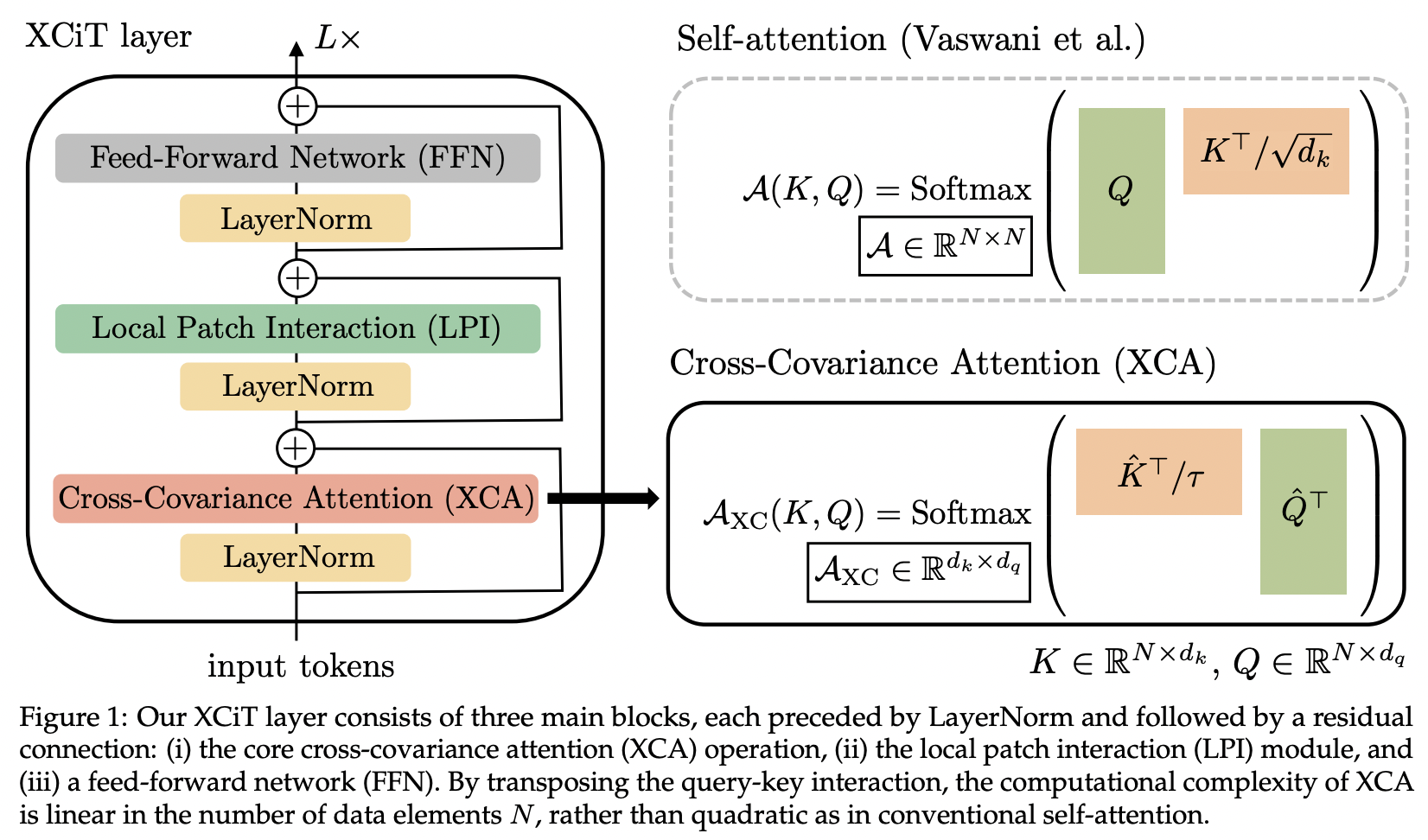
In diesem Artikel wird die Kreuzkovarianz-Aufmerksamkeit (abgekürzt XCA) vorgestellt. Man kann es sich so vorstellen, dass die Aufmerksamkeit auf die Merkmalsdimension und nicht auf die räumliche Dimension gerichtet wird (eine andere Perspektive wäre eine dynamische 1x1-Faltung, wobei der Kernel eine durch räumliche Korrelationen definierte Aufmerksamkeitskarte ist).
Technisch gesehen läuft dies darauf hinaus, einfach die Abfrage, den Schlüssel und die Werte zu transponieren, bevor die Aufmerksamkeit auf die Kosinusähnlichkeit mit der gelernten Temperatur ausgeführt wird.
