sinkhorn transformer
0.11.4
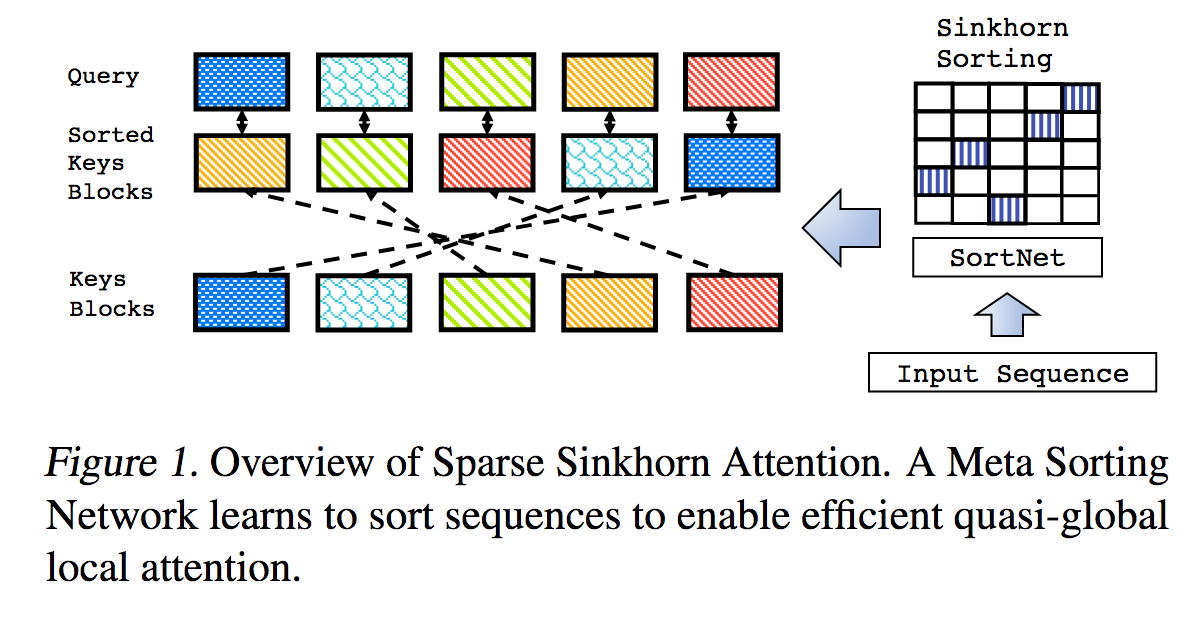
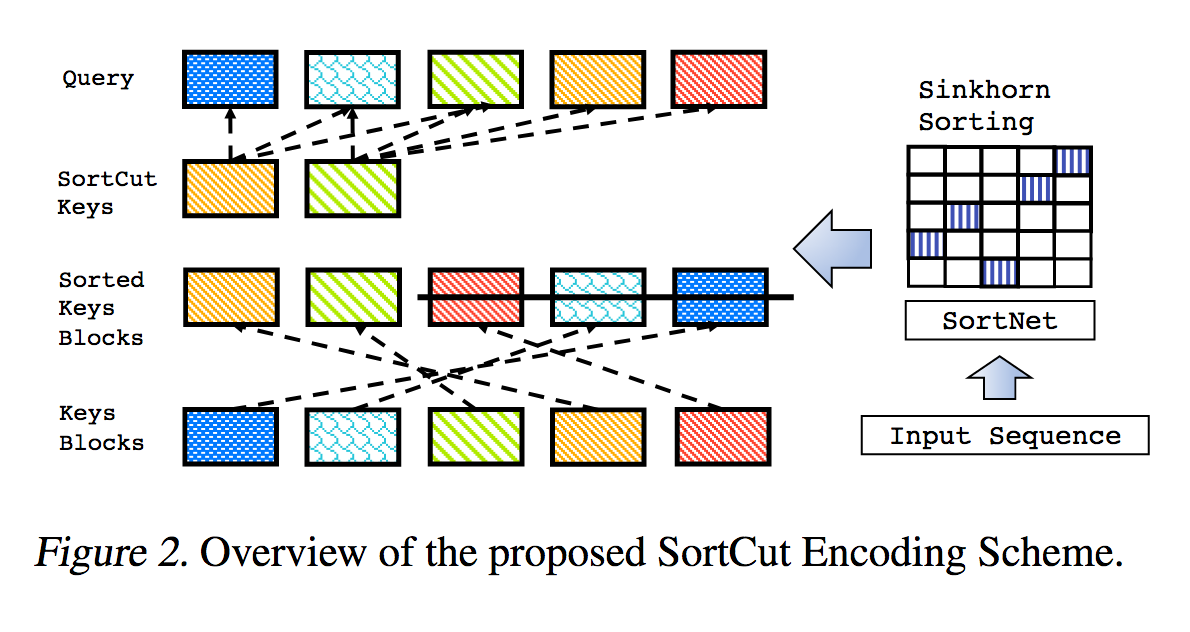
Dies ist eine Reproduktion der in Sparse Sinkhorn Attention beschriebenen Arbeit mit zusätzlichen Verbesserungen.
