rtdl num embeddings
v0.0.11
Wichtig
Schauen Sie sich das neue tabellarische DL-Modell an: TabM
arXiv ? Python-Paket Andere tabellarische DL-Projekte
Dies ist die offizielle Umsetzung des Papiers „On Embeddings for Numerical Features in Tabular Deep Learning“.
In einem Satz: Die Umwandlung der ursprünglichen skalaren kontinuierlichen Merkmale in Vektoren vor dem Mischen im Haupt-Backbone (z. B. in MLP, Transformer usw.) verbessert die Downstream-Leistung tabellarischer neuronaler Netze.
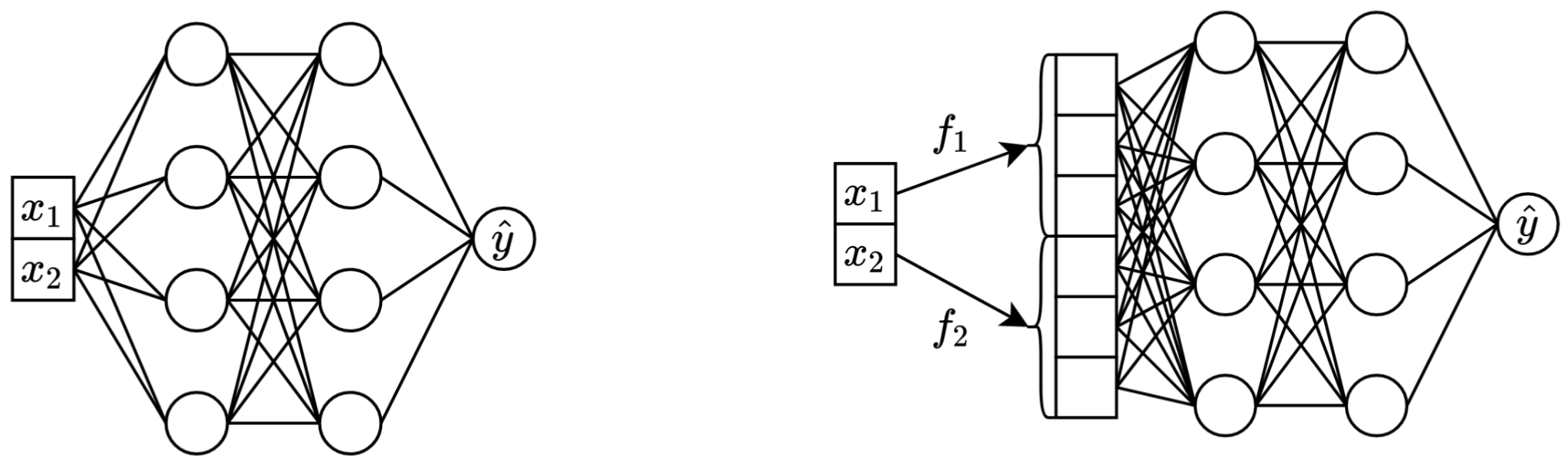
Links: Vanilla MLP mit zwei kontinuierlichen Features als Eingabe.
Rechts: das gleiche MLP, aber jetzt mit Einbettungen für kontinuierliche Funktionen.
Im Detail:
Streng genommen gibt es keine einheitliche Erklärung. Offensichtlich helfen die Einbettungen bei der Bewältigung verschiedener Herausforderungen im Zusammenhang mit kontinuierlichen Funktionen und verbessern die allgemeinen Optimierungseigenschaften von Modellen.
Insbesondere unregelmäßig verteilte kontinuierliche Merkmale (und ihre unregelmäßigen gemeinsamen Verteilungen mit Beschriftungen) sind in realen Tabellendaten üblich und stellen eine große grundlegende Optimierungsherausforderung für herkömmliche tabellarische DL-Modelle dar. Eine gute Referenz zum Verständnis dieser Herausforderung (und ein großartiges Beispiel für die Bewältigung dieser Herausforderungen durch Transformation des Eingaberaums) ist der Artikel „Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains“.
Es ist jedoch unklar, ob unregelmäßige Verteilungen der einzige Grund sind, warum die Einbettungen nützlich sind.
Das Python-Paket im Verzeichnis package/ ist die empfohlene Methode zur Verwendung des Dokuments in der Praxis und für zukünftige Arbeiten.
Der Rest des Dokuments :
Das exp/ -Verzeichnis enthält zahlreiche Ergebnisse und (abgestimmte) Hyperparameter für verschiedene Modelle und Datensätze, die in der Arbeit verwendet werden.
