404 Wissensdatenbank nicht gefunden
Letzte Aktualisierung: 28.06.2020
In der letzten Woche neu hinzugefügt:
- [Paketierung und Veröffentlichung von Python-Projekten](# Tools)
Inhaltsverzeichnis:
- Computer-Grundlagen
- Grundlagen der Computertheorie
- Computernetzwerk
- Betriebssystem
- Datenstrukturen und Algorithmen
- Datenbank
- Grundlagen der Kryptographie
- Grundlagen der Computertechnik
- Sprache
- rahmen
- Werkzeug
- Technologie
- zugrunde liegende Forschung
- Sicherheit
- Sicherheitstechnik
- Schlupflöcher
- Websicherheit
- Penetrationstests
- Code-Audit
- Datensicherheit
- Cloud-Sicherheit
- Sicherheitstools
- Sicherheitsforschung
- APT-Erkennung
- Schädliche Proben
- Rotes Team
- WAF
- Erkennung bösartiger URLs
- Kampf gegen den Maschinenverkehr
- Anomalieerkennung
- Zahlen und Sicherheit
- KI und Sicherheit
- Sicherheitskonstruktion für Unternehmen
- Sichere Entwicklung
- Sicherheitstests
- Sicherheitsprodukte
- Sicherer Betrieb
- Sicherheitsmanagement
- Denken Sie sicher
- Sicherheitsarchitektur
- Konfrontation zwischen Rot und Blau
- Intranet-Sicherheit
- Datensicherheit
- Neue Technologie und neue Sicherheit
- Überblick
- Cloud-nativ
- Trusted Computing
- DevSecOps
- sichere Entwicklung
- persönliche Entwicklung
- Branchenentwicklung
- Daten
- Datensystem
- Datenanalyse und -operationen
- Analyse von Sicherheitsdaten
- Algorithmus
- KI
- Algorithmussystem
- Grundkenntnisse
- maschinelles Lernen
- tiefes Lernen
- Verstärkungslernen
- Anwendungsgebiete
- Branchenentwicklung
- Umfassende Qualität
- Beruf
- Karriereplanung
- Denken
- kommunizieren
- verwalten
- denken
- Dinge zu beachten
- Anhang
- Inländisches herausragendes technisches Personal
- Ausgezeichnete ausländische Technologiestandorte
- verlassen
Computer-Grundlagen
Grundlagen der Computertheorie
Betriebssystem
- [Computer Postgraduate Entrance Examination 408 ist die umfassendste im gesamten Netzwerk!!!!!] Kingly Computer Operating System
- Unterbrechungen und Ausnahmen
- Wie kann man Paging und Segmentierung der Speicherverwaltung im Betriebssystem auf einfache Weise verstehen?
Granularität, logische Informationseinheiten und physikalische Informationseinheiten, unbestimmte und deterministische Längen, zweidimensionale Adressen und eindimensionale Adressen, vollständige Informationen und diskrete Speicherzuweisung. - Zusammenfassung des Kernel-Status und des Benutzerstatus des Betriebssystems
- Zusammenstellung häufiger Interviewfragen zum Betriebssystem (ein Muss für jeden Entwickler)
Computernetzwerk
- Zusammenstellung häufiger Interviewfragen – Computernetzwerk (ein Muss für jeden Entwickler)
Der Unterschied zwischen TCP und UDP, TCP-Drei-Wege-Handshake und Vier-Wege-Welle, der Prozess nach Eingabe der URL durch den Browser, der Anforderungstyp des HTTP-Protokolls, der Unterschied zwischen GET und POST, ARP-Adressauflösungsprotokoll - Ein vollständiger Browser-Anforderungsprozess (Browser, HTTP) umfasst eine Reihe von Prozessen wie den TCP-Drei-Wege-Handshake, z. B. die Auflösung von Domänennamen, das Initiieren des TCP-Drei-Wege-Handshakes, das Initiieren einer HTTP-Anfrage und die Reaktion des Servers auf eine HTTP-Anfrage , und der Browser erhält den HTML-Code und der Browser analysiert den HTML-Code und fordert die Ressourcen im HTML-Code an. Der Browser rendert die Seite und präsentiert sie dem Benutzer.
- Was genau bedeutet die Zuverlässigkeit von TCP? - Antwort von CYS - Zhihu
Die Zuverlässigkeit von TCP bezieht sich auf die Bereitstellung zuverlässiger Datenübertragungsdienste auf der Transportschicht basierend auf der unzuverlässigen IP-Schicht. Dies bedeutet hauptsächlich, dass die Daten nicht beschädigt werden oder verloren gehen und alle Daten in der Reihenfolge übertragen werden, in der sie gesendet wurden. Die folgenden Mechanismen werden verwendet, um eine zuverlässige Übertragung von TCP zu erreichen: Prüfsumme (um zu überprüfen, ob die Daten beschädigt sind), Timer (Neuübertragung, wenn das Paket verloren geht), Sequenznummer (wird zur Erkennung verlorener Pakete und redundanter Pakete verwendet), Bestätigung (Empfänger informieren). dem Absender, dass ein Paket korrekt empfangen wurde und das nächste Paket erwartet wird), negative Bestätigung (der Empfänger benachrichtigt den Absender über ein Paket, das nicht korrekt empfangen wurde), Fenster und Pipelining (wird verwendet, um den Durchsatz des Kanals zu erhöhen).
Datenstrukturen und Algorithmen
- Algorithmus 3: Die am häufigsten verwendete Sortierung – schnelle Sortierung
Sortieren und schnelles Sortieren besteht darin, Löcher zu graben und Zahlen einzugeben + zu dividieren und zu erobern. - Eine Tencent-Interviewfrage: Meine Tasse ist so großartig (ich habe es gelernt)
Problemlösungsmethode 1: Halbierungsmethode; Problemlösungsmethode 2: segmentierte Suchintervallmethode 3: Methode basierend auf mathematischen Gleichungen 4: dynamische Programmiermethode (gelernt), beschrieben durch die Formel: W(n, k) = 1 + min{max(W(n -1, x -1), W(n, k - x))}, x in {2, 3, ……,k} (n ist eine Tassenzahl, k ist die Anzahl der Böden) - Wie man Algorithmusfragen effektiv schreibt
Die Fragen zu LeetCode sind grob in drei Typen unterteilt: Untersuchen Sie Datenstrukturen: wie verknüpfte Listen, Stapel, Warteschlangen, Hash-Tabellen, Diagramme, Versuche, Binärbäume usw.; untersuchen Sie grundlegende Algorithmen: wie Tiefe zuerst, Breite zuerst, binär Suche, Rekursion usw.; Untersuchen Sie grundlegende algorithmische Ideen: Rekursion, Teile und Herrsche, Backtracking-Suche, gierige und dynamische Programmierung. - Eine kurze Diskussion darüber, was der Divide-and-Conquer-Algorithmus ist (gelernt)
Vollständiges Permutationsproblem, Zusammenführungssortierungsproblem, Schnellsortierungsproblem und Turm-von-Hanoi-Problem unter der Idee des Teilens und Eroberns. - 2018.08 Im Vorstellungsgespräch die k-größte Zahl im ungeordneten Array, der Median im ungeordneten Array: schneller Sortierzeiger, O(N).
- [Video-Erklärung] LeetCode-Problem Nr. 1: Die Summe zweier Zahlen
- Strategien, um bei Jahrestagungen rote Umschläge zu ergattern
Grundlagen der Kryptographie
- Ausführliche Erläuterung der Vor- und Nachteile der symmetrischen Verschlüsselung und der asymmetrischen Verschlüsselung. Die symmetrische Verschlüsselung wird auch als Single-Key-Verschlüsselung bezeichnet. Zu den Algorithmen gehören: AES, RC4, 3DES. Es ist schnell und kann verwendet werden, wenn eine große Datenmenge verschlüsselt werden muss. Der Rechenaufwand ist gering und die Effizienz hoch. Wenn der geheime Schlüssel einer Partei preisgegeben wird, ist die gesamte Verschlüsselung unsicher. Asymmetrische Verschlüsselung, Algorithmen umfassen RSA, DSA/DSS, langsam und hochsicher. Zu den Hash-Algorithmen gehören MD5, SHA1 und SHA256. Drei Arten von Algorithmen bilden die Grundlage der HTTPS-Kommunikation .
Datenbank
- Tencent-Interview: Was sind die Gründe, warum eine SQL-Anweisung langsam ausgeführt wird?
Ergänzendes Lernen : Datenbank-Engine (InnoDB unterstützt Transaktionsverarbeitung und Fremdschlüssel, ist jedoch langsamer, ISAM und MyISAM verbrauchen wenig Platz und Speicher und fügen Daten schnell ein), Datenbankcodierung ( character_set_client、character_set_connection、character_set_database、character_set_results、character_set_server、character_set_system ), Datenbank Index (Primärschlüsselindex, Clustered-Index und Nicht-Clustered-Index) und andere grundlegende Wissenspunkte.
Die Gründe, warum eine SQL-Anweisung langsam ausgeführt wird, lassen sich in zwei Kategorien einteilen: 1) In den meisten Fällen normal, gelegentlich sehr langsam: (1) Die Datenbank aktualisiert fehlerhafte Seiten, z. B. bei Redo Wenn das Protokoll voll ist, muss es mit der Festplatte synchronisiert werden. (2) Während der Ausführung treten Sperren auf, z. B. Tabellensperren und Zeilensperren. 2) Es ist immer langsam: (1) Der Index wird nicht verwendet: zum Beispiel , das Feld hat keinen Index; Der Index kann aufgrund von Berechnungen und Funktionsoperationen nicht verwendet werden. (2) Der falsche Index wurde aus dem Clustered-Index ausgewählt und Die direkte vollständige Tabellensuche Es ist möglich, dass das Stichprobenproblem falsch eingeschätzt wird und ein vollständiger Tabellenscan durchgeführt wird. - Dies ist wahrscheinlich die umfassendste SQL-Optimierungslösung
Grundlagen der Computertechnik
Sprache
- Eine ausführliche Analyse von Python-Dekoratoren in einem 10.000 Wörter langen Artikel
- Python3-Iteratoren und -Generatoren
Python : Iteratoren verfügen über zwei grundlegende Methoden: iter() und next(). Iterierbare Objekte wie Zeichenfolgen, Tupel und Listen können zum Erstellen von Iteratoren verwendet werden (dies liegt daran, dass diese Klassen die Funktion __iter__() intern implementieren. Nach dem Aufruf von iter(). , es wird zu einem list_iterator Objekt, Sie werden feststellen, dass __iter__ __next__() __next__ wurden. Der Iterator ist ein zustandsbehaftetes Objekt. Es ist praktisch, die Position der aktuellen Iteration aufzuzeichnen Erhalten Sie bei der nächsten Iteration die richtigen Elemente. __iter__ gibt den Iterator selbst zurück __next__ gibt den nächsten Wert im Container zurück. Generator: Eine Funktion, die Yield verwendet, wird als Generator bezeichnet. Wenn eine Generatorfunktion aufgerufen wird, wird ein Iteratorobjekt zurückgegeben. Der Generator kann als Iterator betrachtet werden. - Python-Black-Technologie-Iterator, Generator, Dekorateur
- Wie viel wissen Sie über die erweiterten Funktionen von Python? Vergleichen wir
Python : Anonyme Lambda-Funktion. Die Funktion dient zum Ausführen einiger einfacher Ausdrücke oder Operationen, ohne die Funktion vollständig zu definieren. Die Map-Funktion ist eine integrierte Python-Funktion, die Funktionen auf Elemente in verschiedenen Datenstrukturen anwenden kann Map-Funktion, gibt aber nur Elemente zurück, für die die angewendete Funktion True zurückgibt. Das Itertools-Modul ist eine Sammlung von Tools zur Verarbeitung von Iteratoren, bei denen es sich um einen Datentyp handelt, der in for-Schleifenanweisungen verwendet werden kann . - Warum Go-Sprache verwenden? Was sind die Vorteile der Go-Sprache?
Go : Die Vorteile von Go und die Einsatzmöglichkeiten von Go. Zu den Hauptvorteilen von Go gehören: statische Sprache, mehrere Parallelität, plattformübergreifend, direkte Kompilierung in Maschinencode, umfangreiche Standardbibliothek usw. Zu den Hauptanwendungen von Go gehören Serverprogrammierung, Netzwerkprogrammierung, verteilte Systeme, In-Memory-Datenbanken und Cloud-Plattformen. - Gin-Übungsreihe – Golang-Einführung und Umgebungsinstallation
Go : Go-Umgebungsinstallation, die Bedeutung jedes Ordners nach der Installation der Umgebung; Go-Arbeitsbereich, die Bedeutung jedes Ordners im Arbeitsbereich. - ruby-on-rails – Was ist der Unterschied zwischen Ruby und JRuby?
Ruby : Ruby ist eine Programmiersprache, auf die wir uns im Allgemeinen beziehen. CRuby wird in der lokalen C-Sprachinterpreterumgebung ausgeführt.
rahmen
- Gin – Einführung und Verwendung des leistungsstarken Golang-Webframeworks
Gin : ist ein in Go geschriebenes Webanwendungs-Framework. - Was ist der Unterschied zwischen Spring Boot und Spring MVC?
Spring -> Spring MVC -> Spring Boot.
