yoloface
1.0.0
YOLOv3 (You Only Look Once) ist ein hochmoderner Echtzeit-Objekterkennungsalgorithmus. Das veröffentlichte Modell erkennt 80 verschiedene Objekte in Bildern und Videos. Weitere Einzelheiten finden Sie in diesem Dokument.
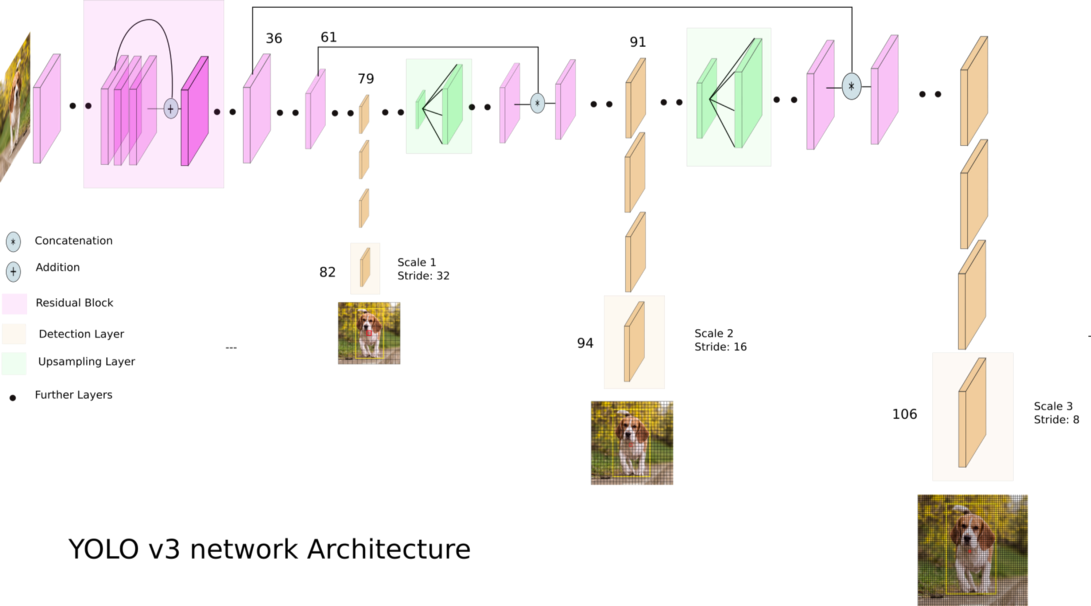
Bildnachweis: Ayoosh Kathuria
Das OpenCV- dnn -Modul unterstützt die Ausführung von Inferenzen auf vorab trainierten Deep-Learning-Modellen aus beliebten Frameworks wie TensorFlow, Torch, Darknet und Caffe.
Die Entwicklung dieses Projekts erfolgt isoliert in einer virtuellen Python-Umgebung. Dadurch können wir mit verschiedenen Versionen von Abhängigkeiten experimentieren.
Es gibt viele Möglichkeiten, virtual environment (virtualenv) zu installieren. Weitere Informationen finden Sie im Python Virtual Environments: A Primer-Leitfaden für verschiedene Plattformen. Hier sind jedoch einige:
$ pip install virtualenv$ pip install --upgrade virtualenvErstellen Sie eine virtuelle Python 3.6-Umgebung für dieses Projekt und aktivieren Sie die virtuelle Umgebung:
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activateAls nächstes installieren Sie die Abhängigkeiten für dieses Projekt:
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface Für die Gesichtserkennung sollten Sie die vorab trainierte YOLOv3-Gewichtungsdatei, die auf dem WIDER FACE: A Face Detection Benchmark-Datensatz trainiert wurde, über diesen Link herunterladen und im Verzeichnis model-weights/ ablegen.
Führen Sie den folgenden Befehl aus:
Bildeingabe
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/Videoeingang
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/Webcam
$ python yoloface.py --src 1 --output-dir outputs/
Dieses Projekt ist unter der MIT-Lizenz lizenziert – weitere Einzelheiten finden Sie in der Datei LICENSE.md.


