FLASH pytorch
0.1.9
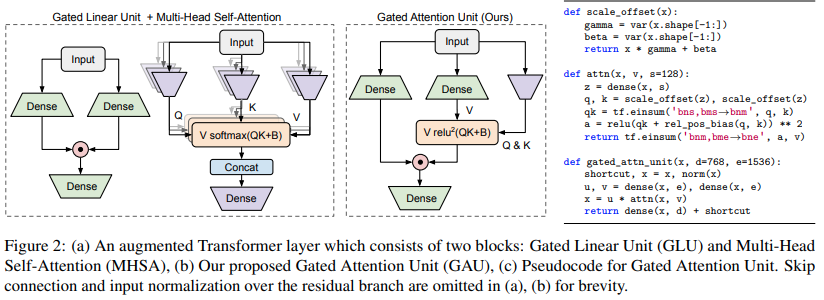
Implementierung der im Artikel „Transformer Quality in Linear Time“ vorgeschlagenen Transformer-Variante
$ pip install FLASH-pytorchDer wichtigste neuartige Schaltkreis in diesem Artikel ist die „Gated Attention Unit“, von der sie behaupten, dass sie die mehrköpfige Aufmerksamkeit ersetzen und sie gleichzeitig auf nur einen Kopf reduzieren kann.
Es verwendet eine Relu-Quadrat-Aktivierung anstelle von Softmax, deren Aktivierung erstmals im Primer-Papier gesehen wurde, und die Verwendung von ReLU in ReLA Transformer. Der Gating-Stil scheint hauptsächlich von gMLPs inspiriert zu sein.
import torch
from flash_pytorch import GAU
gau = GAU (
dim = 512 ,
query_key_dim = 128 , # query / key dimension
causal = True , # autoregressive or not
expansion_factor = 2 , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1024 , 512 )
out = gau ( x ) # (1, 1024, 512) Anschließend kombinieren die Autoren GAU mit der linearen Aufmerksamkeit von Katharopoulos und nutzen die Gruppierung der Sequenzen, um ein bekanntes Problem mit der autoregressiven linearen Aufmerksamkeit zu lösen.
Diese Kombination der quadratischen Gating-Aufmerksamkeitseinheit mit gruppierter linearer Aufmerksamkeit nannten sie FLASH
Das können Sie auch ganz einfach nutzen
import torch
from flash_pytorch import FLASH
flash = FLASH (
dim = 512 ,
group_size = 256 , # group size
causal = True , # autoregressive or not
query_key_dim = 128 , # query / key dimension
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1111 , 512 ) # sequence will be auto-padded to nearest group size
out = flash ( x ) # (1, 1111, 512)Schließlich können Sie den vollständigen FLASH-Transformator verwenden, wie im Dokument erwähnt. Dies enthält alle im Artikel erwähnten Positionseinbettungen. Bei der absoluten Positionseinbettung wird eine skalierte Sinuskurve verwendet. Die quadratische GAU-Aufmerksamkeit erhält eine einköpfige T5-Relativpositionsverzerrung. Darüber hinaus werden sowohl die GAU-Aufmerksamkeit als auch die lineare Aufmerksamkeit rotierend eingebettet (RoPE).
import torch
from flash_pytorch import FLASHTransformer
model = FLASHTransformer (
num_tokens = 20000 , # number of tokens
dim = 512 , # model dimension
depth = 12 , # depth
causal = True , # autoregressive or not
group_size = 256 , # size of the groups
query_key_dim = 128 , # dimension of queries / keys
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
norm_type = 'scalenorm' , # in the paper, they claimed scalenorm led to faster training at no performance hit. the other option is 'layernorm' (also default)
shift_tokens = True # discovered by an independent researcher in Shenzhen @BlinkDL, this simply shifts half of the feature space forward one step along the sequence dimension - greatly improved convergence even more in my local experiments
)
x = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
logits = model ( x ) # (1, 1024, 20000) $ python train.py @article { Hua2022TransformerQI ,
title = { Transformer Quality in Linear Time } ,
author = { Weizhe Hua and Zihang Dai and Hanxiao Liu and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.10447 }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
} @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

