RoboFlamingo
1.0.0
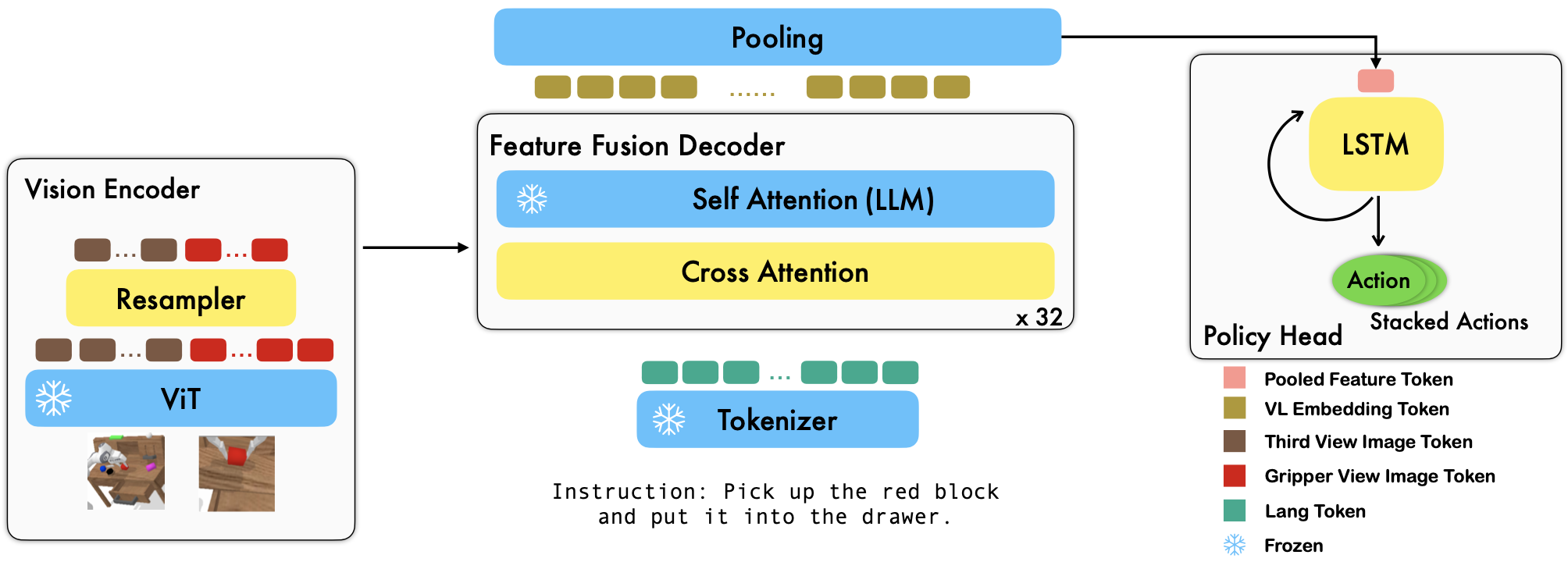
RoboFlamingo ist ein vorab trainiertes, VLM-basiertes Robotik-Lernframework, das eine Vielzahl sprachbedingter Roboterfähigkeiten durch Feinabstimmung anhand von Offline-Datensätzen zur Freiformimitation erlernt. Indem wir die Leistung auf dem neuesten Stand der Technik mit großem Abstand zum CALVIN-Benchmark übertreffen, zeigen wir, dass RoboFlamingo eine effektive und wettbewerbsfähige Alternative zur Anpassung von VLMs an die Robotersteuerung sein kann. Unsere umfangreichen experimentellen Ergebnisse offenbaren auch einige interessante Schlussfolgerungen hinsichtlich des Verhaltens verschiedener vorab trainierter VLMs bei Manipulationsaufgaben. RoboFlamingo kann auf einem einzelnen GPU-Server trainiert oder evaluiert werden (GPU-Speicheranforderungen hängen von der Modellgröße ab), und wir glauben, dass RoboFlamingo das Potenzial hat, eine kostengünstige und benutzerfreundliche Lösung für die Robotermanipulation zu sein, die jedem die Möglichkeit gibt Fähigkeit, ihre eigene Robotikpolitik zu verfeinern.
Dies ist auch das offizielle Code-Repo für den Artikel Vision-Language Foundation Models as Effective Robot Imitators.