Werkzeug
- Vergleich zwischen Funke und Sturm
Big-Data-Technologietools – Computertyp : Vergleichen Sie die Aspekte Echtzeit-Computing-Modell, Echtzeit-Computing-Latenz, Durchsatz, Transaktionsmechanismus, Robustheit/Fehlertoleranz, dynamische Anpassung der Parallelität usw. Spark-Streaming ist ein Quasi-Echtzeitmodell. Es sammelt Daten innerhalb eines bestimmten Zeitraums und verarbeitet sie als RDD. Die Echtzeitberechnungsverzögerung ist auf zweiter Ebene und weist einen hohen Durchsatz auf. Es unterstützt Transaktionsmechanismen, ist aber nicht vollständig . Es ist durchschnittlich robust und unterstützt keine Dynamik. Storm ist ein reines Echtzeitmodell. Die Echtzeitberechnungsverzögerung ist gering. Es unterstützt einen vollständigen Transaktionsmechanismus, ist äußerst robust und unterstützt die dynamische Anpassung des Parallelitätsgrads. Anwendungsszenarien : Storm kann in Szenarien verwendet werden, in denen reine Echtzeit keine Verzögerungen von mehr als 1 Sekunde tolerieren kann, für Echtzeit-Rechenfunktionen, die zuverlässige Transaktionsmechanismen und Zuverlässigkeitsmechanismen erfordern, das heißt, die Datenverarbeitung ist völlig genau, Storm kann dies auch Wenn Sie auch die Parallelität von Echtzeit-Computing-Programmen während Spitzen- und Niedriglastzeiten dynamisch anpassen müssen, können Sie auch Storm in Betracht ziehen, wenn es sich bei dem Projekt um reines Echtzeit-Computing handelt um interaktive SQL-Abfragen in der Mitte auszuführen usw. Für andere Vorgänge ist die Verwendung von Storm die bessere Wahl. Wenn Sie hingegen keine reinen Echtzeit-Transaktionsmechanismen oder dynamische Anpassung der Parallelität benötigen, können Sie Spark-Streaming in Betracht ziehen Makroperspektive des Projekts: Wenn nicht nur Echtzeit-Computing erforderlich ist, sind auch Offline-Stapelverarbeitung und interaktive Abfragen erforderlich. Bei Echtzeitberechnungen sind auch Stapelverarbeitung mit hoher Latenz, interaktive Abfragen und andere Funktionen erforderlich Verwenden Sie Spark Core, um die Offline-Stapelverarbeitung zu entwickeln, und Spark SQL, um interaktive Abfragen zu entwickeln Streaming entwickelt Echtzeit-Computing, lässt sich nahtlos integrieren und bietet eine hohe Skalierbarkeit für das System. Diese Funktion erweitert die Vorteile von Spark Streaming erheblich. Die beiden Frameworks eignen sich gut für unterschiedliche Segmentierungsszenarien. - Ziyu Big Data Spark Erste Schritte-Tutorial (Python-Version) (wichtiger)
- Welche Unterschiede und Zusammenhänge gibt es zwischen den Protokollsammelsystemen Flume und Kafka? Wann werden sie jeweils eingesetzt und wann können sie kombiniert werden?
Big-Data-Technologietools – Middleware-Typ : Kafka kann als Middleware, Cache-System oder Datenbank verstanden werden. Seine Hauptfunktion besteht darin, die Stabilität aufrechtzuerhalten. Flume kann als aktive Sammlung von Protokolldaten verstanden werden. Im Vergleich zu Kafka ist es schwierig, die Online-Anwendungsänderungsschnittstelle zum Schreiben von Daten in Kafka zu fördern. - Welche Vor- und Nachteile haben Logstash und Flume und für welche Szenarien eignen sie sich?
Big-Data-Technologie-Tools – Agententyp : Abhängig von den Anforderungen gibt es sowohl Logstash als auch Flume als Agenten. Logstash verfügt über mehr Plug-Ins und besser unterstützende Produkte wie Elasticsearch, aber die Entwicklungssprache von Logstash ist Ruby und die Betriebsumgebung ist es auch JRuby. Darüber hinaus gibt es einen Mechanismus innerhalb von Flume, der sicherstellt, dass eine bestimmte Datenmenge verlustfrei übertragen wird. Die Entwicklungssprache von Flume ist jedoch einfach dass die JVM viel Speicher beansprucht. - Liste der Mac-Tastenkombinationen
MAC : Grundlegende Tastenkombinationen: Screenshots, in Anwendungen, Textverarbeitung, im Finder, in Browsern; Tastenkombinationen zum Starten und Herunterfahren des MAC. - Häufig verwendete Git-Befehlsblätter
Git : Remote-Warehouse-"Lokales Warehouse->Staging-Bereich-"Workspace, git add., git commit -m message, git push. - git-lfs
Git-lfs : Git-Tool zur Erweiterung des Hochladens großer Dateien. - tshark PCAP-Paket für statistische Analyse
- [Paketierung und Veröffentlichung von Python-Projekten](# Tools)
Notiz : 1. setup.py: long_description und long_description_content_type (beachten Sie die Probleme beim Rendern des MD- und RST-Formats). 2. manifest.in vs. gitignore. 3. readme.rst vs. readme.md. 4. .pypirc vs. gitconfig. 5. Python setup.py bdist_wheel hochladen.
Technologie
- Dekodierung und XSS ( es gibt einen
\u72 im Originaltext „nach der HTML-Entitätskodierung“ sollte sein -
Browser-Technologie-Dekodierungssequenz : Die Browser-Dekodierung umfasst hauptsächlich zwei Teile: Rendering-Engine und JS-Parser. Dekodierungsreihenfolge: Die Dekodierung wird in jeder Umgebung durchgeführt. Die Dekodierungsreihenfolge ist: Die der äußersten Umgebung entsprechende Kodierung wird zuerst dekodiert. Beispiel: Bei <a href=javascript:alert(1)>click</a> befindet sich warning(1) in der Umgebung html->url->js. 1. Klicken Sie auf die Unicode-Kodierung e, die nicht in HTML- oder URL-Umgebungen dekodiert werden kann. Sie kann nur in der JS-Umgebung in das Zeichen e dekodiert werden, sodass kein Popup-Fenster angezeigt wird.
2. Klicken Sie auf URL-Kodierung verwenden. Vor der Ausführung von js wird die URL %65 dekodiert. Wenn die js-Engine startet, sehen Sie die vollständige Warnung (1).
3. Klicken Sie auf „HTML-Entity-Dekodierung wird zuerst ausgeführt“.
4. Klicken Sie auf: Beim URL-Dekodierungsprozess wird JavaScript nicht als Pseudoprotokoll betrachtet und es treten Fehler auf.
5. Klicken Sie, um den HTML-Parser vor dem JavaScript-Parser auszuführen. Der Parsing-Prozess besteht also darin, dass die Zeichen des HTML-Codes zuerst dekodiert werden und dann das JavaScript-Ereignis ausgeführt wird.
Die Browser-Dekodierungsreihenfolge ist die Grundlage für die Umgehung in XSS . - Die Beziehung zwischen Dockerfile und Docker-Compose
Docker-Technologie : die Beziehung zwischen Dateien und Ordnern. - Was ist der Unterschied zwischen Dockerfile und Docker-Compose?
Docker-Technologie : Docker-Compose dient zur Orchestrierung von Containern. - Was ist eine Bastionsmaschine?
Bastion-Host-Technologie : Definiert einen Eingang für den Zugriff auf den Cluster; erleichtert die Berechtigungskontrolle und Überwachung. - Unter welchen Aspekten muss die Machbarkeit eines Produkts analysiert werden?
Machbarkeitsanalyse : Die Produktmachbarkeit wird unterteilt in: technische Machbarkeit, wirtschaftliche Machbarkeit und soziale Machbarkeit. Dabei konzentriere ich mich auf die technische Machbarkeit. Die technische Machbarkeit wird hauptsächlich anhand des Vergleichs von Wettbewerbsfunktionen, technischen Risiken und Vermeidungsmethoden, Benutzerfreundlichkeit und Benutzerschwelle, Abhängigkeit der Produktumgebung usw. gemessen. - Welche Rollen spielen Nginx und Gunicorn auf dem Server?
Anwendungsserver : Nginx-Bereitstellungsszenario: Lastausgleich (Frameworks wie Tornado unterstützen nur einen einzelnen Kern, daher erfordert die Bereitstellung mit mehreren Prozessen einen umgekehrten Lastausgleich. Gunicorn selbst ist ein Multiprozess und benötigt ihn nicht), statische Dateiunterstützung, Anti-Parallelitätsdruck , zusätzliche Zugangskontrolle. - Wikipedia: Kerberos
Kerberos : Grundlegende Beschreibung, Protokollinhalt und spezifischer Prozess von Kerberos. - Die Beziehung zwischen Dockerfile und Docker-Compose
Docker-Technologie : die Beziehung zwischen Dateien und Ordnern. - Was ist der Unterschied zwischen Dockerfile und Docker-Compose?
Docker-Technologie : Docker-Compose dient der Orchestrierung von Containern. - Was ist eine Bastionsmaschine?
Bastion-Host-Technologie : Definiert einen Eingang für den Zugriff auf den Cluster; erleichtert die Berechtigungskontrolle und Überwachung. - Unter welchen Aspekten muss die Machbarkeit eines Produkts analysiert werden?
Machbarkeitsanalyse : Die Produktmachbarkeit wird unterteilt in: technische Machbarkeit, wirtschaftliche Machbarkeit und soziale Machbarkeit. Dabei konzentriere ich mich auf die technische Machbarkeit. Die technische Machbarkeit wird hauptsächlich anhand des Vergleichs von Wettbewerbsfunktionen, technischen Risiken und Vermeidungsmethoden, Benutzerfreundlichkeit und Benutzerschwelle, Abhängigkeit der Produktumgebung usw. gemessen. - Welche Rollen spielen Nginx und Gunicorn auf dem Server?
Anwendungsserver : Nginx-Bereitstellungsszenario: Lastausgleich (Frameworks wie Tornado unterstützen nur einen einzelnen Kern, daher erfordert die Bereitstellung mit mehreren Prozessen einen umgekehrten Lastausgleich. Gunicorn selbst ist ein Multiprozess und benötigt ihn nicht), statische Dateiunterstützung, Anti-Parallelitätsdruck , zusätzliche Zugangskontrolle. - Wikipedia: Kerberos
Kerberos : Grundlegende Beschreibung, Protokollinhalt und spezifischer Prozess von Kerberos. - Was ist Microservices-Architektur**?
- Was ist Service Mesh (Service Mesh)
Microservice-Architektur : Warum: Warum ein Service-Mesh verwenden? Unter der traditionellen dreistufigen MVC-Webanwendungsarchitektur ist die Kommunikation zwischen Diensten nicht kompliziert und kann innerhalb der Anwendung verwaltet werden. Bei den heutigen komplexen, großen Websites sind jedoch einzelne Anwendungen in zahlreiche Abhängigkeiten und Kommunikation zwischen Diensten zerlegt Komplex. Was: Service Mesh ist die Infrastrukturschicht für die Kommunikation zwischen Diensten. Sie kann mit TCP/IP zwischen Anwendungen oder Mikrodiensten verglichen werden. Sie ist für Netzwerkaufrufe, Strombegrenzung, Leitungsunterbrechung und Überwachung verantwortlich. Funktionen von Service Mesh: mittlere Schicht für die Kommunikation zwischen Anwendungen, leichter Netzwerk-Proxy, anwendungsunabhängig, entkoppelte Anwendungswiederholungen/Timeouts, Überwachung, Nachverfolgung und Diensterkennung. Derzeit beliebte Open-Source-Software sind Istio und Linkerd, die beide in die Cloud Native Kubernetes-Umgebung integriert werden können. - Der Updater schlägt fehl, wenn er nicht als Administrator ausgeführt wird, selbst bei einer Benutzerinstallation
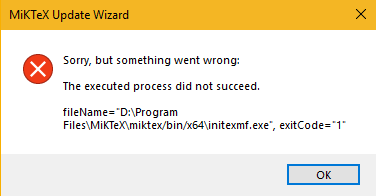
LaTeX : MiKTeX (Registrierungsproblem und Administratorrechteproblem) + TeXnicCenter (PDF-Problem kann nicht generiert werden, legen Sie den Adobe-Ausführungspfad in Build auf Original AcroRd32.exe fest) + Adobe Acrobat Reader DC und verwenden Sie dann die gecrackte Version von Adobe Acrobat DC zum Konvertieren zu anderen Formaten. - HTTPS-Prinzip und Interaktionsprozess
HTTPS : HTTPS erfordert einen Handshake zwischen dem Browser und der Website, bevor Daten übertragen werden. Während des Handshake-Vorgangs werden die von beiden Parteien zum Verschlüsseln der übertragenen Daten verwendeten Passwortinformationen bestätigt. Erhalten Sie den öffentlichen Schlüssel -> Der Browser generiert einen zufälligen (symmetrischen) geheimen Schlüssel -> Verwenden Sie den öffentlichen Schlüssel zum Verschlüsseln des symmetrischen geheimen Schlüssels -> Senden Sie den verschlüsselten symmetrischen geheimen Schlüssel -> Chiffretextkommunikation, die mit dem symmetrischen geheimen Schlüssel verschlüsselt ist. Der gesamte Prozess der HTTPS-Kommunikation verwendet symmetrische Verschlüsselung, asymmetrische Verschlüsselung und HASH-Algorithmen . - Die Same-Origin-Richtlinie des Browsers
Browser-Technologie : Die Same-Origin-Richtlinie ist die wichtigste und grundlegendste Sicherheitsfunktion des Browsers. Die Same-Origin-Richtlinie ist definiert als: Protokoll/Host/Port. - Neun domänenübergreifende Implementierungsprinzipien (Vollversion)
Browser-Technologie : domänenübergreifende Anforderungslösungen: JSONP (Schwachstellen, die auf Skript-Tags ohne domänenübergreifende Einschränkungen basieren), CORS (domänenübergreifende Ressourcenfreigabe), postMessage, Websocket, Node-Middleware-Proxy, Nginx-Reverse-Proxy, Windows.name+iframe , location.hash+iframe, document.domain+iframe.