import torch
from vit_pytorch . xcit import XCiT
v = XCiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of xcit transformer
cls_depth = 2 , # depth of cross attention of CLS tokens to patch, attention pool at end
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 , # randomly dropout 5% of the layers
local_patch_kernel_size = 3 # kernel size of the local patch interaction module (depthwise convs)
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 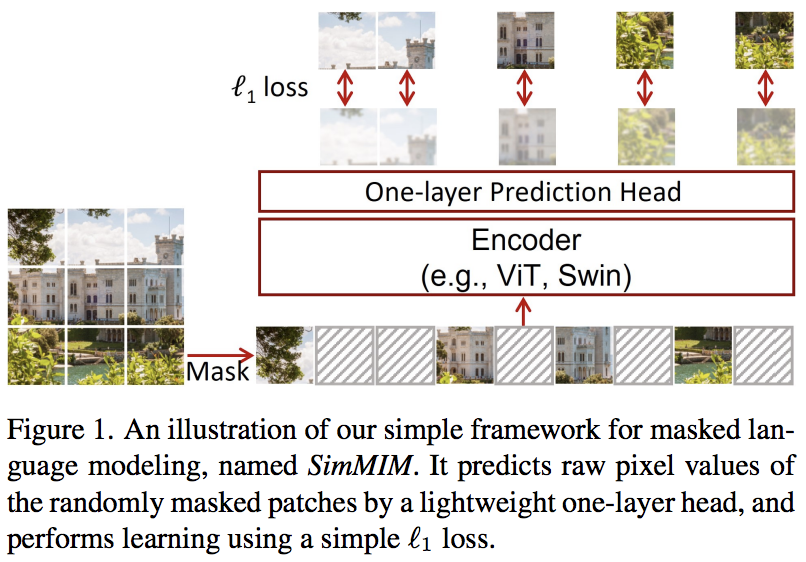
In diesem Artikel wird ein einfaches SimMIM-Schema (Masked Image Modeling) vorgeschlagen, das nur eine lineare Projektion der maskierten Token in den Pixelraum verwendet, gefolgt von einem L1-Verlust mit den Pixelwerten der maskierten Patches. Die Ergebnisse sind mit anderen, komplizierteren Ansätzen konkurrenzfähig.
Sie können dies wie folgt verwenden
import torch
from vit_pytorch import ViT
from vit_pytorch . simmim import SimMIM
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mim = SimMIM (
encoder = v ,
masking_ratio = 0.5 # they found 50% to yield the best results
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mim ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
torch . save ( v . state_dict (), './trained-vit.pt' )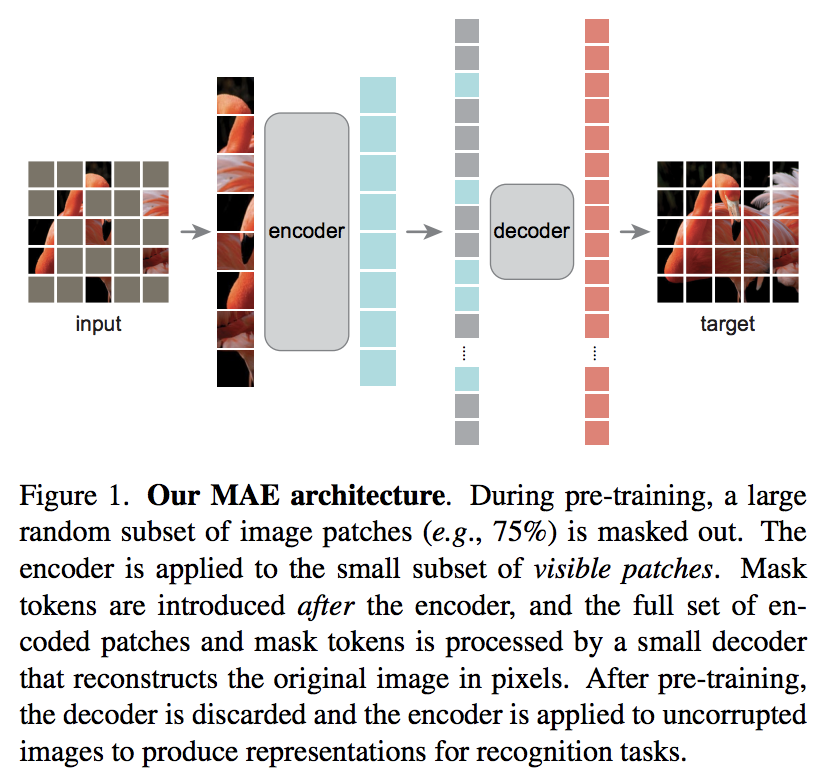
In einem neuen Artikel von Kaiming He wird ein einfaches Autoencoder-Schema vorgeschlagen, bei dem der Vision-Transformer sich um eine Reihe unmaskierter Patches kümmert und ein kleinerer Decoder versucht, die maskierten Pixelwerte zu rekonstruieren.
Kurze Rezension des DeepReader-Artikels
AI-Kaffeepause mit Letitia
Sie können es mit dem folgenden Code verwenden
import torch
from vit_pytorch import ViT , MAE
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mae = MAE (
encoder = v ,
masking_ratio = 0.75 , # the paper recommended 75% masked patches
decoder_dim = 512 , # paper showed good results with just 512
decoder_depth = 6 # anywhere from 1 to 8
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mae ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )Dank Zach können Sie mit der im Artikel vorgestellten Originalaufgabe zur Vorhersage maskierter Patches mit dem folgenden Code trainieren.
