self rewarding lm pytorch
0.2.12
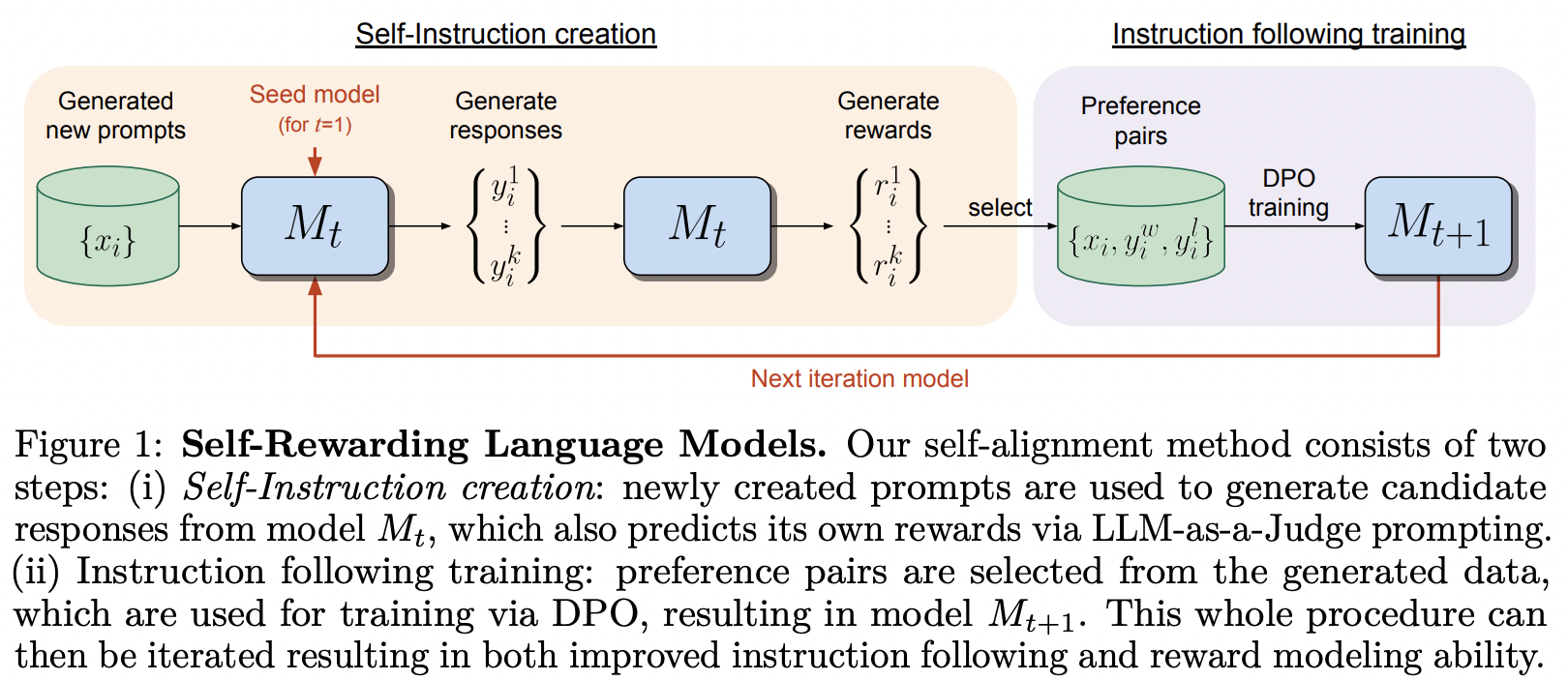
Implementierung des im Self-Rewarding Language Model von MetaAI vorgeschlagenen Trainingsrahmens
Sie haben sich den Titel des DPO-Papiers wirklich zu Herzen genommen.
Diese Bibliothek enthält auch eine Implementierung von SPIN, für die sich Teknium von Nous Research optimistisch geäußert hat.
$ pip install self-rewarding-lm-pytorch import torch
from torch import Tensor
from self_rewarding_lm_pytorch import (
SelfRewardingTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 1 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
prompt_dataset = create_mock_dataset ( 100 , lambda : 'mock prompt' )
def decode_tokens ( tokens : Tensor ) -> str :
decode_token = lambda token : str ( chr ( max ( 32 , token )))
return '' . join ( list ( map ( decode_token , tokens )))
def encode_str ( seq_str : str ) -> Tensor :
return Tensor ( list ( map ( ord , seq_str )))
trainer = SelfRewardingTrainer (
transformer ,
finetune_configs = dict (
train_sft_dataset = sft_dataset ,
self_reward_prompt_dataset = prompt_dataset ,
dpo_num_train_steps = 1000
),
tokenizer_decode = decode_tokens ,
tokenizer_encode = encode_str ,
accelerate_kwargs = dict (
cpu = True
)
)
trainer ( overwrite_checkpoints = True )
# checkpoints after each finetuning stage will be saved to ./checkpointsSPIN kann wie folgt trainiert werden – es kann auch zur Feinabstimmungspipeline hinzugefügt werden, wie im letzten Beispiel in der Readme-Datei gezeigt.
