antialiased cnns
v0.3
Faltungsnetzwerke wieder verschiebungsinvariant machen
Richard Zhang. In ICML, 2019.
Führen Sie pip install antialiased-cnns
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True ) Wenn Sie bereits über ein Modell verfügen und Antialiasing durchführen und das Training fortsetzen möchten, kopieren Sie Ihre alten Gewichte:
import torchvision . models as models
old_model = models . resnet50 ( pretrained = True ) # old (aliased) model
antialiased_cnns . copy_params_buffers ( old_model , model ) # copy the weights overWenn Sie Ihr eigenes Modell ändern möchten, verwenden Sie die BlurPool-Ebene. Weitere Informationen zu unseren bereitgestellten Modellen und zur Verwendung von BlurPool finden Sie unten.
C = 10 # example feature channel size
blurpool = antialiased_cnns . BlurPool ( C , stride = 2 ) # BlurPool layer; use to downsample a feature map
ex_tens = torch . Tensor ( 1 , C , 128 , 128 )
print ( blurpool ( ex_tens ). shape ) # 1xCx64x64 tensorAktualisierungen
pip install antialiased-cnns und Modelle mit dem Flag pretrained=True laden.BlurPool -EbenePip installiert dieses Paket
pip install antialiased-cnnsOder klonen Sie dieses Repository und installieren Sie die Anforderungen (insbesondere PyTorch).
https://github.com/adobe/antialiased-cnns.git
cd antialiased-cnns
pip install -r requirements.txtIm Folgenden wird ein vorab trainiertes Antialiasing-Modell geladen, möglicherweise als Rückgrat für Ihre Anwendung.
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True , filter_size = 4 ) Wir bieten auch Gewichtungen für Antialiasing AlexNet , VGG16(bn) , Resnet18,34,50,101 , Densenet121 und MobileNetv2 (siehe example_usage.py).
Das Modul antialiased_cnns enthält die BlurPool -Klasse, die Unschärfe+Unterabtastung durchführt. Führen Sie pip install antialiased-cnns oder kopieren Sie das Unterverzeichnis antialiased_cnns .
Methodik Die Methodik ist einfach: Bewerten Sie zuerst mit Schritt 1 und verwenden Sie dann unsere BlurPool Ebene, um ein Antialiasing-Downsampling durchzuführen. Nehmen Sie die folgenden architektonischen Änderungen vor.
import antialiased_cnns
# MaxPool --> MaxBlurPool
baseline = nn . MaxPool2d ( kernel_size = 2 , stride = 2 )
antialiased = [ nn . MaxPool2d ( kernel_size = 2 , stride = 1 ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# Conv --> ConvBlurPool
baseline = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 2 , padding = 1 ),
nn . ReLU ( inplace = True )]
antialiased = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 1 , padding = 1 ),
nn . ReLU ( inplace = True ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# AvgPool --> BlurPool
baseline = nn . AvgPool2d ( kernel_size = 2 , stride = 2 )
antialiased = antialiased_cnns . BlurPool ( C , stride = 2 ) Wir gehen davon aus, dass der eingehende Tensor C Kanäle hat. Das Berechnen einer Ebene bei Schritt 1 anstelle von Schritt 2 erhöht den Speicher und die Laufzeit. Daher verzichten wir normalerweise auf Antialiasing bei der höchsten Auflösung (zu Beginn des Netzwerks), um einen starken Anstieg zu verhindern.
Fügen Sie Antialiasing hinzu und fahren Sie dann mit dem Training fort. Wenn Sie bereits ein Modell trainiert haben und dann Antialiasing hinzufügen, können Sie anhand dieses alten Modells eine Feinabstimmung vornehmen:
antialiased_cnns . copy_params_buffers ( old_model , antialiased_model )Wenn dies nicht funktioniert, können Sie einfach die Parameter (und nicht die Puffer) kopieren. Durch das Hinzufügen von Antialiasing werden keine Parameter hinzugefügt, daher sind die Parameterlisten identisch. (Es werden Puffer hinzugefügt, daher wird eine Heuristik verwendet, um die Puffer abzugleichen, was möglicherweise einen Fehler auslöst.)
antialiased_cnns . copy_params ( old_model , antialiased_model )Wir beobachten Verbesserungen sowohl bei der Genauigkeit (wie oft das Bild richtig klassifiziert wird) als auch bei der Konsistenz (wie oft werden zwei Schichten desselben Bildes gleich klassifiziert).
