video diffusion pytorch
0.7.0
Dieses Feuerwerk gibt es nicht
Text zu Video, es passiert! Offizielle Projektseite
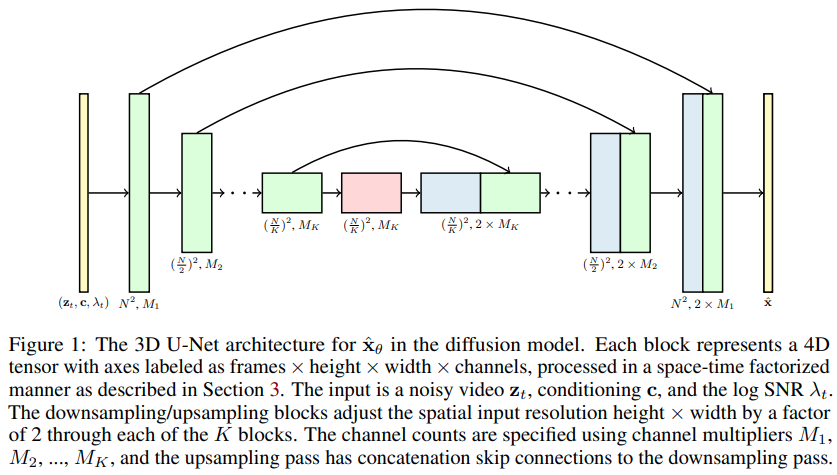
Implementierung von Videodiffusionsmodellen, Jonathan Hos neuer Artikel zur Erweiterung von DDPMs auf die Videogenerierung – in Pytorch. Es nutzt ein spezielles Raum-Zeit-Faktor-U-Netz und erweitert die Generierung von 2D-Bildern auf 3D-Videos
14.000 für schwierig zu bewegende Mnist (konvergiert viel schneller und besser als NUWA) – wip

Die oben genannten Experimente sind nur aufgrund der von Stability.ai bereitgestellten Ressourcen möglich
Alle neuen Entwicklungen für die Text-zu-Video-Synthese werden bei Imagen-pytorch zentralisiert
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)Zur Textkonditionierung leiteten sie Texteinbettungen ab, indem sie zunächst den tokenisierten Text durch BERT-large leiteten. Dann muss man es einfach so trainieren
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)Sie können die Beschreibungen des Videos auch direkt als Zeichenfolgen übergeben, wenn Sie BERT-Base für die Textkonditionierung verwenden möchten
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) Dieses Repository enthält auch eine praktische Trainer für das Training an einem gifs -Ordner. Jedes gif muss die richtigen Abmessungen image_size und num_frames haben.
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train () Beispielvideos (als gif -Dateien) werden regelmäßig in ./results gespeichert, ebenso wie die Parameter des Diffusionsmodells.
Eine der Behauptungen in der Arbeit ist, dass man durch faktorisierte Raum-Zeit-Aufmerksamkeit das Netzwerk dazu zwingen kann, auf die Gegenwart zu achten, um Bilder und Videos zusammen zu trainieren, was zu besseren Ergebnissen führt.
Es war nicht klar, wie sie das erreichten, aber ich habe eine Vermutung geäußert.
Um die Aufmerksamkeit für einen bestimmten Prozentsatz der Batch-Videobeispiele auf den gegenwärtigen Moment zu lenken, übergeben Sie einfach prob_focus_present = <prob> an die Diffusion-Forward-Methode
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()Wenn Sie eine bessere Vorstellung davon haben, wie das geht, öffnen Sie einfach eine Github-Ausgabe.
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