CORS unterstützt alle Arten von HTTP-Anfragen und ist die grundlegende Lösung für domänenübergreifende HTTP-Anfragen. JSONP unterstützt nur GET-Anfragen. Der Vorteil besteht darin, dass es alte Browser unterstützt und Daten von Websites anfordern kann, die CORS nicht unterstützen. Unabhängig davon, ob es sich um einen Node-Middleware-Proxy oder einen Nginx-Reverse-Proxy handelt, besteht der Hauptgrund darin, dem Server durch die Same-Origin-Richtlinie keine Einschränkungen aufzuerlegen. In der täglichen Arbeit sind CORS und Nginx Reverse Proxy die am häufigsten verwendeten domänenübergreifenden Lösungen. - Wie verwende ich die virtuelle Python-Umgebung in Jupyter Notebook?
Anaconda : Plug-Ins installieren, Conda installiert nb_conda - Warum sollten RPC-Aufrufe verwendet werden, da es HTTP-Anfragen gibt? - Die Antwort von Bruder Yi
RPC : Erholsam VS RPC. RPC umfasst: Reverse-Proxy, Serialisierung und Deserialisierung, Kommunikation (HTTP, TCP, UDP), Ausnahmebehandlung
zugrunde liegende Forschung
Eine kurze Analyse des Prozesses der Python-Anforderungsbibliothek
Python fordert die Bibliotheksimplementierung an : socket->httplib->urllib->urllib3->requests. Der interne Aufrufprozess von request.get: request.get->requests()->Session.request->Session.send->adapter.send->HTTPConnectionPool(urllib3)->HTTPConnection(httplib).
1、socket:是TCP/IP最直接的实现,实现端到端的网络传输
2、httplib:基于socket库,是最基础最底层的http库,主要将数据按照http协议组织,然后创建socket连接,将封装的数据发往服务端
3、urllib:基于httplib库,主要对url的解析和编码做进一步处理
4、urllib3:基于httplib库,相较于urllib更高级的地方在于用PoolManager实现了socket连接复用和线程安全,提高了效率
5、requests:基于urllib3库,比urllib3更高级的是实现了Session对象,用Session对象保存一些数据状态,进一步提高了效率
Analyse der XGBoost-Prinzipien und der zugrunde liegenden Implementierung (gelernt)
XGBoost : Verstehen Sie aus der Perspektive der Bewertung des Baums (objektive Funktion: Verlustfunktion (Erweiterung zweiter Ordnung) + regulärer Term) die Struktur des Baums (geteilte Entscheidung (Vorsortierung)).
Vertiefendes Verständnis des Lightgbm-Histogrammoptimierungsalgorithmus
Lightgbm : Im Vergleich zur Vorsortierung verwendet lgb ein Histogramm, um die Knotenaufteilung zu handhaben und den optimalen Aufteilungspunkt zu finden. Algorithmusidee: Konvertieren Sie Merkmalswerte vor dem Training im Voraus in Bin-Werte, dh erstellen Sie eine stückweise Funktion für den Wert jedes Merkmals und teilen Sie die Werte aller Stichproben für dieses Merkmal in ein bestimmtes Segment (Bin) auf. Und schließlich werden Merkmalswerte von kontinuierlichen Werten in diskrete Werte umgewandelt. Histogramme können auch für die Differenzbeschleunigung verwendet werden. Die Komplexität der Berechnung des Histogramms basiert auf der Anzahl der Eimer.
Keras-Textvorverarbeitungs-Quellcode-Analyse
Keras - Textvorverarbeitung : 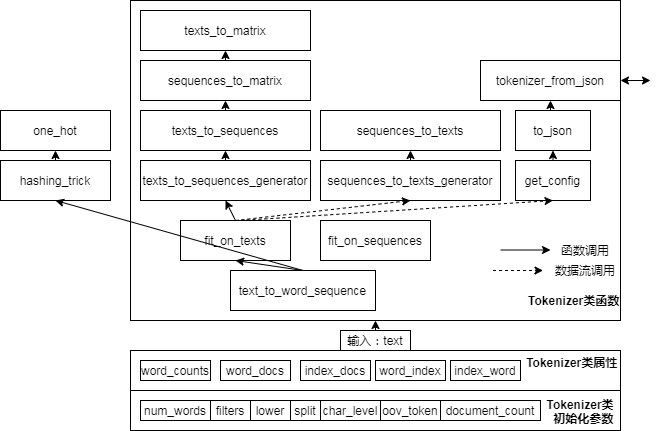
Keras-Sequenzvorverarbeitungs-Quellcode-Analyse
Word2Vec
- Das Skip-Gram-Modell von Word2Vec verstehen
- Implementierung des Skip-Gram-Modells basierend auf TensorFlow – Tian Yusus Artikel
- Word2Vec-Tutorial – Das Skip-Gram-Modell
- Word2Vec-Tutorial Teil 2 – Negative Stichprobe
- Word2Vec-Worteinbettungs-Tutorial in Python und TensorFlow
- word2vec_basic Tensorlflow-Quellcode-Analyse
- Ein Word2Vec Keras-Tutorial
- keras_word2vec@adventures-in-ml-code
Sicherheit
Sicherheitstechnik
Schlupflöcher
- Zusammenstellung der Nutzlast der Wuyun-Schwachstellenbibliothek und des Burp-Hilfs-Plug-Ins
- Boy-Hack/Wooyun-Payload
- Die Perspektive eines Forschers auf die Vulnerabilitätsforschung in den 2010er Jahren
Schwachstellenforschung: Aktueller Stand und Trends der Schwachstellenforschung in den letzten 10 Jahren : 1. In der Post-PC-Ära ist die Kontrollflussintegrität zu einem neuen grundlegenden Schutzmechanismus für die Systemsicherheit geworden. 2. Überraschende Hardware-Sicherheitsfunktionen und Hardware-Sicherheitslücken. 3. Neuer Wein in alten Flaschen, das sichere Design mobiler Geräte ermöglicht das Überholen in Kurven. 4. Der Kampf um Netzwerkzugänge verschärft sich. Zu den Netzwerkzugängen gehören: Browser, WLAN-Coprozessoren, Basisbänder, Bluetooth, Router, Instant-Messaging-Geräte, soziale Software, E-Mail-Clients, herkömmliche PCs und Server. 5. Das automatisierte Schwachstellen-Mining und die Ausnutzung müssen noch verbessert werden.
Websicherheit
- Ein Artikel, der Ihnen ein detailliertes Verständnis der Schwachstellen vermittelt: XXE-Schwachstellen
XXE-Schwachstelle : Das Prinzip von XXE: Aufruf externer Entitäten, die Verwendung von XXE: Verwendung allgemeiner Entitäten, Parameterentitäten, externer Entitäten, interner Entitäten zum Lesen von Dateien, Intranet-Host- und Porterkennung, Intranet-RCE (die Unterstützung der Expect-Erweiterung ist unter erforderlich). PHP) ) - Kommafreie MySQL-Injektionstechniken
Injektionsangriffe : SQL-Injektion, XML-Injection (eine Markup-Sprache, die Daten strukturell durch Tags darstellt), Code-Injection (Bewertungsklasse), CRLF-Injection (rn). MySQL-Injection: Verwenden Sie Kommentare, um Leerzeichen zu umgehen, verwenden Sie Klammern, um Leerzeichen zu umgehen, verwenden Sie Symbole wie %20 %0a, um Leerzeichen bei der Union-Abfrage zu ersetzen, verwenden Sie Join, um die Kommafilterung zu umgehen, select id,ip from client_ip where 1>2 union select * from ( (select user())a JOIN (select version())b ); Verwenden Sie select case when(条件) then 代码1 else 代码2 end , um die Kommafilterung zu umgehen, insert into client_ip (ip) values ('ip'+(select case when (substring((select user()) from 1 for 1)='e') then sleep(3) else 0 end)); - [CRLF Nutzung der Injektionsschwachstelle und Beispielanalyse]([https://wooyun.js.org/drops/CRLF%20Injection%E6%BC%8F%E6%B4%9E%E7%9A%84%E5% 88%A9%E7%94%A8%E4%B8%8E%E5%AE%9E%E4%BE%8B%E5%88%86%E6%9E%90.html](https://wooyun.js .org/drops/CRLF Nutzung der Injektionsschwachstelle und Beispielanalyse.html))
CRLF ist die Abkürzung für „Carriage Return + Line Feed“ (rn). HTTP-Header und HTTP-Body werden durch zwei CRLF getrennt. CRLF-Injection wird auch HTTP Response Splitting oder kurz HRS genannt. X-XSS-Protection:0 deaktiviert die Schutzstrategie des Browsers für die reflektierte XSS-Filterung. - SSRF-Schwachstellenausnutzung und Getshell-Kampf (ausgewählt)
- Zusammenfassung mehrerer Methoden zur Umgehung der Filterung (IP-Einschränkungen) bei SSRF-Schwachstellen
SSRF : Verwenden Sie 302 Jump (xip.io, kurze Adresse, selbst geschriebener Dienst); ändern Sie die Art und Weise, wie die IP-Adresse geschrieben wird: http://[email protected]/ ; über verschiedene Nicht-HTTP-Protokolle - Zusammenfassung der SSRF-Bypass-Methoden
SSRF : Verwenden Sie @; verwenden Sie den speziellen Domänennamen xip.io; verwenden Sie den hexadezimalen Verwendungszeitraum - ThinkPHP 5.0.0 ~ 5.0.23 RCE-Schwachstellenanalyse
- Eine kurze Analyse der Zeichenkodierung und SQL-Injection beim White-Box-Auditing (ausgezeichnet, erlernt)
Injektionsangriff basierend auf Zeichencodierung : Ein GBK-codiertes chinesisches Zeichen belegt 2 Bytes und ein UTF-8-codiertes chinesisches Zeichen belegt 3 Bytes. Die Wide-Byte-Injection nutzt die Eigenschaften von MySQL. Wenn MySQL die GBK-Codierung verwendet, wird davon ausgegangen, dass zwei Zeichen ein chinesisches Zeichen sind (unter GBK muss der vorherige ASCII-Code größer als 128 sein, um den Bereich chinesischer Zeichen zu erreichen; die Codierung). Wertebereich von gb2312: High-Bit 0xA1-0xF7 , Low-Bit 0xA1-0xFE und 0x5c , liegt nicht im Low-Bit-Bereich, daher ist 0x5c nicht die Codierung in gb2312, daher wird diese Idee nicht auf alle Multibyte-Codierungen ausgeweitet, solange der Low-Bit-Bereich die Codierung von 0x5c enthält. Wide-Byte-Injection kann durchgeführt werden. Verteidigungsplan eins: mysql_set_charset+mysql_real_escape_string unter Berücksichtigung des aktuellen Zeichensatzes der Verbindung. Verteidigungsplan zwei: Setzen Sie character_set_client auf binary (binär), SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary . Wenn unser MySQL die Daten des Clients empfängt, geht es davon aus, dass seine Codierung character_set_client ist, und ändert sie dann in die Codierung character_set_connection , gibt dann die spezifische Tabelle und das spezifische Feld ein und konvertiert sie dann in die Codierung, die dem Feld entspricht. Wenn dann die Abfrageergebnisse generiert werden, werden sie von der Tabellen- und Feldkodierung in die Zeichenkodierung character_set_results konvertiert und an den Client zurückgegeben. Wenn wir character_set_client auf binary setzen, gibt es daher kein Wide-Byte- oder Multi-Byte-Problem. Alle Daten werden in binärer Form übertragen, wodurch die Einfügung breiter Zeichen effektiv vermieden werden kann. Auch beim Aufruf von iconv nach der Verteidigung können Probleme auftreten. Wenn Sie iconv zum Konvertieren von utf-8 in gbk verwenden, ist die Verwendungsmethode錦' , da die utf-8-Kodierung 0xe98ca6 und die gbk-Kodierung 0xe55c ist, was schließlich zu %e5%5c%5c%27 wird, zwei %5c Es ist ' eine ungerade Zahl sind, wird ' entgeht dem Grenzwert. Warum können錦' diese Methode nicht verwenden? Gemäß den UTF-8-Kodierungsregeln wird (0x0000005c) in der UTF-8-Kodierung nicht angezeigt, sodass ein Fehler gemeldet wird. - Durch Clientsitzungen verursachte Sicherheitsprobleme
- Ein Einblick in DAST, SAST und IAST in einem Artikel – eine kurze Diskussion über den Vergleich von Technologien zum Testen der Webanwendungssicherheit (gelernt)
- Sprechen Sie über SAST/IDAST/IAST
- Einführung in PHP-Verbindungsmethoden und wie man PHP-FPM angreift
- Eine GET-Anfrage, um die Flagge zu erhalten – XCTF 2018 Final PUBG (WEB 2) Writeup
Penetrationstests
- Eine Reihe praktischer Penetrationstest-Fragen für Vorstellungsgespräche. Codeausführungsfunktionen:
eval、preg_replace+/e、assert、call_user_func、call_user_func_array、create_function ; Befehlsausführungsfunktionen: system、exec、shell_exec、passthru、pcntl_exec、popen、proc_open ; img-Tag außer onerror-Attribut Gibt es außerdem eine andere Möglichkeit, den Administratorpfad zu ermitteln? src gibt eine Remote-Skriptdatei an, um den Referrer abzurufen. - Eine Reihe praktischer Fragen zum Penetrationstest im Vorstellungsgespräch, kennen Sie das?
- Meine Interviewerfahrung, Penetrationstests
Code-Audit
- Java-Code-Audit – Schicht für Schicht Weiterentwicklung
Datensicherheit
- Nr. 27 Chat über Datensicherheit In der Big-Data-Technologie und im Zeitalter von Big Data sind Daten das zentrale Kapital vieler Unternehmen . Die traditionellen Sicherheitsgrenzen sind verschwommen. Wir müssen davon ausgehen, dass unsere Grenzen überschritten wurden, und gleichzeitig über eine umfassende Verteidigung verfügen Möglichkeiten zum Schutz der Informationssicherheit. Daher sollten wir uns bei der Stärkung traditioneller Sicherheitsmethoden direkt auf die Daten selbst konzentrieren. Dies ist die Aufgabe der Datensicherheit. Bevor wir dies tun, gibt es eine Prämisse: Wir müssen wissen, dass die Sicherheit immer noch dem Geschäft dient (in den meisten Fällen der Unternehmenssicherheit lautet „Geschäft > Sicherheit“), daher müssen Sicherheit und Benutzerfreundlichkeit abgewogen werden. Derzeit umfassen die von Unternehmen üblicherweise verwendeten Maßnahmen hauptsächlich: Datenklassifizierung, Datenlebenszyklusmanagement, Datendesensibilisierung und Datenverschlüsselung sowie die Verhinderung von Datenlecks.
