awesome mojo
1.0.0

Mojo – eine neue Programmiersprache für alle Entwickler, KI/ML-Wissenschaftler und Softwareentwickler.
Eine kuratierte Liste fantastischer Mojo-Codes, Problemlösungen, Lösungen und in Zukunft Bibliotheken, Frameworks, Software und Ressourcen.
Lassen Sie uns hier sehr neues Technologiewissen und Best Practices sammeln.
Mojo ist eine Programmiersprache, die die Benutzerfreundlichkeit von Python mit den Leistungsfähigkeiten von C++ und Rust kombiniert. Darüber hinaus ermöglicht Mojo Benutzern, das umfangreiche Ökosystem der Python-Bibliotheken zu nutzen.
In Kürze
Mojo ist eine neue Programmiersprache, die die Lücke zwischen Forschung und Produktion schließt, indem sie das Beste der Python-Syntax mit Systemprogrammierung und Metaprogrammierung kombiniert.
hello.mojo oder hello. Die Dateierweiterung kann ein Emoji sein!
Sie können mehr darüber lesen, warum Modular dies tut. Warum Mojo
Was wir wollten, war ein innovatives und skalierbares Programmiermodell, das auf Beschleuniger und andere heterogene Systeme abzielen kann, die im KI-Bereich allgegenwärtig sind. ... Angewandte KI-Systeme müssen all diese Probleme angehen, und wir sind zu dem Schluss gekommen, dass es keinen Grund gibt, warum dies nicht mit nur einer Sprache möglich ist. So wurde Mojo geboren.
Aber Python hat seine Arbeit sehr gut gemacht =)
Wir sahen keinen Bedarf für Innovationen in der Sprachsyntax oder Community. Deshalb haben wir uns für das Python-Ökosystem entschieden, weil es so weit verbreitet ist, vom KI-Ökosystem geliebt wird und weil wir glauben, dass es eine wirklich schöne Sprache ist.
Mojo bedeutet „ein magischer Zauber“ oder „magische Kräfte“. Wir dachten, dies sei ein passender Name für eine Sprache, die Python magische Kräfte verleiht :python:, einschließlich der Erschließung eines innovativen Programmiermodells für Beschleuniger und andere heterogene Systeme, die heute in der KI allgegenwärtig sind.
Guido van Rossum, wohlwollender Diktator auf Lebenszeit und Christopher Arthur Lattner, angesehener Erfinder, Schöpfer und bekannter Führer der Mojo-Aussprache =)
Laut Beschreibung
Wer weiß, dass diese Programmiersprachen sehr glücklich sein werden, denn Mojo profitiert von enormen Lehren aus anderen Sprachen wie Rust, Swift, Julia, Zig, Nim usw.
[neu]
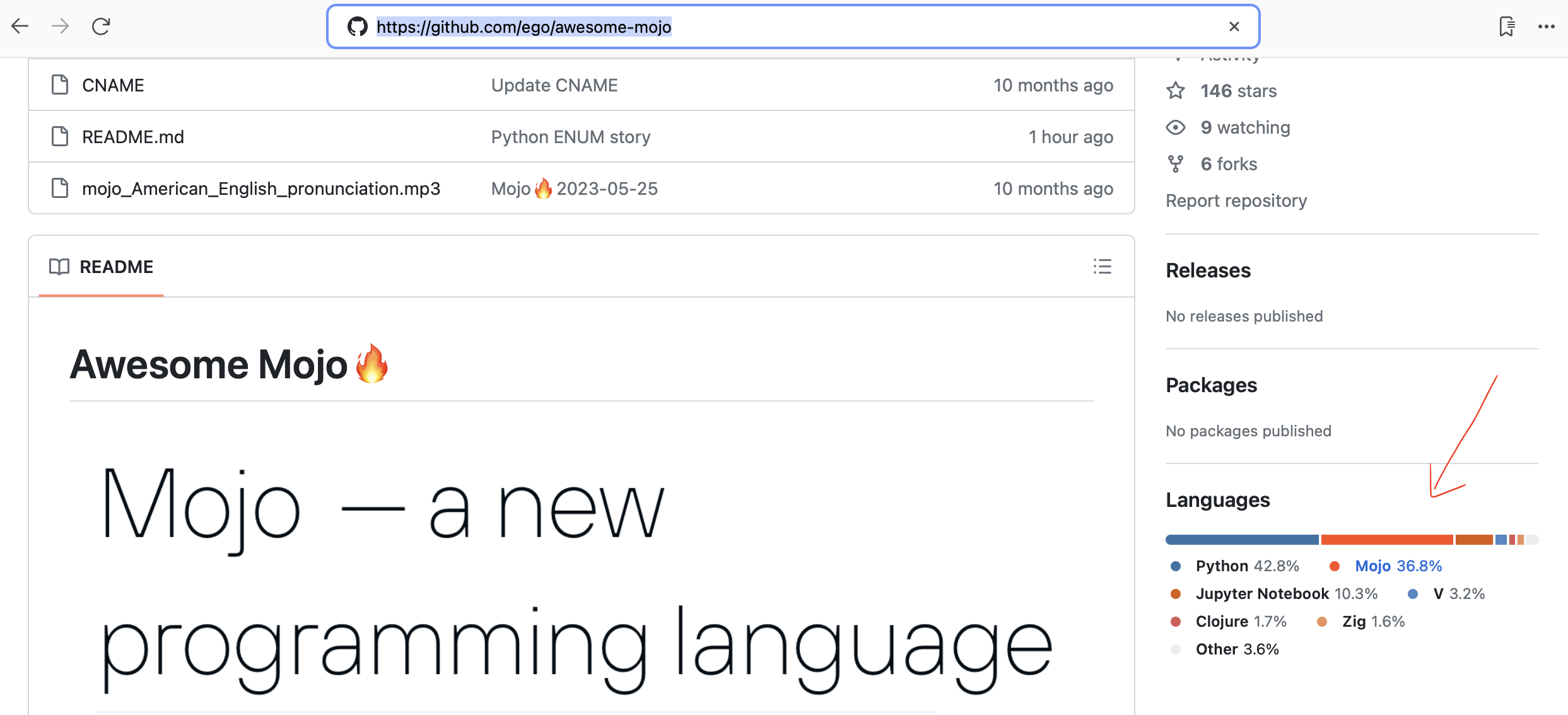
Github erkennt Mojo-Code jetzt automatisch!
Einfaches und schnelles HTTP-Framework für Mojo! Perfekt zum Erstellen von Webdiensten und einfachen APIs. Für Mojicianer
Benchmarking-Framework für LLama-Implementierungen
Automatisierte Python-zu-Mojo-Codeübersetzung
Programmiersprachen-Datenbankforschung
19. Oktober 2023 Mojo ist jetzt auf dem Mac verfügbar! Verwenden Sie die Entwicklerkonsole
Chris Lattner: Zukunft der Programmierung und KI | Lex Fridman Podcast #381
Mojo- und Python-Typsystem erklärt | Chris Lattner und Lex Fridman
Kann Mojo Python-Code ausführen? | Chris Lattner und Lex Fridman
Wechsel von Python zur Programmiersprache Mojo | Chris Lattner und Lex Fridman
Neues GitHub-Thema mojo-lang. So können Sie es verfolgen.
Guido van Rossum über Mojo = Python mit C++/GPU-Leistung?
Tensorstruktur mit einigen grundlegenden Operationen #251
Matrix fn mit Numpy #267
Aktualisierungen zu lambda und parameter und Funktionen höherer Ordnung in Mojo #244
25. Mai 2023, Guido van Rossum (gvanrossum#8415), Schöpfer und emeritierter BDFL von Python, besuchen Sie den öffentlichen Discord-Chat von Mojo
Warten auf eine Mojo-Syntaxhervorhebung auf GitHub
Neue Mojo-Veröffentlichung 24.05.2023
[alt]
Mojo
brew install hyperfinebrew install macchinapip3 install numpy matplotlib scipybrew install silicon
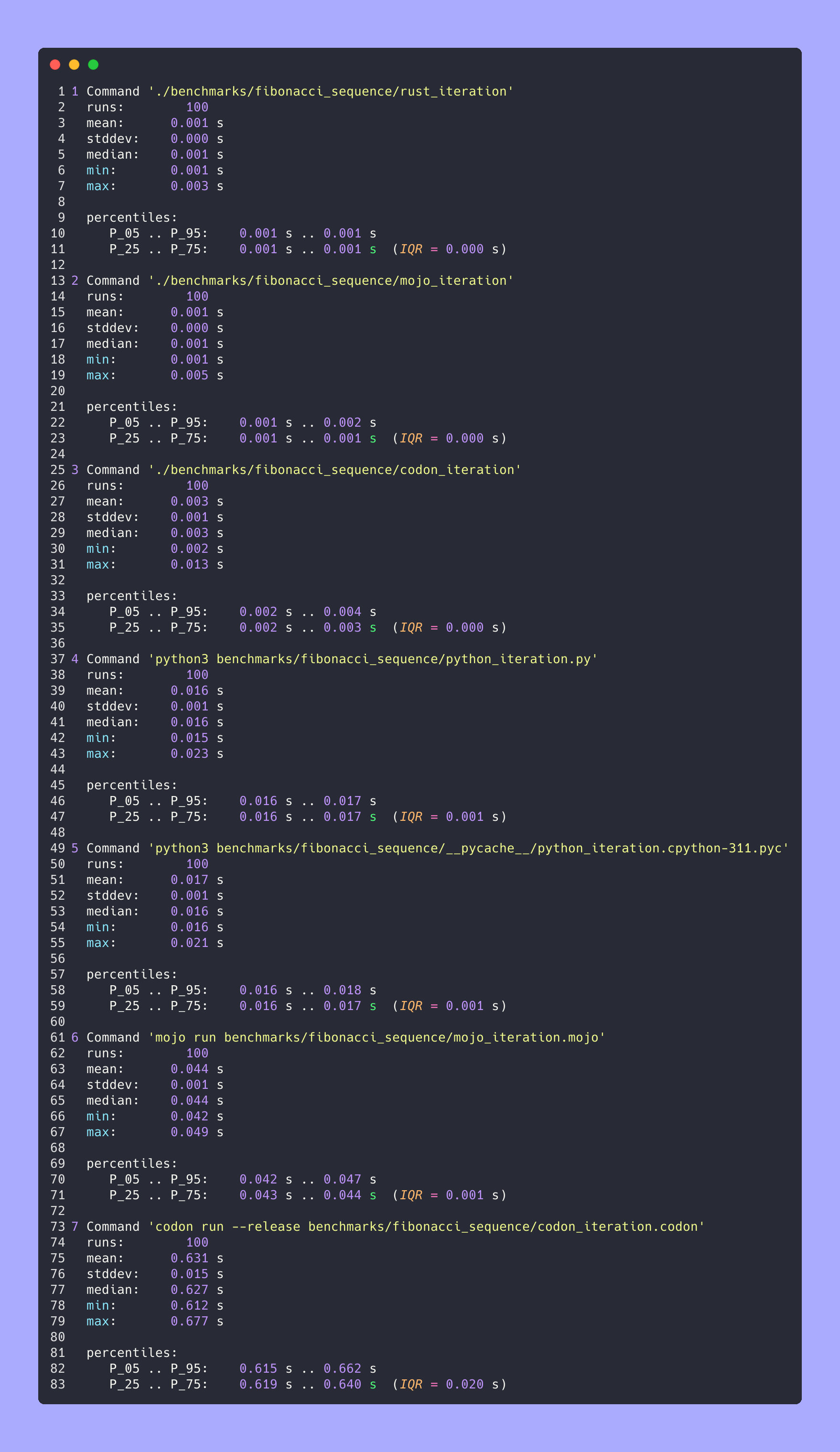
Python-/Mojo-/Codon-/Rust-Versionen
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)Finden wir die Fibonacci-Folge wo
N = 100
def fibonacci_recursion ( n ):
return n if n < 2 else fibonacci_recursion ( n - 1 ) + fibonacci_recursion ( n - 2 )
fibonacci_recursion ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json ' python3 benchmarks/fibonacci_sequence/python_recursion.py 'ERGEBNIS: TIMEOUT, ich habe die Berechnung nach 1 Minute abgebrochen
def fibonacci_iteration ( n ):
a , b = 0 , 1
for _ in range ( n ):
a , b = b , a + b
return a
fibonacci_iteration ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json ' python3 benchmarks/fibonacci_sequence/python_iteration.py ' ERGEBNIS :