Alle unsere Experimente werden auf einem einzigen GPU-Server mit 8 Nvidia A100-GPUs (80G) durchgeführt.
Auf Hugging Face sind vorab trainierte Modelle verfügbar.
Wir unterstützen vorab trainierte Vision-Encoder aus dem OpenCLIP-Paket, das die vorab trainierten Modelle von OpenAI enthält. Wir unterstützen auch vorab trainierte Sprachmodelle aus dem transformers -Paket, wie z. B. MPT-, RedPajama-, LLaMA-, OPT-, GPT-Neo-, GPT-J- und Pythia-Modelle.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) Das Argument cross_attn_every_n_layers steuert, wie oft Queraufmerksamkeitsebenen angewendet werden und mit dem VLM konsistent sein sollten. Das Argument decoder_type steuert den Typ des Decoders. Derzeit unterstützen wir lstm , fc , diffusion (es liegen Fehler für den Datenlader vor) und GPT .
Wir berichten über Ergebnisse zum CALVIN-Benchmark.
| Verfahren | Trainingsdaten | Testaufteilung | 1 | 2 | 3 | 4 | 5 | Durchschn. Len |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD (vollständig) | D | 0,373 | 0,027 | 0,002 | 0,000 | 0,000 | 0,40 |
| HULC | ABCD (vollständig) | D | 0,889 | 0,733 | 0,587 | 0,475 | 0,383 | 3.06 |
| HULC (umgeschult) | ABCD (Sprache) | D | 0,892 | 0,701 | 0,548 | 0,420 | 0,335 | 2,90 |
| RT-1 (umgeschult) | ABCD (Sprache) | D | 0,844 | 0,617 | 0,438 | 0,323 | 0,227 | 2,45 |
| Unsere | ABCD (Sprache) | D | 0,964 | 0,896 | 0,824 | 0,740 | 0,66 | 4.09 |
| MCIL | ABC (vollständig) | D | 0,304 | 0,013 | 0,002 | 0,000 | 0,000 | 0,31 |
| HULC | ABC (vollständig) | D | 0,418 | 0,165 | 0,057 | 0,019 | 0,011 | 0,67 |
| RT-1 (umgeschult) | ABC (Lang) | D | 0,533 | 0,222 | 0,094 | 0,038 | 0,013 | 0,90 |
| Unsere | ABC (Lang) | D | 0,824 | 0,619 | 0,466 | 0,331 | 0,235 | 2,48 |
| HULC | ABCD (vollständig) | D (Anreichern) | 0,715 | 0,470 | 0,308 | 0,199 | 0,130 | 1,82 |
| RT-1 (umgeschult) | ABCD (Sprache) | D (Anreichern) | 0,494 | 0,222 | 0,086 | 0,036 | 0,017 | 0,86 |
| Unsere | ABCD (Sprache) | D (Anreichern) | 0,720 | 0,480 | 0,299 | 0,211 | 0,144 | 1,85 |
| Unsere (Freeze-Emb) | ABCD (Sprache) | D (Anreichern) | 0,737 | 0,530 | 0,385 | 0,275 | 0,192 | 2.12 |
Befolgen Sie die Anweisungen in OpenFlamingo und CALVIN, um den erforderlichen Datensatz und die vorab trainierten VLM-Modelle herunterzuladen.
Laden Sie den CALVIN-Datensatz herunter und wählen Sie eine Aufteilung mit:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugLaden Sie die veröffentlichten OpenFlamingo-Modelle herunter:
| # Parameter | Sprachmodell | Vision-Encoder | Xattn-Intervall* | COCO 4-Schuss-CIDEr | VQAv2 4-Schuss-Genauigkeit | Durchschn. Len | Gewichte |
|---|---|---|---|---|---|---|---|
| 3B | anas-awadalla/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77,3 | 45,8 | 3,94 | Link |
| 3B | anas-awadalla/mpt-1b-redpajama-200b-dolly | openai CLIP ViT-L/14 | 1 | 82,7 | 45,7 | 4.09 | Link |
| 4B | Togethercomputer/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81,8 | 49,0 | 3,67 | Link |
| 4B | Togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85,8 | 49,0 | 3,79 | Link |
| 9B | anas-awadalla/mpt-7b | openai CLIP ViT-L/14 | 4 | 89,0 | 54,8 | 3,97 | Link |
Ersetzen Sie ${lang_encoder_path} und ${tokenizer_path} des Pfadwörterbuchs (z. B. mpt_dict ) in robot_flamingo/models/factory.py für jeden vorab trainierten VLM durch Ihre eigenen Pfade.