- Aufbau eines Internet-Datensicherheitssystems für Unternehmen
Cloud-Sicherheit
- Cloud-Sicherheit, was genau ist das?
Es gibt drei Hauptforschungsrichtungen in der Cloud-Sicherheit: Cloud-Computing-Sicherheit, Cloudisierung der Sicherheitsinfrastruktur und Cloud-Sicherheitsdienste. Die Zusammenarbeit zur Datensicherheit wird auch in den zukünftigen Entwicklungstrends der Cloud -Sicherheit erwähnt, was darauf hinweist, dass Daten, unabhängig von welchem Szenario, im Mittelpunkt der Sicherheit stehen. Cloud -Sicherheitsdienste können als Köche Cooking (PPT aus CDXY), Cloud Computing (Energie), Algorithmen (Tools), Daten (Rohstoffe), Ingenieure (Köche) und welche Art von Reis erstellt werden (Sicherheitsdienste, die sein können, angesehen werden bereitgestellt) ) - Die Zukunft der Cloud-Sicherheit (lang ausführlicher Artikel)
Schreibideen : Cloud Security Market Trends -"Mainstream Cloud -Sicherheitsprodukte (Cloud -Plattform -Sicherheitsprodukte und Cloud -Sicherheitsprodukte von Cloud -Sicherheit von Drittanbietern, CSPM, CASB) -" Die Kombination aus Cloud -Sicherheit und SD -WAN -"Cloud Native (DevOps, kontinuierlich" Lieferung, Microservices, Container) Sicherheit.
andere
- Sicherheitsinformationen: Enterprise Labs, Sicherheitsgemeinschaften, Sicherheitsteams, Sicherheitstools usw.
Sicherheitstools
Sicherheitsanfälligkeitsscan
- Sicherheitsanfälligkeitscannen mit dem Xray -Proxy -Modus
Sicherheitsforschung
Passende Erkennung
- APT -Erkennung basierend auf maschinellem Lernen
APT -Erkennungsmodell : In diesem Artikel wird ein APT -Erkennungsmodell vorgeschlagen, indem mehrere Links im APT -Lebenszyklus erfasst, Alarmereignisse in jedem Link korrelieren und maschinelles Lernen zum Training des Erkennungsmodells verwendet werden. Es ist meiner Idee etwas ähnlich. Dies ist der Zweck, die Sicherheitsereignisse in einem passenden Szenario vollständig zu beschreiben, die falsch positive Rate zu verringern, die Genauigkeit zu verbessern und die Probleme von verpassten Negativen und falsch-positiven Aussagen zu vermeiden, die durch eine traditionelle APT-Einzelverbindungskennung verursacht werden. In diesem Artikel gibt es jedoch auch einige Probleme, wie das Fehlen von Datenquellen.
Bösartige Proben
- Verwenden Sie maschinelles Lernen, um HTTP -böswilligen externen Verkehr zu erkennen (ausgezeichnet)
Bösartige HTTP Externe Verkehrserkennung : Allgemeine Idee : 1. Datenerfassung , bösartige Muster im Sandkasten ausführen, böswilligen Verkehr sammeln, den böswilligen Verkehr manuell vom weißen Verkehr unterscheiden und dann böswilligen Verkehr in Familien basierend auf Bedrohungsinformationen eintreffen. 2. Datenanalyse (Feature Engineering): Für die Ähnlichkeit des böswilligen externen Verkehrs derselben Familie können Sie in Betracht ziehen, einen Clustering -Algorithmus zu verwenden, um den Verkehr derselben Familie in eine Kategorie zu gruppieren, ihre Gemeinsamkeiten zu extrahieren, eine Vorlage zu bilden und dann dann Verwenden Sie die Vorlage, um unbekannten Verkehr zu erkennen. 3 .. Clustering ---> Erzeugen Sie eine schädliche externe Verkehrsvorlage (die Vereinigung dieses Feldes im Cluster wird als Wert dieses Feldes in der Vorlage verwendet). Erkennungsstufe : Unbekannte HTTP externer Verkehr ---> Anforderungsheaderfelder extrahieren ---> Verallgemeinerung ---> Übereinstimmung mit böswilligen Vorlagen ---> Bestimmen Sie, ob die Ähnlichkeit den Schwellenwert überschreitet (Schwellenwertbestimmung) - Konstruktion von Cuckoo Malware Automated Analysis Platform
- Cuckoo Malware -Analyseumgebung
- Mit Kuckuck spielen
Cuckoo Sandbox: Ich habe viele Fallstricke begegnet, um die bösartige Analyseumgebung von Cuckoo zu erstellen. PY zum Startordner; Auf dem physischen Host ist Windows 10 mit VMware installiert. VMware ist mit Ubuntu16 installiert, Ubuntu16 ist mit VirtualBox und Cuckoo Server installiert und VirtualBox ist mit Windows7 als Agent installiert. - Zusammenfassung der böswilligen Musteranalyse -Ressourcen
Kampf gegen den Maschinenverkehr
- 2018 Bad Bot Report
Combat Machine -Verkehr : Sicherheitskonfrontation hat die Entwicklung von Angriffsmethoden gefördert und in die Phase der automatischen Konfrontation eingetragen Der Maschinenverkehr wird generiert, während bösartige Crawler und andere bösartige Crawlers normale Benutzeranfragen zum Generieren von böswilligen Maschinenverkehr imitieren. kopflos. Browser, fortgeschrittenere können Mausbewegungen und -klicks simulieren. Der Maschinenverkehr kann auf der Grundlage der Netzwerkumgebung (Amazon ISP, Rechenzentren, globalen Hosting -Anbietern), den verwendeten Tools (Browser des Maschinenverkehrs) unterschieden werden Interaktionen wie Mausbahnen und Klicks. Sobald sie unsere Versuche erkennen, sie zu stoppen, werden fortgeschrittene APBs für bösartige Maschinenverkehr anhaltend und anpassungsfähig und führen multimodale Transformationen durch. Verteidigung: Verstehen Sie unsere Operationen und feindlichen Ziele. Veraltete UA/Browser unterdrücken; Fehlgeschlagene Anmeldeversuche;
Bösartige URL -Erkennung
- Erkennen bösartiger URLs
Nach dem Lesen von Algorithmen und Sicherheitsdatenanalysen in den häuslichen Sicherheit bis zum Ende begannen sie, ihre Aufmerksamkeit auf das Ausland zu wenden und den Entwicklungsprozess von Anwendungen für maschinelles Lernen im Bereich des maschinellen Lernens im Bereich der Netzwerksicherheit zu verfolgen. Als Beispiel können viele anwendbare Szenarien abgeleitet werden, einschließlich böswilliger Webseitenerkennung, böswilligen Kommunikationsaktivitäten und böswilliger Websoftware. - Jenseits von Blacklists: Lernen, bösartige Websites aus verdächtigen URLs zu erkennen
Verwenden Sie eine böswillige URL -Erkennung als ergänzende Methode zur Erkennung von böswilligen Webseiten. Daten: Open Source-URL-Proben, keine speziellen Merkmale; Keine Merkmale, Analyse und Vergleich jeder Unterkategorie Dieses Modell hat keine Merkmale. Immerhin war es eine Zeitung vor zehn Jahren. - Identifizierung verdächtiger URLs: Eine Anwendung von großem Maßstab Online-Lernen
- Nutzung der Feature-Kovarianz im hochdimensionalen Online-Lernen
Roter Team
- Das Training und Denken des Roten Teams von 0 bis 1 (gelernt)
Definition des roten Teams-> Das Ziel des roten Teams (lernen und verwenden Sie TTPs bekannter realer Angreifer, um anzugreifen, die Effektivität bestehender Verteidigungsfähigkeiten zu bewerten, Schwächen im Verteidigungssystem zu identifizieren und spezifische Gegenmaßnahmen vorzuschlagen, reale und effektive simulierte Angriffe zu verwenden Um die potenziellen geschäftlichen Auswirkungen zu bewerten, die durch Sicherheitsprobleme verursacht werden) ---> Wer braucht rotes Team ---> Wie rotes Team funktioniert (Grundzusammensetzung: Wissensreserve, Infrastruktur, technische Forschungsfunktionen; Arbeitsprozess: Simulation der vollständigen Stufe, inszenierte Angriffsangriffe Simulation; Quantifizierung und Bewertung des Teams (Abdeckung bekannter TTPs, Erkennungsrate/Erkennungszeit/Erkennungsstufe, Blockierungsrate/Blockierungszeit/Blockierung) ---> Wachstum und Verbesserung des Roten Teams (Simulationsumgebungstraining, Schwachstellenanalyse und technische Forschung, externe Kommunikation und teilen) - Zusammenfassung der TTPS von ATT & CK APT
- ATT & CK Full Platform Attanking Technology Summary
- Zusammenfassung der realen APT -Organisationsanalyseberichte
Waf
- Technische Diskussion |
- Verwenden Sie die Übertragung von Chunked, um alle WAFs zu besiegen
- BYPASS WAF von HTTP -Protokollebene und Datenbankebene
- Vier Ebenen der WAF -Angriffs- und Verteidigungsforschung: Bypass WAF
- Einige Kenntnisse über WAF
Anomalieerkennung
- N Methoden der Anomalieerkennung (gelernt)
Eine der Schwierigkeiten bei der Erkennung von Anomalie ist die mangelnde Grundwahrheit. Aus Zeitreihen (gleitender Durchschnitt, Jahr gegenüber dem Vorjahr und Monat, STL+GESD), Statistik (Mahalanobis-Entfernung, Boxplot), Distanzwinkel (KNN), linear (Relative Entropie-KL erkennen Anomalien aus Blickwinkeln wie Divergenz, Chi-Quadrat-Test), Bäume, Diagramme, Verhaltenssequenzen und überwachte Modelle (die automatisch mehr Merkmale wie GBDT kombinieren können). - Erkennungsalgorithmus für maschinelle Lernanomalie (1): Isolationswald
- Maschinelles Lernanomalie-Erkennungsalgorithmus (2): Lokaler Ausreißerfaktor
- Erkennungsalgorithmus für maschinelle Lernanomalie (3): Hauptkomponentenanalyse
- Was ist eine Einklassen-Support-Vektormaschine (eine Klasse SVM)?
- Anomalie -Erkennungsalgorithmus -Isolationwald
- Anomalie -Bergbau, Isolationswald
- Erster Versuch zur Erkennung von Anomalie
- Intelligente Überwachung von Zeitreihendatenanomalien, die durch maschinelles Lernen betrieben werden
- Bergbauausnahmen in massiven Betriebs- und Wartungsprotokollen
- Datenvorverarbeitung Identifizierung
- Eine vorläufige Studie zur Anwendung abnormaler Erkennung und überwachtes Lernen bei der Erkennung von Anomalie
- Was sind die üblichen "Anomalie -Erkennungs" -Algorithmen im Data Mining? - Feinabstimmige Antwort - Zhihu
1. Einbeziehung von nicht übermäßigen Anomalie -Erkennungsalgorithmen und Experimenten; 1.1) Statistik- und Wahrscheinlichkeitsmodelle: Hypothesenverteilung und Hypothesen-Test, eindimensional und mehrdimensional, Merkmalsunabhängigkeit und Merkmalskorrelation, euklidische Entfernung und Mahalanobis-Distanz; Euklidische Entfernung und Mahalanobis-Entfernung, PCA und Soft PCA und One-Class-SVM; 1.2) Überprüfen Sie die Verbindung zwischen Algorithmen aus der Entscheidungsgrenze des experimentellen Ergebnisdiagramms. 2.1) Vergleich von Modellerkennungseffekten, Isolationswald und KNN werden stabil ausgewiesen; 3.1) Datenvolumen und Datenabmessungen haben sich ebenfalls auf den Algorithmus -Overhead aus. Die Isolation ist besser für hochdimensionale Räume geeignet. 4.1) Die experimentellen Ergebnisse bringen Ideen für die Auswahl der Anomalie-Erkennungsmodells: KNN und MCD für kleine und mittelgroße Datensätze sind relativ stabil, und der Isolationswald für mittlere und große Datensätze ist stabil; Als PCA und MCD ist die Erkennung von Anomalie häufig nicht beaufsichtigt, so kann die Stabilität wichtiger ist als schwankende Leistung. 4.2) Für ein neues Anomalie -Erkennungsproblem können Sie die folgenden Schritte zur Analyse befolgen: A. Verstehe die Daten, die Datenverteilung und die Anomalieverteilung und wählen Sie ein Modell basierend auf Annahmen; , Wenn ja, muss es nicht verschwendet werden. Punktauswahlalgorithmus; Die Eigenschaften von Anomalien ändern sich häufig. Manuelle Regeln sind immer noch sehr nützlich. Versuchen Sie nicht, vorhandene Regeln durch Datenstrategien in einem Schritt zu ersetzen. - Kämmen |
- Anomalie -Erkennungsisolation Wald & Visualisierung
- Erkennung von Anomalie mit Zeitreihenprognose
Zahlen und Sicherheit
- Figure/Louvain/DGA -Zufallsgespräch Das Diagramm enthält topologische Informationen, und topologische Informationen können als charakteristische Dimension angesehen werden. Der entscheidende Punkt des Louvain -Algorithmus ist das Gewicht der Kanten des Diagramms, die eine spezielle Studie in spezifischen Angriffs- und Verteidigungsszenarien erfordert. von iPs, die gleichzeitig Domainnamen A und B besucht haben. Master CDXY implementierte diese Logik mit SQL.
