RobustSAM
1.0.0
Offizielles Repository für RobustSAM: Segment Anything Robustly on Degraded Images
Projektseite | Papier | Video | Datensatz
August 2024: Zur einfacheren Verwendung können Sie sich über diesen Link auf die Hugging Face-Modellkarten und die Demo von @jadechoghari beziehen.
Juli 2024: Trainingscode, Daten und Modellprüfpunkte für verschiedene ViT-Backbones werden veröffentlicht!
Juni 2024: Inferenzcode wurde veröffentlicht!
Februar 2024: RobustSAM wurde in CVPR 2024 aufgenommen!
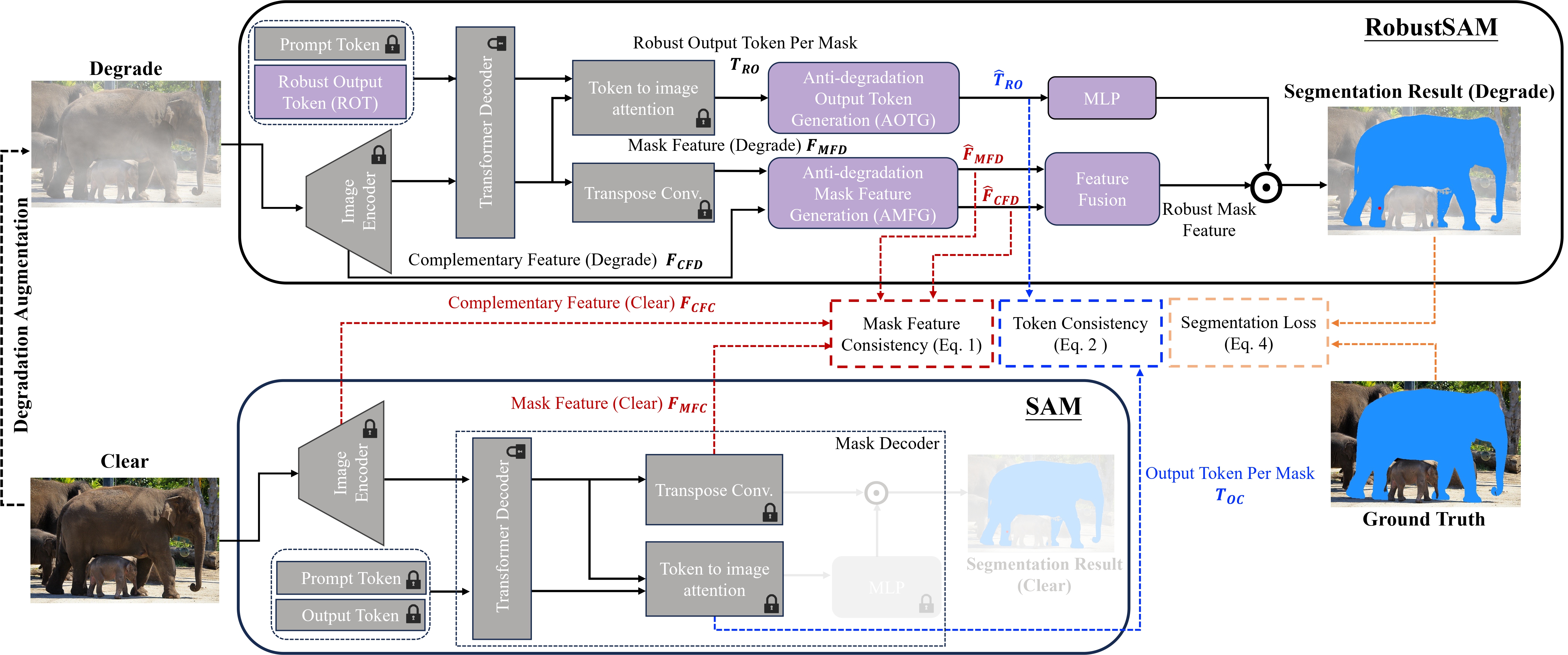
Das Segment Anything Model (SAM) hat sich als transformativer Ansatz in der Bildsegmentierung herausgestellt und ist für seine robusten Zero-Shot-Segmentierungsfunktionen und sein flexibles Eingabeaufforderungssystem bekannt. Dennoch wird seine Leistung durch Bilder mit verminderter Qualität beeinträchtigt. Um diese Einschränkung zu beseitigen, schlagen wir das Robust Segment Anything Model (RobustSAM) vor, das die Leistung von SAM bei Bildern mit geringer Qualität verbessert und gleichzeitig seine Schnelligkeit und Zero-Shot-Generalisierung beibehält.