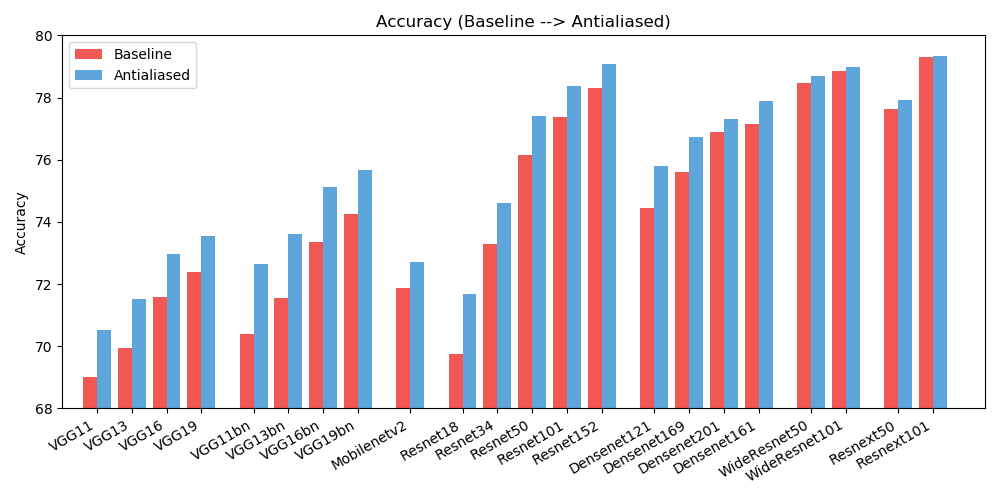
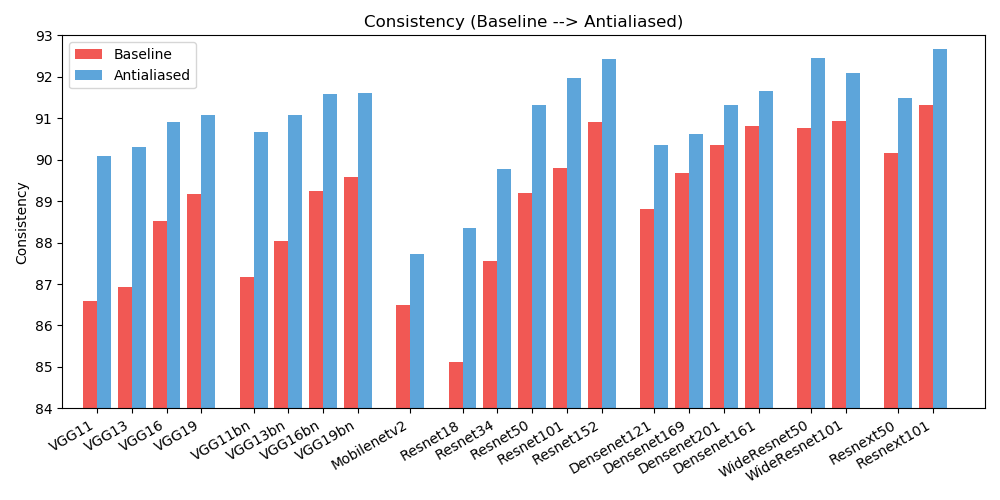
| GENAUIGKEIT | Grundlinie | Antialiasing | Delta |
|---|---|---|---|
| Alexnet | 56,55 | 56,94 | +0,39 |
| vgg11 | 69.02 | 70,51 | +1,49 |
| vgg13 | 69,93 | 71,52 | +1,59 |
| vgg16 | 71,59 | 72,96 | +1,37 |
| vgg19 | 72,38 | 73,54 | +1,16 |
| vgg11_bn | 70,38 | 72,63 | +2,25 |
| vgg13_bn | 71,55 | 73,61 | +2.06 |
| vgg16_bn | 73,36 | 75.13 | +1,77 |
| vgg19_bn | 74,24 | 75,68 | +1,44 |
| resnet18 | 69,74 | 71,67 | +1,93 |
| resnet34 | 73.30 | 74,60 | +1,30 |
| resnet50 | 76.16 | 77,41 | +1,25 |
| resnet101 | 77,37 | 78,38 | +1.01 |
| resnet152 | 78,31 | 79.07 | +0,76 |
| resnext50_32x4d | 77,62 | 77,93 | +0,31 |
| resnext101_32x8d | 79,31 | 79,33 | +0,02 |
| wide_resnet50_2 | 78,47 | 78,70 | +0,23 |
| wide_resnet101_2 | 78,85 | 78,99 | +0,14 |
| dichtennet121 | 74,43 | 75,79 | +1,36 |
| dichtennet169 | 75,60 | 76,73 | +1.13 |
| dichtennet201 | 76,90 | 77,31 | +0,41 |
| dichtennet161 | 77.14 | 77,88 | +0,74 |
| mobilenet_v2 | 71,88 | 72,72 | +0,84 |
| KONSISTENZ | Grundlinie | Antialiasing | Delta |
|---|---|---|---|
| Alexnet | 78,18 | 83,31 | +5.13 |
| vgg11 | 86,58 | 90.09 | +3,51 |
| vgg13 | 86,92 | 90,31 | +3,39 |
| vgg16 | 88,52 | 90,91 | +2,39 |
| vgg19 | 89,17 | 91.08 | +1,91 |
| vgg11_bn | 87,16 | 90,67 | +3,51 |
| vgg13_bn | 88.03 | 91.09 | +3.06 |
| vgg16_bn | 89,24 | 91,58 | +2,34 |
| vgg19_bn | 89,59 | 91,60 | +2.01 |
| resnet18 | 85.11 | 88,36 | +3,25 |