- Community Discovery-Algorithmus-eine vorläufige Studie zum Fast-Entfaltungs-Algorithmus (Louvian)
- Eine DGA -Odyssey -PDNS -DGA -Analyse angetrieben
- Das Graph Computing hat die Implementierung der grundlegenden Sicherheit kennengelernt: die Implementierung von Graphen in der Intrusionserkennung, der Intrusionsreaktion, der Bedrohung intelligenz und der UEBA. Intrusion Detection: Die Entwicklungsrichtung des Intrusion -Erkennung von Unternehmen und die Entwicklungsgeschichte von Datenanalysefunktionen. Intrusion Reaktion: während des Prozesses gelöst (Vollständigkeit und Reichtum von Protokollen, Korrelationsanalyse massiver Daten und langjährige Fenster, Echtzeitkonstruktion und Abfrage von Graphen, Interaktion und Visualisierung). UEBA: Die Entwicklung des Cloud -nativen Trusts und des Zero Trust -"Secure By Standard -" Erhalten von Anmeldeinformationen für vertrauenswürdige Dienste, "Lieferketten" -Angriffe -"Intrusion Detection, die auf der Authentifizierung basieren -" Verhaltensanalyse und Profilerstellung. Zusammenfassung: Geschäftsprobleme -> Datenfragen.
KI und Sicherheit
- Zusammenstellung von Lernmaterialien für Sicherheitsszenarien, KI-basierte Sicherheitsalgorithmen und Sicherheitsdatenanalysen
- In Richtung der Privatsphäre und Sicherheit von Deep -Learning -Systemen: Eine Umfrage
Angriffsoberfläche der KI -Sicherheit : In Bezug auf Daten und Modelle in der Trainingsphase und der Testphase gehören Angriffe Datenvergiftung und kontroverse Proben, Modellextraktion und Modellinversion usw. - Intelligente Erkennung von Bedrohungen: Spark-basierte SoC-Erkennung von SoC Maschinenlernen
Unternehmenssicherheitskonstruktion
Sichere Entwicklung
- Konstruktion der automatisierten Erkennungsplattform für Sicherheit (Web Black Box)
- Nehmen Sie mit, um die Kunpeng -Quellcodeanalyse des Artefakts zu lesen
Sicherheitstests
- Planen Sie eine Risikokontrolle und ein Frühwarnsystem
Steuerung des Unternehmenssicherheitsrisikos : Erkennen Sie schnell Anomalien und definieren Sie die Risiken genau. Entdecken Sie abnormale Fragmente und Entitäten durch Veränderungen der Kernindikatoren und entdecken Sie alle Entitäten unter dem abnormalen Cluster durch Clustering-Methoden. - Die Reise des Umschaltens von traditioneller Sicherheit auf den Bereich der Risikokontrolle und die Erörterung der Trends in der schwarzen Industrie und der Risikokontrollindustrie
Die Kontrolle des Unternehmens zur Sicherheit des Risikos wird immer heftiger. Mit dem hohen Druck der Regierung gegen schwarze und graue Produkte werden große Unternehmen auf die Produktfunktionen und die Compliance-Legitimität von Risikokontrolllieferanten achten. - Vorbereitung des Risikokontrollmodellingenieurs Interview-Technisches Kapitel
- Risikokontrollmodellpraxis-"Magic Mirror Cup" Risikokontrollalgorithmus Wettbewerb
- Methode zur Identifizierung der Risikosteuerung der Benutzerin Identifizierung
- Github: Sladesha
- Mehrere Algorithmen identifizieren abnormale Benutzer wie Anmeldeinformationen und Gutscheinbetrug
- DNS -Tunnel verdeckte Kommunikationsexperiment && Versucht, die Erkennung von Merkmalsvektorisierungs -Denkmodus zu reproduzieren
- Versteckt für Unternehmenssicherheitskonstruktionen
- Gewährleistung der IDC -Sicherheit: Verteilte HIDS -Cluster -Architekturdesign
- Dianrong Open Source Agentsmiths versteckt-ein leichtes HIDS-System
- Konstruktion für Unternehmenssicherheit-Einige Ideen zum Design des agentenbasierten HIDS-Systems
Intrusion Detection-Host Intrusion Detection System : Die systematische Praxis von Meituan ist es wert, gelernt zu werden. Aus der Nachfragebeschreibung stellt der Produktmanager die Nachfrage vor -> analysiert die Nachfrage, fasst die Merkmale zusammen, die die Produktarchitektur entsprechen muss -> technische Schwierigkeiten, analysiert die technischen Herausforderungen -> Architekturdesign und Technologieauswahl -> Distributed HIDS Cluster Architekturdiagramm -> Programmiersprache Auswahl-> Produktimplementierung. - ICMP -Tunnelerkennungsmethode und -implementierung basierend auf der statistischen Analyse
Sicherheitsprodukte
- Sammeln Sie einige exzellente Open -Source -Sicherheitsprojekte, mit denen die Sicherheitspraktiker von Party A helfen können, Unternehmensfunktionen für Unternehmenssicherheit (gelernte) Open -Source -Sicherheitsprodukte zu erstellen: einschließlich Vermögensverwaltung, Sicherheitsentwicklung, automatisierter Code -Audit, Sicherheitsbetrieb und Wartung, Bastion Host, HIDs und Netzwerkverkehrsverkehrsanalyse , Honeypot, WAF, Enterprise Cloud Disk, Phishing -Website -System, GitHub -Überwachung, Risikokontrolle, Schwachstellenmanagement, Siem/SOC.
Sicherer Betrieb
- Was ich über Sicherheitsvorgänge verstehe
Unternehmen zahlen für Output, nicht Wissen . Sicherheitsvorgänge sind problemlösend orientiert. Hauptverantwortung und Fähigkeiten für Sicherheitsvorgänge: Sicherheitsvorkehrungen, Betriebs- und Wartungshintergrund; - Sprechen wir über das Warum sicherer Operationen: Das Risiko der Sicherheit wird sichtbar gemacht und das Erscheinungsbild wird ausgesetzt .
Das Was und wie sicheres Operationen: Nehmen Sie die Hauptspuren und sekundären Widersprüche ein und versuchen Sie Ihr Bestes, um sie zu lösen.
Sicherheitsmanagement
- Die Veröffentlichung von Enterprise Security Construction Skill Tree V1.0 umfasst sechs Teile: Beschreibung, Sicherheitskonzept, Sicherheit Governance, allgemeine Fähigkeiten, berufliche Fähigkeiten und qualitativ hochwertige Ressourcen.
Denken Sie sicher
- Sprechen Sie über die Entwicklungsrichtung der Internetunternehmenssicherheit
Enterprise Security Development Direction : Vom flacheren bis tieferen ist es in vier Ziele unterteilt: 1. Durch die Beseitigung von Schwachstellen ist das erste Ziel, jede Codezeile zu machen, die von Ingenieuren geschrieben wurde. Abgeleitete technische Forschung und Technologie. 2. SDL kann nicht zu 100% sicher sein, daher ist das zweite Ziel, dass alle bekannten und unbekannten Angriffe zum ersten Mal entdeckt und schnell alarmiert und verfolgt werden. Herausforderungen: Massive Daten und komplexe Anforderungen: Super-Computerleistung und dreidimensionale Modelle. 3. Das dritte Ziel ist es, die Sicherheit zur Kernwettbewerbsfähigkeit des Unternehmens zu gestalten und die Funktionen jedes Produkts tief einzugehen, um die Internetnutzungsgewohnheiten der Benutzer besser zu leiten. V. Wenn Sie in einem Internetunternehmen Sicherheit machen, müssen Sie die Entwicklung anderer technischer Bereiche auf diese Weise auf diese Weise beachten. Sei gemacht. - Förderung der Verteidigung durch Offensiv
- Zhao Yans Ciso Blitz |
SCOPE-Objekte (Unternehmensgeschäft, Herausforderungen und Sicherheitsbedürfnisse (Verteidigung eingehend, eigene Sicherheit für die Lieferkette, die Sicherheit von Drittanbietern) ---> Zieleinstellung (aktuelle Nachfragemittel und zukünftige Entwicklung) ---> Herausforderungen (teamweit Stack (Wissensstruktur und Fähigkeiten, die dem Hauptgeschäft entsprechen), technische Funktionen, Managementfunktionen) ---> Zersetzung Sicherheitssystem (Sicherheitskonstruktion Sandbox im Allgemeinen Felder: F & E-Sicherheit, IT-Sicherheit, Infrastruktursicherheit, Datensicherheit, Terminalsicherheit, Unternehmenssicherheit, Datenschutz- und Sicherheitsvorschriften) ---> Implementierung und Reaktion Fähigkeit, Demo gilt nicht als diese Fähigkeit), Sicherheitsforschung). Im Allgemeinen handelt es sich um eine technische Vision in voller Stapel (bemühen Sie sich, von der Fähigkeitsniveau auf technische Sichtebene zu steigen) + Sicherheitsmanagementfunktionen.
Sicherheitsarchitektur
- Network Security Architecture | Die Sicherheit durch Sicherheitsarchitektur] (https://mp.weixin.qq.com/s/m90wyaevhzfsdgnfhmgxcw)
Konfrontation zwischen Rot und Blau
- [Rote und blaue Konfrontation] Bau des Sicherheitsteams der Blue Army für große Internetunternehmen (gelernt)
Das Warum von rotem und blauem Konfrontation : Testen Sie das Unternehmensschutzsystem;
Was ist die rot-blaue Konfrontation : Intrusion Discovery Rate;
Das Wie der rot-blauen Konfrontation : Simulate APT ---> Das Blue-Team muss eine systematische Wissensbasis und eine Waffenbasis von Angriffstechniken entwickeln ---> att && Ck Matrix Framework.
Herausforderungen in der rot-blauen Konfrontation mit DO : Effizienz/Nutzen;
Die Zukunft der rot-blauen Konfrontation : Mehrstufe und Multi-Scope Blue Army; - Aufbau einer rotblauen Konfrontation im Zeitalter der Cyberspace-Sicherheit (es gibt Artikel im Zusammenhang mit der rot-blauen Konfrontation im Anhang)
Der tatsächliche Kampf ist das einzige Kriterium zum Testen von Sicherheitsschutzfunktionen . Penetrationstests sind für die anfängliche Stufe des Konstruktionssystems für Unternehmenssicherheit oder für die Erschöpfungsstufe geeignet, und die rot-blaue Konfrontation ist eine verbesserte Version des Penetrationstests. Sicherheitskonstruktionssystem . /Peeping und andere Felder aus Sicht der Cyberspace -Sicherheit .
Intranet -Sicherheit
- Intranet -Sicherheitsangriffssimulation und Anomalie -Erkennungsregel Praxis
Die Schreibidee : Externe Informationssammlung -> Grenzbruch -> Informationssammlung, Berechtigungskalation -> Berechtigungswartung -> Informationssammlung, Anmeldeinformationsextraktion -> Laterale Bewegung -> Datendiebstahl -> Säuberspuren.
Datensicherheit
- Tencent Security startet auf Unternehmensebene "Datensicherheitskapazitätskarte".
Schreibideen : Die Karte der Datensicherheitskapitalisierung umfasst sechs Hauptaspekte: Datenvermögensverwaltung und Kontrollfunktionen, Funktionen zur Datensicherheit, Datenverwaltungsverwaltungen und Steuerungsfunktionen des Datengeschäfts, Datenschutzverwaltungen und Steuerungsfunktionen für Umgebungsumgebungen, Datenbetrieb und Wartungssicherheitsmanagement und Kontrolle Funktionen und Funktionen der Datensicherheit.
Neue Technologie und neue Sicherheit
Überblick
- Anwendungsmodernisierung und Sicherheitsverschiebung in der digitalen Transformation links
Ideen für Schreiben : Neue Infrastruktur -> Digitale Transformation -> Traditionelle Informatisierung steht vor Herausforderungen -> Business -Driven -Anwendungsmodernisierung -> Native Cloud, Containerisierung, DevOps, Anwendungsmikroservices, Orchestrierung und andere neue Technologien -> Anwendung Modernisierung Architektur -> Endogene Sicherheit (alle -Round Wahrnehmung, Vertrauenswürdigkeit, Sicherheitsintervention in voller Verarbeitung und sicherer Betrieb des Cloud-Netzwerks).
Wolke native
- Interpretation von Cloud Native Network Proxy MOSN transparente Hijacking -Technologie | Open Source
Die Schreibidee : Service Mesh-> Istio-> Datenebene-> Netzwerk-Proxy-> MOSN-> Effiziente und transparente Verkehrsentüchtigungen. Problem: Verkehrsübernahme. Lösen von Problemen: Umgebungsanpassung, Konfigurationsmanagement, Datenebene Leistung. - Wolke native Intrusion Detection Trend Beobachtung
Die Idee des Schreibens : Diversifizierung der Asset, Service -Fragmentierung, Middleware Blowout, Infrastruktursicherheit standardmäßig -> "geschäftsorientierte" Intrusion -Erkennung, Verhaltensanalyse wird zur Kernfähigkeit. - Wang Renfei (Avfisher): Rote Teaming für Cloud (Cloud Offensive and Defense) (Mark)
vertrauenswürdiges Computer
- Zhang OU: Digital Banking Trusted Network Practice
Schreibideen : Das wesentliche Problem ist: Verteidigung ausführlich auf Netzwerkebene. Warum dies tun (Herausforderung) -> Ideen und Pläne für die Umsetzung -> Herausforderungen und Gedanken im Prozess . - Er Yi: Der Weg zur Praxis von Zero Trust Security Architecture
Kernpunkt : Der Kern von Zero Trust ist die Festlegung von Vertrauensketten wie Benutzern + Geräten + Anwendungen, sichere und kontinuierliche dynamische Überprüfung und Verengung der Angriffsfläche. Arbeiten erledigt: Netzwerkgateway, Host -Gateway, Application Gateway, Soc .
