algebraic nnhw
1.0.0
Dieses Repository enthält den Quellcode für ML-Hardwarearchitekturen, die fast die Hälfte der Multiplikatoreinheiten benötigen, um die gleiche Leistung zu erzielen, indem alternative Innenproduktalgorithmen ausgeführt werden, die fast die Hälfte der Multiplikationen gegen kostengünstige Additionen mit niedriger Bitbreite eintauschen und dennoch eine identische Ausgabe erzeugen als konventionelles inneres Produkt. Dies erhöht den theoretischen Durchsatz und die Recheneffizienzgrenzen von ML-Beschleunigern. Ausführliche Informationen finden Sie in der folgenden Zeitschriftenveröffentlichung:
TE Pogue und N. Nicolici, „Fast Inner-Product Algorithms and Architectures for Deep Neural Network Accelerators“, in IEEE Transactions on Computers, vol. 73, nein. 2, S. 495–509, Februar 2024, doi: 10.1109/TC.2023.3334140.
Artikel-URL: https://ieeexplore.ieee.org/document/10323219
Open-Access-Version: https://arxiv.org/abs/2311.12224
Zusammenfassung: Wir stellen einen neuen Algorithmus namens Free-pipeline Fast Inner Product (FFIP) und seine Hardware-Architektur vor, die einen wenig erforschten schnellen Inner-Product-Algorithmus (FIP) verbessern, der 1968 von Winograd vorgeschlagen wurde. Im Gegensatz zu den nicht verwandten