Benchmark 1: python3 benchmarks/fibonacci_sequence/python_iteration.py
Zeit (Mittelwert ± σ): 16374,7 µs ± 904,0 µs [Benutzer: 11483,5 µs, System: 3680,0 µs]
Bereich (min … max): 15361,0 µs … 22863,3 µs 100 Läufe
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.pyhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc ' ERGEBNIS :
Benchmark 1: python3 benchmarks/fibonacci_sequence/ pycache /python_iteration.cpython-311.pyc
Zeit (Mittelwert ± σ): 16584,6 µs ± 761,5 µs [Benutzer: 11451,8 µs, System: 3813,3 µs]
Bereich (min … max): 15592,0 µs … 20953,2 µs 100 Durchläufe
fn fibonacci_recursion ( n : Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1 ) + fibonacci_recursion(n - 2 )
fn main ():
_ = fibonacci_recursion( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json ' mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo 'ERGEBNIS: TIMEOUT, ich habe die Berechnung nach 1 Minute abgebrochen
fn fibonacci_iteration ( n : Int) -> Int:
var a : Int = 0
var b : Int = 1
for _ in range (n):
a = b
b = a + b
return a
fn main ():
_ = fibonacci_iteration( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json ' mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo ' ERGEBNIS :
Benchmark 1: mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo
Zeit (Mittelwert ± σ): 43852,7 µs ± 1353,5 µs [Benutzer: 38156,0 µs, System: 10407,3 µs]
Bereich (min … max): 42033,6 µs … 49357,3 µs 100 Läufe
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojohyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json ' ./benchmarks/fibonacci_sequence/mojo_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json ' ./benchmarks/fibonacci_sequence/mojo_iteration ' ERGEBNIS :
Benchmark 1: ./benchmarks/fibonacci_sequence/mojo_iteration
Zeit (Mittelwert ± σ): 934,6 µs ± 468,9 µs [Benutzer: 409,8 µs, System: 247,8 µs]
Bereich (min … max): 552,7 µs … 4522,9 µs 100 Läufe
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json ' codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon 'ERGEBNIS: TIMEOUT, ich habe die Berechnung nach 1 Minute abgebrochen
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json ' codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon ' ERGEBNIS :
Benchmark 1: Codon Run --release benchmarks/fibonacci_sequence/codon_iteration.codon
Zeit (Mittelwert ± σ): 628060,1 µs ± 10430,5 µs [Benutzer: 584524,3 µs, System: 39358,5 µs]
Bereich (min … max): 612742,5 µs … 662716,9 µs 100 Läufe
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codonhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json ' ./benchmarks/fibonacci_sequence/codon_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json ' ./benchmarks/fibonacci_sequence/codon_iteration ' ERGEBNIS :
Benchmark 1: ./benchmarks/fibonacci_sequence/codon_iteration
Zeit (Mittelwert ± σ): 2732,7 µs ± 1145,5 µs [Benutzer: 1466,0 µs, System: 1061,5 µs]
Bereich (min … max): 2036,6 µs … 13236,3 µs 100 Läufe
fn fibonacci_recursive ( n : i64 ) -> i64 {
if n < 2 {
return n ;
}
return fibonacci_recursive ( n - 1 ) + fibonacci_recursive ( n - 2 ) ;
}
fn main ( ) {
let _ = fibonacci_recursive ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json ' ./benchmarks/fibonacci_sequence/rust_recursion 'ERGEBNIS: TIMEOUT, ich habe die Berechnung nach 1 Minute abgebrochen
fn fibonacci_iteration ( n : usize ) -> usize {
let mut a = 1 ;
let mut b = 1 ;
for _ in 1 ..n {
let old = a ;
a = b ;
b += old ;
}
b
}
fn main ( ) {
let _ = fibonacci_iteration ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json ' ./benchmarks/fibonacci_sequence/rust_iteration ' ERGEBNIS :
Benchmark 1: ./benchmarks/fibonacci_sequence/rust_iteration
Zeit (Mittelwert ± σ): 848,9 µs ± 283,2 µs [Benutzer: 371,8 µs, System: 261,4 µs]
Bereich (min … max): 525,9 µs … 2607,3 µs 100 Läufe
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.pngErweiterte Statistiken
Alles zusammen
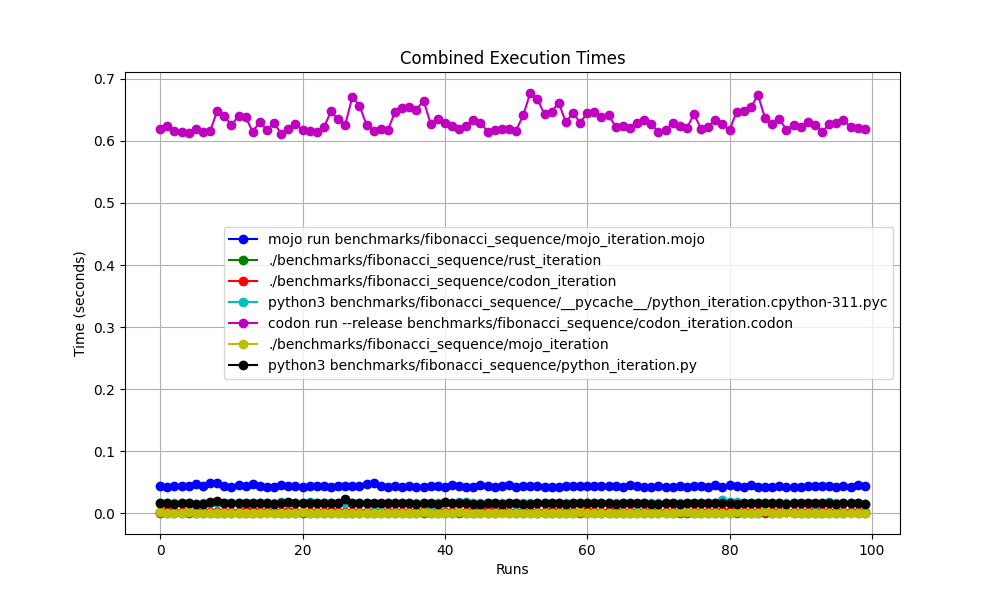
Vergrößert
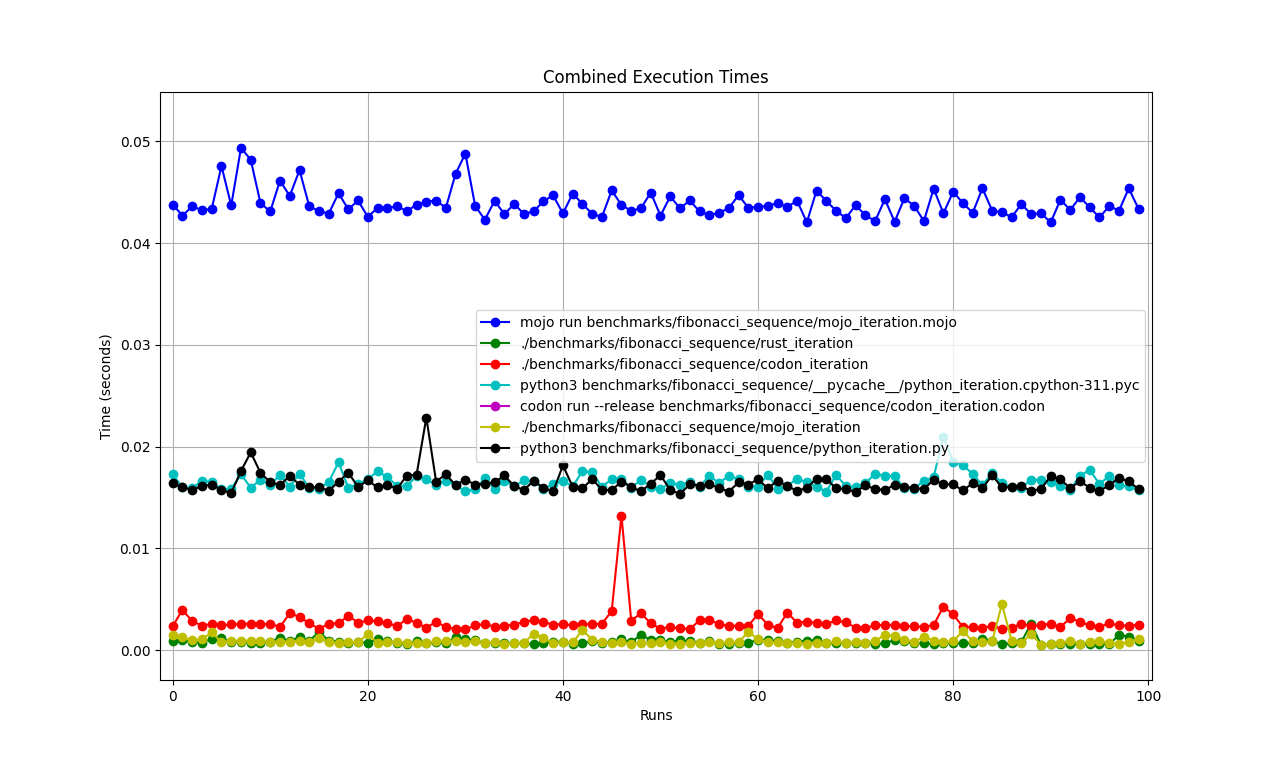
Nach und nach detailliert
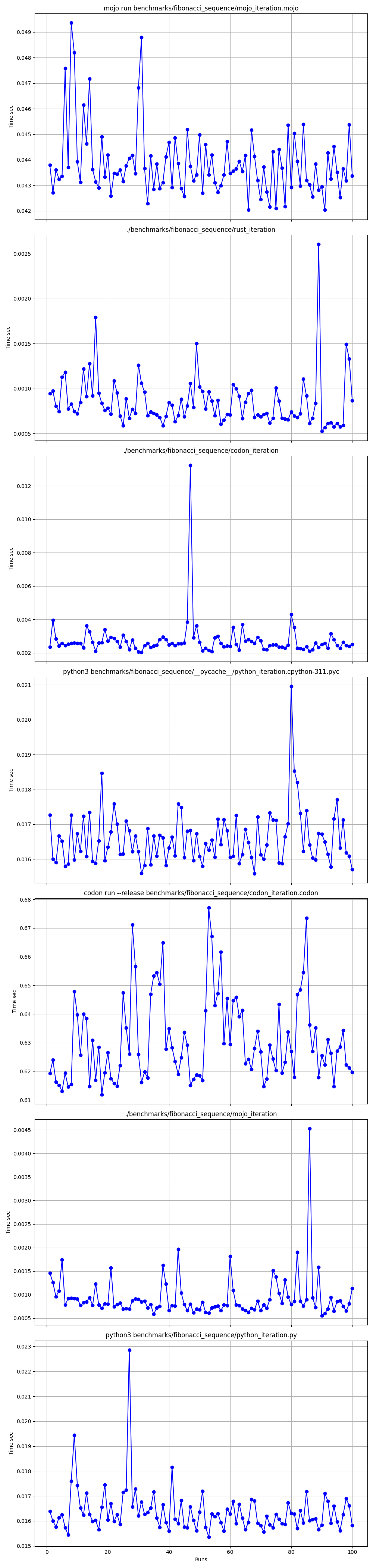
Orte
Aber hier viele Fragen:
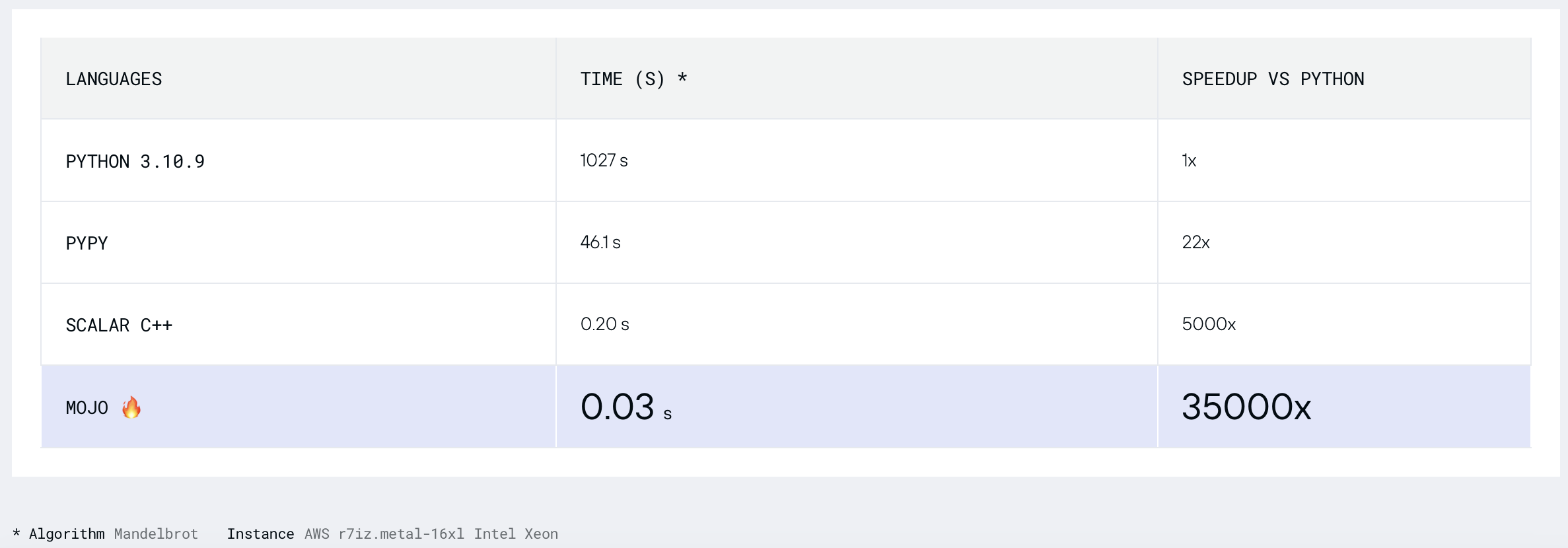
mojo run so langsam?codon run --release so langsam?run der Python-Interpreter schneller als Mojo/Codon?Wir können also sagen, dass Mojo auf dem Mac genauso schnell ist wie Rust!
