perfusion pytorch
0.1.23
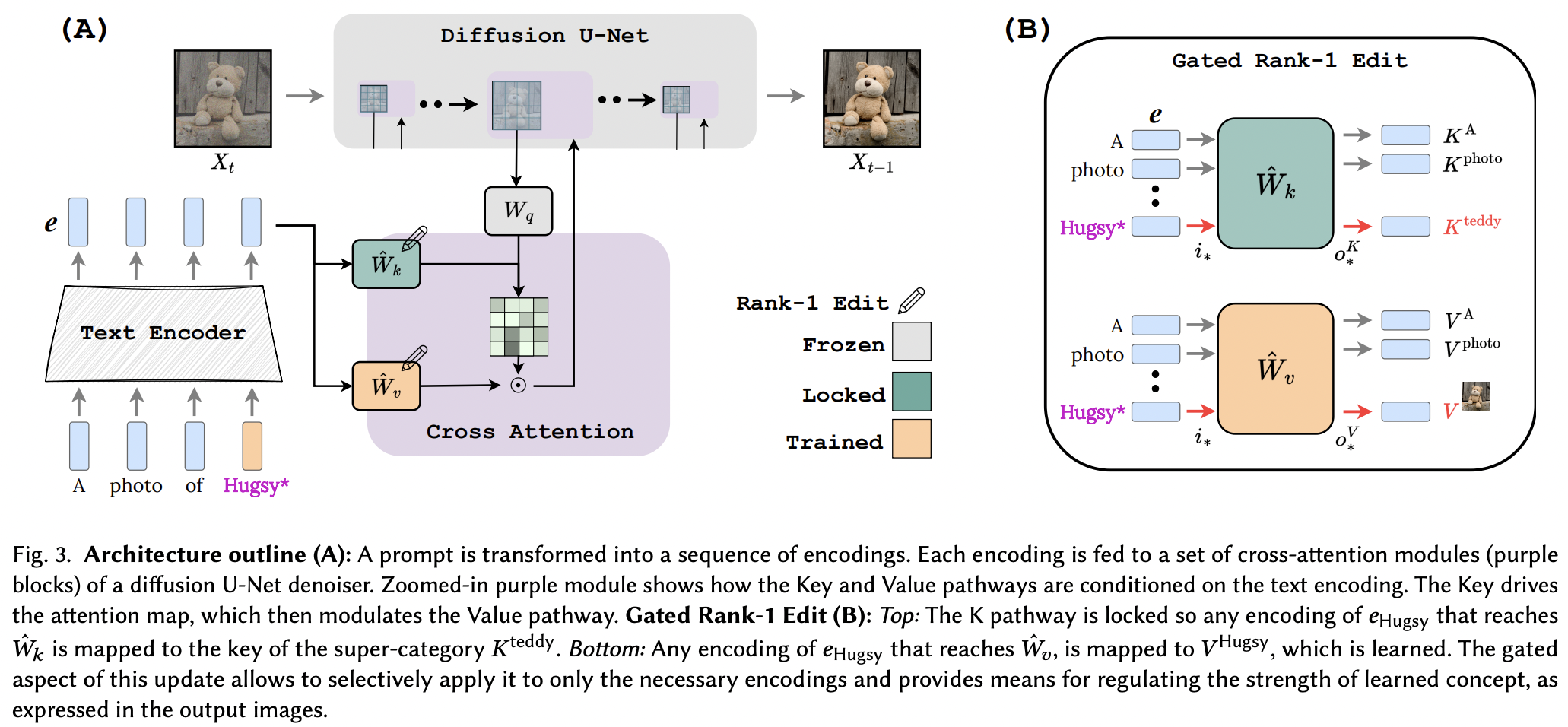
Implementierung von Key-Locked Rank One Editing. Projektseite
Das Verkaufsargument dieses Artikels sind die extrem geringen zusätzlichen Parameter pro hinzugefügtem Konzept, bis hin zu 100 KB.
Es scheint, dass sie die Rang-1-Bearbeitungstechnik aus einem Gedächtnisbearbeitungspapier für LLM erfolgreich angewendet haben, mit einigen Verbesserungen. Sie stellten außerdem fest, dass die Schlüssel das „Wo“ des neuen Konzepts bestimmen, während die Werte das „Was“ bestimmen und eine lokale/globale Schlüsselsperre für ein Oberklassenkonzept vorschlagen (während die Werte gelernt werden).
Für Forscher da draußen: Wenn dieses Papier gelesen wird, sollten die Tools in diesem Repository für jedes andere Text-zu- <insert modality> -Netzwerk funktionieren, das Queraufmerksamkeitskonditionierung verwendet. Nur ein Gedanke
StabilityAI für das großzügige Sponsoring sowie meine anderen Sponsoren da draußen
Vielen Dank an Tewel für die zahlreichen Codeüberprüfungen und klärenden E-Mails
Brad Vidler für die Vorberechnung der Kovarianzmatrix für den in Stable Diffusion 1.5 verwendeten CLIP!
Alle Betreuer von OpenClip für ihre SOTA-Open-Source-Text-Bild-Modelle zum kontrastiven Lernen
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) Das Repository enthält außerdem einen EmbeddingWrapper , der es einfach macht, ein neues Konzept zu trainieren (und eventuelle Rückschlüsse auf mehrere Konzepte zu ziehen).
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask Wenn Sie die CLIP Instanz innerhalb der stabilen Diffusionsinstanz identifizieren können, können Sie sie auch direkt an den OpenClipEmbedWrapper übergeben, um alles zu erhalten, was Sie für die Weiterleitung der Queraufmerksamkeitsebenen benötigen
ex.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) Verkabelung mit SD 1.5, beginnend mit Xiaos Dreambooth-SD
Beispiel in der Readme-Datei für Inferenz mit mehreren Konzepten anzeigen
Leiten Sie automatisch ab, wo sich Schlüssel- und Werteprojektionen befinden, wenn sie nicht für die Funktion make_key_value_proj_rank1_edit_modules_ angegeben werden
Der Einbettungs-Wrapper sollte für die Ersetzung durch die Superklassen-Token-ID sorgen und die Einbettung durch die Superklasse zurückgeben
Überprüfen Sie mehrere Konzepte – dank Yoad
bieten eine Funktion, die die Aufmerksamkeit auf sich zieht
Behandeln Sie mehrere Konzepte in einer Eingabeaufforderung bei Inferenz – Summierung des Sigmoid-Terms + Ausgaben
bieten eine Möglichkeit, separat erlernte Konzepte aus mehreren Rank1EditModule für Rückschlüsse zu einem einzigen zu kombinieren
Rank1EditModule s an Fügen Sie die im Papier vorgeschlagene Zero-Shot-Maskierung des Konzepts hinzu
Kümmern Sie sich um die Funktion, die den Datensatz und den Text-Encoder aufnimmt und die für die Rang-1-Aktualisierung erforderliche Kovarianzmatrix vorberechnet
Anstatt den Forscher sich über unterschiedliche Lernraten Gedanken machen zu lassen, bieten Sie den Trick mit dem fraktionierten Gradienten aus anderen Arbeiten an (um das Einbetten des Konzepts zu erlernen).
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