| resnet34 | 87,56 | 89,77 | +2.21 |
| resnet50 | 89,20 | 91,32 | +2.12 |
| resnet101 | 89,81 | 91,97 | +2.16 |
| resnet152 | 90,92 | 92,42 | +1,50 |
| resnext50_32x4d | 90,17 | 91,48 | +1,31 |
| resnext101_32x8d | 91,33 | 92,67 | +1,34 |
| wide_resnet50_2 | 90,77 | 92,46 | +1,69 |
| wide_resnet101_2 | 90,93 | 92.10 | +1,17 |
| dichtennet121 | 88,81 | 90,35 | +1,54 |
| dichtennet169 | 89,68 | 90,61 | +0,93 |
| dichtennet201 | 90,36 | 91,32 | +0,96 |
| dichtennet161 | 90,82 | 91,66 | +0,84 |
| mobilenet_v2 | 86,50 | 87,73 | +1,23 |
Um die Unordnung zu reduzieren, finden Sie hier erweiterte Ergebnisse (verschiedene Filtergrößen). Helfen Sie mit, die Ergebnisse zu verbessern!
Dieses Werk ist unter der Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License lizenziert.
Das gesamte Material wird unter der Creative Commons BY-NC-SA 4.0-Lizenz von Adobe Inc. zur Verfügung gestellt. Sie können das Material für nichtkommerzielle Zwecke verwenden, weiterverbreiten und anpassen , sofern Sie durch Zitieren unseres Artikels und Angabe etwaiger Änderungen die entsprechende Quellenangabe machen das du gemacht hast.
Das Repository baut auf dem PyTorch-Beispiel-Repository und dem Torchvision-Modell-Repository auf. Diese sind im BSD-Stil lizenziert.
Wenn Sie dies für Ihre Recherche nützlich finden, denken Sie bitte darüber nach, diesen Bibtex zu zitieren. Bitte wenden Sie sich mit Kommentaren oder Rückmeldungen an Richard Zhang <rizhang at adobe dot com>.