Klonen Sie dieses Repo
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
Installieren Sie die erforderlichen Pakete:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} ist der Pfad zum CALVIN-Datensatz;
${lm_path} ist der Pfad zum vorab trainierten LLM;
${tokenizer_path} ist der Pfad zum VLM-Tokenizer;
${openflamingo_checkpoint} ist der Pfad zum vorab trainierten OpenFlamingo-Modell;
${log_file} ist der Pfad zur Protokolldatei.
Wir stellen auch robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash zur Verfügung, um das Training zu starten. Dieser Bash optimiert die MPT-3B-IFT Version des OpenFlamingo-Modells, das die Standard -Hyperparameter zum Trainieren des Modells enthält und den besten Ergebnissen im Artikel entspricht.
python eval_ckpts.py
Durch Hinzufügen des Prüfpunktnamens und -verzeichnisses zu eval_ckpts.py würde das Skript das Modell automatisch laden und auswerten. Wenn Sie beispielsweise den Prüfpunkt im Pfad „Ihr-Prüfpunkt-Pfad“ auswerten möchten, können Sie die Variablen ckpt_dir und ckpt_names in eval_ckpts.py ändern. Die Auswertungsergebnisse werden dann als „logs/Ihr-Prüfpunkt-Präfix“ gespeichert. Protokoll'.
Die unten gezeigten Ergebnisse deuten darauf hin, dass durch Co-Training die meisten Fähigkeiten des VLM-Rückgrats bei VL-Aufgaben erhalten bleiben könnten, während bei Roboteraufgaben etwas Leistung verloren geht.
verwenden
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
Einführung des Co-Trainers RoboFlamingo mit CoCO, VQAV2 und CALVIN. Sie sollten die CoCO- und VQA-Pfade in get_coco_dataset und get_vqa_dataset in robot_flamingo/data/data.py aktualisieren.
| Teilt | SR 1 | SR 2 | SR 3 | SR 4 | SR 5 | Durchschn. Len |
|---|---|---|---|---|---|---|
| Co-Trainer | ABC->D | 82,9 % | 63,6 % | 45,3 % | 32,1 % | 23,4 % |
| Feinabstimmung | ABC->D | 82,4 % | 61,9 % | 46,6 % | 33,1 % | 23,5 % |
| Co-Trainer | ABCD->D | 95,7 % | 85,8 % | 73,7 % | 64,5 % | 56,1 % |
| Feinabstimmung | ABCD->D | 96,4 % | 89,6 % | 82,4 % | 74,0 % | 66,2 % |
| Co-Trainer | ABCD->D (Anreichern) | 67,8 % | 45,2 % | 29,4 % | 18,9 % | 11,7 % |
| Feinabstimmung | ABCD->D (Anreichern) | 72,0 % | 48,0 % | 29,9 % | 21,1 % | 14,4 % |
| Kokos | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE_L | Apfelwein | WÜRZEN | Acc | |
| Feinabstimmung (3B, Nullschuss) | 0,156 | 0,051 | 0,018 | 0,007 | 0,038 | 0,148 | 0,004 | 0,006 | 4.09 |
| Feinabstimmung (3B, 4-Schuss) | 0,166 | 0,056 | 0,020 | 0,008 | 0,042 | 0,158 | 0,004 | 0,008 | 3,87 |
| Co-Train (3B, Nullschuss) | 0,225 | 0,158 | 0,107 | 0,072 | 0,124 | 0,334 | 0,345 | 0,085 | 36,37 |
| Original Flamingo (80B, fein abgestimmt) | - | - | - | - | - | - | 1.381 | - | 82,0 |
Das Logo wird mit MidJourney generiert
Diese Arbeit verwendet Code aus den folgenden Open-Source-Projekten und Datensätzen:
Original: https://github.com/mees/calvin Lizenz: MIT
Original: https://github.com/openai/CLIP Lizenz: MIT
Original: https://github.com/mlfoundations/open_flamingo Lizenz: MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