DevSecops
- "Sicherheit erfordert die Teilnahme jedes Ingenieurs" -DevSecops Philosophie und Denken (Mark)
sichere Entwicklung
persönliche Entwicklung
Interview
- Sicherheitsinterviews, Praktika usw.
Interviews : Didi, Baidu (2), 360 (2), Alibaba (6), Tencent (3), Bilibili, Huawei, Tonghuashun, Mogujie. Im Allgemeinen sind die großen Jungs so stark, dass die meisten ihrer Entscheidungen die Sicherheitsabteilung der Partei A sind. Mein Verständnis: Nach dem Lesen der Interviews und Fragen, die die großen Jungs gestellt haben, ist es sehr vielfältig, einschließlich Binorientierung, Ausrichtung der Datensicherheit, Orientierung des Sicherheitsbetriebs usw., der einen gewissen Referenzwert hat, aber weil die Anweisungen unterschiedlich sind, also Sie, also Sie Kann sie nicht starr kopieren. - 2018 Spring Recruitment Safety Post Post -Praktikumsinterview Zusammenfassung
- Tencent 2016 Praktikum Rekrutierung detaillierte Erläuterung der Antworten auf den Sicherheitsposten geschriebener Testfragen
Schreibender Test : Entwerfen Sie eine sichere Webauthentifizierungslösung: Front-End: Verifizierungscode + CSRF_TOKE + Zufällige Zahlen basierend auf der Zeitstempelverschlüsselung; , Port, Protokoll); - Interviews für Sicherheitstechnologiepositionen in großen Unternehmen
Interview : Grundlagen der Sicherheitstechnologie ---> Projektdetails (Tiefe des Wissens, überwältigter den Interviewer in Bereichen des Fachwissens, verhindern, dass der Interviewer eingehende Fragen stellt) ---> Wie man mit herausfordernden Fragen umgeht (Wissen und kognitiv Die Fähigkeit weicht im Allgemeinen nicht vom Fachgebiet ab und erfordert tägliches Lesen und Denken) ---> Industrie detaillierte kognitive Fähigkeiten und Karriereplanung - Wie hoch ist die aktuelle Situation interner Empfehlungen für Alibaba -Praktikanten im Jahr 2019? - Zuo Zuo Veras Antwort - Zhihu (gelernt)
- Zehn Gesichter von Ali, sieben Gesichter von Schlagzeilen, denkst du, ich habe Ali betreten?
Interview : Java-Version von Excellent Interview Experience, ein Muss für Java. - Buch der Schwerter und Feindschaften: Ich und Alibaba (zu stark)
- Fragen der Sicherheitsrekrutierung Interviews (gelernt)
Ideen für Schreiben : Penetrationstests (Webrichtung), Sicherheitsforschung und -entwicklung (Java -Richtung), Sicherheitsvorgänge (Compliance Audit Direction), Sicherheitsarchitektur (Sicherheitsmanagement -Anweisung)
Ergänzendes Lernen : CRLF, Unterschiede, Vor- und Nachteile der symmetrischen Verschlüsselung und asymmetrische Verschlüsselung, HTTPS-Interaktionsprozess, Ursprungsrichtlinie, Cross-Domain-Anfragen. - Wie sieht ein guter Lebenslauf für eine sichere Rekrutierung aus?
- Sicherheitsrekrutierung: Aktuelle Situation der Sicherheitsbranche
- Wesentliche Qualitäten von Sicherheitspraktikern für Sicherheitsrekrutierung
Schreibidee: Basic Quality = Basic-Fähigkeit (selbstgetriebenes + unabhängiges Lernen) + Professionelle Fähigkeit (Penetrationangriff und Verteidigung + Softwareentwicklung). Fortgeschrittene Eigenschaften = Intelligenz (IQ + emotionale Intelligenz) + Tapferkeit und Optimismus + Selbstbeobachtung . - Der Interviewprozess für eine sichere Rekrutierung ist jetzt faul und es wird mehr kosten, dies später auszugleichen.
- 2019 eines Sicherheitsingenieurs 2019
Schreibideen : Old Track und New Journey - "Industry Explorer oder Anhänger -" transparenter Austausch von Brancheninformationen - "Fügen Sie ein wenig Salz zum Leben hinzu".
Karriereentwicklung
- Selbstkultivation von Sicherheitsforschern
- Selbstkultivation von Sicherheitsforschern (Fortsetzung)
- Diskussion über die Entwicklungsrichtung des Sicherheitspersonals
Die Sicherheitsentwicklungsroute der Partei A : Hard-Core-Technologie-Typ ---> Dachang-Laboratorien und Sicherheitsforschungsposten Nicht-Hard-Core-Technologie-Typ ---> Internet Enterprise Security Construction rot und blau, technische Operationen, Sicherheitsmanagement - Die Bedeutung der Existenz von Sicherheitspraktikern
Persönliche Entwicklung : Ziel ist es, fortschrittliche Produktivität zu helfen, Sicherheitsprobleme zu lösen. Das Sicherheitsproblem ist ein Vertrauensproblem (Vertrauensunterstützung, Herkunftsunterstützung), eine Wissenschaft, die Konfrontation (Konfrontation zwischen Menschen) und ein Wahrscheinlichkeitsproblem (Sicherheitsarchitektur) studiert. Sicherheit ist eine angewandte Wissenschaft. , einschließlich Machine Intelligence und Blockchain -Technologie. - Mehrere Identitäten des Sicherheitsteams im Unternehmen
团队发展:安全团队应该以服务者和协作者的身份,用专业的安全能力给出一类安全问题的解决思路和方案并解决,防止安全问题发生多次。
行业发展
安全格局
- 最新统计2005-2017年国内科研单位在国际安全顶级会议中发表文章量统计
- 从内容产出看安全领域变化
技术格局:企鹅等互联网巨头开始进行流量封锁,对安全从业人员影响很大,爬不到数据,api又有限,只能上升到app hook了;技术上安全分析、数据挖掘、威胁情报的比重越来越重, AI已经不仅仅是噱头了,智能安全势不可挡;安全的职业发展方面,越来越多大佬们开始转型业务安全、数据安全。 - 网络安全行业竞争格局浅析
市场格局:基础安全防护(传统安全防护能力),中级安全防护(海量数据建模与分析能力),高级安全防护(云端威胁情报与分析能力),中高级安全防护市场广阔。此外,全文在多处凸显了人工智能技术,智能安全开始迈入开悟之坡了吗? !半数以上的人看好智能安全,也有人不看好智能安全,未来会怎么样,让我们拭目以待! - ZoomEye 网络空间测绘——委内瑞拉停电事件对其网络关键基础设施和重要信息系统影响
- 2020安全工作展望
Logic of writing : Major events in 2019 : HW action changes safety from implicit to explicit, low frequency to high frequency, exposes problems, and promotes management to pay attention to safety. This is the background; Classification Protection 2.0 safety compliance is becoming more stringent . 2019大变化:领导重视了;实战化了。 2020甲方安全关注技术点:安全运营(覆盖率和正常率等指标、是否有验证思路:能否在一定时间内主动发现安全措施失效)和安全资产管理(CMDB、主机上数据、流量、扫描、人工添加)。 2020关注“人”的需求。 2020展望行业:甲方安全团队组织架构会发生剧烈变化,安全团队能否承受变化;甲乙两方相处之道;安全黑天鹅事件越来越多。
安全产品
- C端安全产品的未来之路
C端安全产品:移动端安全产品是否会像前几天PC端安全产品一样迎来春天?PC时代windows是一家独大的完全开放的平台,这让第三方安全公司能够在平台和用户之间产生价值的空间足够的大,但在移动端,安卓开始封闭,就不好说了。传统安全软件围绕病毒和欺诈,而围绕个人信息安全的C端安全产品有一线生机。 - 下一座圣杯- 2019
API安全:应用安全的发展:2015年预测,数据是新中心,身份是新边界,行为是新控制,情报是新服务。基础设施演进->交付方式的改变。2015年,应用安全领域的WAF产品是良机,由市场决定。新形势与新机遇:微服务、Serverless、边缘计算。市场中的交付方式发生变化。跨细分领域且跨基础设施:API安全横跨应用安全、数据安全和身份安全三大领域。API使用场景广泛,需要产品有全面覆盖多种不同基础设施的能力。
Daten
数据体系
- 数据分析师如何搭建数据运营指标体系? - 张溪梦Simon的回答
Core point : Collaboration process empowerment : Implementing the data-driven XX indicator system construction process requires cross-team collaboration. The processes include: demand collection, program planning, data collection, collection program evaluation, data collection and data verification online, and effect evaluation .规划数据指标体系的两个模型:OSM和UJM。 OSM强调业务目标,UJM强调用户旅程。指标分级体系:一二三级指标联动。 - 如何在企业中从0-1建立一个数据/商业分析部门?(学到了)
部门的定位和价值——>里程碑设计——->团队搭建——->构建IT数据——->前期管理。
定位和价值是一个部门立足公司的根本:做报表的部门VS做战略的部门;业务其他公司的定位和公司内其他部门的认可;一定要会放大部门的价值和一定要走高层路线。
设立长期目标并拆解里程碑:公司业务目标--->公司战略--->部门目标--->部门里程碑--->工作计划;设立里程碑的技巧?借势、共赢、取巧、筑基;借老板势,寻找1-2个老板的痛点问题解决;寻找利益相同的部门共建共赢;取巧摘已有的“桃子”;筑基数据链路梳理、数据清洗、系统互联、数据仓库设计、数据集市设计。
基于里程碑进行团队搭建:切忌一步到位;审慎拉帮结派;遇到人才不可错过;学会“画饼”;注意团队文化建设。
构建公司的数据IT能力:搭建基础且通用的数据流框架:应用层、归集层、加工层、分析层、展示层; 同时根据各种数据库选型指标选择对应的数据库存储产品,数据库选型指标比如容量、水平扩展性、查询实时性、查询灵活性、写入速度、事务、数据存储、处理数据规模、列扩展性。在搭建数据框架中需要注意的点是:需要实现公司级别的业务数据架构。基于业务对整个公司的数据进行体系化的梳理,任何的业务变化都会体现在数据之上,实现数据充分体现业务现状的目的。要完成这一步的关键是完成公司级别的主数据管理:明确各项数据的业务含义和口径、明确每个数据的职责单位、打通数据链路,推动数据共享。
引领团队走向胜利:做“排长”而不要做“军长”;让合适的人做合适的事;明确规则,及时兑现。
数据分析与运营
- 数据分析与可视化:谁是安全圈的吃鸡第一人(学到了)
数据分析与可视化:收集数据集--->观察数据集--->社群发现与社区关系--->玩家画像。 - 请分享一下数据分析方面的思路,如何做好数据分析?
核心点:数据分析的问题:业务的数据分析指标体系(点线面体)。数据分析的方法:分类和对比。
安全数据分析
- Data-Knowledge-Action: 企业安全数据分析入门(优秀,学到了)
综述: 1、让模型理解业务,基于业务历史行为建立异常基线,在异常的基础上检测威胁;将运营结果反馈到模型,将误报视作正常行为回流。2、安全运营可运营,降低事件调查成本,自动化信息收集与聚合。3、随着数据的积累,安全数据分析将向基于图结构的高级知识表达方式发展。(这点深表赞同)4、对场景、攻击模式、数据的认识深度,远比选择工具重要。 - Security Data Science Learning Resources
综述:作者的研究点也是安全数据科学,整理了一些学习方法和学习资源。学习方法主要分为三个方面:谷歌学术、Twitter、安全会议。谷歌学术关注知名研究者以及他们新出的文章,关注引用了你关注的文章的文章,Twitter关注细分安全领域的人群,关注安全会议以及会议议程。学习资源:书籍和课程。 - 快速搭建一个轻量级OpenSOC架构的数据分析框架(一)(学到了)
框架:行文思路:由粗变细(由框架到举例子(由框架到场景到实际架构))。OpenSOC介绍(框架组成和工作流程)---》构建轻量级OpenSOC(聚焦具体场景和工具及具体架构)---》搭建步骤(每一步的环境搭建及配置)---》效果展示。 - 先知talk:从数据视角探索安全威胁
- 大数据威胁建模方法论(学到了很多)
- 安全日志维度随想
- 数据安全分析思想探索
- DataCon 2019: 1st place solution of malicious DNS traffic & DGA analysis(学到了)
我的理解:涉及的知识点有:安全场景:DNS安全;数据处理:tshark工具的使用,MaxCompute和SQL的使用,PAI预分析和可视化;特征工程:DNS_type、src_ip维度的特征;异常检测算法:单特征3sigma检测;人工提取特征规则。
第一小题DNS恶意流量的异常检测:个人吸收80%,整理流程无障碍,每步流程中的细节和工具还未完全掌握,比如DNS安全场景了解不全面、tshark的大量数据解析、统计特征的全面提取、SQL语句做特征化;
第二小题DGA的多分类:个人吸收50%,流程搞懂了,但是对一些问题的理解还不到位,比如社区算法 - 基于大数据企业网络威胁发现模型实践
我的理解:问题:多源安全分析设备和服务(威胁数据)的横向和纵向联动。
Algorithmus
KI
算法体系
- 机器学习算法集锦:从贝叶斯到深度学习及各自优缺点
算法知识框架:主要从算法的定义、过程、代表性算法、优缺点解释回归、正则化算法、人工神经网络、深度学习||决策树算法、集成算法||支持向量机||降维算法、聚类算法||基于实例的算法||贝叶斯算法||关联规则学习算法||图模型。
个人理解:回归系列主要基于线性回归和逻辑回归衍生,包括回归、正则化算法、人工神经网络、深度学习;树系列主要基于决策树衍生,包括决策树和基于树的集成学习算法;支持向量机属于老牌算法;降维算法和聚类算法主要基于数据的内在结构描述数据;基于实例的算法实际上并没有训练的过程,代表性算法是KNN,基于记忆的学习;贝叶斯算法利用贝叶斯定理计算输出概率;关联规则学习算法能够提取数据中变量之间的关系的最佳解释;图模型是一种概率模型,可以表示随机变量之间的条件依赖结构。 - Categories of algorithms non exhaustive (学到了)
算法知识框架:学到了搭建自己的算法体系。
基础知识
- HTTP DATASET CSIC 2010
Security Data Set-CSIC2010 : A security data set automatically generated based on e-Commerce Web application, including 36,000 normal requests and 25,000 abnormal requests. Abnormal requests include: SQL injection, buffer overflow, information collection, file leakage, CRLF injection, XSS etc . - 分类模型的性能评估——以SAS Logistic 回归为例(3): Lift 和Gain
- 机器学习中非均衡数据集的处理方法?
