q transformer
0.3.0
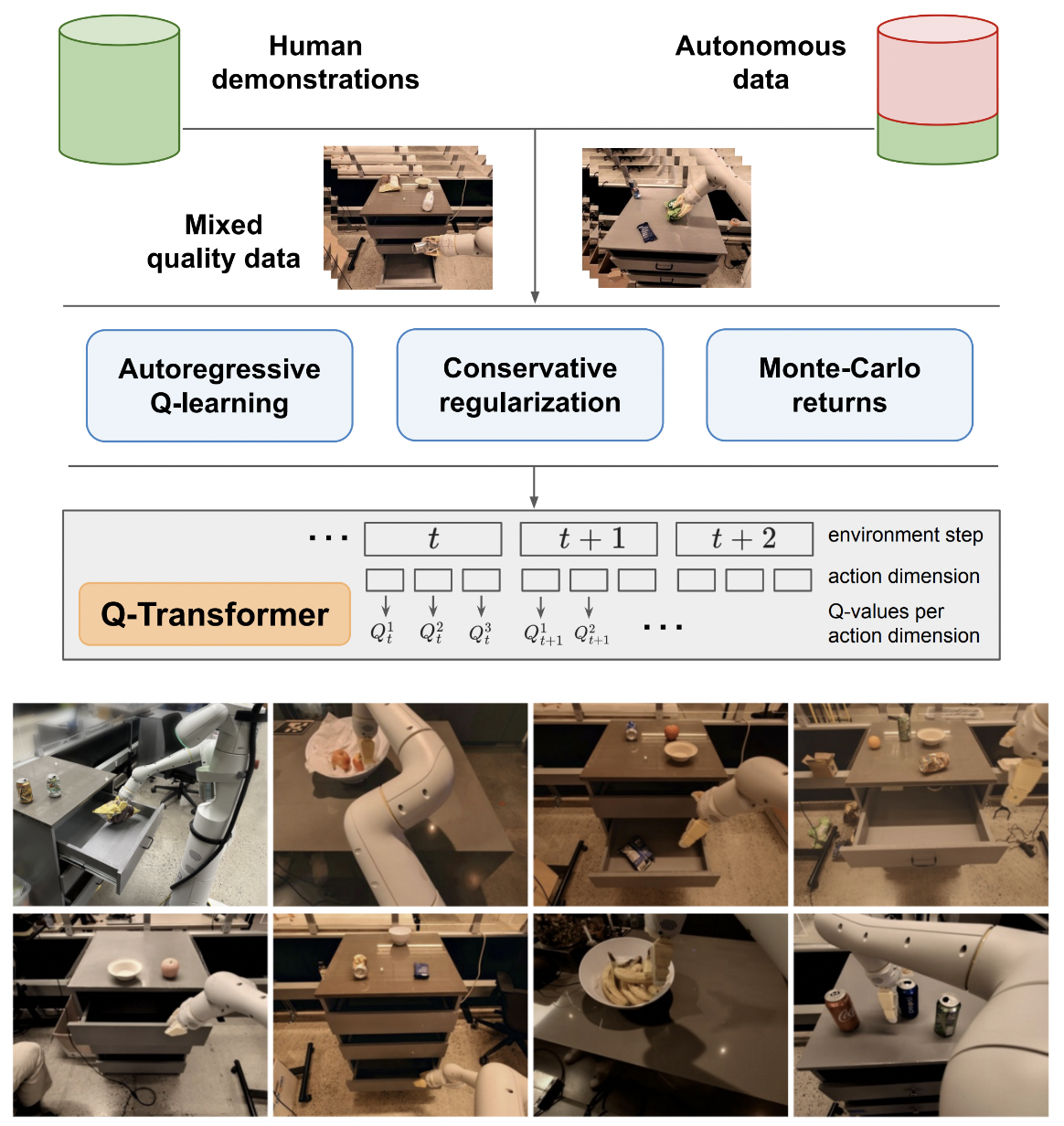
Implementierung von Q-Transformer, skalierbarem Offline-Reinforcement-Lernen über autoregressive Q-Funktionen, aus Google Deepmind
Ich werde die Logik für Q-Learning für einzelne Aktionen beibehalten, nur um einen abschließenden Vergleich mit dem vorgeschlagenen autoregressiven Q-Learning für mehrere Aktionen zu ermöglichen. Auch um der Aufklärung für mich und die Öffentlichkeit zu dienen.
Die autoregressive Q-Learning-Formulierung wurde von Kotb et al. reproduziert.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )erster Arbeitsweg zur Single-Action-Unterstützung
Bieten Sie eine Batchnorm-lose Variante von Maxvit an, wie dies im SOTA-Wettermodell metnet3 der Fall ist
Fügen Sie eine optionale Deep-Duell-Architektur hinzu
Fügen Sie n-stufiges Q-Lernen hinzu
Bauen Sie die konservative Regularisierung auf
Erarbeiten Sie den Hauptvorschlag in Papierform (autoregressive diskrete Aktionen bis zur letzten Aktion, Belohnung wird nur bei der letzten Aktion vergeben)
Improvisieren Sie die Decoder-Kopf-Variante, anstatt vorherige Aktionen in der Phase „Frames + gelernte Token“ zu verketten. Mit anderen Worten: Verwenden Sie den klassischen Encoder-Decoder
Redo Maxvit mit axialen rotierenden Einbettungen + Sigmoid-Gating, um sich um nichts zu kümmern. Aktivieren Sie mit dieser Änderung die Flash-Aufmerksamkeit für Maxvit
Erstellen Sie eine einfache Dataset-Erstellerklasse, übernehmen Sie die Umgebung und das Modell und geben Sie einen Ordner zurück, der von einem ReplayDataset akzeptiert werden kann
ReplayDataset das den Ordner aufnimmt Behandeln Sie mehrere Anweisungen korrekt
Zeigen Sie ein einfaches End-to-End-Beispiel im gleichen Stil wie alle anderen Repos
Behandeln Sie keine Anweisungen, nutzen Sie den Null-Conditioner in der CFG-Bibliothek
Cache-KV für die Aktionsdekodierung
Ermöglichen Sie zur Erkundung die feine Randomisierung einer Teilmenge von Aktionen und nicht aller Aktionen auf einmal
Konsultieren Sie einige RL-Experten und finden Sie heraus, ob es neue Fortschritte bei der Lösung wahnhafter Vorurteile gibt
Finden Sie heraus, ob man mit zufälligen Reihenfolgen von Aktionen trainieren kann – die Reihenfolge könnte als Konditionierung gesendet werden, die vor den Aufmerksamkeitsebenen zusammengefasst oder summiert wird
Einfache Strahlsuchfunktion für optimale Aktionen
Improvisieren Sie die Queraufmerksamkeit auf vergangene Aktionen und Zeitschrittzustände, Transformer-XL-Manier (mit strukturiertem Gedächtnisverlust)
Sehen Sie hier, ob die Hauptidee in diesem Artikel auf Sprachmodelle anwendbar ist
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