import torch
from vit_pytorch import ViT
from vit_pytorch . mpp import MPP
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
mpp_trainer = MPP (
transformer = model ,
patch_size = 32 ,
dim = 1024 ,
mask_prob = 0.15 , # probability of using token in masked prediction task
random_patch_prob = 0.30 , # probability of randomly replacing a token being used for mpp
replace_prob = 0.50 , # probability of replacing a token being used for mpp with the mask token
)
opt = torch . optim . Adam ( mpp_trainer . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . FloatTensor ( 20 , 3 , 256 , 256 ). uniform_ ( 0. , 1. )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = mpp_trainer ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )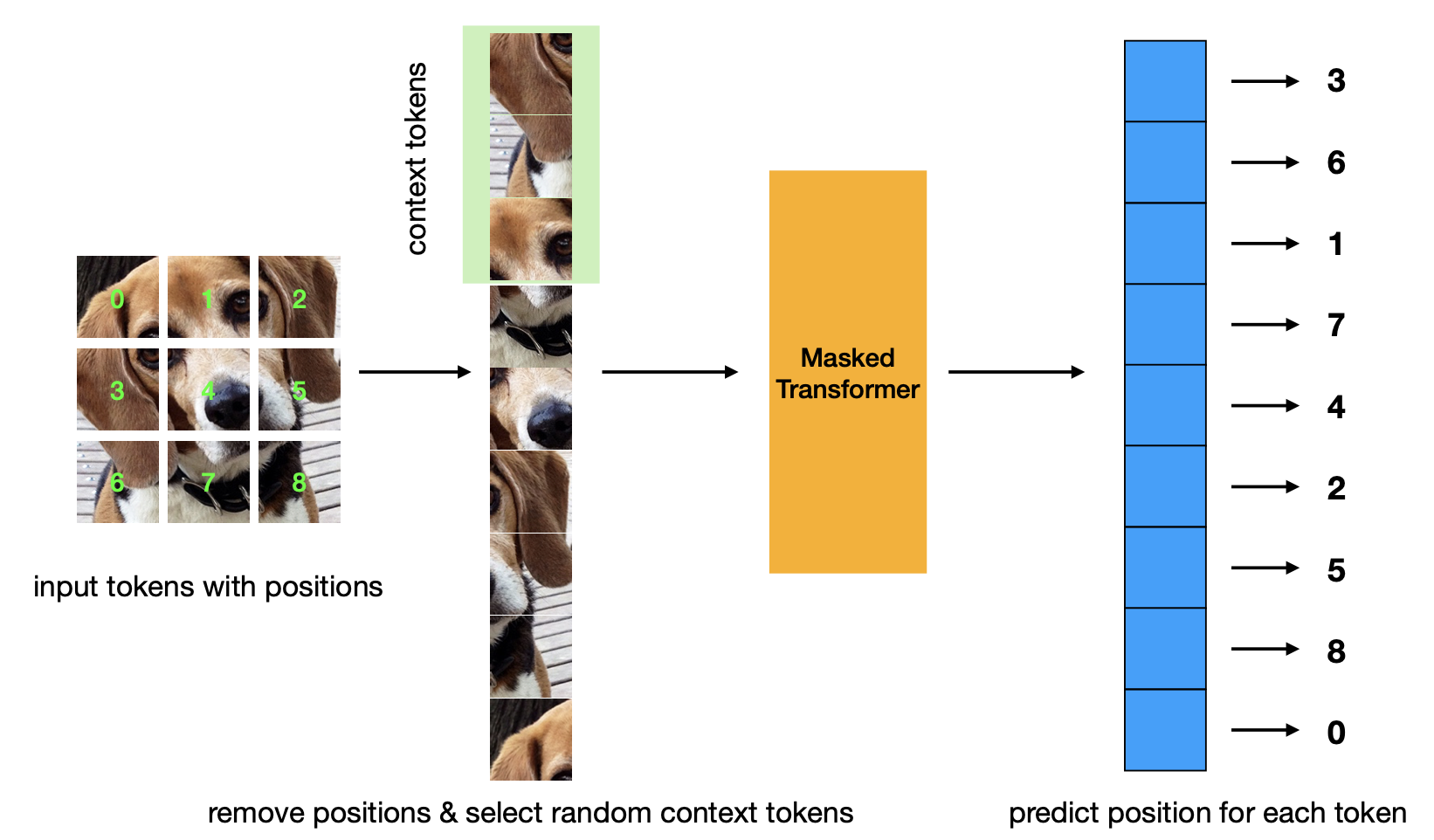
Neues Papier, das vor dem Training Kriterien für die maskierte Positionsvorhersage einführt. Diese Strategie ist effizienter als die Masked Autoencoder-Strategie und weist eine vergleichbare Leistung auf.
import torch
from vit_pytorch . mp3 import ViT , MP3
v = ViT (
num_classes = 1000 ,
image_size = 256 ,
patch_size = 8 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
)
mp3 = MP3 (
vit = v ,
masking_ratio = 0.75
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mp3 ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )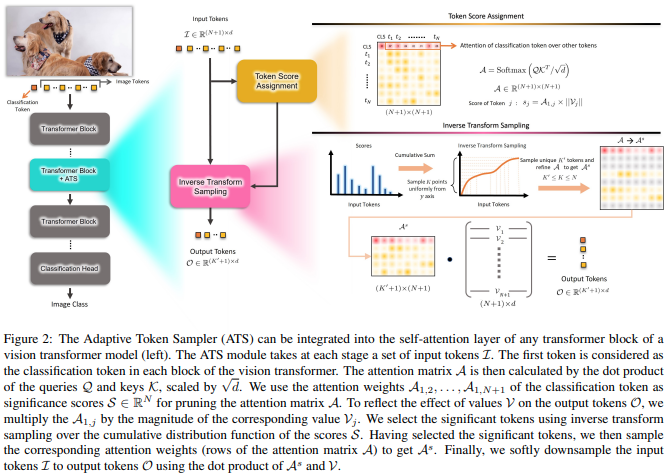
In diesem Artikel wird vorgeschlagen, die CLS-Aufmerksamkeitswerte, neu gewichtet mit den Normen der Wertköpfe, zu verwenden, um unwichtige Token auf verschiedenen Ebenen zu verwerfen.