Es umfasst ein parametrisiertes Sortiernetzwerk, das mithilfe der Sinkhorn-Normalisierung eine Permutationsmatrix abtastet, die die relevantesten Schlüssel-Buckets den Abfrage-Buckets zuordnet.
Diese Arbeit führt auch reversible Netzwerke und Feed-Forward-Chunking (von Reformer eingeführte Konzepte) ein, um weitere Speichereinsparungen zu erzielen.
204.000 Token (Demonstrationszwecke)
$ pip install sinkhorn_transformerEin auf Sinkhorn Transformer basierendes Sprachmodell
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
bucket_size = 128 , # size of the buckets
causal = False , # auto-regressive or not
n_sortcut = 2 , # use sortcut to reduce memory complexity to linear
n_top_buckets = 2 , # sort specified number of key/value buckets to one query bucket. paper is at 1, defaults to 2
ff_chunks = 10 , # feedforward chunking, from Reformer paper
reversible = True , # make network reversible, from Reformer paper
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post attention dropout
attn_layer_dropout = 0.1 , # post attention layer dropout
layer_dropout = 0.1 , # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True , # tie layer parameters, from Albert paper
emb_dim = 128 , # embedding factorization, from Albert paper
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_glu = True , # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 2 , # replace N heads with local attention, suggested to work well from Routing Transformer paper
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
model ( x ) # (1, 2048, 20000)Ein einfacher Sinkhorn-Transformator, Schichten voller Sinkhorn-Aufmerksamkeit
import torch
from sinkhorn_transformer import SinkhornTransformer
model = SinkhornTransformer (
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128
)
x = torch . randn ( 1 , 2048 , 1024 )
model ( x ) # (1, 2048, 1024)Sinkhorn Encoder/Decoder-Transformator
import torch
from sinkhorn_transformer import SinkhornTransformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
bucket_size = 128 ,
max_seq_len = DE_SEQ_LEN ,
reversible = True ,
return_embeddings = True
). cuda ()
dec = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
causal = True ,
bucket_size = 128 ,
max_seq_len = EN_SEQ_LEN ,
receives_context = True ,
context_bucket_size = 128 , # context key / values can be bucketed differently
reversible = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). cuda ()
y = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). cuda ()
x_mask = torch . ones_like ( x ). bool (). cuda ()
y_mask = torch . ones_like ( y ). bool (). cuda ()
context = enc ( x , input_mask = x_mask )
dec ( y , context = context , input_mask = y_mask , context_mask = x_mask ) # (1, 4096, 20000) Standardmäßig beschwert sich das Modell, wenn eine Eingabe erfolgt, die kein Vielfaches der Bucket-Größe ist. Um zu vermeiden, dass Sie jedes Mal die gleichen Füllberechnungen durchführen müssen, können Sie die Hilfsklasse Autopadder verwenden. Falls vorhanden, kümmert es sich auch um die input_mask . Kontextbezogene Schlüssel/Werte und Masken werden ebenfalls unterstützt.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
from sinkhorn_transformer import Autopadder
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 2048 ,
bucket_size = 128 ,
causal = True
)
model = Autopadder ( model , pad_left = True ) # autopadder will fetch the bucket size and autopad input
