byol pytorch
0.8.2
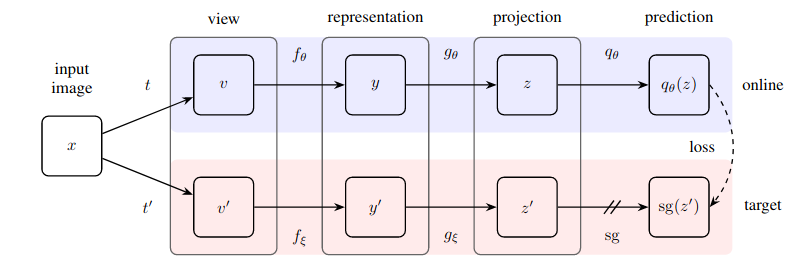
Praktische Umsetzung einer erstaunlich einfachen Methode zum selbstüberwachten Lernen, die einen neuen Stand der Technik erreicht (über SimCLR hinausgeht), ohne kontrastives Lernen und ohne die Benennung negativer Paare.
Dieses Repository bietet ein Modul, mit dem man problemlos jedes bildbasierte neuronale Netzwerk (Restnetzwerk, Diskriminator, Richtliniennetzwerk) umschließen kann, um sofort von unbeschrifteten Bilddaten zu profitieren.
Update 1: Es gibt jetzt neue Beweise dafür, dass die Batch-Normalisierung der Schlüssel zum reibungslosen Funktionieren dieser Technik ist
Update 2: Ein neues Papier hat die Chargennorm erfolgreich durch die Gruppennorm + Gewichtsstandardisierung ersetzt und widerlegt, dass Chargenstatistiken erforderlich sind, damit BYOL funktioniert
Update 3: Abschließend haben wir eine Analyse, warum dies funktioniert
Yannic Kilchers hervorragende Erklärung
Ersparen Sie Ihrer Organisation jetzt die Kosten für Etiketten :)
$ pip install byol-pytorchSchließen Sie einfach Ihr neuronales Netzwerk an und geben Sie (1) die Bildabmessungen sowie (2) den Namen (oder Index) der verborgenen Schicht an, deren Ausgabe als latente Darstellung für das selbstüberwachte Training verwendet wird.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Das ist so ziemlich alles. Nach viel Training sollte das verbleibende Netzwerk nun bei seinen nachgelagerten überwachten Aufgaben eine bessere Leistung erbringen.
Ein neuer Artikel von Kaiming He legt nahe, dass es bei BYOL nicht einmal erforderlich ist, dass der Ziel-Encoder ein exponentieller gleitender Durchschnitt des Online-Encoders ist. Ich habe beschlossen, diese Option einzubauen, damit Sie diese Variante problemlos für das Training verwenden können, indem Sie einfach das Flag use_momentum auf False setzen. Sie müssen update_moving_average nicht mehr aufrufen, wenn Sie diesen Weg gehen, wie im Beispiel unten gezeigt.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Während die Hyperparameter bereits auf das eingestellt wurden, was das Papier als optimal befunden hat, können Sie sie mit zusätzlichen Schlüsselwortargumenten für die Basis-Wrapper-Klasse ändern.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) Standardmäßig verwendet diese Bibliothek die Erweiterungen aus dem SimCLR-Artikel (der auch im BYOL-Artikel verwendet wird). Wenn Sie jedoch Ihre eigene Erweiterungspipeline angeben möchten, können Sie einfach Ihre eigene benutzerdefinierte Erweiterungsfunktion mit dem Schlüsselwort augment_fn übergeben.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)In der Arbeit scheinen sie zu versichern, dass eine der Erweiterungen eine höhere Wahrscheinlichkeit der Gaußschen Unschärfe aufweist als die andere. Sie können dies auch nach Herzenslust anpassen.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) Um die Einbettungen oder Projektionen abzurufen, müssen Sie lediglich ein return_embeddings = True Flag an die BYOL Lerninstanz übergeben
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) Das Repository bietet jetzt verteiltes Training mit ? Huggingface beschleunigen. Sie müssen lediglich Ihren eigenen Dataset an den importierten BYOLTrainer übergeben
Richten Sie zunächst die Konfiguration für verteiltes Training ein, indem Sie die Beschleunigungs-CLI aufrufen
$ accelerate config Erstellen Sie dann Ihr Trainingsskript wie unten gezeigt, beispielsweise in ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()Verwenden Sie dann erneut die Beschleunigungs-CLI, um das Skript zu starten
$ accelerate launch ./train.pyWenn Ihre nachgelagerte Aufgabe eine Segmentierung umfasst, sehen Sie sich bitte das folgende Repository an, das BYOL auf Lernen auf „Pixel“-Ebene erweitert.
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