import torch
from vit_pytorch . ats_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
max_tokens_per_depth = ( 256 , 128 , 64 , 32 , 16 , 8 ), # a tuple that denotes the maximum number of tokens that any given layer should have. if the layer has greater than this amount, it will undergo adaptive token sampling
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000)
# you can also get a list of the final sampled patch ids
# a value of -1 denotes padding
preds , token_ids = v ( img , return_sampled_token_ids = True ) # (4, 1000), (4, <=8) 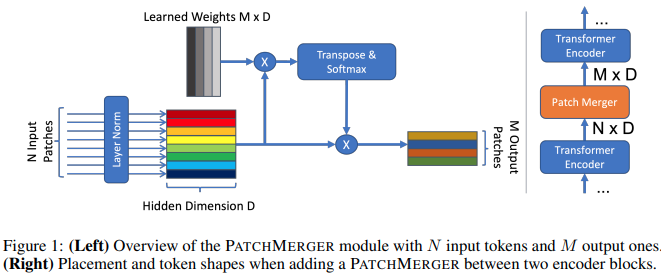
In diesem Artikel wird ein einfaches Modul (Patch Merger) vorgeschlagen, um die Anzahl der Token auf jeder Ebene eines Vision-Transformators zu reduzieren, ohne die Leistung zu beeinträchtigen.
import torch
from vit_pytorch . vit_with_patch_merger import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 ,
heads = 8 ,
patch_merge_layer = 6 , # at which transformer layer to do patch merging
patch_merge_num_tokens = 8 , # the output number of tokens from the patch merge
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000) Man kann das PatchMerger -Modul auch alleine verwenden
import torch
from vit_pytorch . vit_with_patch_merger import PatchMerger
merger = PatchMerger (
dim = 1024 ,
num_tokens_out = 8 # output number of tokens
)
features = torch . randn ( 4 , 256 , 1024 ) # (batch, num tokens, dimension)
out = merger ( features ) # (4, 8, 1024) 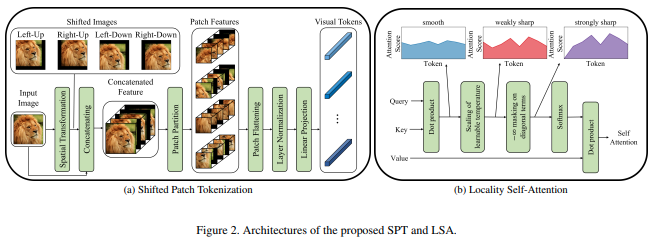
In diesem Artikel wird eine neue Bild-zu-Patch-Funktion vorgeschlagen, die Bildverschiebungen berücksichtigt, bevor das Bild normalisiert und in Patches unterteilt wird. Ich habe festgestellt, dass das Verschieben bei einigen anderen Transformatorenarbeiten äußerst hilfreich ist, und habe mich daher entschlossen, dies für weitere Untersuchungen einzubeziehen. Dazu gehört auch die LSA mit der erlernten Temperatur und der Ausblendung der Aufmerksamkeit eines Tokens auf sich selbst.
Sie können wie folgt verwenden:
import torch
from vit_pytorch . vit_for_small_dataset import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) Sie können das SPT aus diesem Dokument auch als eigenständiges Modul verwenden
import torch
from vit_pytorch . vit_for_small_dataset import SPT
spt = SPT (
dim = 1024 ,
patch_size = 16 ,
channels = 3
)
img = torch . randn ( 4 , 3 , 256 , 256 )
tokens = spt ( img ) # (4, 256, 1024) Auf vielfachen Wunsch werde ich damit beginnen, einige der Architekturen in diesem Repository auf 3D-ViTs für die Verwendung mit Video, medizinischer Bildgebung usw. zu erweitern.
Sie müssen zwei zusätzliche Hyperparameter übergeben: (1) die Anzahl der frames und (2) die Patchgröße entlang der Frame-Dimension frame_patch_size
Für den Anfang: 3D ViT
import torch
from vit_pytorch . vit_3d import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)3D einfaches ViT
import torch
from vit_pytorch . simple_vit_3d import SimpleViT
v = SimpleViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)3D-Version von CCT
import torch
from vit_pytorch . cct_3d import CCT
cct = CCT (
img_size = 224 ,
num_frames = 8 ,
embedding_dim = 384 ,
n_conv_layers = 2 ,
frame_kernel_size = 3 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable'
)
video = torch . randn ( 1 , 3 , 8 , 224 , 224 ) # (batch, channels, frames, height, width)
pred = cct ( video )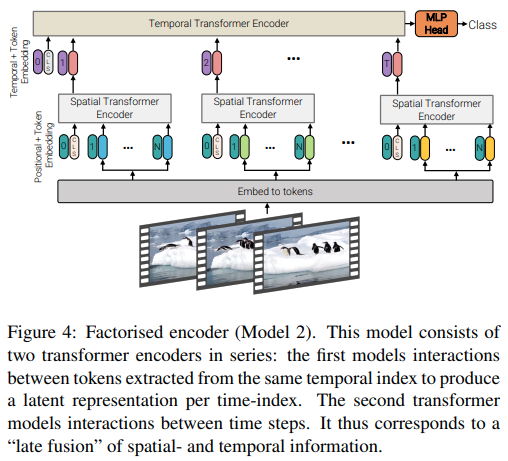
In diesem Artikel werden drei verschiedene Arten von Architekturen für die effiziente Aufmerksamkeit von Videos vorgestellt, wobei das Hauptthema darin besteht, die Aufmerksamkeit über Raum und Zeit hinweg zu faktorisieren. Dieses Repository umfasst den faktorisierten Encoder und die faktorisierte Selbstaufmerksamkeitsvariante. Die faktorisierte Encoder-Variante ist ein räumlicher Transformator, gefolgt von einem zeitlichen. Die faktorisierte Selbstaufmerksamkeitsvariante ist ein räumlich-zeitlicher Transformator mit abwechselnden räumlichen und zeitlichen Selbstaufmerksamkeitsschichten.
