rtdl revisiting models
1.0.0
Wichtig
Schauen Sie sich das neue tabellarische DL-Modell an: TabM
arXiv ? Python-Paket Andere tabellarische DL-Projekte
Dies ist die offizielle Umsetzung des Papiers „Revisiting Deep Learning Models for Tabular Data“.
In einem Satz: MLP-ähnliche Modelle sind immer noch gute Grundlagen, und FT-Transformer ist eine neue leistungsstarke Anpassung der Transformer-Architektur für tabellarische Datenprobleme.
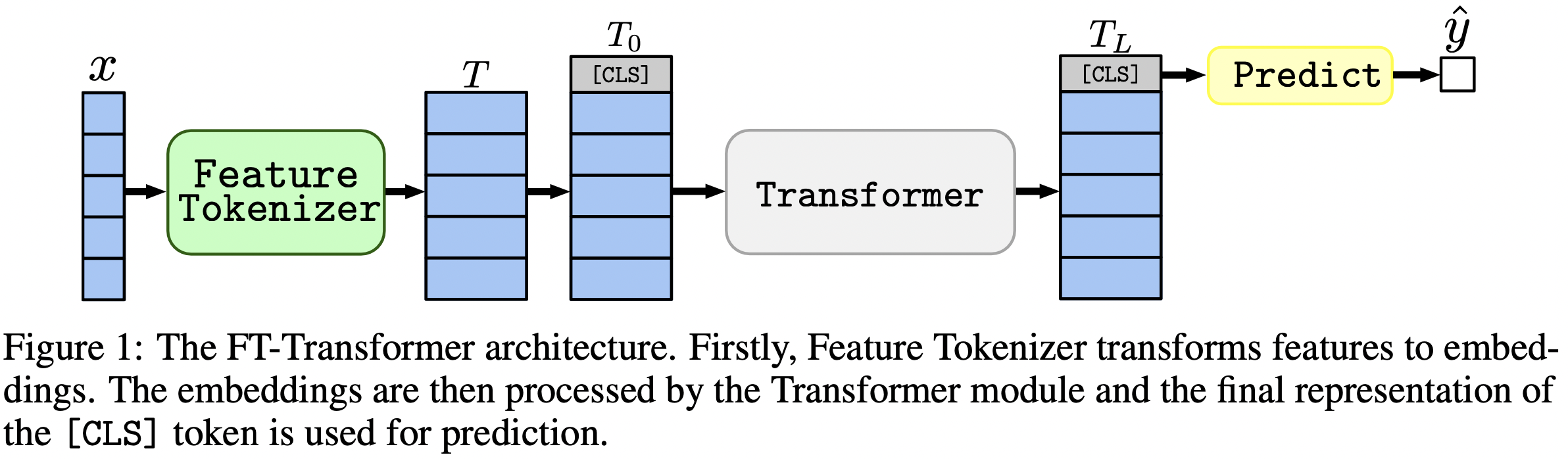
Der Artikel konzentriert sich auf Architekturen für tabellarische Datenprobleme. Die Ergebnisse:
Das Python-Paket im Verzeichnis package/ ist die empfohlene Methode zur Verwendung des Dokuments in der Praxis und für zukünftige Arbeiten.
Der Rest des Dokuments :
Das Verzeichnis output/ enthält zahlreiche Ergebnisse und (abgestimmte) Hyperparameter für verschiedene Modelle und Datensätze, die in der Arbeit verwendet werden.
Lassen Sie uns beispielsweise die Metriken für das MLP-Modell untersuchen. Laden wir zunächst die Berichte (die stats.json -Dateien):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])Berechnen wir nun für jeden Datensatz das über alle Zufallsstartwerte gemittelte Testergebnis:
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Die Ausgabe stimmt genau mit Tabelle 2 aus dem Papier überein:
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
Der obige Ansatz kann auch zur Untersuchung von Hyperparametern verwendet werden, um einen Eindruck von typischen Hyperparameterwerten für verschiedene Algorithmen zu erhalten. So kann man beispielsweise die mittlere abgestimmte Lernrate für das MLP-Modell berechnen:
Notiz
Für einige Algorithmen (z. B. MLP) bieten neuere Projekte mehr Ergebnisse, die auf ähnliche Weise untersucht werden können. Sehen Sie sich zum Beispiel dieses Dokument zu TabR an.
Warnung
Verwenden Sie diesen Ansatz mit Vorsicht. Bei der Untersuchung von Hyperparameterwerten:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536Notiz
Dieser Abschnitt ist lang. Verwenden Sie die „Outline“-Funktion auf GitHub in Ihrem Texteditor, um einen Überblick über diesen Abschnitt zu erhalten.
Der Code ist wie folgt aufgebaut:
bin :ensemble.py führt Ensemling durchtune.py führt eine Optimierung der Hyperparameter durchanalysis_gbdt_vs_nn.py führt die Experimente auscreate_synthetic_data_plots.py erstellt Diagrammelib enthält allgemeine Tools, die von Programmen in bin verwendet werdenoutput enthält Konfigurationsdateien (Eingaben für Programme in bin ) und Ergebnisse (Metriken, optimierte Konfigurationen usw.).package enthält das Python-Paket für dieses Dokument Conda installieren
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsDiese Umgebung wird nur zum Experimentieren mit TabNet benötigt. In allen anderen Fällen verwenden Sie die PyTorch-Umgebung.