import torch
from self_rewarding_lm_pytorch import (
SPINTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 6 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
spin_trainer = SPINTrainer (
transformer ,
max_seq_len = 16 ,
train_sft_dataset = sft_dataset ,
checkpoint_every = 100 ,
spin_kwargs = dict (
λ = 0.1 ,
),
)
spin_trainer () Angenommen, Sie möchten mit Ihrer eigenen Belohnungsaufforderung experimentieren (außer LLM-as-Judge). Zuerst müssen Sie RewardConfig importieren und es anschließend als reward_prompt_config an den Trainer übergeben
# first import
from self_rewarding_lm_pytorch import RewardConfig
# then say you want to try asking the transformer nicely
# reward_regex_template is the string that will be looked for in the LLM response, for parsing out the reward where {{ reward }} is defined as a number
trainer = SelfRewardingTrainer (
transformer ,
...,
self_reward_prompt_config = RewardConfig (
prompt_template = """
Pretty please rate the following user prompt and response
User: {{ prompt }}
Response: {{ response }}
Format your score as follows:
Rating: <rating as integer from 0 - 10>
""" ,
reward_regex_template = """
Rating: {{ reward }}
"""
)
) Wenn Sie schließlich mit beliebigen Feinabstimmungsreihenfolgen experimentieren möchten, haben Sie diese Flexibilität auch, indem Sie FinetuneConfig Instanzen als Liste an finetune_configs übergeben
ex. Angenommen, Sie möchten Untersuchungen zur Verschachtelung von SPIN, externer Belohnung und Selbstbelohnung durchführen
Diese Idee entstand bei Teknium über einen privaten Discord-Kanal.
# import the configs
from self_rewarding_lm_pytorch import (
SFTConfig ,
SelfRewardDPOConfig ,
ExternalRewardDPOConfig ,
SelfPlayConfig ,
)
trainer = SelfRewardingTrainer (
model ,
finetune_configs = [
SFTConfig (...),
SelfPlayConfig (...),
ExternalRewardDPOConfig (...),
SelfRewardDPOConfig (...),
SelfPlayConfig (...),
SelfRewardDPOConfig (...)
],
...
)
trainer ()
# checkpoints after each finetuning stage will be saved to ./checkpoints Verallgemeinern Sie die Probenahme, sodass sie an verschiedenen Positionen in der Charge erfolgen kann, und legen Sie alle zu stapelnden Proben fest. Lassen Sie auch links aufgefüllte Sequenzen zu, falls einige Leute Transformatoren mit relativen Positionen haben, die dies ermöglichen
Behandeln Sie EOS
Zeigen Sie ein Beispiel für die Verwendung Ihrer eigenen Belohnungsaufforderung anstelle des standardmäßigen „llm-as-judge“.
ermöglichen unterschiedliche Strategien zum Abtasten der Paare
früher Stopper
Jede Reihenfolge von SFT, Spin, selbstbelohnendem DPO, DPO mit externem Belohnungsmodell
Ermöglichen Sie eine Validierungsfunktion für die Belohnungen (sagen wir, die Belohnung muss eine Ganzzahl, eine Gleitkommazahl, ein Wert innerhalb eines bestimmten Bereichs usw. sein).
Finden Sie heraus, wie Sie am besten mit den verschiedenen Impl des KV-Cache umgehen, und verzichten Sie vorerst einfach darauf
Umgebungsflag, das alle Checkpoint-Ordner automatisch löscht
@misc { yuan2024selfrewarding ,
title = { Self-Rewarding Language Models } ,
author = { Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston } ,
year = { 2024 } ,
eprint = { 2401.10020 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { Chen2024SelfPlayFC ,
title = { Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models } ,
author = { Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.01335 } ,
url = { https://api.semanticscholar.org/CorpusID:266725672 }
} @article { Rafailov2023DirectPO ,
title = { Direct Preference Optimization: Your Language Model is Secretly a Reward Model } ,
author = { Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.18290 } ,
url = { https://api.semanticscholar.org/CorpusID:258959321 }
} @inproceedings { Guo2024DirectLM ,
title = { Direct Language Model Alignment from Online AI Feedback } ,
author = { Shangmin Guo and Biao Zhang and Tianlin Liu and Tianqi Liu and Misha Khalman and Felipe Llinares and Alexandre Rame and Thomas Mesnard and Yao Zhao and Bilal Piot and Johan Ferret and Mathieu Blondel } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267522951 }
}

