toyCarIRL
1.0.0
Reinforcement Learning (RL) ist die grundlegendste und intuitivste Form des Versuch-und-Irrtum-Lernens. Auf diese Weise lernen die meisten lebenden Organismen mit irgendeiner Form von Denkfähigkeiten. Dies wird oft als „Lernen durch Erkunden“ bezeichnet und ist die Art und Weise, wie ein neugeborenes menschliches Baby lernt, seine ersten Schritte zu machen, indem es zunächst zufällige Aktionen ausführt und dann langsam herausfindet, welche Aktionen zur Vorwärtsbewegung führen.
Beachten Sie, dass dieser Beitrag ein gutes Verständnis des Reinforcement-Lernrahmens voraussetzt. Machen Sie sich bitte in Woche 5 und 6 dieses großartigen Online-Kurses AI_Berkeley mit RL vertraut.
Die Frage, die ich mir nun immer wieder gestellt habe, ist: Was ist die treibende Kraft für diese Art des Lernens, was zwingt den Agenten, ein bestimmtes Verhalten auf die Art und Weise zu lernen, wie er es tut? Als ich mehr über RL erfuhr, stieß ich auf die Idee der Belohnungen . Grundsätzlich versucht der Agent, seine Aktionen so auszuwählen, dass die Belohnungen, die er aus diesem bestimmten Verhalten erhält, maximiert werden. Um nun den Agenten dazu zu bringen, unterschiedliche Verhaltensweisen auszuführen, muss die Belohnungsstruktur geändert/ausgenutzt werden. Angenommen, wir haben nur das Wissen über das Verhalten des Experten bei uns, wie schätzen wir dann die Belohnungsstruktur bei einem bestimmten Verhalten in der Umgebung ein? Nun, das ist genau das Problem des Inverse Reinforcement Learning (IRL) , bei dem wir angesichts der optimalen Expertenpolitik (die eigentlich als optimal angenommen wird) die zugrunde liegende Belohnungsstruktur bestimmen möchten.
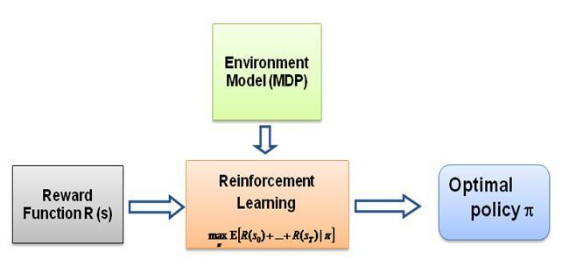
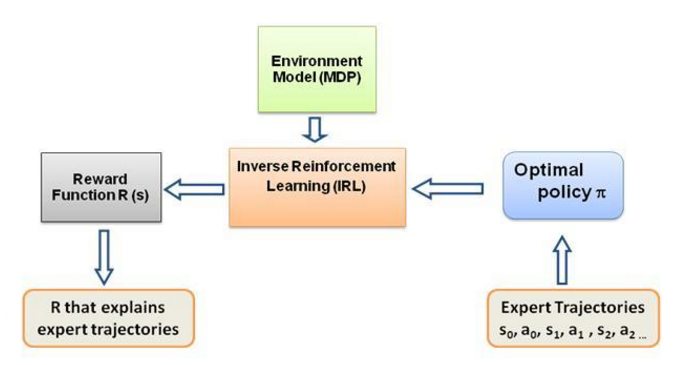
Auch hier handelt es sich nicht um eine Einführung in das Inverse-Reinforcement-Learning-Beitrag, sondern um ein Tutorial zur Verwendung/Codierung des Inverse-Reinforcement-Learning-Frameworks für Ihr eigenes Problem, aber IRL ist der Kern davon und es ist von grundlegender Bedeutung, es zu kennen es zuerst. IRL wurde in der Vergangenheit ausführlich untersucht und es wurden Algorithmen dafür entwickelt. Weitere Informationen finden Sie in den Artikeln Ng und Russell, 2000, und Abbeel und Ng, 2004.
Dieser Beitrag adaptiert den Algorithmus von Abbeel und Ng, 2004 zur Lösung des IRL-Problems.
Die Idee hier besteht darin, einen einfachen Agenten in einer 2D-Welt voller Hindernisse zu programmieren, um verschiedene Verhaltensweisen in der Umgebung zu kopieren/klonen. Die Verhaltensweisen werden mithilfe von Expertentrajektorien eingegeben, die manuell von einem Mensch/Computer-Experten vorgegeben werden. Diese Form des Lernens aus Expertendemonstrationen wird in der wissenschaftlichen Literatur als Apprenticeship Learning bezeichnet. Ihr Kernstück ist inverses Reinforcement Learning, und wir versuchen lediglich, die verschiedenen Belohnungsfunktionen für diese unterschiedlichen Verhaltensweisen herauszufinden.