import torch
from vit_pytorch . vivit import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
spatial_depth = 6 , # depth of the spatial transformer
temporal_depth = 6 , # depth of the temporal transformer
heads = 8 ,
mlp_dim = 2048 ,
variant = 'factorized_encoder' , # or 'factorized_self_attention'
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000) 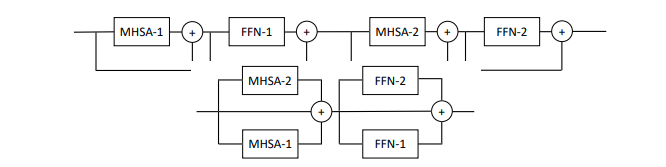
In diesem Artikel wird die Parallelisierung mehrerer Aufmerksamkeits- und Feedforward-Blöcke pro Schicht (2 Blöcke) vorgeschlagen und behauptet, dass es einfacher ist, ohne Leistungsverlust zu trainieren.
Sie können diese Variante wie folgt ausprobieren
import torch
from vit_pytorch . parallel_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
num_parallel_branches = 2 , # in paper, they claimed 2 was optimal
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000) 
Dieser Artikel zeigt, dass das Hinzufügen lernbarer Speichertokens auf jeder Ebene eines Vision-Transformators die Feinabstimmungsergebnisse erheblich verbessern kann (zusätzlich zu lernbaren aufgabenspezifischen CLS-Token und Adapterköpfen).
Sie können dies mit einem speziell modifizierten ViT wie folgt verwenden
import torch
from vit_pytorch . learnable_memory_vit import ViT , Adapter
# normal base ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
logits = v ( img ) # (4, 1000)
# do your usual training with ViT
# ...
# then, to finetune, just pass the ViT into the Adapter class
# you can do this for multiple Adapters, as shown below
adapter1 = Adapter (
vit = v ,
num_classes = 2 , # number of output classes for this specific task
num_memories_per_layer = 5 # number of learnable memories per layer, 10 was sufficient in paper
)
logits1 = adapter1 ( img ) # (4, 2) - predict 2 classes off frozen ViT backbone with learnable memories and task specific head
# yet another task to finetune on, this time with 4 classes
adapter2 = Adapter (
vit = v ,
num_classes = 4 ,
num_memories_per_layer = 10
)
logits2 = adapter2 ( img ) # (4, 4) - predict 4 classes off frozen ViT backbone with learnable memories and task specific head 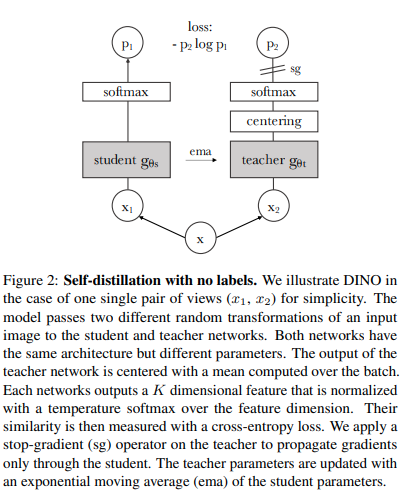
Sie können ViT mit der aktuellen selbstüberwachten Lerntechnik von SOTA, Dino, mit dem folgenden Code trainieren.
Yannic Kilcher-Video
import torch
from vit_pytorch import ViT , Dino
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
learner = Dino (
model ,
image_size = 256 ,
hidden_layer = 'to_latent' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )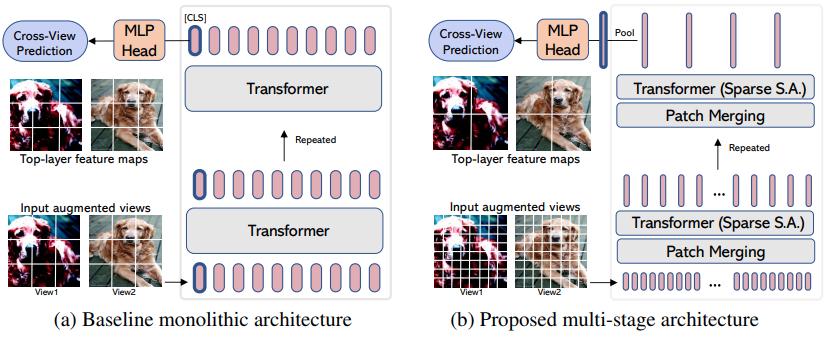
EsViT ist eine Variante von Dino (von oben), die überarbeitet wurde, um effiziente ViT mit Patch-Merging/Downsampling zu unterstützen, indem ein zusätzlicher regionaler Verlust zwischen den erweiterten Ansichten berücksichtigt wird. Um die Zusammenfassung zu zitieren: Es outperforms its supervised counterpart on 17 out of 18 datasets bei einem dreimal höheren Durchsatz.