Die Anweisungen sind die gleichen wie für die PyTorch-Umgebung (einschließlich der Installation von PyTorch!), jedoch:
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt Folgendes:pip install tensorflow-gpu==1.14tensorboard in requirements.txt ausLIZENZ : Durch das Herunterladen unseres Datensatzes akzeptieren Sie Lizenzen für alle seine Komponenten. Zusätzlich zu diesen Lizenzen führen wir keine neuen Beschränkungen ein. Das Quellenverzeichnis finden Sie im Abschnitt „Referenzen“ unserer Arbeit.
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz Dieser Abschnitt enthält nur spezifische Befehle mit wenigen Kommentaren. Nach Abschluss des Tutorials empfehlen wir, den nächsten Abschnitt zu lesen, um besser zu verstehen, wie man mit dem Repository arbeitet. Es wird auch helfen, das Tutorial besser zu verstehen.
In diesem Tutorial reproduzieren wir die Ergebnisse für MLP im Datensatz „California Housing“. Wir werden Folgendes abdecken:
Beachten Sie, dass die Chancen, genau die gleichen Ergebnisse zu erhalten, eher gering sind, sie sollten sich jedoch nicht wesentlich von unseren unterscheiden. Bevor Sie etwas ausführen, gehen Sie zum Stammverzeichnis des Repositorys und legen Sie explizit CUDA_VISIBLE_DEVICES fest (wenn Sie eine GPU verwenden möchten):
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0Bevor wir beginnen, überprüfen wir, ob die Umgebung erfolgreich konfiguriert wurde. Die folgenden Befehle sollten einen MLP für den California Housing-Datensatz trainieren:
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml Das Ergebnis sollte im Verzeichnis draft/check_environment liegen. Der Inhalt des Ergebnisses ist vorerst nicht wichtig.
Unsere Konfiguration zum Optimieren von MLP für den Datensatz „California Housing“ befindet sich unter output/california_housing/mlp/tuning/0.toml . Um das Tuning zu reproduzieren, kopieren Sie unsere Konfiguration und führen Sie Ihr Tuning aus:
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml Das Ergebnis Ihres Tunings finden Sie unter output/california_housing/mlp/tuning/reproduced . Sie können es mit unserem vergleichen: output/california_housing/mlp/tuning/0 . Die Datei best.toml enthält die beste Konfiguration, die wir im nächsten Abschnitt bewerten werden.
Jetzt müssen wir die abgestimmte Konfiguration mit 15 verschiedenen Zufallsstartwerten bewerten.
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done Unser Verzeichnis mit Evaluierungsergebnissen befindet sich direkt neben Ihrem, nämlich unter output/california_housing/mlp/tuned .
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced Ihre Ergebnisse finden Sie unter output/california_housing/mlp/tuned_reproduced_ensemble . Sie können sie mit unseren vergleichen: output/california_housing/mlp/tuned_ensemble .
Verwenden Sie den hier beschriebenen Ansatz, um die Ergebnisse des durchgeführten Experiments zusammenzufassen (ändern Sie den Pfadfilter in .glob(...) entsprechend: tuned -> tuned_reproduced ).
Ähnliche Schritte können für alle Modelle und Datensätze durchgeführt werden. Bei der Rastersuche ist der Optimierungsprozess etwas anders: Sie müssen alle gewünschten Konfigurationen ausführen und anhand der Validierungsleistung manuell die beste auswählen. Siehe beispielsweise output/epsilon/ft_transformer .
Sie sollten Python-Skripte im Stammverzeichnis des Repositorys ausführen. Die meisten Programme erwarten als einziges Argument eine Konfigurationsdatei. Die Ausgabe ist ein Verzeichnis mit demselben Namen wie die Konfiguration, jedoch ohne die Erweiterung. Konfigurationen werden in TOML geschrieben. Die Listen möglicher Argumente für die Programme werden nicht bereitgestellt und sollten aus Skripten abgeleitet werden (normalerweise wird die Konfiguration in Skripten mit der Variablen args dargestellt). Wenn Sie CUDA verwenden möchten, müssen Sie die Umgebungsvariable CUDA_VISIBLE_DEVICES explizit festlegen. Zum Beispiel:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlWenn Sie CUDA ständig verwenden, können Sie die Umgebungsvariable in der Conda-Umgebung speichern:
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " Die Option -f ( --force ) entfernt die vorhandenen Ergebnisse und führt das Skript von Grund auf aus:
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py unterstützt die Fortsetzung:
python bin/tune.py path/to/config.toml --continuestats.json und andere Ergebnisse Bei allen Skripten ist stats.json der wichtigste Teil der Ausgabe. Der Inhalt variiert von Programm zu Programm. Es kann enthalten:
Vorhersagen für Zug-, Validierungs- und Testsätze werden normalerweise auch gespeichert.
Jetzt wissen Sie alles, was Sie brauchen, um alle Ergebnisse zu reproduzieren und dieses Repository für Ihre Bedürfnisse zu erweitern. Das Tutorial sollte jetzt auch klarer sein. Fühlen Sie sich frei, Probleme zu eröffnen und Fragen zu stellen.
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