Finden wir die Mandelbrot-Menge wo
BREITE = 960
HÖHE = 960
MAX_ITERS = 200
MIN_X = -2,0
MAX_X = 0,6
MIN_Y = -1,5
MAX_Y = 1,5
def mandelbrot_kernel ( c ):
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z . real * z . real + z . imag * z . imag > 4 :
return i
return MAX_ITERS
def compute_mandelbrot ():
t = [[ 0 for _ in range ( WIDTH )] for _ in range ( HEIGHT )] # Pixel matrix
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
for row in range ( HEIGHT ):
for col in range ( WIDTH ):
t [ row ][ col ] = mandelbrot_kernel ( complex ( MIN_X + col * dx , MIN_Y + row * dy ))
return t
compute_mandelbrot ()python3 -m compileall benchmarks/multibrot_set/multibrot.py
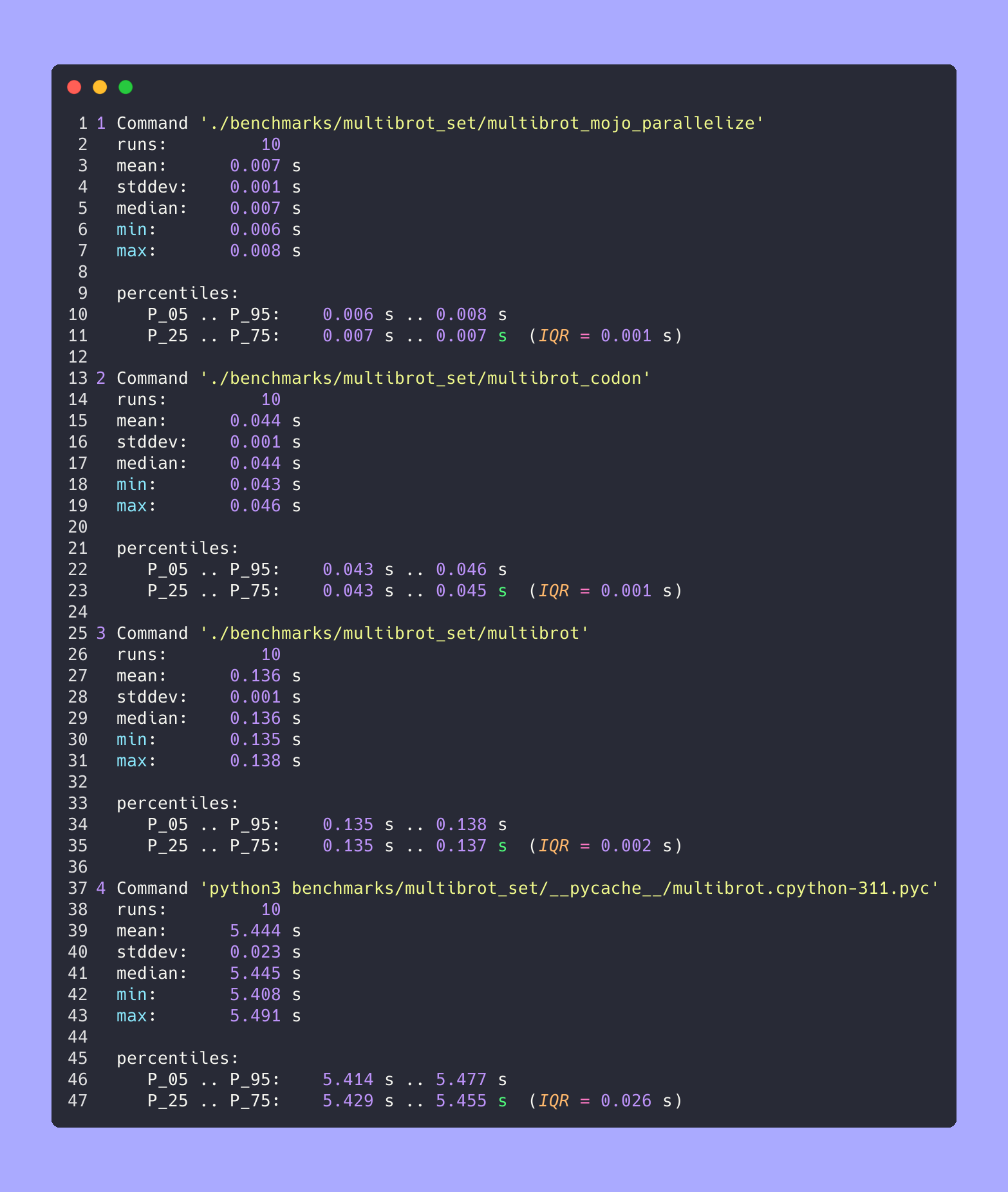
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json ' python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc ' ERGEBNIS :
Benchmark 1: python3 benchmarks/multibrot_set/ pycache /multibrot.cpython-311.pyc
Zeit (Mittelwert ± σ): 5444155,4 µs ± 23059,7 µs [Benutzer: 5419790,1 µs, System: 18131,3 µs]
Bereich (min … max): 5408155,3 µs … 5490548,4 µs 10 Läufe
Mojo-Version ohne Optimierung.
# Compute the number of steps to escape.
def multibrot_kernel ( c : ComplexFloat64) -> Int:
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4 :
return i
return MAX_ITERS
def compute_multibrot () -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType]( HEIGHT , WIDTH )
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
y = MIN_Y
for row in range ( HEIGHT ):
x = MIN_X
for col in range ( WIDTH ):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()mojo build benchmarks/multibrot_set/multibrot.mojo
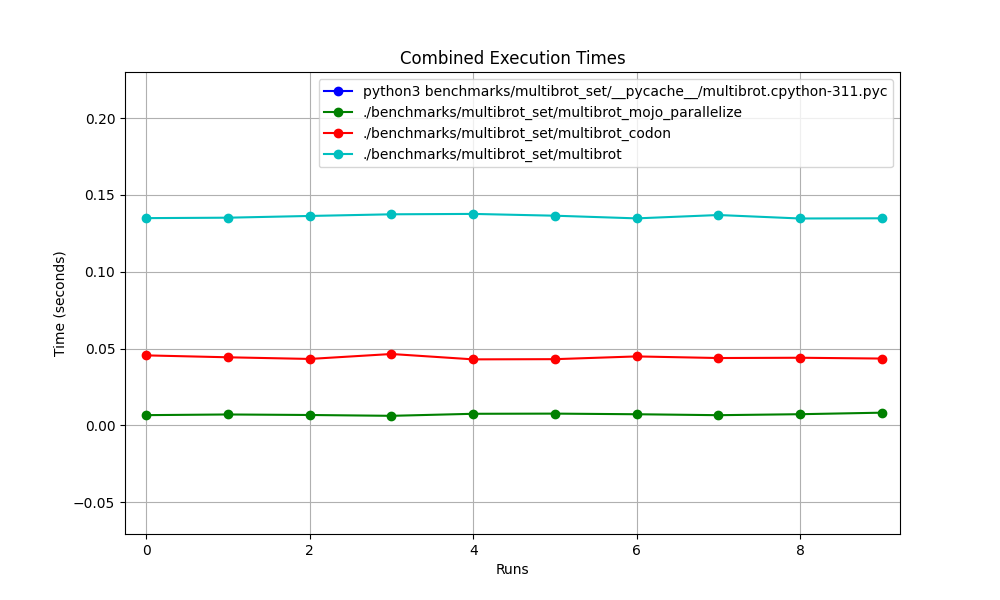
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json ' ./benchmarks/multibrot_set/multibrot ' ERGEBNIS :
Benchmark 1: ./benchmarks/multibrot_set/multibrot
Zeit (Mittelwert ± σ): 135880,5 µs ± 1175,4 µs [Benutzer: 133309,3 µs, System: 1700,1 µs]
Bereich (min … max): 134639,9 µs … 137621,4 µs 10 Durchläufe
fn mandelbrot_kernel_SIMD [
simd_width : Int
]( c : ComplexSIMD[float_type, simd_width]) -> SIMD [float_type, simd_width]:
""" A vectorized implementation of the inner mandelbrot computation. """
let cx = c.re
let cy = c.im
var x = SIMD [float_type, simd_width]( 0 )
var y = SIMD [float_type, simd_width]( 0 )
var y2 = SIMD [float_type, simd_width]( 0 )
var iters = SIMD [float_type, simd_width]( 0 )
var t : SIMD [DType.bool, simd_width] = True
for i in range ( MAX_ITERS ):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1 , iters)
return iters
fn compute_multibrot_parallelized () -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker ( row : Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector [ simd_width : Int]( col : Int):
""" Each time we operate on a `simd_width` vector of pixels. """
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main ():
_ = compute_multibrot_parallelized()mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json ' ./benchmarks/multibrot_set/multibrot_mojo_parallelize ' ERGEBNIS :
Benchmark 1: ./benchmarks/multibrot_set/multibrot_mojo_parallelize
Zeit (Mittelwert ± σ): 7139,4 µs ± 596,4 µs [Benutzer: 36535,2 µs, System: 6670,1 µs]
Bereich (min … max): 6222,6 µs … 8269,7 µs 10 Durchläufe
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
Für Testlauf oder Plot (Code in der Datei auskommentieren)
CODON_PYTHON=/opt/homebrew/opt/[email protected]/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codonErstellen und ausführen
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json ' ./benchmarks/multibrot_set/multibrot_codon ' ERGEBNIS :
Benchmark 1: ./benchmarks/multibrot_set/multibrot_codon
Zeit (Mittelwert ± σ): 44184,7 µs ± 1142,0 µs [Benutzer: 248773,9 µs, System: 72935,3 µs]
Bereich (min … max): 42963,8 µs … 46456,2 µs 10 Durchläufe
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json ' ./benchmarks/multibrot_set/multibrot_codon_par ' # Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.pngErweiterte Statistiken
Alles zusammen
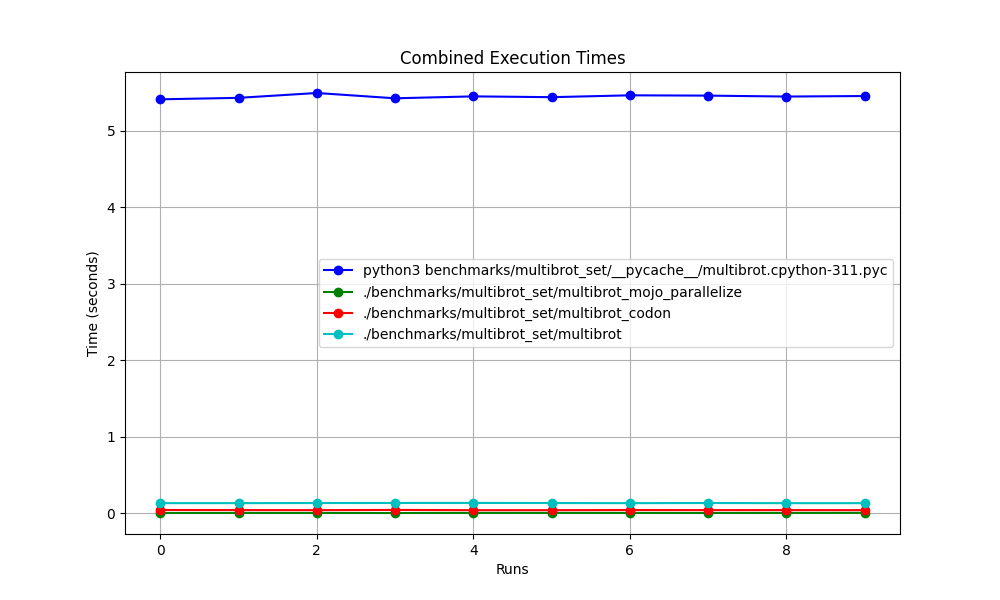
Vergrößert
Nach und nach detailliert
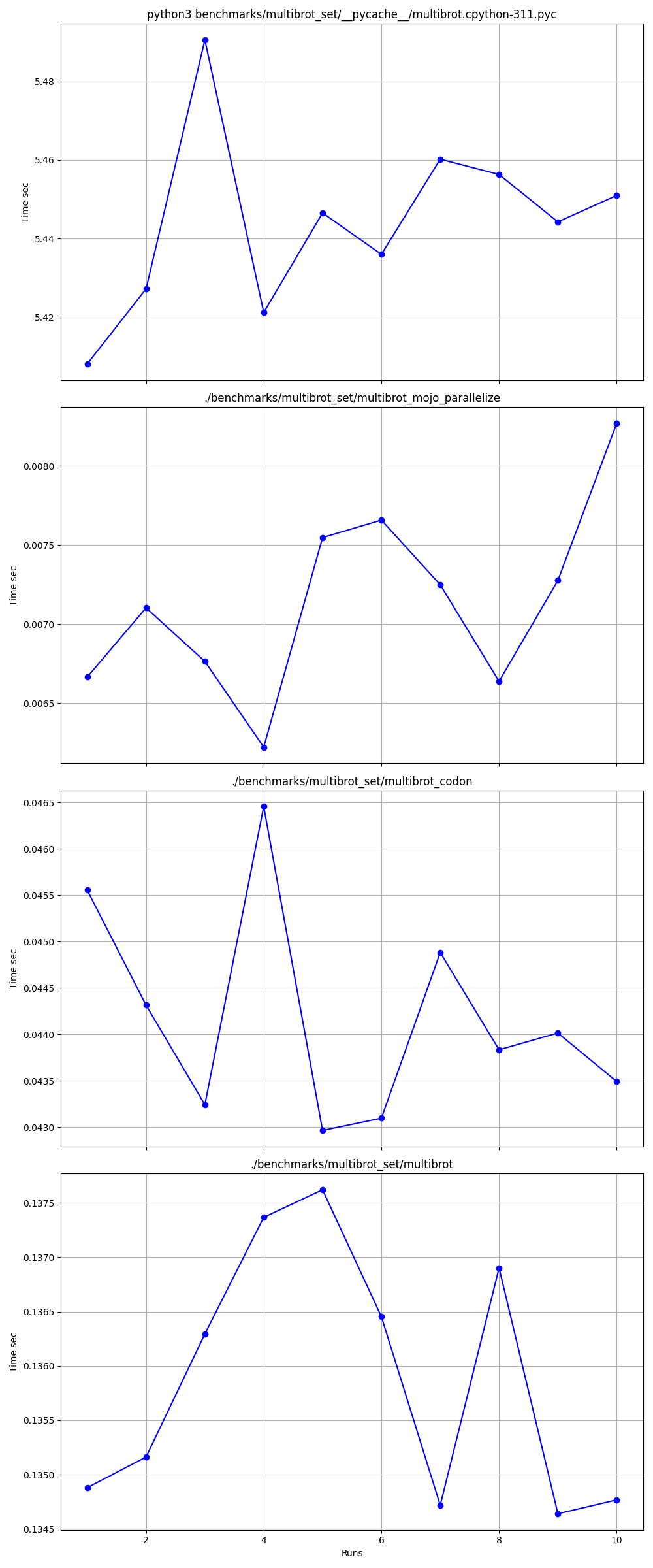
Orte
Links:
Mandelbrot = Multibrot mit power = 2
z = z ** power + c # You can change this for different setKissen eingebaut ImagingEffectMandelbrot
Exaloop-Codon-Version von Mandelbrot
Modulare Mojo-Version von Mandelbrot
Mojo Complex quadrierte_norm
Matplotlib Mandelbrot
In der Informatik ist der binäre Suchalgorithmus, auch bekannt als Halbintervallsuche, logarithmische Suche oder Binär-Chop, ein Suchalgorithmus, der die Position eines Zielwerts innerhalb eines sortierten Arrays findet.
Lassen Sie uns Code mit Python, Mojo, Swift, V, Julia, Nim, Zig erstellen.
Hinweis: Für Python- und Mojo- Versionen belasse ich einige Optimierungen und mache den Code für Messungen und Vergleiche ähnlich.
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple ( i for i in range ( SIZE )) # Make it aka at compile-time.
def python_binary_search ( element : int , array : List [ int ]) -> int :
start = 0
stop = len ( array ) - 1
while start <= stop :
index = ( start + stop ) // 2
pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