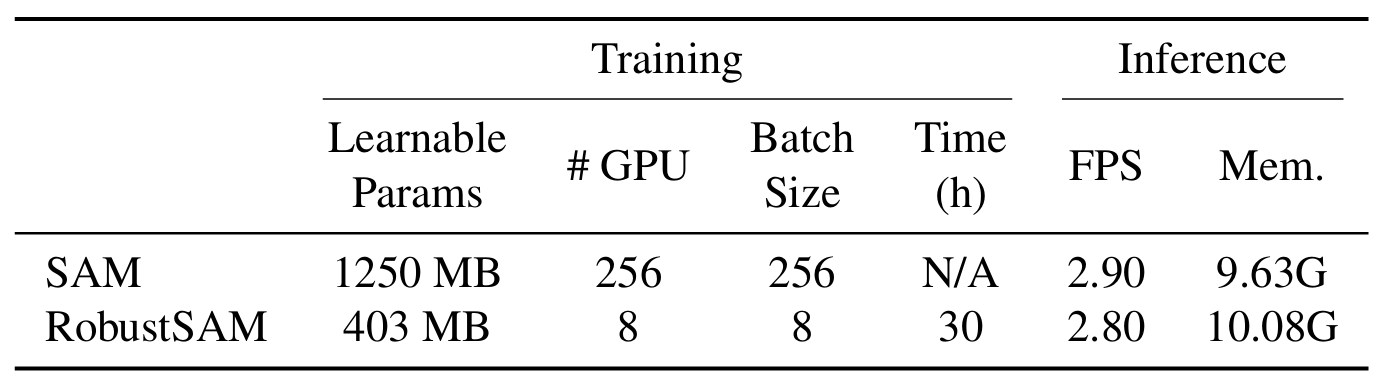
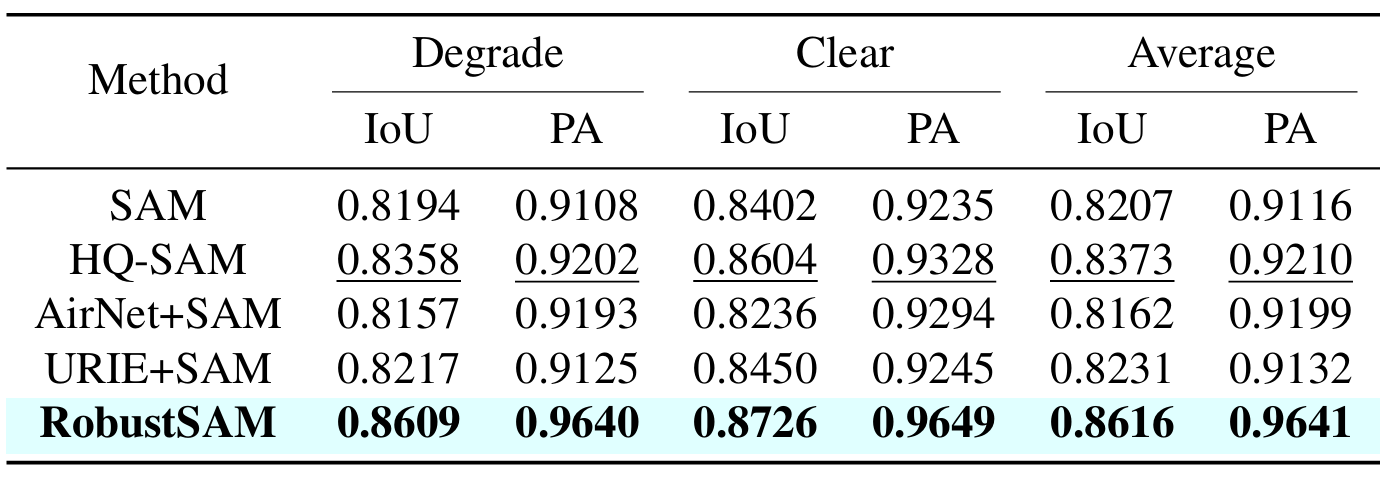
Unsere Methode nutzt das vorab trainierte SAM-Modell mit nur geringfügigen Parameterinkrementen und Rechenanforderungen. Die zusätzlichen Parameter von RobustSAM können innerhalb von 30 Stunden auf acht GPUs optimiert werden, was seine Machbarkeit und Praktikabilität für typische Forschungslabore demonstriert. Wir stellen außerdem den Robust-Seg-Datensatz vor, eine Sammlung von 688.000 Bildmaskenpaaren mit unterschiedlichen Verschlechterungen, die darauf ausgelegt sind, unser Modell optimal zu trainieren und auszuwerten. Umfangreiche Experimente mit verschiedenen Segmentierungsaufgaben und Datensätzen bestätigen die überlegene Leistung von RobustSAM, insbesondere unter Zero-Shot-Bedingungen, und unterstreichen sein Potenzial für umfangreiche reale Anwendungen. Darüber hinaus hat sich gezeigt, dass unsere Methode die Leistung von SAM-basierten Downstream-Aufgaben wie der Enttrübung und Unschärfe einzelner Bilder effektiv verbessert.