Im Allgemeinen ist es ja dasselbe, was bedeutet, dass man aus Demonstrationen lernen kann (LfD). Beide Methoden lernen aus der Demonstration, aber sie lernen unterschiedliche Dinge:
Beim Lehrlingslernen wird durch inverses Verstärkungslernen versucht, auf das Ziel des Lehrers zu schließen . Mit anderen Worten: Es lernt aus der Beobachtung eine Belohnungsfunktion, die dann beim verstärkenden Lernen verwendet werden kann. Wenn es erkennt, dass das Ziel darin besteht, einen Nagel mit einem Hammer zu schlagen, ignoriert es Blinzeln und Kratzen des Lehrers, da diese für das Ziel irrelevant sind.
Beim Nachahmungslernen (auch bekannt als Verhaltensklonen) wird versucht , den Lehrer direkt zu kopieren . Dies kann allein durch überwachtes Lernen erreicht werden. Die KI wird versuchen, jede Aktion zu kopieren, auch irrelevante Aktionen wie zum Beispiel Blinzeln oder Kratzen oder sogar Fehler. Auch hier könnte man RL nutzen, allerdings nur, wenn man über eine Belohnungsfunktion verfügt.
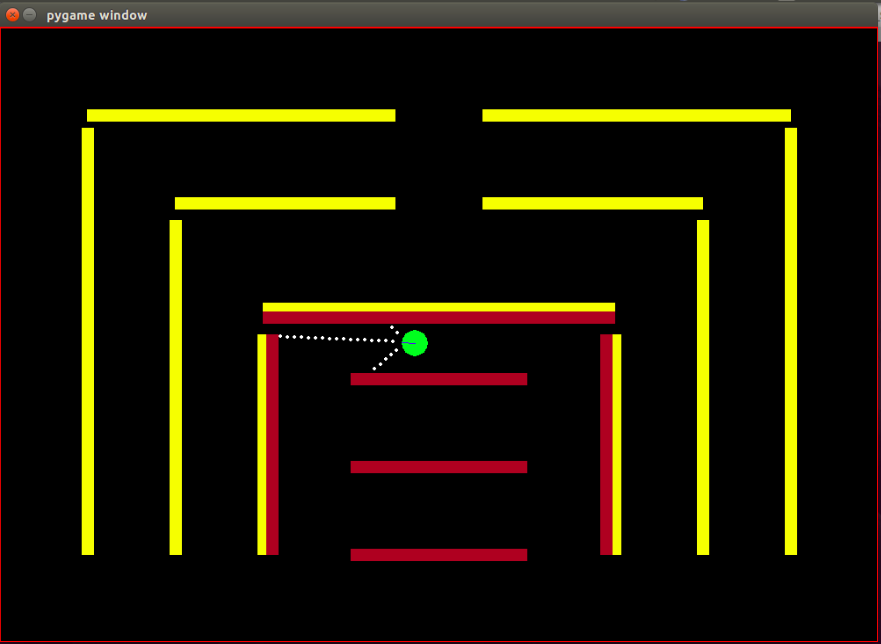
Agent: Der Agent ist ein kleiner grüner Kreis, dessen Fahrtrichtung durch eine blaue Linie angezeigt wird.
Sensoren: Der Agent ist mit 3 Abstands- und Farbsensoren ausgestattet. Dies sind die einzigen Informationen, die der Agent über die Umgebung hat.
Zustandsraum: Der Zustand des Agenten besteht aus 8 beobachtbaren Merkmalen:
Beachten Sie, dass die Normalisierung durchgeführt wird, um sicherzustellen, dass jeder beobachtbare Merkmalswert im Bereich [0,1] liegt, was eine notwendige Bedingung für die Belohnungen für die Konvergenz des IRL-Algorithmus ist.
Belohnungen: Die Belohnung nach jedem Frame wird als gewichtete lineare Kombination der im jeweiligen Frame beobachteten Merkmalswerte berechnet. Hier wird die Belohnung r_t im t-ten Rahmen durch das Skalarprodukt des Gewichtsvektors w mit dem Vektor der Merkmalswerte im t-ten Rahmen, also dem Zustandsvektor phi_t, berechnet. So dass r_t = w^T x phi_t.
Verfügbare Aktionen: Mit jedem neuen Frame macht der Agent automatisch einen Vorwärtsschritt . Die verfügbaren Aktionen können entweder den Agenten nach links oder rechts drehen oder nichts tun , was einen einfachen Vorwärtsschritt darstellt. Beachten Sie, dass die Drehaktionen auch die Vorwärtsbewegung umfassen ist keine In-Place-Rotation.
Hindernisse: Die Umgebung besteht aus starren Wänden, die bewusst in verschiedenen Farben gehalten sind. Der Agent verfügt über Farberkennungsfunktionen, die ihm helfen, zwischen den Hindernistypen zu unterscheiden. Die Umgebung ist auf diese Weise zum einfachen Testen des IRL-Algorithmus konzipiert.