非均衡数据集:上采样和下采样、正负样本的惩罚权重(scikit-learn的SVM为例:class_weight:{dict,'balanced'})、组合/集成方法(从大样本中抽取多个小样本训练模型再集成)、特征选择(小样本量具有一定规模的时候,选择显著型的特征) - 机器学习算法中GBDT 和XGBOOST 的区别有哪些?
算法比较:GBDT基分类器为CART,XGB的分类器可以是多种基分类器,比如线性分类器,这时候就相当于L1、L2正则项的逻辑回归或线性回归;传统的GBDT在优化时用到的是一阶导数,XGB则对损失函数进行了二阶泰勒公式的展开,精度变高;XGB并行处理(特征粒度的并行,对特征值进行预排序存储为block结构,在进行节点分类的时候,需要计算每个特征的增益,最终选择增益最大的那个特征去做分类,那么各个特征的增益计算就可以开多线程进行),相对于GBM速度飞跃;剪枝时,当新增分类带来负增益时,GBM会停止分裂,而XGB一直分类到指定的最大深度,然后进行后全局剪枝;从最优化的角度来看,GBDT采用的是数值优化的思维,用的最速下降法去求解Loss function的最优解,其中用CART决策树去拟合负梯度,用牛顿法求步长,而XGB用的是解析的思维,对Loss function展开到二阶近似,求得解析解,用解析解作为Gain来建立决策树,使得Loss function最优。 - SVM和logistic回归分别在什么情况下使用?
算法使用场景-SVM和逻辑回归使用场景:需要根据特征数量和训练样本数量来确定。如果特征数相对于训练样本数已经够大了,使用线性模型就能取得不错的效果,不需要过于复杂的模型,则使用LR或线性核函数的SVM。 If the training samples are large enough and the number of features is small, better prediction performance can be obtained through SVM with complex kernel functions. If the samples do not reach millions, SVM with complex kernel functions will not cause the operation to be too slow . .如果训练样本特别大,使用复杂核函数的SVM已经会导致运算过慢了,因此应该考虑引入更多特征,然后使用线性SVM或者LR来构造模型。 - gbdt的残差为什么用负梯度代替?
- 欧氏距离与马氏距离
- 机器学习算法常用指标总结
- 分类模型评估之ROC-AUC曲线和PRC曲线
maschinelles Lernen
- 平均数编码:针对高基数定性特征(类别特征)的数据预处理/特征工程
- Mean Encoding
- kaggle编码categorical feature总结
- Python target encoding for categorical features
- Mean (likelihood) encodings: a comprehensive study
- 如何在Kaggle 首战中进入前10%
- kaggle竞赛总结
- 分享一波关于做Kaggle比赛,Jdata,天池的经验,看完我这篇就够了
- 为什么在实际的kaggle比赛中,GBDT和Random Forest效果非常好?
有监督学习-树系列算法:单模型,gradient boosting machine和deep learning是首选。gbm不需要复杂的特征工程,不需要太多时间去调参数,dl则需要比较多的时间去调网络结构。从overfit角度理解,两者都有overfit甚至perfect fit的能力,overfit能力越强,可塑性越强,然后我们要解决的问题就是如果把模型训练的“恰好”,比如gbm里有early_stopping功能。线性回归模型就缺乏overfit能力,如果实际数据符合线性模型的关系,那可以得到很好的结果,如果不符合的话,就需要做特征工程,可特征工程又是一个比较主观的过程。树的优势,非参数模型,gbm的overfit能力强。而random forest的perfact fit能力很差,这是因为rf的树是独立训练的,没有相互协作,虽然是非参数型模型,但是浪费了这个先天优势。 - 【总结】树类算法认知总结
有监督学习-树类算法:分类树和回归树的区别;避免决策树过拟合的方法;随机森林怎么应用到分类和回归问题上;kaggle上为啥GBDT比RF更优;RF、GBDT、XGBoost的认知(原理、优缺点、区别、特性)。 - LightGBM
- LightGBM算法总结
- 『我爱机器学习』集成学习(四)LightGBM
- 如何玩转LightGBM(官方slides讲解)
有监督学习-LightGBM-个人理解: LightGBM几大特性及原理:直方图分割及直方图差加速(直方图两大改进:直方图复杂度=O(#feature×#data),GOSS降低样本数,EFB降低特征数)-》效率和内存提升。Leaf-wise with max depth limitation取代Level-wise-》准确率提升。支持原生类别特征。并行计算:数据并行(水平划分数据)、特征并行(垂直划分数据)、PV-Tree投票并行(本质上是数据并行)。 - 快速弄懂机器学习里的集成算法:原理、框架与实战
- 时间序列数据的聚类有什么好方法?
无监督学习-时间序列问题:传统的机器学习数据分析领域:提取特征,使用聚类算法聚集;在自然语言处理领域:为了寻找相似的新闻或是把相似的文本信息聚集到一起,可以使用word2vec把自然语言处理成向量特征,然后使用KMeans等机器学习算法来作聚类;另一种做法是使用Jaccard相似度来计算两个文本内容之间的相似性,然后使用层次聚类的方法来作聚类。常见的聚类算法:基于距离的机器学习聚类算法(KMeans)、基于相似性的机器学习聚类算法(层次聚类)。对时间序列数据进行聚类的方法:时间序列的特征构造、时间序列的相似度方法。如果使用深度学习的话,要么就提供大量的标签数据;要么就只能使用一些无监督的编码器的方法。 - 凝聚式层次聚类算法的初步理解
无监督学习-层次聚类:算法步骤:计算邻近度矩阵--->(合并最接近的两个簇--->更新邻近度矩阵)(repeat),直到达到仅剩一个簇或达到终止条件。 - 推荐算法入门(1)相似度计算方法大全
无监督学习-层次聚类-相似性计算:曼哈顿距离、欧式距离、切比雪夫距离、余弦相似度、皮尔逊相关系数、Jaccard系数。
tiefes Lernen
CPU环境搭建
- tensorflow issues#22512
Nature of the problem : Error: ImportError: DLL load failed, reason: missing dependencies, solution: pip install --index-url https://pypi.douban.com/simple tensorflow==2.0.0, dependencies will be installed automatically .
GPU环境搭建
- Tensorflow和Keras 常见问题(持续更新~)(坑点)
- Tested build configurations(版本对应速查表)
- windows tensorflow-gpu的安装(靠谱)
- windows下安装配置cudn和cudnn
问题本质:总的来说,是英伟达显卡驱动版本、cuda、cudnn和tensorflow-gpu之间版本的对应问题。最好装tensorflow-gpu==1.14.0,tensorflow-gpu==2.0需要cuda==10.0,10.2会报错,tensorflow-gpu==2.0不支持。 - win10搭建tensorflow-gpu环境
问题本质:CUDA的各种环境变量添加。
深度学习基础知识
- 深度学习中的batch的大小对学习效果有何影响?
- Batch Normalization原理与实战(还没完全看懂)
神经网络基本部件
- 如何计算感受野(Receptive Field)——原理感受野:卷积层越深,感受野越大,计算公式为(N-1)_RF = f(N_RF, stride, kernel) = (N_RF - 1) * stride + kernel,思路为倒推法。
- 如何理解空洞卷积(dilated convolution)谭旭的回答空洞卷积:池化层减小图像尺寸同时增大感受野,空洞卷积的优点是不做pooling损失信息的情况下,增大感受野。3层3*3的传统卷积叠加起来,stride为1的话,只能达到(kernel_size-1)layer+1=7的感受野,和层数layer成线性关系,而空洞卷积的感受野是指数级的增长,计算公式为(2^layer-1)(kernel_size-1)+kernel_size=15。
- 空洞卷积(dilated convolution)感受野计算
- 空洞卷积(dilated Convolution)
- 直观理解神经网络最后一层全连接+Softmax(便于理解)
全连接层:可以理解为对特征的加权求和。
神经网络基本结构
- 一组图文,读懂深度学习中的卷积网络到底怎么回事?
卷积神经网络:卷积层参数:内核大小(卷积视野3乘3)、步幅(下采样2)、padding(填充)、输入和输出通道。卷积类型:引入扩张率参数的扩张卷积、转置卷积、可分离卷积。 - 卷积神经网络(CNN)模型结构
- 总结卷积神经网络发展历程- 没头脑的文章(很全面)
- 三次简化一张图:一招理解LSTM/GRU门控机制(很清晰)
循环神经网络:文中电路图的形式好理解。RNN:输入状态、隐藏状态。LSTM:输入状态、隐藏状态、细胞状态、3个门。GRU:输入状态、隐藏状态、2个门。LSTM和GRU通过设计门控机制缓解RNN梯度传播问题。 - gcn
- GRAPH CONVOLUTIONAL NETWORKS
图神经网络:相较于CNN,区别是图卷积算子计算公式。 - keras-attention-mechanism
神经网络应用
- [AI识人]OpenPose:实时多人2D姿态估计| 附视频测试及源码链接
- 使用生成对抗网络(GAN)生成DGA
- GAN_for_DGA
- 详解如何使用Keras实现Wassertein GAN
- Wasserstein GAN in Keras
- WassersteinGAN
- keras-acgan
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题- 综述和实践
NLP :传统的高维稀疏->现在的低维稠密。注意事项:类目不均衡、理解数据(badcase)、fine-tuning(只用word2vec训练的词向量作为特征表示,可能会损失很大效果,预训练+微调)、一定要用dropout、避免训练震荡、超参调节、未必一定要softmax loss、模型不是最重要的、关注迭代质量(为什么?结论?下一步?)
Verstärkungslernen
- 深度强化学习的弱点和局限
- 关于强化学习的局限的一些思考
强化学习的局限性:采样效率很差、很难设计一个合适的奖励函数。
Anwendungsgebiete
- 全球最全?的安全数据网站(有时间得好好整理一下)
- 初探机器学习检测PHP Webshell
- 基于机器学习的Webshell 发现技术探索
- 网络安全即将迎来机器对抗时代?
