meshgpt pytorch
1.8.1
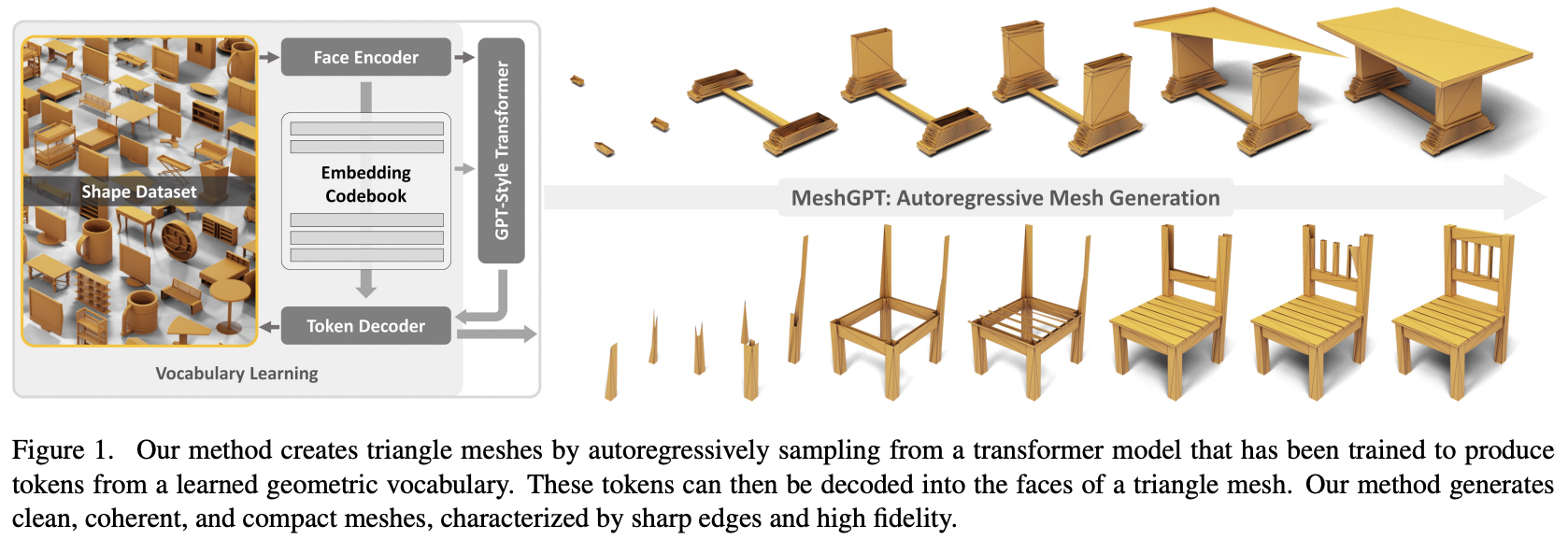
Implementierung von MeshGPT, SOTA Mesh-Generierung mit Attention, in Pytorch
Wird auch eine Textkonditionierung für eventuelle Text-zu-3D-Assets hinzufügen
Bitte treten Sie bei, wenn Sie daran interessiert sind, mit anderen zusammenzuarbeiten, um diese Arbeit zu reproduzieren
Update: Marcus hat trainiert und ein funktionierendes Modell hochgeladen? Umarmendes Gesicht!
StabilityAI, A16Z Open Source AI Grant Program und ? Huggingface für die großzügigen Sponsoren und auch für meine anderen Sponsoren, die mir die Unabhängigkeit gegeben haben, aktuelle Forschung im Bereich der künstlichen Intelligenz als Open-Source-Quelle zu nutzen
Einops, der mir das Leben leichter gemacht hat
Marcus für die erste Codeüberprüfung (mit dem Hinweis auf einige fehlende abgeleitete Funktionen) sowie für die Durchführung der ersten erfolgreichen End-to-End-Experimente
Marcus für das erste erfolgreiche Training einer auf Etiketten basierenden Formenkollektion
Quexi Ma für das Auffinden zahlreicher Fehler bei der automatischen EOS-Behandlung
Yingtian für die Entdeckung eines Fehlers bei der Gaußschen Unschärfe der Positionen für die Glättung räumlicher Beschriftungen
Marcus noch einmal dafür, dass er die Experimente durchgeführt hat, um zu bestätigen, dass es möglich ist, das System von Dreiecken auf Vierecke zu erweitern
Marcus dafür, dass er ein Problem mit der Textkonditionierung identifiziert und alle Experimente durchgeführt hat, die zu seiner Lösung geführt haben
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset Für eine textbedingte 3D-Formsynthese setzen Sie einfach condition_on_text = True auf Ihrem MeshTransformer und übergeben dann Ihre Beschreibungsliste als texts Schlüsselwortargument
ex.
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
) Wenn Sie Netze zur Verwendung in Ihrem multimodalen Transformator tokenisieren möchten, rufen Sie einfach .tokenize auf Ihrem Autoencoder auf (oder dieselbe Methode auf der Autoencoder-Trainer-Instanz für das exponentiell geglättete Modell).
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) Führen Sie im Stammverzeichnis des Projekts Folgendes aus:
$ cp .env.sample .envAutoencoder
face_edges automatisch direkt von Flächen und Scheitelpunkten ableiten können Transformator
Trainer Wrapper mit HF-Beschleunigung
Textkonditionierung mit eigener CFG-Bibliothek
hierarchische Transformatoren (unter Verwendung des RQ-Transformators)
Caching in der einfachen Gateloop-Ebene in einem anderen Repo behoben
lokale Aufmerksamkeit
KV-Caching für zweistufigen hierarchischen Transformator behoben – jetzt 7x schneller und schneller als der ursprüngliche nicht-hierarchische Transformator
Caching für Gateloop-Layer behoben
ermöglichen die Anpassung der Modelldimensionen des feinen vs. groben Aufmerksamkeitsnetzwerks
Finden Sie heraus, ob ein Autoencoder wirklich notwendig ist – er ist notwendig, Ablationen stehen im Papier
Machen Sie den Transformator effizient
spekulative Dekodierungsoption
Verbringen Sie einen Tag mit der Dokumentation
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