Winograd-Minimalfilteralgorithmen für Faltungsschichten ist FIP auf alle Modellschichten für maschinelles Lernen (ML) anwendbar, die sich hauptsächlich in Matrixmultiplikation zerlegen lassen, einschließlich vollständig verbundener, Faltungs-, wiederkehrender und Aufmerksamkeits-/Transformerschichten. Wir implementieren FIP zum ersten Mal in einem ML-Beschleuniger und stellen dann unseren FFIP-Algorithmus und die verallgemeinerte Architektur vor, die die Taktfrequenz von FIP und damit den Durchsatz bei ähnlichen Hardwarekosten von Natur aus verbessern. Schließlich tragen wir ML-spezifische Optimierungen für die FIP- und FFIP-Algorithmen und -Architekturen bei. Wir zeigen, dass FFIP nahtlos in herkömmliche Festkomma-ML-Beschleuniger mit systolischem Array integriert werden kann, um den gleichen Durchsatz mit der halben Anzahl von Multiply-Accumulate (MAC)-Einheiten zu erreichen, oder es kann die maximale systolische Array-Größe, die auf Geräte passt, verdoppeln ein festes Hardwarebudget. Unsere FFIP-Implementierung für nicht-sparse ML-Modelle mit 8- bis 16-Bit-Festkomma-Eingängen erzielt einen höheren Durchsatz und eine höhere Recheneffizienz als die besten Lösungen früherer Klasse auf derselben Art von Rechenplattform.