Lassen Sie uns beispielsweise die Metriken für das MLP-Modell untersuchen. Laden wir zunächst die Berichte (die report.json -Dateien):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])Berechnen wir nun für jeden Datensatz das über alle Zufallsstartwerte gemittelte Testergebnis:
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Die Ausgabe stimmt genau mit Tabelle 3 aus dem Papier überein:
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
Der obige Ansatz kann auch zur Untersuchung von Hyperparametern verwendet werden, um einen Eindruck von typischen Hyperparameterwerten für verschiedene Algorithmen zu erhalten. So kann man beispielsweise die mittlere abgestimmte Lernrate für das MLP-Modell berechnen:
Notiz
Für einige Algorithmen (z. B. MLP, MLP-LR, MLP-PLR) bieten neuere Projekte mehr Ergebnisse, die auf ähnliche Weise untersucht werden können. Sehen Sie sich zum Beispiel dieses Dokument zu TabR an.
Warnung
Verwenden Sie diesen Ansatz mit Vorsicht. Bei der Untersuchung von Hyperparameterwerten:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358Wichtig
Dieser Abschnitt ist lang. Verwenden Sie die „Outline“-Funktion auf GitHub in Ihrem Texteditor, um einen Überblick über diesen Abschnitt zu erhalten.
Vorrunden:
/usr/local/cuda-11.1/bin immer in Ihrer PATH Umgebungsvariablen enthalten ist export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddingsLIZENZ: Durch das Herunterladen unseres Datensatzes akzeptieren Sie die Lizenzen aller seiner Komponenten. Zusätzlich zu diesen Lizenzen führen wir keine neuen Beschränkungen ein. Das Quellenverzeichnis finden Sie im Artikel.
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tarDer folgende Code gibt die Ergebnisse für MLP im Datensatz „California Housing“ wieder. Die Pipeline für andere Algorithmen und Datensätze ist absolut gleich.
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
Der Abschnitt „Metriken“ zeigt, wie die erhaltenen Ergebnisse zusammengefasst werden.
Der Code ist wie folgt aufgebaut:
bintrain4.py für neuronale Netze (es implementiert alle Einbettungen und Backbones aus dem Papier)xgboost_.py für XGBoostcatboost_.py für CatBoosttune.py zum Tuningevaluate.py zur Auswertungensemble.py für Ensembledatasets.py wurde zum Erstellen der Datensatzaufteilungen verwendetsynthetic.py zum Generieren der synthetischen GBDT-freundlichen Datensätzetrain1_synthetic.py für die Experimente mit synthetischen Datenlib enthält allgemeine Tools, die von Programmen in bin verwendet werdenexp enthält Experimentkonfigurationen und Ergebnisse (Metriken, abgestimmte Konfigurationen usw.). Die Namen der verschachtelten Ordner folgen den Namen aus dem Papier (Beispiel: exp/mlp-plr entspricht dem MLP-PLR-Modell aus dem Papier).package enthält das Python-Paket für dieses DokumentCUDA_VISIBLE_DEVICES beim Ausführen von Skripten explizit festlegenlib.dump_config und lib.load_config anstelle von bloßen TOML-BibliothekenDas übliche Muster zum Ausführen von Skripten ist:
python bin/my_script.py a/b/c.toml Dabei ist a/b/c.toml die Eingabekonfigurationsdatei (config). Die Ausgabe befindet sich unter a/b/c . Die Konfigurationsstruktur folgt normalerweise der Config -Klasse aus bin/my_script.py .
Es gibt auch Skripte, die Befehlszeilenargumente anstelle von Konfigurationen verwenden (z. B. bin/{evaluate.py,ensemble.py} ).
Sie benötigen sie alle, um Ergebnisse zu reproduzieren, für zukünftige Arbeiten benötigen Sie jedoch nur train4.py , weil:
bin/train1.py implementiert eine Obermenge der Funktionen von bin/train0.pybin/train3.py implementiert eine Obermenge der Funktionen von bin/train1.pybin/train4.py implementiert eine Obermenge der Funktionen von bin/train3.py Um zu sehen, welches der vier Skripte zum Ausführen eines bestimmten Experiments verwendet wurde, überprüfen Sie das Feld „Programm“ der entsprechenden Tuning-Konfiguration. Hier ist beispielsweise die Tuning-Konfiguration für MLP im California Housing-Datensatz: exp/mlp/california/0_tuning.toml . Die Konfiguration gibt an, dass bin/train0.py verwendet wurde. Das bedeutet, dass die Konfigurationen in exp/mlp/california/0_evaluation speziell mit bin/train0.py kompatibel sind. Um dies zu überprüfen, können Sie einen davon an einen separaten Speicherort kopieren und an bin/train0.py übergeben:
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