def test_python_binary_search ():
_ = python_binary_search ( SIZE - 1 , COLLECTION )
print (
"Average execution time of func in sec" ,
timeit . timeit ( lambda : test_python_binary_search (), number = MAX_ITERS ),
) """Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search ( element : Int , array : DynamicVector [ Int ]) - > Int :
var start = 0
var stop = len ( array ) - 1
while start <= stop :
let index = ( start + stop ) // 2
let pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
@ parameter # statement runs at compile-time.
fn get_collection () - > DynamicVector [ Int ]:
var v = DynamicVector [ Int ]( SIZE )
for i in range ( SIZE ):
v . push_back ( i )
return v
fn test_mojo_binary_search () - > F64 :
fn test_closure ():
_ = mojo_binary_search ( SIZE - 1 , get_collection ())
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ test_closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
test_mojo_binary_search (),
)Es ist die erste binäre Suche, die in der Mojoby-Community (@ego) geschrieben und im Mojo-Chat gepostet wurde.
func binarySearch ( items : [ Int ] , elem : Int ) -> Int {
var low = 0
var high = items . count - 1
var mid = 0
while low <= high {
mid = Int ( ( high + low ) / 2 )
if items [ mid ] < elem {
low = mid + 1
} else if items [ mid ] > elem {
high = mid - 1
} else {
return mid
}
}
return - 1
}
let items = [ 1 , 2 , 3 , 4 , 0 ] . sorted ( )
let res = binarySearch ( items : items , elem : 4 )
print ( res ) function binarysearch (lst :: Vector{T} , val :: T ) where T
low = 1
high = length (lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end proc binarySearch [T](a: openArray [T], key: T): int =
var b = len (a)
while result < b:
var mid = ( result + b) div 2
if a[mid] < key: result = mid + 1
else : b = mid
if result >= len (a) or a[ result ] != key: result = - 1
let res = @ [ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 25 , 27 , 30 ]
echo binarySearch (res, 10 ) const std = @import ( "std" );
fn binarySearch ( comptime T : type , arr : [] const T , target : T ) ? usize {
var lo : usize = 0 ;
var hi : usize = arr . len - 1 ;
while ( lo <= hi ) {
var mid : usize = ( lo + hi ) / 2 ;
if ( arr [ mid ] == target ) {
return mid ;
} else if ( arr [ mid ] < target ) {
lo = mid + 1 ;
} else {
hi = mid - 1 ;
}
}
return null ;
} fn binary_search (a [] int , value int ) int {
mut low := 0
mut high := a.len - 1
for low < = high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return - 1
}
fn main () {
search_list := [ 1 , 2 , 3 , 5 , 6 , 7 , 8 , 9 , 10 ]
println ( binary_search (search_list, 9 ))
} fn breadth_first_search_path (graph map [ string ][] string , vertex string , target string ) [] string {
mut path := [] string {}
mut visited := [] string {init: vertex}
mut queue := [][][] string {}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][ 0 ][ 0 ]
path = queue[idx][ 1 ]
queue. delete (idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path. clone ()
if child ! in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main () {
graph := map {
'A' : [ 'B' , 'C' ]
'B' : [ 'A' , 'D' , 'E' ]
'C' : [ 'A' , 'F' ]
'D' : [ 'B' ]
'E' : [ 'B' , 'F' ]
'F' : [ 'C' , 'E' ]
}
println ( 'Graph: $graph ' )
path := breadth_first_search_path (graph, 'A' , 'F' )
println ( 'The shortest path from node A to node F is: $path ' )
assert path == [ 'A' , 'C' , 'F' ]
} import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz (): # Make it aka at compile-time.
res = []
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
s = "FizzBuzz"
elif n % 3 == 0 :
s = "Fizz"
elif n % 5 == 0 :
s = "Buzz"
else :
s = str ( n )
res . append ( s )
return res
DATA = _fizz_buzz ()
def fizz_buzz ():
print ( " n " . join ( DATA ))
print (
"Average execution time of Python func in sec" ,
timeit . timeit ( lambda : fizz_buzz (), number = MAX_ITERS ),
)
# Average execution time of Python func in sec 0.005334990004485007 ( import '[java.io OutputStream])
( require '[clojure.java.io :as io])
( def devnull ( io/writer ( OutputStream/nullOutputStream )))
( defmacro timeit [n expr]
`(with-out-str ( time
( dotimes [_# ~( Math/pow 1 n)]
( binding [*out* devnull]
~expr)))))
( defmacro macro-fizz-buzz [n]
`( fn []
( print
~( apply str
( for [i ( range 1 ( inc n))]
( cond
( zero? ( mod i 15 )) " FizzBuzz n "
( zero? ( mod i 5 )) " Buzz n "
( zero? ( mod i 3 )) " Fizz n "
:else ( str i " n " )))))))
( print ( timeit 100 ( macro-fizz-buzz 100 )))
; ; "Elapsed time: 0.175486 msecs"
; ; Average execution time of Clojure func in sec 0.000175486 seconds from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@ parameter # statement runs at compile-time.
fn _fizz_buzz () - > String :
var res : String = ""
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
res += "FizzBuzz"
elif n % 3 == 0 :
res += "Fizz"
elif n % 5 == 0 :
res += "Buzz"
else :
res += String ( n )
res += " n "
return res
fn fizz_buzz ():
print ( _fizz_buzz ())
fn run_benchmark () - > F64 :
fn _closure ():
_ = fizz_buzz ()
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
run_benchmark (),
)
# Average execution time of func in sec 0.000104 Es ist der erste Fizz-Buzz, der jemals von der Community (@Ego) in Mojo geschrieben wurde.