智能安全-智能攻击:国外已经在研究利用机器学习打造更智能的攻击工具,比如深度强化学习,就是深度学习和强化学习的结合,可以感知环境,做出最优决策,可能被应用到漏洞扫描器里,使扫描器能够自动化地入侵目标。
个人理解:国外已有案例Deep Exploit就是利用深度强化学习结合metasploit进行自动化地渗透测试,国内还没有看到过相关公开案例。由于学习门槛高、安全本身攻击场景需要精细化操作、弱智能化机器学习导致的机器学习和安全场景结合深度不够等一系列的问题,已有的机器学习+安全的大多数研究主要集中在安全防护方面,机器学习+攻击方面的研究较少且局限,但是我相信这个场景很有潜力,或许以后就成为蓝方的攻击利器。 - 人工智能反欺诈三部曲之:设备指纹
智能安全-业务安全-设备指纹:ip、cookie、设备ID ;主动式设备指纹:使用JS或SDK从客户端抓取各种各样的设备属性值,然后组合,通过hash算法得到设备ID;优点:Web内或者App内准确率高。 Disadvantages : Active device fingerprinting will generate different device IDs between Web and App and between different browsers, and cannot achieve device association across Web and App, and between different browsers; due to reliance on client code, fingerprinting It is less confrontational in anti-fraud Szenarien.被动式设备指纹:从数据报文中提取设备OS、协议栈和网络状态的特征集,并结合机器学习算法识别终端设备。优点:弥补了主动式设备指纹的缺点。缺点:占用处理资源多;响应时延比主动式长。 - 风险大脑支付风险识别初赛经验分享【谋杀电冰箱-凤凰还未涅槃】
智能安全-业务安全-风控:个人理解见:https://github.com/404notf0und/Risk-Operation-Detection/blob/master/atec.ipynb。 - 机器学习在互联网巨头公司实践
入侵检测:机器学习和统计建模的主要区别:机器学习主要依赖数据和算法,统计建模依赖建模者对数据特征的了解。两者的优缺点:机器学习:打标数据难获取,如果采用非监督学习,则性能不足以运维;机器学习结果不可解释。所以现在机器学习在做入侵检测的时候,一般都要限定一个特定的场景。统计建模:数据预处理阶段移除正常数据的干扰(重点关注查全率,强调过正常数据的过滤能力,尽可能筛除正常数据),构建能够识别恶意可疑行为的攻击模型(重点关注precision,强调模型对异常攻击模式判断的准确性,攻击链模型),缺点是泛化能力不足、在入侵检测一些场景中,模型易被干扰。我们的最终目的:大数据场景下安全分析可运维。 - Web安全检测中机器学习的经验之谈
Web安全:从文本分类的角度解决Web安全检测的问题。数据样本的多样性,短文本分类,词向量,句向量,文本向量。文本分类+多维度特征。与传统方法做对比得出更好的检测方式:传统方法+机器学习:传统waf/正则规则给数据打标;传统方法先进行过滤。 - 词嵌入来龙去脉(学到了)
NLP :DeepNLP的核心关键:语言表示--->NLP词的表示方法类型:词的独热表示和词的分布式表示(这类方法都基于分布假说:词的语义由上下文决定,方法核心是上下文的表示以及上下文与目标词之间的关系的建模)--->NLP语言模型:统计语言模型--->词的分布式表示:基于矩阵的分布表示、基于聚类的分布表示、基于神经网络的分布表示,词嵌入--->词嵌入(word embedding是神经网络训练语言模型的副产品)--->神经网络语言模型与word2vec。 - 深入浅出讲解语言模型
NLP :NLP统计语言模型:定义(计算一个句子的概率的模型,也就是判断一句话是否是人话的概率)、马尔科夫假设(随便一个词出现的概率只与它前面出现的有限的一个或几个词有关)、N元模型(一元语言模型unigram、二元语言模型bigram)。 - 有谁可以解释下word embedding? - YJango的回答- 知乎
NLP :单词表达:one hot representation、distributed representation。Word embedding:以神经网络分析one hot representation和distributed representation作为例子,证明用distributed representation表达一个单词是比较好的。word embedding就是神经网络分析distributed representation所显示的效果,降低训练所需的数据量,就是要从数据中自动学习出输入空间到distributed representation空间的映射f(相当于加入了先验知识,相同的东西不需要分别用不同的数据进行学习)。训练方法:如何自动寻找到映射f,将one hot representation转变成distributed representation呢?思想:单词意思需要放在特定的上下文中去理解,例子:这个可爱的泰迪舔了我的脸和这个可爱的京巴舔了我的脸,用输入单词x 作为中心单词去预测其他单词z 出现在其周边的可能性(至此我才明白为什么说词嵌入是神经网络训练语言模型的副产品这句话)。用输入单词作为中心单词去预测周边单词的方式叫skip-gram,用输入单词作为周边单词去预测中心单词的方式叫CBOW。 - Chars2vec: character-based language model for handling real world texts with spelling errors and…
- Character Level Embeddings
- 使用TextCNN模型探究恶意软件检测问题
恶意软件检测:改进分为两个方面:调参和结构。调参:Embedding层的inputLen、output_dim,EarlyStopping,样本比例参数class_weight,卷积层和全连接层的正则化参数l2,适配硬件(GPU、TPU)的batch_size。结构:增加了全局池化层。
学到了:一个trick,通过训练集和评价指标logloss计算测试集的各标签数量,以此调整训练阶段的参数class_weight,还可以事先达到“对答案”的效果。和一个T大大佬在datacon域名安全检测比赛中使用的trick如出一辙。 - 基于海量url数据识别视频类网页
CV-行文思路:问题:视频类网页识别。解决方式:url粗筛->视频网页规则粗筛->视频网页截屏及CNN识别。
行业发展
- 认知智能再突破,阿里18 篇论文入选AI 顶会KDD
认知智能:计算智能->感知智能->认知智能。快速计算、记忆、存储->识别处理语言、图像、视频->实现思考、理解、推理和解释。认知智能的三大关键技术:知识图谱是底料、图神经网络是推理工具、用户交互是目的。 - 未来3~5 年内,哪个方向的机器学习人才最紧缺? - 王喆的回答
要点简记:站在机器学习“工程体系”之上,综合考虑“模型结构”,“工程限制”,“问题目标”的算法“工程师”。我的理解:红利的迁移,模型结构单点创新带来的收益->体系结构协同带来的收益。 阿里技术副总裁贾扬清:我对人工智能的一点浅见
AI发展:神经网络和深度学习的成功与局限,成功原因是大数据和高性能计算,局限原因是结构化的理解和小数据上的有效学习算法。 AI这个方向会怎么走?传统的深度学习应用,比如图像、语音等,应该如何输出产品和价值?而不仅仅是停留在安防这个层面,要深入到更广阔的领域。除了语音和图像之外,如何解决更多问题?而不仅仅是停留在解决语音图像等几个领域内的问题。
综合素质
- 算法工程师必须要知道的面试技能雷达图(学到了)
个人发展-必备技术素质:算法工程师必备技术素质拆分:知识、工具、逻辑、业务。 On the basis of meeting the minimum requirements, algorithm engineers have relatively comprehensive capabilities in these four aspects, including both "algorithm" and "engineering", while big data engineers focus on "tools" and researchers focus on "knowledge" and "logic" .
针对安全业务的算法工程师就是安全算法工程师。为了便于理解,举个例子,如果用XGBoost解决某个安全问题,那么可以由浅入深理解,把知识、工具、逻辑、业务四个方面串起来:
1.GBDT的原理(知识)
2.决策树节点分裂时是如何选择特征的? (Wissen)
3.写出Gini Index和Information Gain的公式并举例说明(知识)
4.分类树和回归树的区别是什么(知识)
5.与Random Forest对比,理解什么是模型的偏差和方差(知识)
6.XGBoost的参数调优有哪些经验(工具)
7.XGBoost的正则化和并行化分别是如何实现的(工具)
8.为什么解决这个安全问题会出现严重的过拟合问题(业务)
9.如果选用一种其他模型替代XGBoost或改进XGBoost你会怎么做? Warum? (业务、逻辑、知识)。
以上,就是以“知识”为切入点,不仅深度理解了“知识”,也深度理解了“工具”、“逻辑”、“业务”。
- [校招经验] BAT机器学习算法实习面试记录(学到了)
个人发展-面试经验:根据面试常遇到的问题再深入理解机器学习,储备自己的算法知识库。 - 机器学习如何才能避免「只是调参数」?(学到了)
个人发展-职业发展:机器学习工程师分为三种:应用型(能力:保持算法全栈,即数据、建模、业务、运维、后端,重点在建模能力,流程是遇到一个指定的业务场景应该迅速知道用什么数据做特征,用什么模型,这个模型在工程上的时效性和鲁棒性,最终会不会产生业务风险等一整套链路。预期目标:锻炼得到很强的业务敏感性,快速验证提出的需求)、造轮子型(多读顶会跟上时代节奏,且拥有超强的功能能力,打造ML框架,提供给应用型机器学习工程师使用)、研究型(AI Lab,读论文+试验性复现)。 Personal development: Develop business and engineering capabilities. The growth plan for the next few years is still the full-stack algorithm route. I will be independent in technology and bring KPIs in business. I will be promoted quickly + lead the team in the future .同时保持阅读习惯,多学习新知识。 - 做机器学习算法工程师是什么样的工作体验?
个人发展-工作体验:业务理解、数据清洗和特征工程、持续学习(增强解决方案的判断力)、编程能力、常用工具(XGB、TensorFlow、ScikitLearn、Pandas(表格类数据或时间序列数据)、Spark、SQL、FbProphet(时间序列)) - 大三实习面经(学到了)
- 如果你是面试官,你怎么去判断一个面试者的深度学习水平?
个人发展-心得体会:深度学习擅长处理具有局部相关性的问题和数据,在图像、语音、自然语言处理方面效果显著,因为图像是由像素构成,语音是由音位构成,语言是由单词构成,都有局部相关性,可以构造高级特征。 - 面试官如何判断面试者的机器学习水平? - 微调的回答- 知乎
个人发展-心得体会:考虑方法优点和局限性,培养独立思考的能力;正确判断机器学习对业务的影响力;学会分情况讨论(比如深度学习相对于机器学习而言);学习机器学习不能停留在“知道”的层次,要从原理级学习,甚至可以从源码级学习,知其然知其所以然,要做安全圈机器学习最6的。 - 两年美团算法大佬的个人总结与学习建议
个人发展-心得体会:算法的基本认识(知识)、过硬的代码能力(工具)、数据处理和分析能力(业务和逻辑)、模型的积累和迁移能力(业务和逻辑)、产品能力、软实力。
Beruf
Karriereplanung
Denken
- 如何解决思维混乱、讲话没条理的情况?(学到了)
结构化思维->讲话有条理。 - 哪些思维方式是你刻意训练过的? (学到了)
结构化思维
金字塔思维:结论先行,以上统下,归类分组,逻辑递进。
金字塔结构:纵向延伸,横向分类。
如何得出金字塔结论:归纳法,演绎推理法。实际生活中,不是每时每刻都有相关的模型套用和演绎法的,这时候就用归纳法,自下而上进行梳理,得出结论,比如头脑风暴把闪过的碎片想法全部写下来,再抽象与分类,最后得出结论。 - 厉害的人是怎么分析问题的?(学到了)
Define the problem/describe the problem: The essence of the problem is the gap between reality and expectations ; clarify the expected value B', accurately locate the current situation B, and use the gap B--->B' to accurately describe the Problem.
分析问题/解决问题:不能从现状B出发,找寻一条B--->B'的路径,要透过现象看本质。方法A,现实B,期望B',变量C。校准期望B',重构方法A,消除变量C。
kommunizieren
verwalten
- “我是技术总监,你干嘛总问我技术细节?”
(快速发展期、平稳期、衰退期等业务发展时期作为时间轴)(中高层管理者)(需要掌握)(应用场景、技术基础、技术栈中的技术细节)。技术基础要扎实,技术栈了解程度深(对技术原理和细节清楚),应用场景不能浮于表面。总的来说就是一句话:技术细节与技术深度。 - 阿里巴巴高级算法专家威视:组建技术团队的一些思考(学到了)
行文思路:团队的定位(定位(能力、业务、服务)、壁垒(以不变应万变沉淀风险管控知识作为壁垒)和价值(提供不同层次的服务形式))-》团队的能力(连接、生产、传播、服务)-》组织与个人的关系-》招人-》用人-》对内管理模式(找对前进的方向、绩效的考核(3个维度:业务结果、能力进步、技术影响力))
学到了:建设技术体系解决某一类问题,而不是某个技术点去解决某一个问题。 - 26岁当上数据总监,分享第一次做Leader的心得
团队管理方面的基本功和方法论:定策略、建团队、立规矩、拿结果。
定策略:要明确公司高层的真实目的;对自己的团队了如指掌;管理者专精的行业知识和经验。
建团队:避免嫉贤妒能、职场近亲、玻璃心。
立规矩:立规矩守规矩。
拿结果:注意吃相。
管理中常见的误区:做管理后放弃原来专业(要关注行业发展方向和前沿技术);过度管理(要自循环的稳定成熟团队);过度追求团队稳定(衡量团队稳定的核心标准不是人员的稳定,而是团队的效率和产出是否能够有持续稳定的增长) - 什么特质的员工容易成为管理者
公司内部晋升管理者:天时:企业/行业所处的阶段;地利:部门/业务所处的阶段;人和:人际关系+自身能力。
跳槽成为管理者:大公司跳槽到小公司,寻找职业突破,弊端是跳出去容易跳回来难;成为行业内有影响力的人物,被大公司挖角。大部分人都是第一种情况,在大公司的同学要多一点耐心,通过努力在公司内晋升,因为曲线救国式的跳槽已经没有市场了。 - 技术部门Leader是不是一定要技术大牛担任?
核心点:Manager vs Tech Leader、方法论、软技能、赋能成员、综合。
denken
- 好的研究想法从哪里来
研究的本质是对未知领域的探索,是对开放问题的答案的追寻。“好”的定义-》区分好与不好的能力-》全面了解所在研究方向的历史和现状-》实践法/类比法/组合法。这就好比是机器学习的训练和测试阶段,训练:全面了解所在研究方向的历史和现状,判断不同时期的研究工作的好与不好。测试:实践法/类比法/组合法出的idea,判断自己的研究工作好与不好。 - 科研论文如何想到不错的idea?
模块化学习、交叉、布局可预期的趋势。 - 人在年轻的时候,最核心的能力是什么?
核心点:达到以前从未达到的高度:基本的事情做到极致、专注、坚持长久做一件事、延迟满足、认清自己+了解环境->准确定位、
Dinge zu beachten
- 领域点-线-面体系:点:自己focus的领域;线:上游和下游;面:大领域。不要过度focus在自己工作的领域,要有全局化的眼光,特别是自己的上游和下游。
- 日常学习点-线-面体系:点:自己focus的安全数据分析领域;线:安全/数据分析;面:全局安全内容/行业发展/职业规划。 Study a small field for at least one hour every day; read intensively for at least half an hour every day/at least one quality article on security/data analysis/industry development/career planning; browse a large number of incremental articles/stock articles täglich.保持学习与思考的敏感性。
Anhang
国外优质技术站点
- https://resources.distilnetworks.com
站点概况:专注于机器流量对抗与缓解。 - http://www.covert.io
技术栈:Jason Trost,专注于安全研究、大数据、云计算、机器学习,即安全数据科学。 - http://cyberdatascientist.com
站点概括:专注于安全数据科学,提供网络安全、统计学和AI等学习资料,并提供14个安全数据集,包括:垃圾邮件、恶意网站、恶意软件、Botnet等。没有secrepo.com提供的资料全面。 - https://towardsdatascience.com
站点概括:专注于数据科学。
国内优秀技术人
- michael282694
技术栈:数据分析挖掘产品开发、爬虫、Java、Python。 - LittleHann
技术栈:我也不知道该怎么描述,Han师傅会的太多了,C++、Java、Python、PHP、Web安全、系统安全,不过目前好像做算法多一些。 - FeeiCN
技术栈:专注自动化漏洞发现和入侵检测防御。 - xiaojunjie
技术栈:专注于代码审计、CTF。 - 云雷
技术栈:阿里云存储技术专家,专注于日志分析与业务,日志计算驱动业务增长。 - iami
技术栈:主要研究Web安全、机器学习,喜欢Python和Go。一直偷学师傅的博客。 - cdxy
技术栈:早先主要做Web安全,CTF,代码审计,现在主要做安全研究与数据分析,初步估算技术领先我1~2年,师傅别学了。 - csuldw
技术栈:专注于机器学习、数据挖掘、人工智能。 - molunerfinn
技术栈:专注于前端,北邮大佬,和404notfound同级。 - 刘建平Pinard
技术栈:机器学习、深度学习、强化学习、自然语言处理、数学统计学、大数据挖掘,相关tutorial非常棒。
verlassen
- Efficient and Flexible Discovery of PHP Vulnerability译文
- Efficient and Flexible Discovery of PHP Application Vulnerabilities原文
- The Code Analysis Platform "Octopus"
- A Code Intelligence System:The Octopus Platform


