block recurrent transformer pytorch
0.4.4
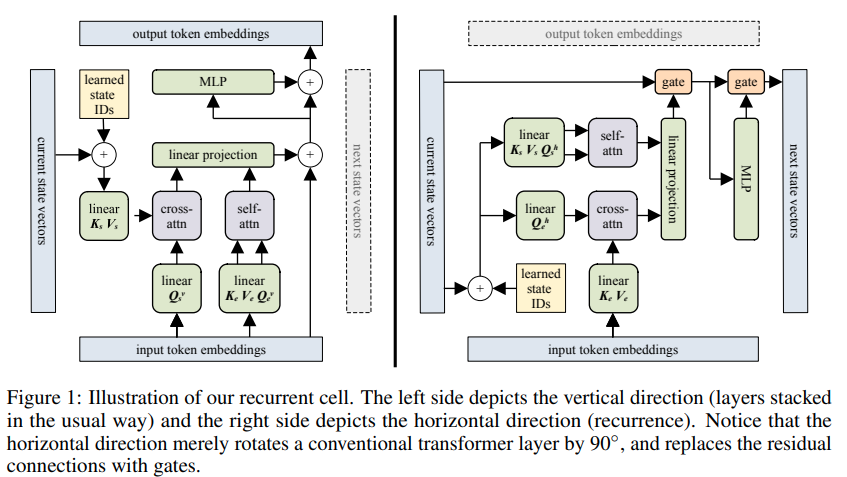
Implementierung eines Block-Recurrent-Transformators – Pytorch. Der Höhepunkt des Papiers ist seine berichtete Fähigkeit, sich an etwas vor bis zu 60.000 Token zu erinnern.
Dieses Design ist SOTA für die Forschungslinie für wiederkehrende Transformatoren, afaict.
Es wird auch Flash-Aufmerksamkeit sowie geroutete Erinnerungen an bis zu 250.000 Token unter Verwendung von Ideen aus diesem Papier beinhalten
$ pip install block-recurrent-transformer-pytorch import torch
from block_recurrent_transformer_pytorch import BlockRecurrentTransformer
model = BlockRecurrentTransformer (
num_tokens = 20000 , # vocab size
dim = 512 , # model dimensions
depth = 6 , # depth
dim_head = 64 , # attention head dimensions
heads = 8 , # number of attention heads
max_seq_len = 1024 , # the total receptive field of the transformer, in the paper this was 2 * block size
block_width = 512 , # block size - total receptive field is max_seq_len, 2 * block size in paper. the block furthest forwards becomes the new cached xl memories, which is a block size of 1 (please open an issue if i am wrong)
num_state_vectors = 512 , # number of state vectors, i believe this was a single block size in the paper, but can be any amount
recurrent_layers = ( 4 ,), # where to place the recurrent layer(s) for states with fixed simple gating
use_compressed_mem = False , # whether to use compressed memories of a single block width, from https://arxiv.org/abs/1911.05507
compressed_mem_factor = 4 , # compression factor of compressed memories
use_flash_attn = True # use flash attention, if on pytorch 2.0
)
seq = torch . randint ( 0 , 2000 , ( 1 , 1024 ))
out , mems1 , states1 = model ( seq )
out , mems2 , states2 = model ( seq , xl_memories = mems1 , states = states1 )
out , mems3 , states3 = model ( seq , xl_memories = mems2 , states = states2 ) Zuerst pip install -r requirements.txt , dann
$ python train.pyVerwenden Sie dynamische Positionsvoreingenommenheit
Fügen Sie eine verbesserte Wiederholung hinzu
Richten Sie lokale Aufmerksamkeitsblöcke ein, wie in der Arbeit
Wrapper-Transformator-Klasse für die Schulung
Kümmern Sie sich um die Generierung mit Wiederholung in RecurrentTrainWrapper
Fügen Sie die Möglichkeit hinzu, während jedes Segmentschritts während des Trainings ganze Erinnerungen und Zustände auszublenden
Testen Sie das gesamte System lokal auf enwik8, entfernen Sie Zustände und Erinnerungen und sehen Sie die Auswirkungen aus erster Hand
Stellen Sie sicher, dass auch Einzelkopfschlüssel/-werte berücksichtigt werden
Führen Sie einige Experimente mit festem Gating in normalen Transformatoren durch – funktioniert nicht
Flash-Aufmerksamkeit integrieren
Cache-Aufmerksamkeitsmaske + rotierende Einbettungen
Fügen Sie komprimierte Speicher hinzu
Besuchen Sie Memformer noch einmal
Versuchen Sie, Langstreckenspeicher von bis zu 250.000 mithilfe des Koordinatenabstiegs zu routen (Wright et al.)
@article { Hutchins2022BlockRecurrentT ,
title = { Block-Recurrent Transformers } ,
author = { DeLesley S. Hutchins and Imanol Schlag and Yuhuai Wu and Ethan Dyer and Behnam Neyshabur } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2203.07852 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Ainslie2023CoLT5FL ,
title = { CoLT5: Faster Long-Range Transformers with Conditional Computation } ,
author = { Joshua Ainslie and Tao Lei and Michiel de Jong and Santiago Ontan'on and Siddhartha Brahma and Yury Zemlyanskiy and David Uthus and Mandy Guo and James Lee-Thorp and Yi Tay and Yun-Hsuan Sung and Sumit Sanghai } ,
year = { 2023 }
}Erinnerung ist Aufmerksamkeit durch die Zeit – Alex Graves