Wir werden Algorithmen aus dem bekannten Referenzbuch „Einführung in Algorithmen A3“ verwenden
Sein Ruhm hat zur allgemeinen Verwendung der Abkürzung „ CLRS “ (Cormen, Leiserson, Rivest, Stein) oder, in der ersten Ausgabe, „ CLR “ (Cormen, Leiserson, Rivest) geführt.
Kapitel 2 „2.3.1 Der Divide-and-Conquer-Ansatz“.
% % python
import timeit
MAX_ITERS = 100
def merge ( A , p , q , r ):
n1 = q - p + 1
n2 = r - q
L = [ None ] * n1
R = [ None ] * n2
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
i = 0
j = 0
k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
def merge_sort ( A , p , r ):
if p < r :
q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
def run_benchmark_merge_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
merge_sort ( A , 0 , len ( A ) - 1 )
print (
"Average execution time of Python `merge_sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_merge_sort (), number = MAX_ITERS ),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
A . sort ()
print (
"Average execution time of Python builtin `sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_sort (), number = MAX_ITERS ),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494 from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge ( inout A : DynamicVector [ Int ], p : Int , q : Int , r : Int ):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector [ Int ]( n1 )
var R = DynamicVector [ Int ]( n2 )
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
fn merge_sort ( inout A : DynamicVector [ Int ], p : Int , r : Int ):
if p < r :
let q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
@ parameter
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ MAX_ITERS , Int ]( 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
fn run_benchmark_merge_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo `merge_sort` in sec " ,
run_benchmark_merge_sort (),
)
# Average execution time of Mojo `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
sort ( A )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo builtin `sort` in sec " ,
run_benchmark_sort (),
)
# Average execution time of Mojo builtin `sort` in sec 2.988e-06Sie können es wie folgt verwenden:
# Usage: merge_sort
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
print ( len ( A ))
print ( A [ 0 ], A [ 99 ]) Die from Sort import sort Quicksort integrierte Implementierung ist etwas schneller als unsere Implementierung, aber wir können sie tief in der Sprache und wie üblich mit Algorithmen =) und Programmierparadigmen optimieren.
| Lang | Sek |
|---|---|
| Python merge_sort | 0,019136679 |
| In Python integrierte Sortierung | 0,000199228 |
| Mojo merge_sort | 0,000011346 |
| Mojo eingebaute Sortierung | 0,000002988 |
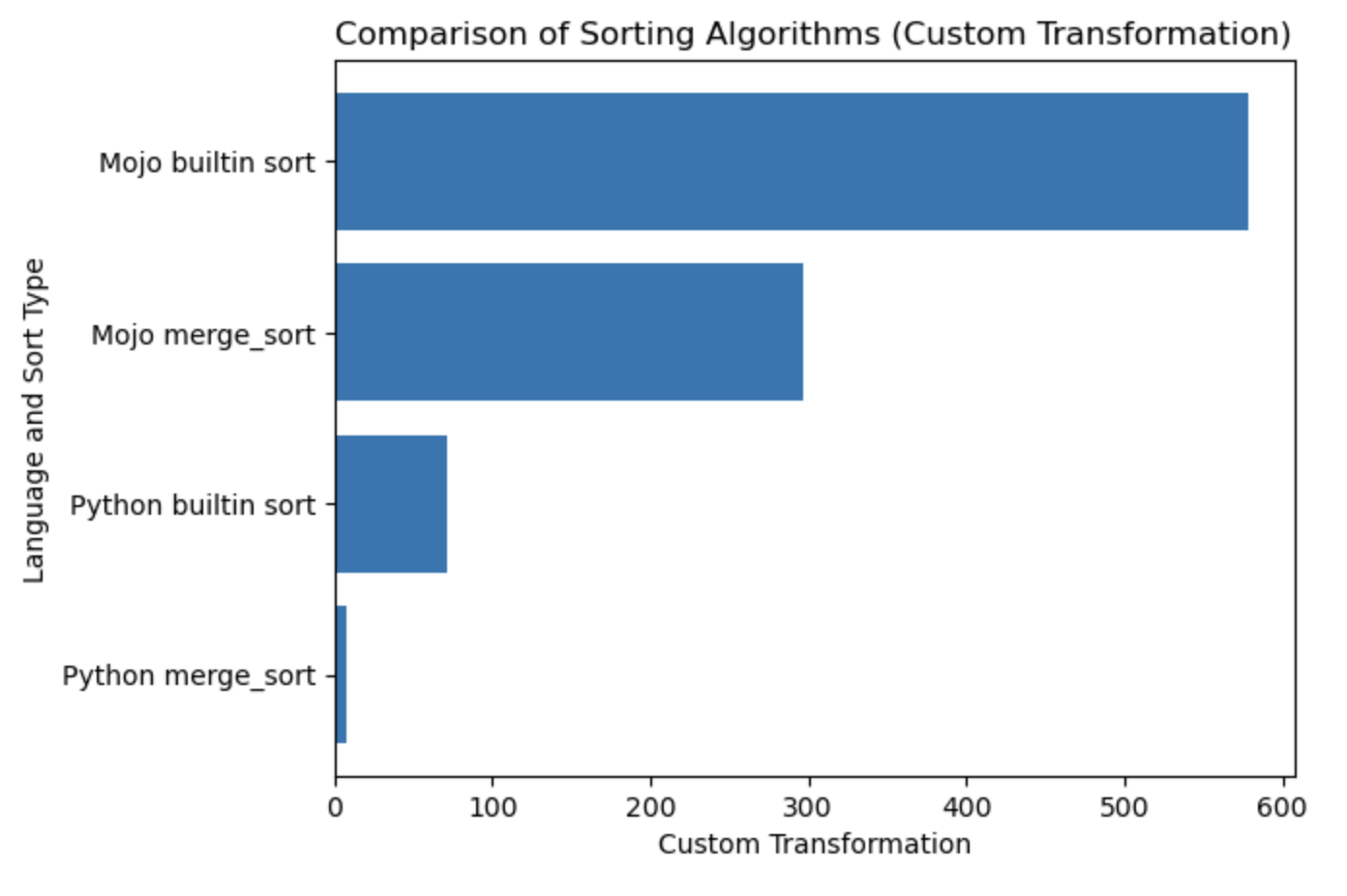
Lassen Sie uns ein Diagramm für diese Tabelle erstellen.
#%%python
import matplotlib . pyplot as plt
import numpy as np
languages = [ 'Python merge_sort' , 'Python builtin sort' , 'Mojo merge_sort' , 'Mojo builtin sort' ]
seconds = [ 0.019136679 , 0.000199228 , 0.000011346 , 0.000002988 ]
# Apply a custom transformation to the values
transformed_seconds = [ np . sqrt ( 1 / x ) for x in seconds ]
plt . barh ( languages , transformed_seconds )
plt . xlabel ( 'Custom Transformation' )
plt . ylabel ( 'Language and Sort Type' )
plt . title ( 'Comparison of Sorting Algorithms (Custom Transformation)' )
plt . show ()Handlungshinweise: Mehr ist besser und schneller.
Ich empfehle dringend, hier mit HelloMojo zu beginnen und die Parametrisierung von [Parametern] und [Parameterausdrücken] hier zu verstehen. Wie in diesem Beispiel:
fn concat [ len1 : Int , len2 : Int ]( lhs : MySIMD [ len1 ], rhs : MySIMD [ len2 ]) - > MySIMD [ len1 + len2 ]:
let result = MySIMD [ len1 + len2 ]()
for i in range ( len1 ):
result [ i ] = lhs [ i ]
for j in range ( len2 ):
result [ len1 + j ] = rhs [ j ]
return result
let a = MySIMD [ 2 ]( 1 , 2 )
let x = concat [ 2 , 2 ]( a , a )
x . dump () Kompilierungszeit [Parameter]: fn concat[len1: Int, len2: Int] .
Laufzeit (Args) : fn concat(lhs: MySIMD, rhs: MySIMD) .
Parameter PEP695-Syntax in eckigen [] Klammern.
Jetzt in Python:
def func ( a : _T , b : _T ) -> _T :
...Jetzt in Mojo:
def func [ T ]( a : T , b : T ) -> T :
... [Parameter] sind benannt und haben Typen wie normale Werte in einem Mojo-Programm, aber parameters[] werden zur Kompilierungszeit ausgewertet.
Das Laufzeitprogramm kann den Wert von [Parametern] verwenden, da die Parameter zur Kompilierungszeit aufgelöst werden, bevor sie vom Laufzeitprogramm benötigt werden. Die Parameterausdrücke zur Kompilierungszeit verwenden jedoch möglicherweise keine Laufzeitwerte.
Self von PEP673
fn __sub__ ( self , rhs : Self ) - > Self :
let result = MySIMD [ size ]()
for i in range ( size ):
result [ i ] = self [ i ] - rhs [ i ]
return resultIn den Dokumenten finden Sie Wortfelder, auch bekannt als Klassenattribute in Python.
Sie nennen sie also mit dot .
from DType import DType
let bool_type = DType . bool from DType import DType
DType . si8 from DType import DType
from SIMD import SIMD , SI8
alias MY_SIMD_DType_si8 = SIMD [ DType . si8 , 1 ]
alias MY_SI8 = SI8
print ( MY_SIMD_DType_si8 == MY_SI8 )
# true from DType import DType
from SIMD import SIMD , SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias b = DynamicVector [ SI8 ]
print ( a == b )
print ( a == String )
print ( b == String )
# all true Der String ist also nur ein Alias für etwas wie DynamicVector[SIMD[DType.si8, 1]] .
VariadicList zum Destrukturieren/Entpacken/Zugreifen auf Argumente from List import VariadicList
fn destructuring_arguments ( * args : Int ):
let my_var_list = VariadicList ( args )
for i in range ( len ( my_var_list )):
print ( "argument" , i , ":" , my_var_list [ i ])
destructuring_arguments ( 1 , 2 , 3 , 4 )Es ist sehr nützlich für die Erstellung erster Sammlungen. Wir können so schreiben:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ 4 , Int ]( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])
# or
from List import VariadicList
fn create_vertor () - > DynamicVector [ Int ]:
let var_list = VariadicList ( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( len ( var_list ))
for i in range ( len ( var_list )):
v . push_back ( var_list [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])Lesen Sie mehr über die Funktionen def und fn
from String import String
# String concatenation
print ( String ( "'" ) + String ( 1 ) + "' n " )
# Python's join
print ( String ( "|" ). join ( "a" , "b" , "c" ))
# String format
from IO import _printf as print
let x : Int = 1
print ( "'%i' n " , x . value )Für eine Zeichenfolge können Sie „Builtin Slice“ mit der Formatzeichenfolge „slice[start:end:step]“ verwenden.
