PALM E
0.0.4

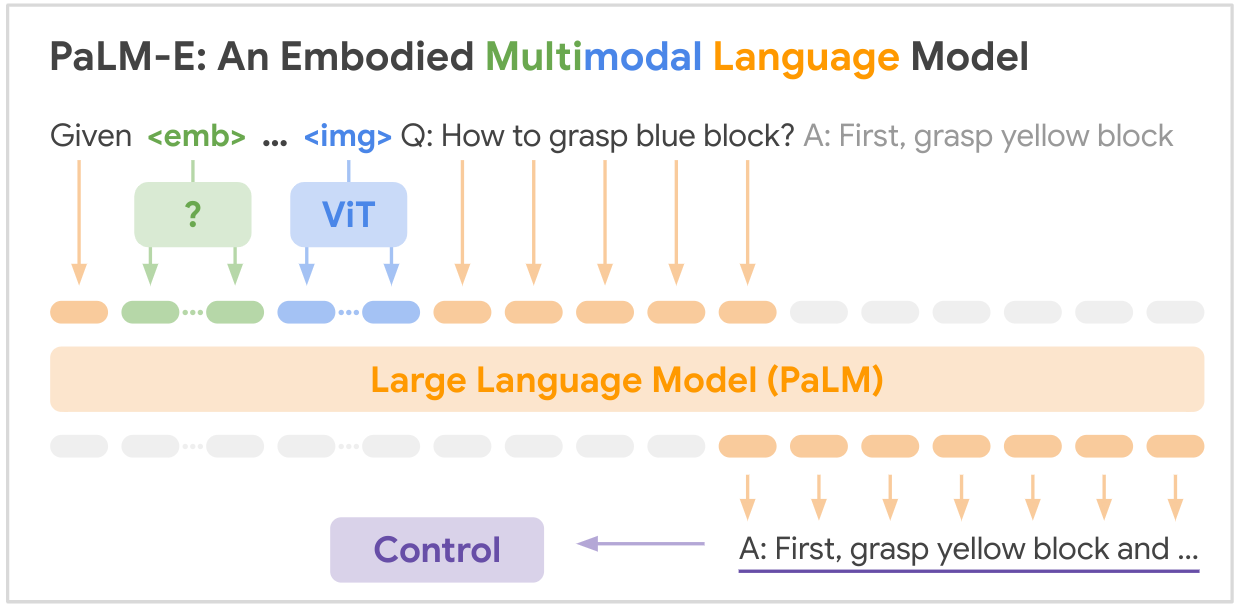
Dies ist die Open-Source-Implementierung des SOTA-Multimodalitäts-Grundmodells „PALM-E: An Embodied Multimodal Language Model“ von Google. PALM-E ist ein einzelnes großes verkörpertes multimodales Modell, das eine Vielzahl verkörperter Argumentationsaufgaben bewältigen kann Eine Vielzahl von Beobachtungsmodalitäten, mehrere Ausführungsformen und darüber hinaus weisen einen positiven Transfer auf: Das Modell profitiert von vielfältigem gemeinsamem Training in den Bereichen Sprache, Vision und visuelle Sprache im Internetmaßstab.
PAPIERLINK: PaLM-E: Ein verkörpertes multimodales Sprachmodell
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
Hier ist eine Übersichtstabelle der wichtigsten Datensätze, die im Papier erwähnt werden:
| Datensatz | Aufgaben | Größe | Link |
|---|---|---|---|
| TAMP | Robotermanipulationsplanung, VQA | 96.000 Szenen | Benutzerdefinierter Datensatz |
| Sprachtabelle | Robotermanipulationsplanung | Benutzerdefinierter Datensatz | Link |
| Mobile Manipulation | Roboternavigation und Manipulationsplanung, VQA | 2912 Sequenzen | Basierend auf dem SayCan-Datensatz |
| WebLI | Bild-Text-Abruf | 66 Millionen Bildunterschriftenpaare | Link |
| VQAv2 | Visuelle Beantwortung von Fragen | 1,1 Millionen Fragen zu COCO-Bildern | Link |
| OK-VQA | Visuelle Beantwortung von Fragen, die externes Wissen erfordern | 14.031 Fragen zu COCO-Bildern | Link |
| COCO | Bildunterschrift | 330.000 Bilder mit Bildunterschriften | Link |
| Wikipedia | Textkorpus | N / A | Link |
Die wichtigsten Robotik-Datensätze wurden speziell für diese Arbeit gesammelt, während die größeren Vision-Language-Datensätze (WebLI, VQAv2, OK-VQA, COCO) Standard-Benchmarks in diesem Bereich sind. Die Datensätze reichen von Zehntausenden Beispielen für die Robotik-Domänen bis hin zu Zehnmillionen für die Vision-Sprachdaten im Internet-Maßstab.
Ihre Brillanz ist gefragt! Machen Sie mit und lassen Sie uns gemeinsam PALM-E noch beeindruckender machen:
? Behebt, ? Verbesserungen, Dokumente oder Ideen – alle sind willkommen! Lassen Sie uns Hand in Hand die Zukunft der KI gestalten.
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