Erstellen Sie eine Conda-Umgebung und aktivieren Sie sie.
conda create --name robustsam python=3.10 -y conda activate robustsam
Klonen und in das Repo-Verzeichnis eingeben.
git clone https://github.com/robustsam/RobustSAM cd RobustSAM
Verwenden Sie den folgenden Befehl, um Ihre CUDA-Version zu überprüfen.
nvidia-smi
Ersetzen Sie unten die CUDA-Version durch Ihre befehlshabende Version.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu[$YOUR_CUDA_VERSION] # For example: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 # cu117 = CUDA_version_11.7
Installieren Sie die verbleibenden Abhängigkeiten
pip install -r requirements.txt
Laden Sie vorab trainierte RobustSAM-Prüfpunkte unterschiedlicher Größe herunter und platzieren Sie sie im aktuellen Verzeichnis.
ViT-B RobustSAM-Kontrollpunkt
ViT-L RobustSAM-Prüfpunkt
ViT-H RobustSAM-Kontrollpunkt
Ändern Sie das aktuelle Verzeichnis in das Verzeichnis „data“.
cd data
Laden Sie Zug-, Validierungs-, Test- und zusätzliche COCO- und LVIS-Datensätze herunter. (HINWEIS: Bilder im Zug-, Prüf- und Testdatensatz bestehen aus Bildern von LVIS, MSRA10K, ThinObject-5k, NDD20, STREETS und FSS-1000)
bash download.sh
Im vorherigen Schritt wurden nur klare Bilder heruntergeladen. Verwenden Sie den folgenden Befehl, um entsprechende beeinträchtigte Bilder zu generieren.
bash gen_data.sh