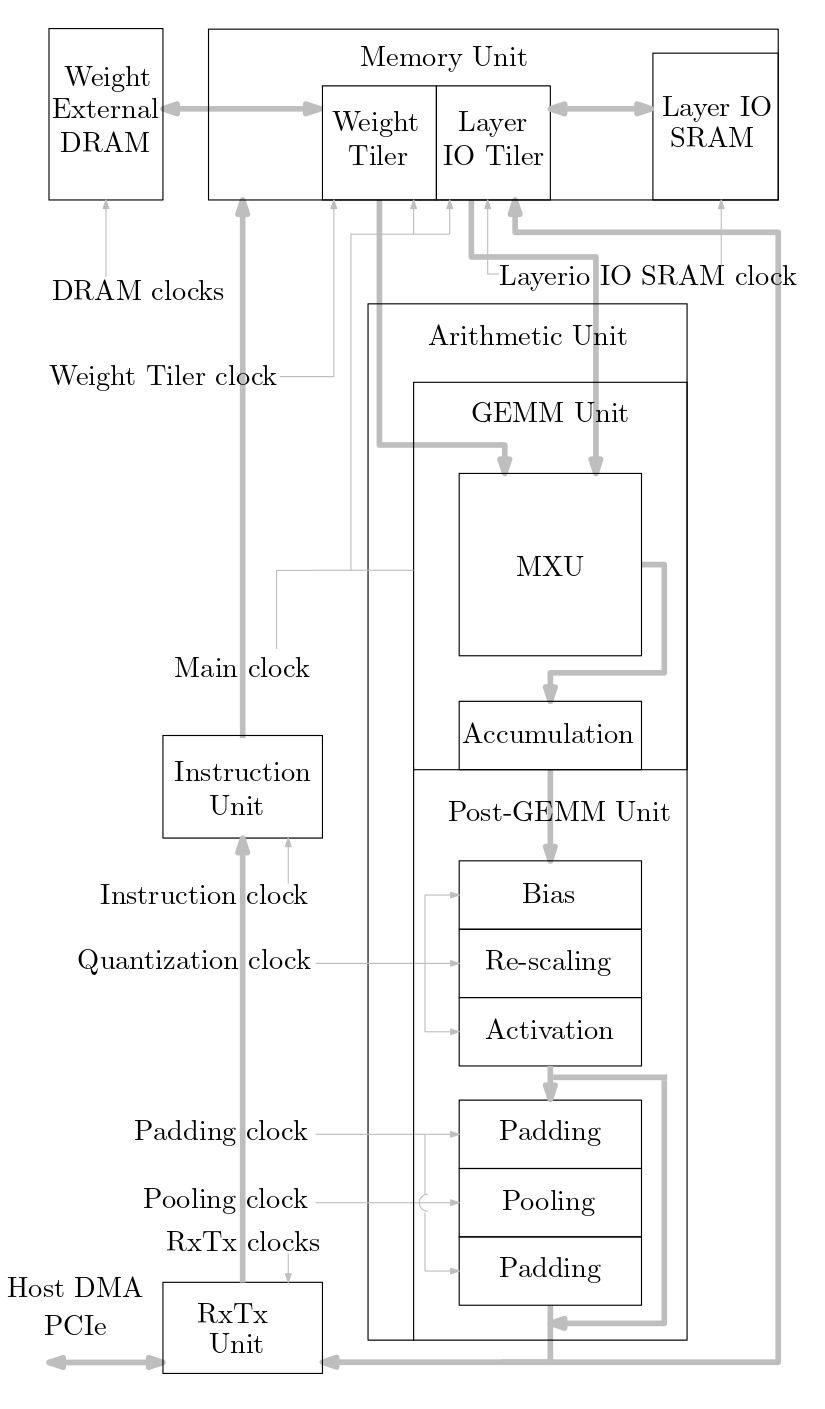
Das folgende Diagramm zeigt einen Überblick über das in diesem Quellcode implementierte ML-Beschleunigersystem:
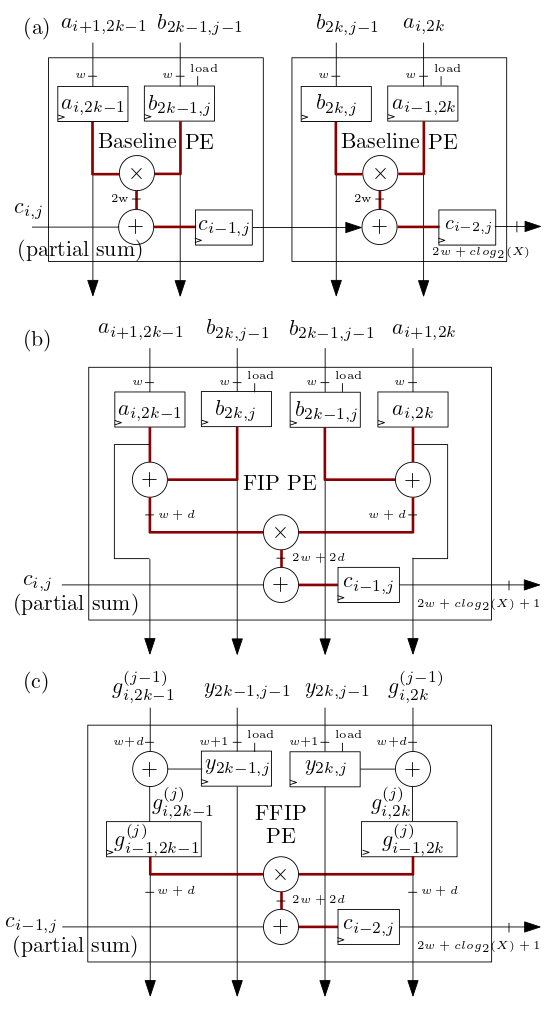
Die unten in (b) und (c) gezeigten systolischen Array-/MXU-Verarbeitungselemente (PE) von FIP und FFIP implementieren die FIP- und FFIP-Innenproduktalgorithmen und bieten jeweils einzeln die gleiche effektive Rechenleistung wie die beiden in ( a) kombiniert, die das grundlegende innere Produkt wie in früheren ML-Beschleunigern mit systolischem Array implementieren:
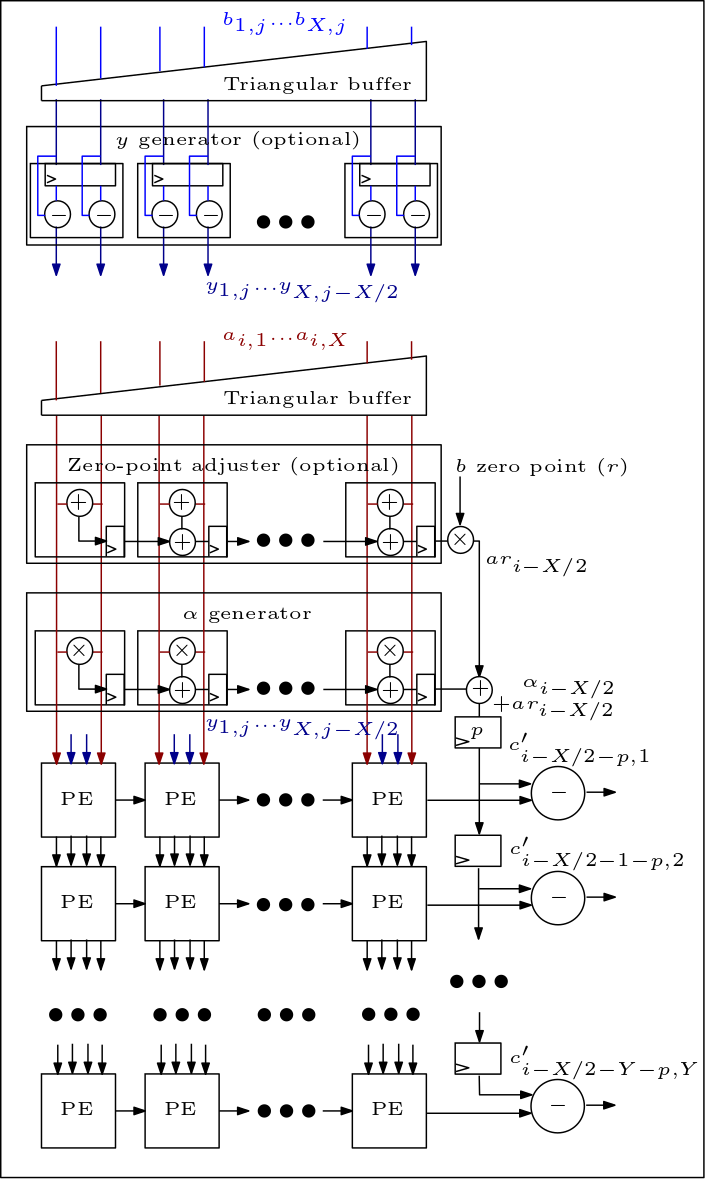
Das Folgende ist ein Diagramm des MXU/Systolic-Arrays und zeigt, wie die PEs verbunden sind:
Die Organisation des Quellcodes ist wie folgt:
Die Dateien rtl/top/define.svh und rtl/top/pkg.sv enthalten eine Reihe konfigurierbarer Parameter wie FIP_METHOD in define.svh, das den systolischen Array-Typ (Baseline, FIP oder FFIP) definiert, SZI und SZJ, die definieren die Höhe/Breite des systolischen Arrays und LAYERIO_WIDTH/WEIGHT_WIDTH, die die Eingabebitbreiten definieren.
Das Verzeichnis rtl/arith enthält mxu.sv und mac_array.sv, die die RTL für die systolischen Array-Architekturen Baseline, FIP und FFIP enthalten (abhängig vom Wert des Parameters FIP_METHOD).