x = torch . randint ( 0 , 20000 , ( 1 , 1117 )) # odd sequence length
model ( x ) # (1, 1117, 20000) Dieses Repository ist vom Papier abgewichen und verwendet nun Aufmerksamkeit anstelle des ursprünglichen Sortiernetzes + Gumbel Sinkhorn-Probenahme. Ich habe noch keinen spürbaren Leistungsunterschied festgestellt und das neue Schema ermöglicht es mir, das Netzwerk auf flexible Sequenzlängen zu verallgemeinern. Wenn Sie Sinkhorn ausprobieren möchten, verwenden Sie bitte die folgenden Einstellungen, die nur für nicht kausale Netzwerke funktionieren.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128 ,
max_seq_len = 8192 ,
use_simple_sort_net = True , # turn off attention sort net
sinkhorn_iter = 7 , # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2 , # use sortcut to reduce complexity to linear time
temperature = 0.75 , # gumbel temperature - default is set at reported best in paper
non_permutative = False , # allow buckets of keys to be sorted to queries more than once
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
model ( x ) # (1, 8192, 20000) Um die Vorteile der Verwendung von PKM zu erkennen, muss die Lernrate der Werte höher eingestellt werden als die der übrigen Parameter. (Empfohlen 1e-2 )
Sie können den Anweisungen hier folgen, um es richtig einzustellen: https://github.com/lucidrains/product-key-memory#learning-rates
Wenn Sinkhorn auf Sequenzen fester Länge trainiert wird, scheint es Probleme zu haben, Sequenzen von Grund auf zu dekodieren, was hauptsächlich auf die Tatsache zurückzuführen ist, dass das Sortiernetz Schwierigkeiten bei der Verallgemeinerung hat, wenn die Buckets teilweise mit Fülltokens gefüllt sind.
Zum Glück glaube ich, eine einfache Lösung gefunden zu haben. Schneiden Sie während des Trainings für kausale Netzwerke die Sequenzen nach dem Zufallsprinzip ab und erzwingen Sie die Generalisierung des Sortiernetzes. Um dies zu vereinfachen, habe ich ein Flag ( randomly_truncate_sequence ) für die AutoregressiveWrapper -Instanz bereitgestellt.
import torch
from sinkhorn_transformer import SinkhornTransformerLM , AutoregressiveWrapper
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 75 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000)Ich bin offen für Vorschläge, wenn jemand eine bessere Lösung gefunden hat.
Es besteht ein potenzielles Problem mit dem Kausalsortiernetzwerk, bei dem die Entscheidung, welche Schlüssel-/Wert-Buckets der Vergangenheit in einen Bucket sortiert werden, nur vom ersten Token abhängt und nicht vom Rest (aufgrund des Bucketing-Schemas und der Verhinderung des Durchsickerns zukünftiger Token). Vergangenheit).
Ich habe versucht, dieses Problem zu lösen, indem ich die Hälfte der Köpfe um die Eimergröße - 1 nach links gedreht habe, wodurch der letzte Token zum ersten wird. Dies ist auch der Grund, warum der AutoregressiveWrapper während des Trainings standardmäßig auf die linke Auffüllung setzt, um immer sicherzustellen, dass das letzte Token in der Sequenz mitbestimmt, was abgerufen werden soll.
Wenn jemand eine sauberere Lösung gefunden hat, lassen Sie es mich bitte in den Ausgaben wissen.
@misc { tay2020sparse ,
title = { Sparse Sinkhorn Attention } ,
author = { Yi Tay and Dara Bahri and Liu Yang and Donald Metzler and Da-Cheng Juan } ,
year = { 2020 } ,
url. = { https://arxiv.org/abs/2002.11296 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
}


