gigagan pytorch
0.2.20

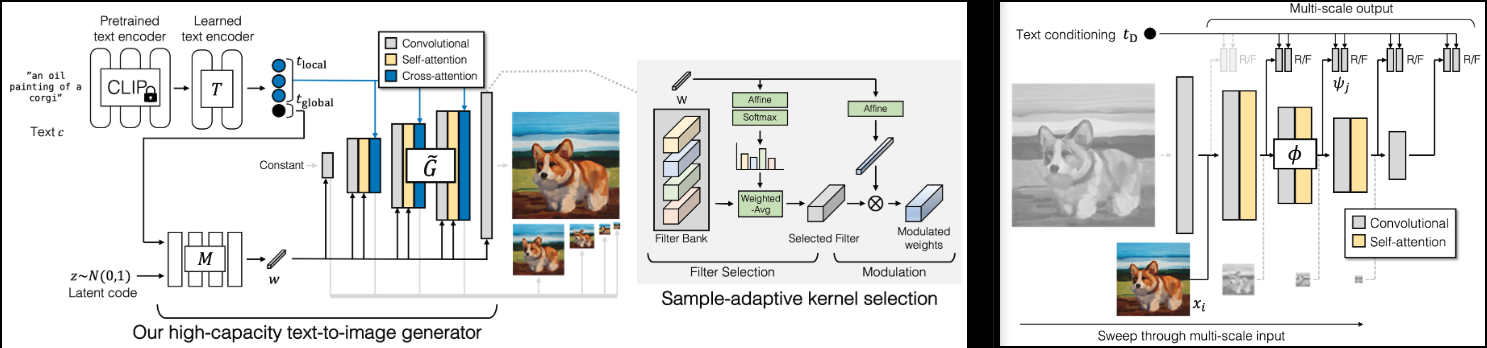
Implementierung von GigaGAN (Projektseite), neues SOTA GAN von Adobe.
Ich werde auch ein paar Erkenntnisse aus dem Lightweight-Gan hinzufügen, für schnellere Konvergenz (Skip-Layer-Anregung) und bessere Stabilität (Rekonstruktionshilfsverlust im Diskriminator).
Es wird auch den Code für die 1k-4k-Upsampler enthalten, was meiner Meinung nach das Highlight dieses Dokuments ist.
Bitte treten Sie bei, wenn Sie daran interessiert sind, bei der Replikation mit der LAION-Community mitzuhelfen
StabilitätAI und ? Huggingface für das großzügige Sponsoring und meine anderen Sponsoren dafür, dass sie mir die Unabhängigkeit im Umgang mit Open-Source-künstlicher Intelligenz ermöglicht haben.
? Huggingface für ihre Beschleunigungsbibliothek
Alle Betreuer von OpenClip für ihre SOTA-Open-Source-Text-Bild-Modelle zum kontrastiven Lernen
Xavier für die sehr hilfreiche Codeüberprüfung und für Diskussionen darüber, wie die Skaleninvarianz im Diskriminator aufgebaut werden sollte!
@CerebralSeed für die Pull-Anfrage des ersten Sampling-Codes sowohl für den Generator als auch für den Upsampler!
Keerth für die Codeüberprüfung und den Hinweis auf einige Unstimmigkeiten mit dem Papier!
$ pip install gigagan-pytorchEinfaches bedingungsloses GAN für den Anfang
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)Für bedingungslosen Unet-Upsampler
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G – GeneratorMSG – MultiskalengeneratorD – DiskriminatorMSD – MultiskalendiskriminatorGP – SteigungsstrafeSSL – Hilfsrekonstruktion im Diskriminator (von Lightweight GAN)VD – Vision-Aided DiscriminatorVG – Vision-Aided GeneratorCL – Kontrastverlust des GeneratorsMAL – Matching Aware Loss Ein gesunder Lauf hätte G , MSG , D , MSD mit Werten, die zwischen 0 und 10 schwanken und normalerweise ziemlich konstant bleiben. Wenn diese Werte zu irgendeinem Zeitpunkt nach 1.000 Trainingsschritten im dreistelligen Bereich bleiben, würde das bedeuten, dass etwas nicht stimmt. Es ist in Ordnung, dass die Generator- und Diskriminatorwerte gelegentlich ins Negative abfallen, aber sie sollten wieder in den oben genannten Bereich ansteigen.
GP und SSL sollten in Richtung 0 verschoben werden. GP kann gelegentlich ansteigen; Ich stelle es mir gerne so vor, als würden die Netzwerke eine Offenbarung erleben
Die GigaGAN -Klasse ist jetzt mit ? Beschleuniger. Mithilfe der accelerate -CLI können Sie ganz einfach ein Multi-GPU-Training in zwei Schritten durchführen
Führen Sie es im Stammverzeichnis des Projekts aus, in dem sich das Trainingsskript befindet
$ accelerate configDann im selben Verzeichnis
$ accelerate launch train . py Stellen Sie sicher, dass es bedingungslos trainiert werden kann
Lesen Sie die relevanten Papiere und eliminieren Sie alle drei Hilfsverluste
Unet-Upsampler
Holen Sie sich eine Codeüberprüfung für die Ein- und Ausgänge mit mehreren Maßstäben, da der Artikel etwas vage war
Fügen Sie eine Upsampling-Netzwerkarchitektur hinzu
Machen Sie sowohl für den Basisgenerator als auch für den Upsampler bedingungslose Arbeit
Sorgen Sie dafür, dass textkonditioniertes Training sowohl für die Basis als auch für den Upsampler funktioniert
Machen Sie die Aufklärung effizienter, indem Sie Patches nach dem Zufallsprinzip auswählen
Stellen Sie sicher, dass Generator und Diskriminator auch vorcodierte CLIP-Textcodierungen akzeptieren können
Führen Sie eine Überprüfung der Hilfsverluste durch
Fügen Sie einige differenzierbare Erweiterungen hinzu, eine bewährte Technik aus den alten GAN-Tagen
Verschieben Sie alle Modulationsprojektionen in die adaptive conv2d-Klasse
Beschleunigung hinzufügen
Clip sollte für alle Module optional sein und von GigaGAN verwaltet werden, wobei Text -> Texteinbettungen einmal verarbeitet werden
Fügen Sie aus Effizienzgründen die Möglichkeit hinzu, eine zufällige Teilmenge aus einer Multiskalendimension auszuwählen
Port über CLI von Lightweight|stylegan2-pytorch
Schließen Sie den Laion-Datensatz für Text-Bild an
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