Auch wenn der Name so aussieht, als wäre es eine neue ViT Variante, handelt es sich tatsächlich nur um eine Strategie zum Trainieren eines mehrstufigen ViT (im Artikel konzentrierten sie sich auf Swin). Das folgende Beispiel zeigt, wie es mit CvT verwendet wird. Sie müssen hidden_layer auf den Namen des Layers in Ihrem effizienten ViT setzen, der die nicht durchschnittlichen gepoolten visuellen Darstellungen ausgibt, unmittelbar vor dem globalen Pooling und der Projektion auf Logits.
import torch
from vit_pytorch . cvt import CvT
from vit_pytorch . es_vit import EsViTTrainer
cvt = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 ,
s1_emb_kernel = 7 ,
s1_emb_stride = 4 ,
s1_proj_kernel = 3 ,
s1_kv_proj_stride = 2 ,
s1_heads = 1 ,
s1_depth = 1 ,
s1_mlp_mult = 4 ,
s2_emb_dim = 192 ,
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 ,
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
learner = EsViTTrainer (
cvt ,
image_size = 256 ,
hidden_layer = 'layers' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . AdamW ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 8 , 3 , 256 , 256 )
for _ in range ( 1000 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( cvt . state_dict (), './pretrained-net.pt' )Wenn Sie die Aufmerksamkeitsgewichte (Post-Softmax) für Ihre Forschung visualisieren möchten, befolgen Sie einfach die nachstehende Vorgehensweise
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . recorder import Recorder
v = Recorder ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
preds , attns = v ( img )
# there is one extra patch due to the CLS token
attns # (1, 6, 16, 65, 65) - (batch x layers x heads x patch x patch)um die Klasse und die Hooks zu bereinigen, sobald Sie genügend Daten gesammelt haben
v = v . eject () # wrapper is discarded and original ViT instance is returned Sie können auf ähnliche Weise mit dem Extractor Wrapper auf die Einbettungen zugreifen
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # (1, 65, 1024) - (batch x patches x model dim) Oder sagen wir CrossViT , das über einen Multiskalen-Encoder verfügt, der zwei Einbettungssätze für „große“ und „kleine“ Skalen ausgibt
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 ,
sm_dim = 192 ,
sm_patch_size = 16 ,
sm_enc_depth = 2 ,
sm_enc_heads = 8 ,
sm_enc_mlp_dim = 2048 ,
lg_dim = 384 ,
lg_patch_size = 64 ,
lg_enc_depth = 3 ,
lg_enc_heads = 8 ,
lg_enc_mlp_dim = 2048 ,
cross_attn_depth = 2 ,
cross_attn_heads = 8 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# wrap the CrossViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v , layer_name = 'multi_scale_encoder' ) # take embedding coming from the output of multi-scale-encoder
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # ((1, 257, 192), (1, 17, 384)) - (batch x patches x dimension) <- large and small scales respectively Es mag einige aus dem Bereich Computer Vision geben, die glauben, dass die Aufmerksamkeit immer noch unter quadratischen Kosten leidet. Glücklicherweise verfügen wir über viele neue Techniken, die helfen können. Dieses Repository bietet Ihnen die Möglichkeit, Ihren eigenen Sparse-Attention-Transformator einzubinden.
Ein Beispiel mit Nystromformer
$ pip install nystrom-attention import torch
from vit_pytorch . efficient import ViT
from nystrom_attention import Nystromformer
efficient_transformer = Nystromformer (
dim = 512 ,
depth = 12 ,
heads = 8 ,
num_landmarks = 256
)
v = ViT (
dim = 512 ,
image_size = 2048 ,
patch_size = 32 ,
num_classes = 1000 ,
transformer = efficient_transformer
)
img = torch . randn ( 1 , 3 , 2048 , 2048 ) # your high resolution picture
v ( img ) # (1, 1000)Andere Frameworks mit geringer Aufmerksamkeit, die ich wärmstens empfehlen würde, sind Routing Transformer oder Sinkhorn Transformer
In diesem Artikel wurden absichtlich die einfachsten Aufmerksamkeitsnetzwerke genutzt, um eine Aussage zu machen. Wenn Sie einige der neuesten Verbesserungen für Aufmerksamkeitsnetze nutzen möchten, verwenden Sie bitte den Encoder aus diesem Repository.
ex.
$ pip install x-transformers import torch
from vit_pytorch . efficient import ViT
from x_transformers import Encoder
v = ViT (
dim = 512 ,
image_size = 224 ,
patch_size = 16 ,
num_classes = 1000 ,
transformer = Encoder (
dim = 512 , # set to be the same as the wrapper
depth = 12 ,
heads = 8 ,
ff_glu = True , # ex. feed forward GLU variant https://arxiv.org/abs/2002.05202
residual_attn = True # ex. residual attention https://arxiv.org/abs/2012.11747
)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
v ( img ) # (1, 1000) Sie können bereits nicht quadratische Bilder übergeben – Sie müssen nur sicherstellen, dass Ihre Höhe und Breite kleiner oder gleich der image_size sind und beide durch die patch_size teilbar sind
ex.
import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 ) # <-- not a square
preds = v ( img ) # (1, 1000) import torch
from vit_pytorch import ViT
v = ViT (
num_classes = 1000 ,
image_size = ( 256 , 128 ), # image size is a tuple of (height, width)
patch_size = ( 32 , 16 ), # patch size is a tuple of (height, width)
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 )
preds = v ( img )Kommen Sie von Computer Vision und sind neu bei Transformern? Hier sind einige Ressourcen, die mein Lernen erheblich beschleunigt haben.