from String import String
let hello_mojo = String ( "Hello Mojo!" )
print ( "Till the end:" , hello_mojo [ 0 ::])
print ( "Before last 2 chars:" , hello_mojo [ 0 : - 2 ])
print ( "From start to the end with step 2:" , hello_mojo [ 0 :: 2 ])
print ( "From start to the before last with step 3:" , hello_mojo [ 0 : - 1 : 3 ])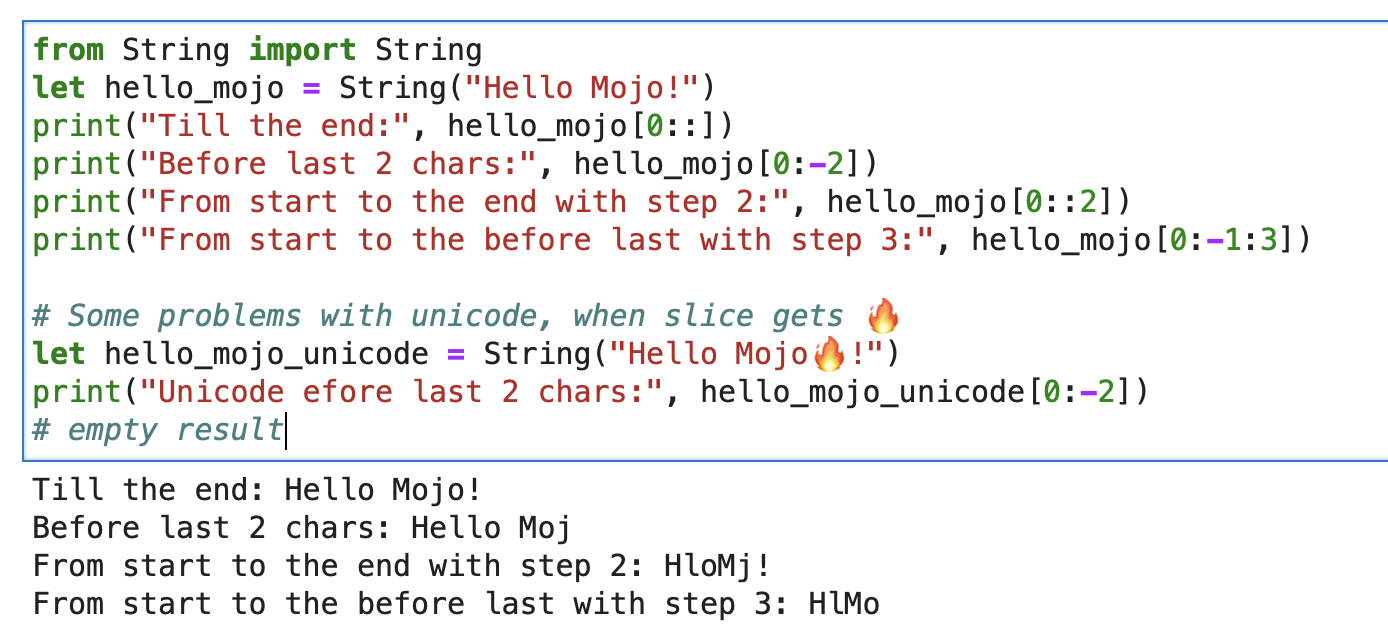
Beim Slicing gibt es ein Problem mit Unicode:
let hello_mojo_unicode = String ( "Hello Mojo!" )
print ( "Unicode efore last 2 chars:" , hello_mojo_unicode [ 0 : - 2 ])
# no result, silentsHier ist eine Erklärung und eine Diskussion.
mbstowcs – Konvertieren einer Multibyte-Zeichenfolge in eine Breitzeichenzeichenfolge
struct , auch bekannt als Python @dataclass . Es generiert automatisch die Methoden __init__ , __copyinit__ , __moveinit__ für Sie.
@ value
struct dataclass :
var name : String
var age : Int Beachten Sie, dass der @value -Dekorator nur für Typen funktioniert, deren Mitglieder copyable und/oder movable sind.
Triviale Typen. Dieser Dekorateur teilt Mojo mit, dass der Typ kopierbar __copyinit__ und verschiebbar __moveinit__ sein soll. Außerdem weist es Mojo an, den Wert lieber in CPU-Registern zu übergeben. Ermöglicht structs , sich dafür zu entscheiden, in einem register übergeben zu werden, anstatt memory zu durchlaufen.
@ register_passable ( "trivial" )
struct Int :
var value : __mlir_type . `!pop.scalar<index>`Dekoratoren, die vollständige Kontrolle über Compiler-Optimierungen bieten. Weist den Compiler an, diese Funktion beim Aufruf immer einzubinden .
@ always_inline
fn foo ( x : Int , y : Int ) - > Int :
return x + y
fn bar ( z : Int ):
let r = foo ( z , z ) # This call will be inlinedEs kann auf verschachtelten Funktionen platziert werden, die Laufzeitwerte erfassen, um „parametrische“ Erfassungsabschlüsse zu erstellen. Es ermöglicht die Übergabe von Abschlüssen, die Laufzeitwerte erfassen, als Parameterwerte.
@ always_inline
@ parameter
fn test (): return Einige Casting-Beispiele
s : StringLiteral
let p = DTypePointer [ DType . si8 ]( s . data ()). bitcast [ DType . ui8 ]()
var result = 0
result += (( p . simd_load [ 64 ]( offset ) >> 6 ) != 0b10 ). cast [ DType . ui8 ](). reduce_add (). to_int ()
let rest_p : DTypePointer [ DType . ui8 ] = stack_allocation [ simd_width , UI8 , 1 ]()
from Bit import ctlz
s : String
i : Int
let code = s . buffer . data . load ( i )
let byte_length_code = ctlz ( ~ code ). to_int ()DTypePointer – Speichern Sie eine Adresse mit einem bestimmten DType, sodass Sie Daten zuweisen, laden und ändern können und bequem auf SIMD-Vorgänge zugreifen können.
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer [ DType . ui8 ]. alloc ( 8 )
memset_zero ( my_pointer_on_heap , 8 )
# `stack or register`
var data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
rand ( my_pointer_on_heap , 4 )
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
# simd_load and simd_store
var half = my_pointer_on_heap . simd_load [ 4 ]( 0 )
half = half + 1
my_pointer_on_heap . simd_store [ 4 ]( 4 , half )
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Pointer move back
my_pointer_on_heap -= 1
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Mast free memory
my_pointer_on_heap . free ()Struct kann potenziell gefährliche Zeiger minimieren, indem es den Scoup begrenzt.
Ausgezeichneter Artikel im Mojo Dojo-Blog über DTypePointer hier
Plus sein Beispiel Matrix Struct und DTypePointer
Zeiger speichern eine Adresse für jeden register_passable type und weisen n davon dem heap zu.
from Pointer import Pointer
from Memory import memset_zero
from String import String
@ register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord : # memory-only type
var x : UI8
var y : UI8
var p1 = Pointer [ Coord ]. alloc ( 2 )
memset_zero ( p1 , 2 )
var coord = p1 [ 0 ] # is an identifier to memory on the stack or in a register
print ( coord . x )
# Store the value
coord . x = 5
coord . y = 5
print ( coord . x )
# We need to store the data.
p1 . store ( 0 , coord )
print ( p1 [ 0 ]. x )
# Mast free memory
p1 . free ()Vollständiger Artikel über Pointer
Plus Beispielzeiger und Struktur
Bei Modular Intrinsics handelt es sich um eine Art Ausführungs-Backend :
Mojo -> MLIR-Dialekte -> Ausführungs-Backends mit Optimierungscode und Architekturen.
MLIR ist eine Compiler-Infrastruktur, die verschiedene Transformations- und Optimierungsdurchgänge für verschiedene Programmiersprachen und Architekturen implementiert.
MLIR selbst bietet keine direkte Funktionalität für die Interaktion mit Systemaufrufen des Betriebssystems.
Dabei handelt es sich um Low-Level-Schnittstellen zu Betriebssystemdiensten, die typischerweise auf der Ebene der Zielprogrammiersprache oder des Betriebssystems selbst gehandhabt werden. MLIR ist sprach- und zielunabhängig und sein Hauptaugenmerk liegt auf der Bereitstellung einer Zwischendarstellung für die Durchführung von Optimierungen. Um Betriebssystem-Systemaufrufe in MLIR durchzuführen, müssen wir ein zielspezifisches Backend verwenden.
Aber mit diesen execution backends haben wir im Grunde Zugriff auf Betriebssystem-Systemaufrufe. Und wir haben die ganze Welt der C/LLVM/Python-Sachen unter der Haube.
Werfen wir einen kurzen Blick darauf in der Praxis:
from OS import getenv
print ( getenv ( "PATH" ))
print ( getenv ( StringRef ( "PATH" )))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call [ "getenv" , StringRef ]( StringRef ( "PATH" ))
print ( path1 . data )
var path2 = external_call [ "getenv" , StringRef ]( "PATH" )
print ( path2 . data )
let abs_10 = external_call [ "abs" , SI8 , Int ]( - 10 )
print ( abs_10 ) In diesem einfachen Beispiel haben wir external_call verwendet, um eine Betriebssystemumgebungsvariable mit einem Umwandlungstyp zwischen Mojo- und libc-Funktionen abzurufen. Ziemlich cool, ja!
Ich habe viele Ideen zu diesem Thema und freue mich darauf, diese bald umsetzen zu können. Handeln kann zu erstaunlichen Ergebnissen führen =)
Machen wir etwas Interessantes: Rufen Sie libc function gethostname auf.
Die Funktion hat diese Schnittstelle int gethostname (char *name, size_t size) .
Dazu können wir die Hilfsfunktion external_call aus dem Intrinsics -Modul verwenden oder ein eigenes MLIR schreiben.
Los geht's mit dem Code:
from Intrinsics import external_call
from SIMD import SIMD , SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer , Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer [ DType . si8 ]( cArrayOfStrings ( capacity ). data )
var c_int_result = external_call [ "gethostname" , Int , DTypePointer [ DType . si8 ], Int ]( c_pointer_to_array_of_strings , capacity )
let mojo_string_result = String ( c_pointer_to_array_of_strings . address )
print ( "C function gethostname result code:" , c_int_result )
print ( "C function gethostname result value:" , star_hostname ( mojo_string_result ))
@ always_inline
fn star_hostname ( hostname : String ) - > String :
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname [ 0 : - 1 : 2 ]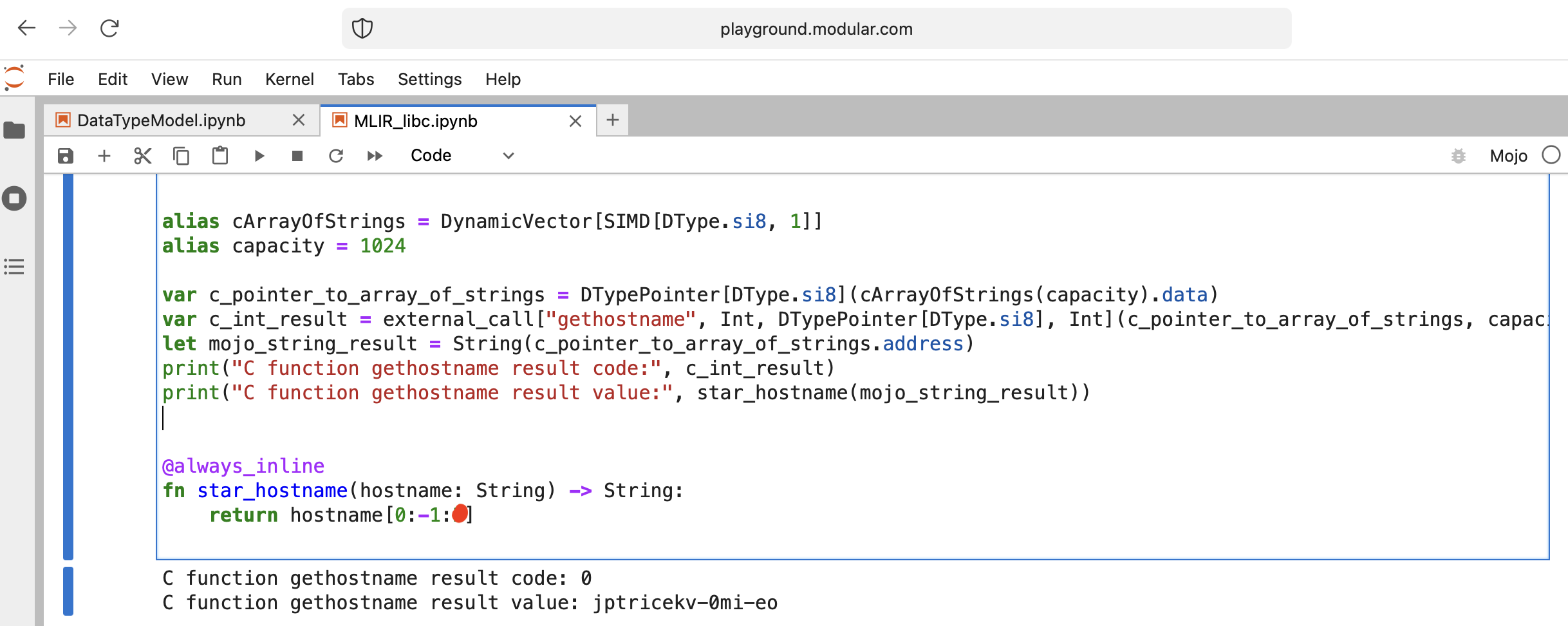
Lassen Sie uns mit Mojo einige Dinge für ein WEB tun. Wir haben unter Playground.modular.com keinen Internetzugang, aber wir können einige interessante Dinge wie TCP auf einer Maschine erledigen.