Wenn Sie von Grund auf trainieren möchten, verwenden Sie den folgenden Befehl.
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l
Wenn Sie von einem vorab trainierten Kontrollpunkt aus trainieren möchten, verwenden Sie den folgenden Befehl.
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] --load_model [$CHECKPOINT_PATH] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l --load_model robustsam_checkpoint_l.pth
python gradio_app.py
Wir haben einige Bilder im Ordner demo_images für Demozwecke vorbereitet. Außerdem stehen zwei Eingabeaufforderungsmodi zur Verfügung (Box-Eingabeaufforderungen und Punkt-Eingabeaufforderungen).
Für die Box-Eingabeaufforderung:
python eval.py --bbox --model_size l
Zur Punktaufforderung:
python eval.py --model_size l
Standardmäßig werden Demo-Ergebnisse unter demo_result/[$PROMPT_TYPE] gespeichert.
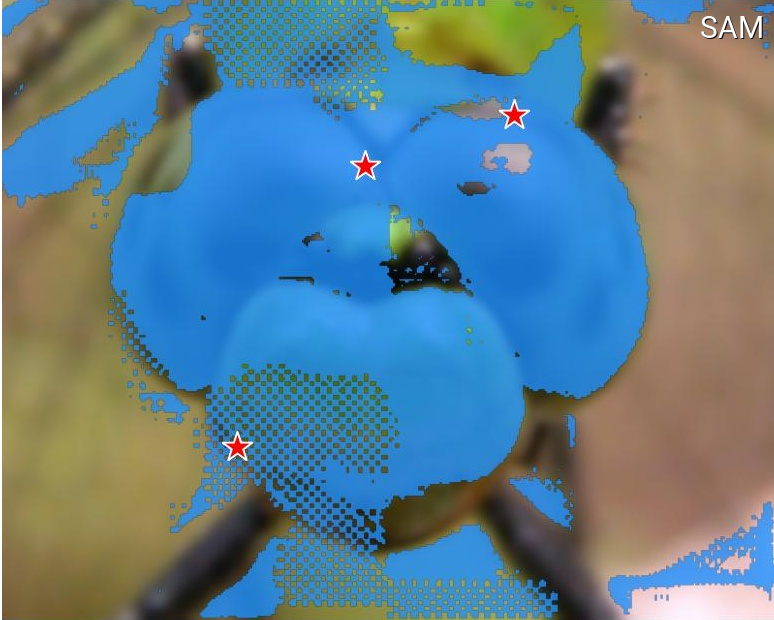 |  |
 |  |

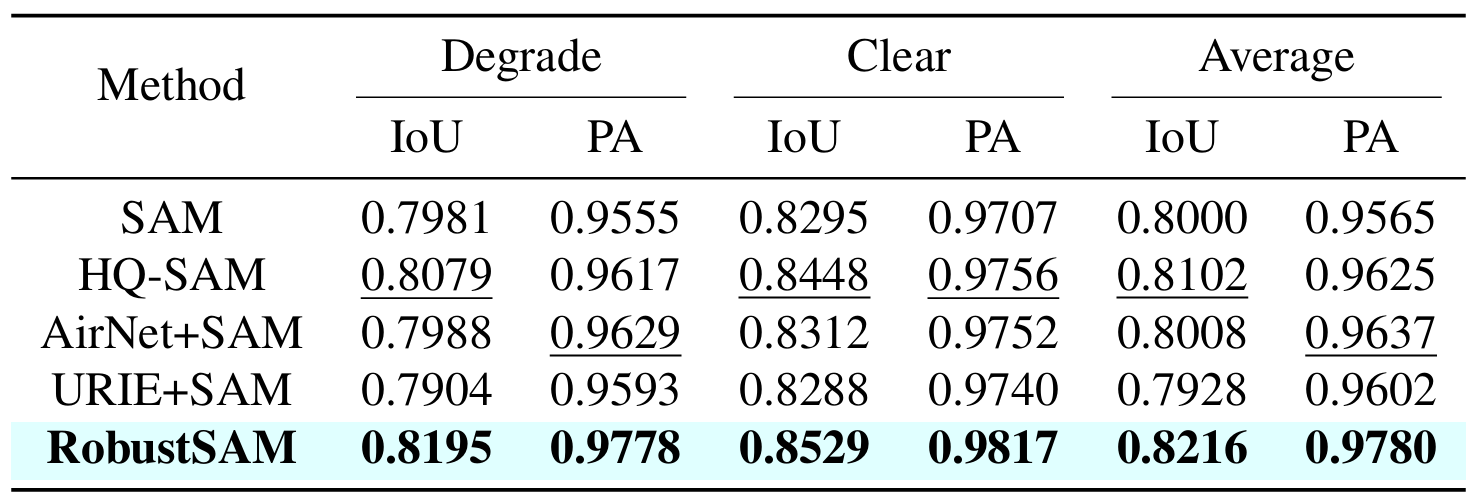
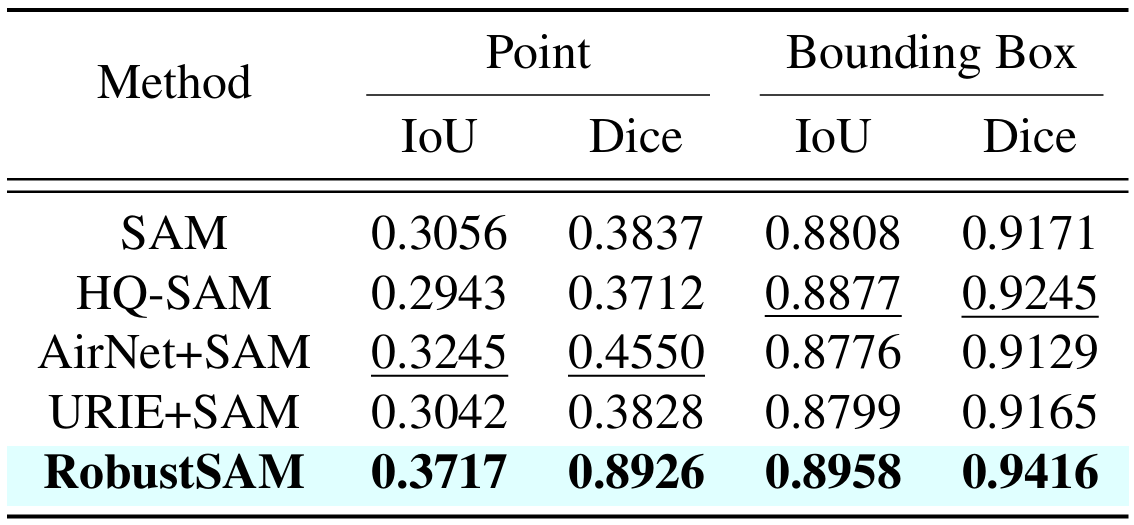
Wenn Sie diese Arbeit nützlich finden, denken Sie bitte darüber nach, uns zu zitieren!
@inproceedings{chen2024robustsam, Titel={RobustSAM: Segment Anything Robustly on Degraded Images}, Autor={Chen, Wei-Ting und Vong, Yu-Jiet und Kuo, Sy-Yen und Ma, Sizhou und Wang, Jian}, Zeitschrift= {CVPR}, Jahr={2024}}Wir danken den Autoren von SAM, auf dem unser Repo basiert.