Illustrierter Transformer – Jay Alammar
Transformers von Grund auf - Peter Bloem
Der kommentierte Transformator – Harvard NLP
@article { hassani2021escaping ,
title = { Escaping the Big Data Paradigm with Compact Transformers } ,
author = { Ali Hassani and Steven Walton and Nikhil Shah and Abulikemu Abuduweili and Jiachen Li and Humphrey Shi } ,
year = 2021 ,
url = { https://arxiv.org/abs/2104.05704 } ,
eprint = { 2104.05704 } ,
archiveprefix = { arXiv } ,
primaryclass = { cs.CV }
} @misc { dosovitskiy2020image ,
title = { An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale } ,
author = { Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby } ,
year = { 2020 } ,
eprint = { 2010.11929 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2020training ,
title = { Training data-efficient image transformers & distillation through attention } ,
author = { Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou } ,
year = { 2020 } ,
eprint = { 2012.12877 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yuan2021tokenstotoken ,
title = { Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet } ,
author = { Li Yuan and Yunpeng Chen and Tao Wang and Weihao Yu and Yujun Shi and Francis EH Tay and Jiashi Feng and Shuicheng Yan } ,
year = { 2021 } ,
eprint = { 2101.11986 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { zhou2021deepvit ,
title = { DeepViT: Towards Deeper Vision Transformer } ,
author = { Daquan Zhou and Bingyi Kang and Xiaojie Jin and Linjie Yang and Xiaochen Lian and Qibin Hou and Jiashi Feng } ,
year = { 2021 } ,
eprint = { 2103.11886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2021going ,
title = { Going deeper with Image Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alexandre Sablayrolles and Gabriel Synnaeve and Hervé Jégou } ,
year = { 2021 } ,
eprint = { 2103.17239 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021crossvit ,
title = { CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification } ,
author = { Chun-Fu Chen and Quanfu Fan and Rameswar Panda } ,
year = { 2021 } ,
eprint = { 2103.14899 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wu2021cvt ,
title = { CvT: Introducing Convolutions to Vision Transformers } ,
author = { Haiping Wu and Bin Xiao and Noel Codella and Mengchen Liu and Xiyang Dai and Lu Yuan and Lei Zhang } ,
year = { 2021 } ,
eprint = { 2103.15808 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { heo2021rethinking ,
title = { Rethinking Spatial Dimensions of Vision Transformers } ,
author = { Byeongho Heo and Sangdoo Yun and Dongyoon Han and Sanghyuk Chun and Junsuk Choe and Seong Joon Oh } ,
year = { 2021 } ,
eprint = { 2103.16302 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { graham2021levit ,
title = { LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference } ,
author = { Ben Graham and Alaaeldin El-Nouby and Hugo Touvron and Pierre Stock and Armand Joulin and Hervé Jégou and Matthijs Douze } ,
year = { 2021 } ,
eprint = { 2104.01136 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { li2021localvit ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and Kai Zhang and Jiezhang Cao and Radu Timofte and Luc Van Gool } ,
year = { 2021 } ,
eprint = { 2104.05707 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chu2021twins ,
title = { Twins: Revisiting Spatial Attention Design in Vision Transformers } ,
author = { Xiangxiang Chu and Zhi Tian and Yuqing Wang and Bo Zhang and Haibing Ren and Xiaolin Wei and Huaxia Xia and Chunhua Shen } ,
year = { 2021 } ,
eprint = { 2104.13840 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { zhang2021aggregating ,
title = { Aggregating Nested Transformers } ,
author = { Zizhao Zhang and Han Zhang and Long Zhao and Ting Chen and Tomas Pfister } ,
year = { 2021 } ,
eprint = { 2105.12723 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021regionvit ,
title = { RegionViT: Regional-to-Local Attention for Vision Transformers } ,
author = { Chun-Fu Chen and Rameswar Panda and Quanfu Fan } ,
year = { 2021 } ,
eprint = { 2106.02689 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wang2021crossformer ,
title = { CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention } ,
author = { Wenxiao Wang and Lu Yao and Long Chen and Binbin Lin and Deng Cai and Xiaofei He and Wei Liu } ,
year = { 2021 } ,
eprint = { 2108.00154 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { caron2021emerging ,
title = { Emerging Properties in Self-Supervised Vision Transformers } ,
author = { Mathilde Caron and Hugo Touvron and Ishan Misra and Hervé Jégou and Julien Mairal and Piotr Bojanowski and Armand Joulin } ,
year = { 2021 } ,
eprint = { 2104.14294 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { he2021masked ,
title = { Masked Autoencoders Are Scalable Vision Learners } ,
author = { Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Dollár and Ross Girshick } ,
year = { 2021 } ,
eprint = { 2111.06377 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { xie2021simmim ,
title = { SimMIM: A Simple Framework for Masked Image Modeling } ,
author = { Zhenda Xie and Zheng Zhang and Yue Cao and Yutong Lin and Jianmin Bao and Zhuliang Yao and Qi Dai and Han Hu } ,
year = { 2021 } ,
eprint = { 2111.09886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { fayyaz2021ats ,
title = { ATS: Adaptive Token Sampling For Efficient Vision Transformers } ,
author = { Mohsen Fayyaz and Soroush Abbasi Kouhpayegani and Farnoush Rezaei Jafari and Eric Sommerlade and Hamid Reza Vaezi Joze and Hamed Pirsiavash and Juergen Gall } ,
year = { 2021 } ,