Schreiben wir den ersten TCP-Client-Server-Code in Mojo mit PythonInterface
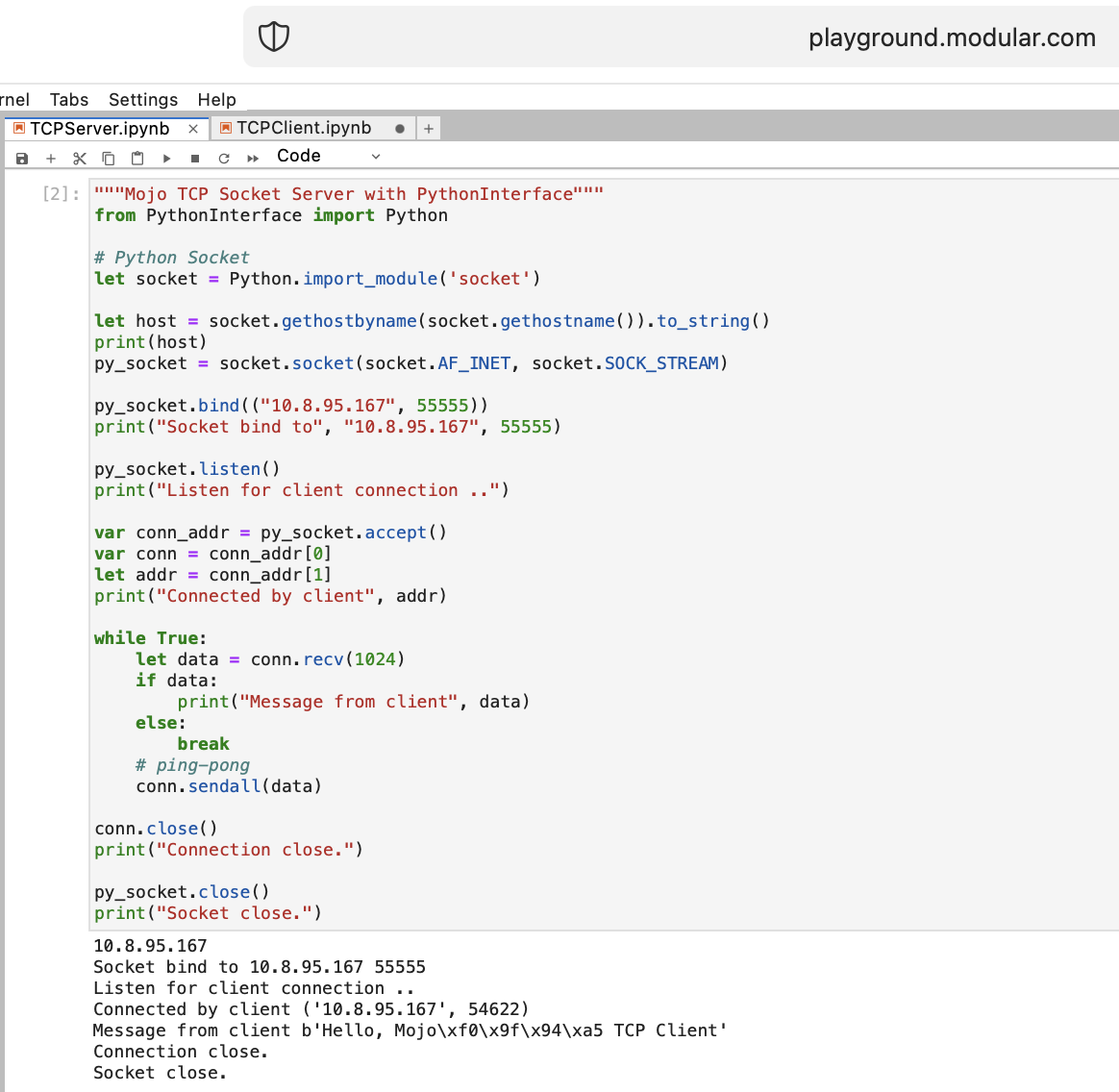
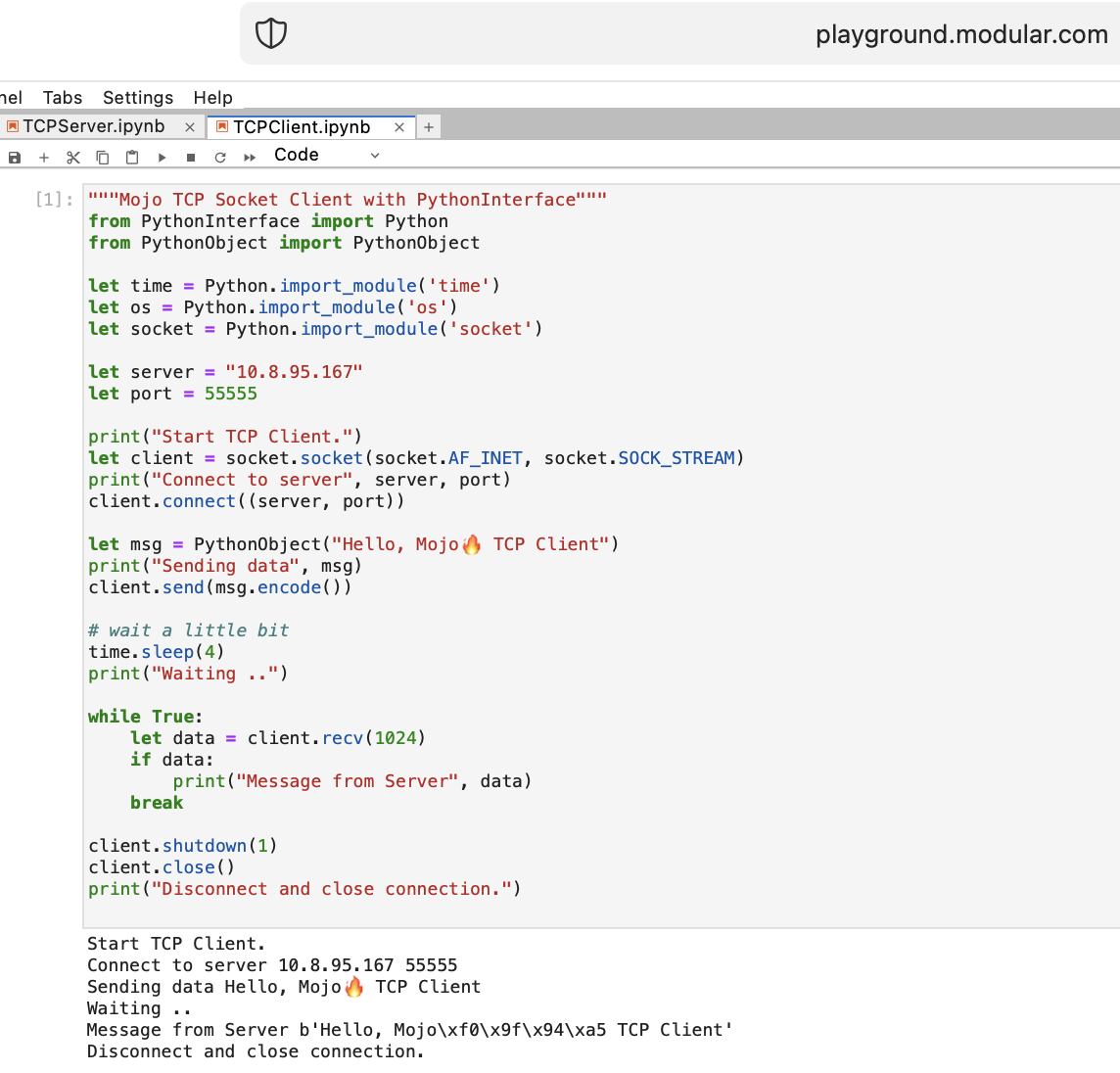
Sie sollten zwei separate Notebooks erstellen und zuerst TCPSocketServer und dann TCPSocketClient ausführen.
Die Python-Version dieses Codes ist fast identisch, außer:
with Syntaxleta, b = (1, 2)Nach dem TCP-Server in Mojo geht es weiter =)
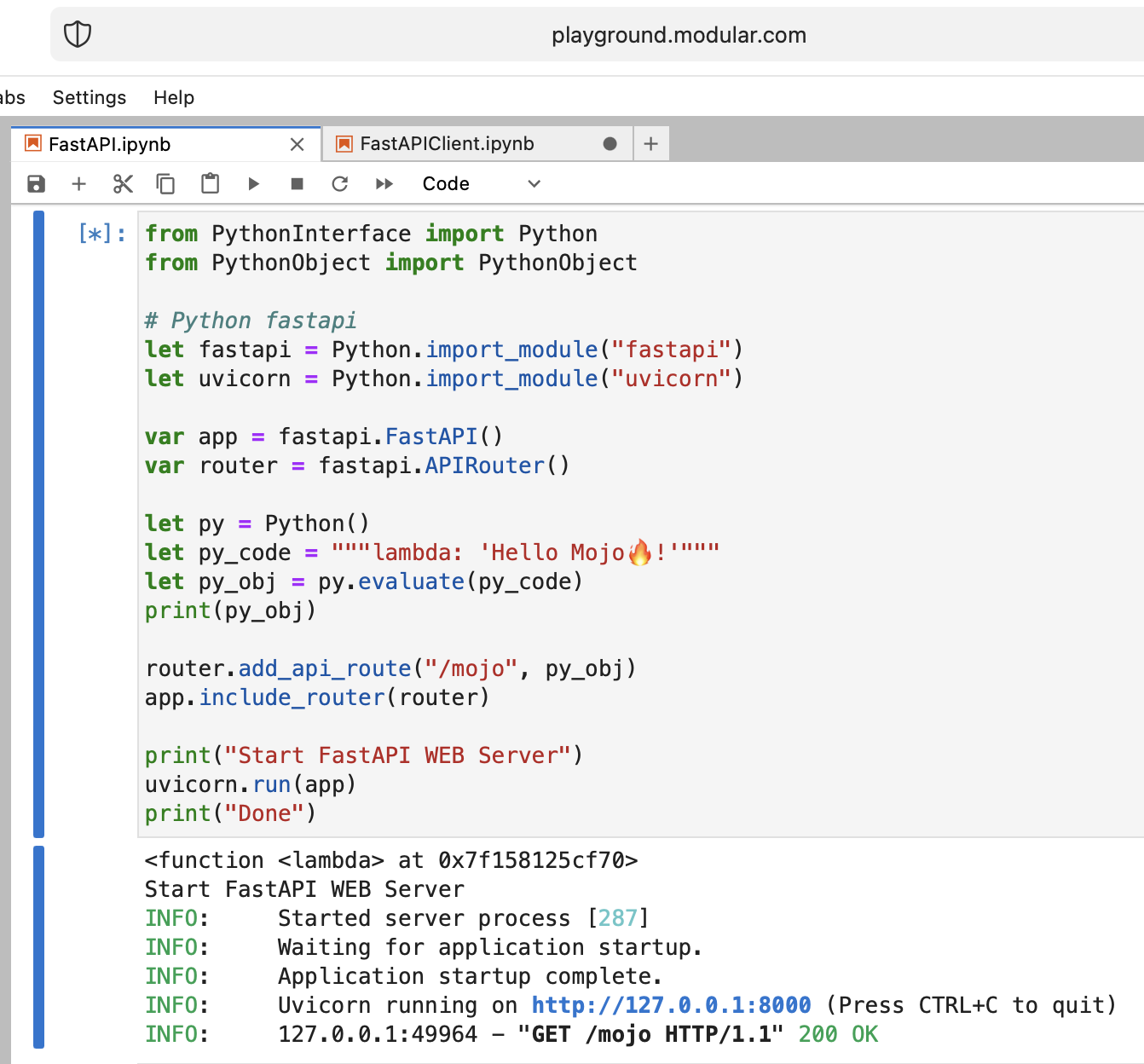
Es ist verrückt, aber versuchen wir, den modernen Python-Webserver FastAPI mit Mojo auszuführen!