eprint = { 2111.15667 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mehta2021mobilevit ,
title = { MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer } ,
author = { Sachin Mehta and Mohammad Rastegari } ,
year = { 2021 } ,
eprint = { 2110.02178 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { lee2021vision ,
title = { Vision Transformer for Small-Size Datasets } ,
author = { Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song } ,
year = { 2021 } ,
eprint = { 2112.13492 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { renggli2022learning ,
title = { Learning to Merge Tokens in Vision Transformers } ,
author = { Cedric Renggli and André Susano Pinto and Neil Houlsby and Basil Mustafa and Joan Puigcerver and Carlos Riquelme } ,
year = { 2022 } ,
eprint = { 2202.12015 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yang2022scalablevit ,
title = { ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer } ,
author = { Rui Yang and Hailong Ma and Jie Wu and Yansong Tang and Xuefeng Xiao and Min Zheng and Xiu Li } ,
year = { 2022 } ,
eprint = { 2203.10790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Touvron2022ThreeTE ,
title = { Three things everyone should know about Vision Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alaaeldin El-Nouby and Jakob Verbeek and Herv'e J'egou } ,
year = { 2022 }
} @inproceedings { Sandler2022FinetuningIT ,
title = { Fine-tuning Image Transformers using Learnable Memory } ,
author = { Mark Sandler and Andrey Zhmoginov and Max Vladymyrov and Andrew Jackson } ,
year = { 2022 }
} @inproceedings { Li2022SepViTSV ,
title = { SepViT: Separable Vision Transformer } ,
author = { Wei Li and Xing Wang and Xin Xia and Jie Wu and Xuefeng Xiao and Minghang Zheng and Shiping Wen } ,
year = { 2022 }
} @inproceedings { Tu2022MaxViTMV ,
title = { MaxViT: Multi-Axis Vision Transformer } ,
author = { Zhengzhong Tu and Hossein Talebi and Han Zhang and Feng Yang and Peyman Milanfar and Alan Conrad Bovik and Yinxiao Li } ,
year = { 2022 }
} @article { Li2021EfficientSV ,
title = { Efficient Self-supervised Vision Transformers for Representation Learning } ,
author = { Chunyuan Li and Jianwei Yang and Pengchuan Zhang and Mei Gao and Bin Xiao and Xiyang Dai and Lu Yuan and Jianfeng Gao } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09785 }
} @misc { Beyer2022BetterPlainViT
title = { Better plain ViT baselines for ImageNet-1k } ,
author = { Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander } ,
publisher = { arXiv } ,
year = { 2022 }
}
@article { Arnab2021ViViTAV ,
title = { ViViT: A Video Vision Transformer } ,
author = { Anurag Arnab and Mostafa Dehghani and Georg Heigold and Chen Sun and Mario Lucic and Cordelia Schmid } ,
journal = { 2021 IEEE/CVF International Conference on Computer Vision (ICCV) } ,
year = { 2021 } ,
pages = { 6816-6826 }
} @article { Liu2022PatchDropoutEV ,
title = { PatchDropout: Economizing Vision Transformers Using Patch Dropout } ,
author = { Yue Liu and Christos Matsoukas and Fredrik Strand and Hossein Azizpour and Kevin Smith } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.07220 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @inproceedings { Dehghani2023PatchNP ,
title = { Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution } ,
author = { Mostafa Dehghani and Basil Mustafa and Josip Djolonga and Jonathan Heek and Matthias Minderer and Mathilde Caron and Andreas Steiner and Joan Puigcerver and Robert Geirhos and Ibrahim M. Alabdulmohsin and Avital Oliver and Piotr Padlewski and Alexey A. Gritsenko and Mario Luvci'c and Neil Houlsby } ,
year = { 2023 }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @inproceedings { ElNouby2021XCiTCI ,
title = { XCiT: Cross-Covariance Image Transformers } ,
author = { Alaaeldin El-Nouby and Hugo Touvron and Mathilde Caron and Piotr Bojanowski and Matthijs Douze and Armand Joulin and Ivan Laptev and Natalia Neverova and Gabriel Synnaeve and Jakob Verbeek and Herv{'e} J{'e}gou } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2021 } ,
url = { https://api.semanticscholar.org/CorpusID:235458262 }
} @inproceedings { Koner2024LookupViTCV ,
title = { LookupViT: Compressing visual information to a limited number of tokens } ,
author = { Rajat Koner and Gagan Jain and Prateek Jain and Volker Tresp and Sujoy Paul } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:271244592 }
} @article { Bao2022AllAW ,
title = { All are Worth Words: A ViT Backbone for Diffusion Models } ,
author = { Fan Bao and Shen Nie and Kaiwen Xue and Yue Cao and Chongxuan Li and Hang Su and Jun Zhu } ,
journal = { 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 22669-22679 } ,
url = { https://api.semanticscholar.org/CorpusID:253581703 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Loshchilov2024nGPTNT ,
title = { nGPT: Normalized Transformer with Representation Learning on the Hypersphere } ,
author = { Ilya Loshchilov and Cheng-Ping Hsieh and Simeng Sun and Boris Ginsburg } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273026160 }
} @inproceedings { Liu2017DeepHL ,
title = { Deep Hyperspherical Learning } ,
author = { Weiyang Liu and Yanming Zhang and Xingguo Li and Zhen Liu and Bo Dai and Tuo Zhao and Le Song } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2017 } ,
url = { https://api.semanticscholar.org/CorpusID:5104558 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}Ich stelle mir eine Zeit vor, in der wir für Roboter das sein werden, was Hunde für Menschen sind, und ich feuere die Maschinen an. – Claude Shannon