Wir müssen den FastAPI-Code auf den Spielplatz hochladen. Also, auf Ihrem lokalen Rechner
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz web und laden Sie web.tar.gz über die Webschnittstelle auf den Spielplatz hoch.
Dann müssen wir es install , einfach in den richtigen Ordner legen:
% % python
import os
import site
site_packages_path = site . getsitepackages ()[ 0 ]
# install fastapi
os . system ( f"tar xzf web.tar.gz -C { site_packages_path } " )
os . system ( f"cp -r { site_packages_path } /web/* { site_packages_path } /" )
os . system ( f"ls { site_packages_path } | grep fastapi" )
# clean packages
os . system ( f"rm -rf { site_packages_path } /web" )
os . system ( f"rm web.tar.gz" ) from PythonInterface import Python
# Python fastapi
let fastapi = Python . import_module ( "fastapi" )
let uvicorn = Python . import_module ( "uvicorn" )
var app = fastapi . FastAPI ()
var router = fastapi . APIRouter ()
# tricky part
let py = Python ()
let py_code = """lambda: 'Hello Mojo!'"""
let py_obj = py . evaluate ( py_code )
print ( py_obj )
router . add_api_route ( "/mojo" , py_obj )
app . include_router ( router )
print ( "Start FastAPI WEB Server" )
uvicorn . run ( app )
print ( "Done" ) from PythonInterface import Python
let http_client = Python . import_module ( "http.client" )
let conn = http_client . HTTPConnection ( "localhost" , 8000 )
conn . request ( "GET" , "/mojo" )
let response = conn . getresponse ()
print ( response . status , response . reason , response . read ())Wie üblich sollten Sie zwei separate Notebooks erstellen und zuerst FastAPI und dann FastAPIClient ausführen.
Es gibt viele offene Fragen, aber grundsätzlich erreichen wir das Ziel.
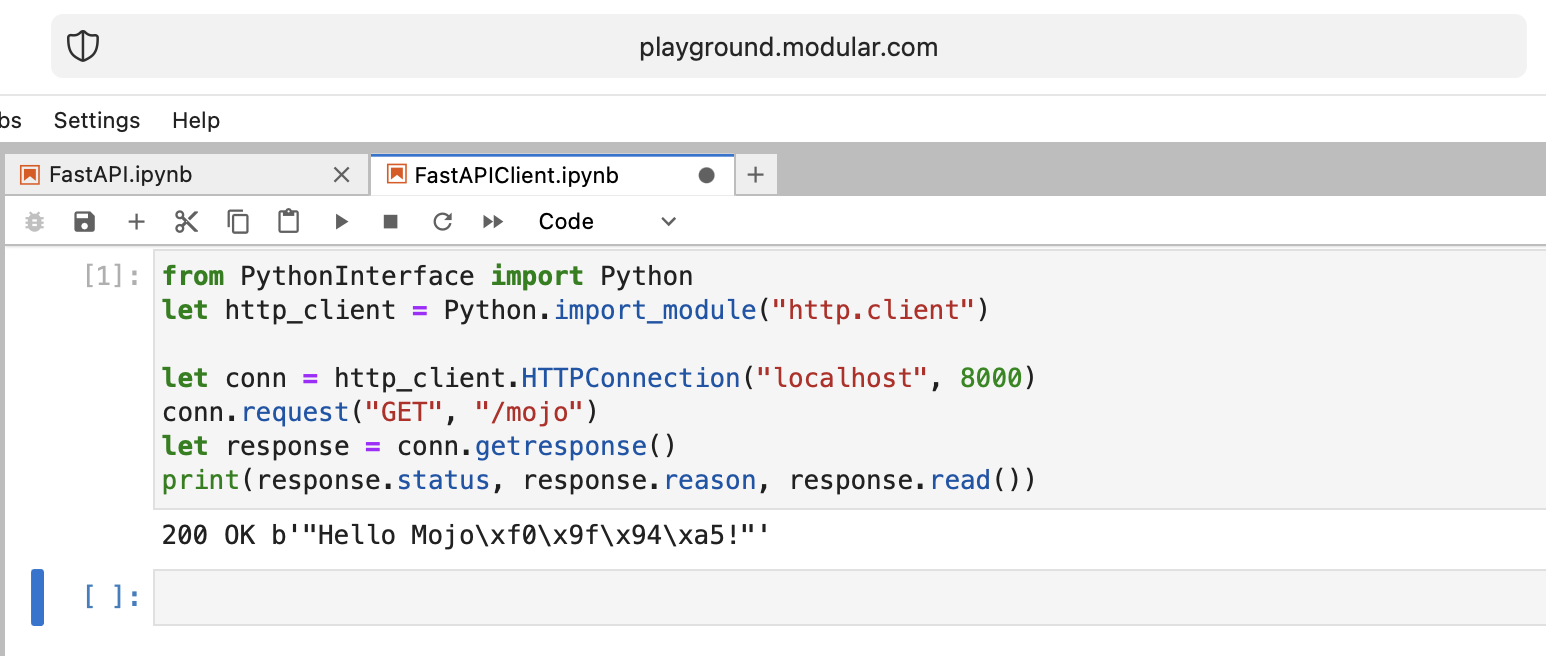
Mojo, gut gemacht!
Einige offene Fragen:
from PythonInterface import Python
let pyfn = Python . evaluate ( "lambda x, y: x+y" )
let functools = Python . import_module ( "functools" )
print ( functools . reduce ( pyfn , [ 1 , 2 , 3 , 4 ]))
# How to, without Mojo pyfn.so?
def pyfn ( x , y ):
retyrn x + yDie Zukunft sieht sehr optimistisch aus!
Links:
Benchmark Mojo vs Numba von Nick Wogan
Zeitliche Hilfsmittel von Samay Kapadia @Zalando
Herstellen einer Verbindung zu Ihrem Mojo-Spielplatz über VSCode oder DataSpell
von Maxim Zaks
from String import String
from PythonInterface import Python
let pathlib = Python . import_module ( 'pathlib' )
let txt = pathlib . Path ( 'nfl.csv' ). read_text ()
let s : String = txt . to_string ()libc-Implementierung
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String , chr
let hello = "hello"
let pointer = Pointer ( hello . data ())
print ( "variant 1" )
var result = String ()
for i in range ( len ( hello )):
result += chr ( pointer . bitcast [ Int8 ](). offset ( i ). load (). to_int ())
print ( result )
print ( "variant 2" )
print ( StringRef ( hello . data ()))
print ( "variant 3" )
print ( StringRef ( pointer . address ))
print ( "variant 4" )
let pm : Pointer [ __mlir_type . `!pop.scalar<si8>` ] = Pointer ( hello . data ())
print ( StringRef ( pm . address ))
print ( "variant 5" )
print ( String ( pointer . address ))
print ( "variant 6" )
let x = Buffer [ 8 , DType . int8 ]( pointer )
let array = x . simd_load [ 10 ]( 0 )
var result = String ()
for i in range ( len ( array )):
result += chr ( array [ i ]. to_int ())
print ( result )right click die Datei im Explorer und klicken Sie auf Open With > Editorselect all und copy.ipynbGithub rendert es ordnungsgemäß, und wenn jemand den Code dann auf seinem Spielplatz ausprobieren möchte, kann er den Rohcode kopieren und einfügen.
Es ist meine persönliche Meinung, also beurteilen Sie mich nicht zu hart.
Ich kann nicht sagen, dass Mojo eine einfach zu erlernende Programmiersprache ist, wie beispielsweise Python.
Es erfordert viel Verständnis, Geduld und Erfahrung in allen anderen Programmiersprachen.
Wenn Sie etwas bauen möchten, das nicht trivial ist, wird es schwierig, aber lustig!
Es ist nun zwei Wochen her, seit ich mich auf diese Reise begeben habe, und ich freue mich, Ihnen mitteilen zu können, dass ich das Mojo mittlerweile gut kennengelernt habe.
Die Feinheiten seiner Struktur und Syntax beginnen sich vor meinen Augen zu entwirren , und ich bin von einem neuen Verständnis erfüllt.
Ich bin stolz darauf, sagen zu können, dass ich nun selbstbewusst Code in dieser Sprache erstellen kann und so eine Vielzahl von Ideen zum Leben erwecken kann.
Mojo ist eine Programmiersprache von Modular Inc. Warum Mojo, das haben wir hier besprochen. Über das Unternehmen wissen wir weniger, aber es hat einen sehr coolen Namen Modular , auf den man sich beziehen kann:
„Mit anderen Worten: Mojo ist keine Magie, es ist modular.“
Alles über Computer, Programmierung, KI/ML. Ein sehr guter Domainname, der die Bedeutung des Unternehmens genau beschreibt.
Es gibt einige zusätzliche Materialien zur Markengeschichte von Modular und zur Unterstützung von Modular bei der Humanisierung von KI durch Marke
Heute möchte ich eine Geschichte über das Python Enum-Problem erzählen. Als Softwareentwickler treffen wir es oft im WEB. Angenommen, wir haben dieses Datenbankschema (PostgreSQL) mit der enum :
CREATE TYPE public .status_type AS ENUM (
' FIRST ' ,
' SECOND '
);In einem Python-Code benötigen wir Namen und Werte als Zeichenfolgen (angenommen, wir verwenden GraphQL mit einem ENUM-Typ für unsere Frontend-Seite), und wir müssen ihre Reihenfolge beibehalten und die Möglichkeit haben, diese Aufzählungen zu vergleichen:
order2.status > order1.status > 'FIRST'
Es ist also ein Problem für die meisten gängigen Sprachen =), aber wir können eine little-known Python-Funktion verwenden und die Enum-Klassenmethode überschreiben: __new__ .
MALE -> 1 , FEMALE -> 2 , wie es PostgreSQL tut.len -Funktion! import enum
from functools import total_ordering
@ total_ordering
@ enum . unique
class BaseUniqueSortedEnum ( enum . Enum ):
"""Base unique enum class with ordering."""
def __new__ ( cls , * args , ** kwargs ):
obj = object . __new__ ( cls )
obj . index = len ( cls . __members__ ) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__ ( self ) -> int :
return hash (
f" { self . __module__ } _ { self . __class__ . __name__ } _ { self . name } _ { self . value } "
)
def __eq__ ( self , other ) -> bool :
self . _check_type ( other )
return super (). __eq__ ( other )
def __lt__ ( self , other ) -> bool :
self . _check_type ( other )
return self . index < other . index
def _check_type ( self , other ) -> None :
if type ( self ) != type ( other ):
raise TypeError ( f"Different types of Enum: { self } != { other } " )
class Dog ( BaseUniqueSortedEnum ):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat ( BaseUniqueSortedEnum )
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog . BLOODHOUND < Dog . WEIMARANER
assert Dog . BLOODHOUND <= Dog . WEIMARANER
assert Dog . BLOODHOUND != Dog . WEIMARANER
assert Dog . BLOODHOUND == Dog . BLOODHOUND
assert Dog . WEIMARANER == Dog . WEIMARANER
assert Dog . WEIMARANER > Dog . BLOODHOUND
assert Dog . WEIMARANER >= Dog . BLOODHOUND
assert Cat . BRITISH < Cat . SCOTTISH
assert Cat . BRITISH <= Cat . SCOTTISH
assert Cat . BRITISH != Cat . SCOTTISH
assert Cat . BRITISH == Cat . BRITISH
assert Cat . SCOTTISH == Cat . SCOTTISH
assert Cat . SCOTTISH > Cat . BRITISH
assert Cat . SCOTTISH >= Cat . BRITISH
assert hash ( Dog . BLOODHOUND ) == hash ( Dog . BLOODHOUND )
assert hash ( Dog . WEIMARANER ) == hash ( Dog . WEIMARANER )
assert hash ( Dog . BLOODHOUND ) != hash ( Dog . WEIMARANER )
assert hash ( Dog . SAME ) != hash ( Cat . SAME )
# raise TypeError
Dog . SAME <= Cat . SAME
Dog . SAME < Cat . SAME
Dog . SAME > Cat . SAME
Dog . SAME >= Cat . SAME
Dog . SAME != Cat . SAME Das Ende der Geschichte. und nutzen Sie diese Python ENUM Erkenntnisse für Ihre gute Codierung!