Die Startposition (der Startstatus) des Bots ist festgelegt, da es gemäß dem IRL-Algorithmus erforderlich ist, dass der Startstatus für alle Iterationen derselbe ist.
Beachten Sie, dass der RL-Algorithmus mit geringfügigen Änderungen vollständig aus diesem Beitrag von Matt Harvey übernommen wurde. Daher ist es absolut sinnvoll, über die von mir vorgenommenen Änderungen zu sprechen. Auch wenn der Leser mit RL vertraut ist, empfehle ich dringend, einen Blick darauf zu werfen Lesen Sie diesen Beitrag, um zu verstehen, wie das verstärkende Lernen stattfindet.
Die Umgebung wird erheblich verändert, da der Agent nicht nur die Entfernung von den drei Sensoren, sondern auch die Farbe der Hindernisse erkennen kann, wodurch er zwischen den Hindernissen unterscheiden kann. Außerdem ist der Agent jetzt kleiner und seine Sensorpunkte sind jetzt näher beieinander, um eine höhere Auflösung und eine bessere Leistung zu erzielen. Um den Prozess des Testens des IRL-Algorithmus zu vereinfachen, mussten die Hindernisse vorerst statisch gemacht werden. Dies kann durchaus zu einer Überanpassung der Daten führen, aber darüber mache ich mir im Moment keine Sorgen. Wie oben erläutert, wurde der Beobachtungssatz bzw. der Status des Agenten von 3 auf 8 erhöht, wobei die Absturzfunktion in den Status des Agenten einbezogen wurde. Die Belohnungsstruktur wurde komplett geändert, die Belohnung ist nun eine gewichtete lineare Kombination dieser 8 Merkmale, der Agent erhält keine -500-Belohnung mehr für das Anstoßen gegen Hindernisse, sondern der Merkmalswert für das Anstoßen beträgt +1 und für das Nicht-Anstoßen ist er 0 und Es obliegt dem Algorithmus, auf Grundlage des Expertenverhaltens zu entscheiden, welche Gewichtung dieser Funktion zugewiesen werden soll.
Wie in Matts Blog dargelegt, besteht das Ziel hier nicht nur darin, dem RL-Agenten beizubringen, Hindernissen auszuweichen, sondern ich meine, warum man irgendetwas über die Belohnungsstruktur annehmen sollte, die Belohnungsstruktur vollständig durch den Algorithmus aus den Expertendemonstrationen bestimmen zu lassen und zu sehen, welches Verhalten eine bestimmte Einstellung von Belohnungen erreicht!
Die Merkmale oder Basisfunktionen phi_i, die grundsätzlich Observable im Staat sind. Die Merkmale des aktuellen Problems werden oben im Abschnitt zum Zustandsraum besprochen. Wir definieren phi(s_t) als die Summe aller Merkmalserwartungen phi_i, sodass:
Belohnungen r_t – lineare Kombination dieser Merkmalswerte, die in jedem Zustand s_t beobachtet werden.
Merkmalserwartungen mu(pi) einer Richtlinie pi ist die Summe der abgezinsten Merkmalswerte phi(s_t).
Die Merkmalserwartungen einer Richtlinie sind unabhängig von den Gewichten, sie hängen nur von den während des Laufs besuchten Staaten (gemäß der Richtlinie) und vom Diskontfaktor Gamma ab, einer Zahl zwischen 0 und 1 (z. B. 0,9 in unserem Fall). Um die Funktionserwartungen einer Richtlinie zu erhalten, müssen wir die Richtlinie in Echtzeit mit dem Agenten ausführen und die besuchten Zustände und die erhaltenen Merkmalswerte aufzeichnen.
Die Merkmalserwartungen der Expertenpolitik oder die Merkmalserwartungen des Experten mu(pi_E) werden durch die Maßnahmen ermittelt, die entsprechend dem Verhalten des Experten ergriffen werden. Grundsätzlich führen wir diese Richtlinie aus und erhalten die Funktionserwartungen wie bei jeder anderen Richtlinie. Die Expertenmerkmalserwartungen werden an den IRL-Algorithmus übergeben, um die Gewichte so zu finden, dass die Belohnungsfunktion, die den Gewichten entspricht, der zugrunde liegenden Belohnungsfunktion ähnelt, die der Experte zu maximieren versucht (in der üblichen RL-Sprache).
Zufällige Richtlinien-Feature-Erwartungen – Führen Sie eine zufällige Richtlinie aus und verwenden Sie die erhaltenen Feature-Erwartungen, um IRL zu initialisieren.
Führen Sie eine Liste der Richtlinienfunktionserwartungen, die wir nach jeder Iteration erhalten.
Ganz am Anfang haben wir nur pi^1 -> die zufälligen Richtlinienmerkmalserwartungen.
Finden Sie den ersten Satz von Gewichten von w^1 durch konvexe Optimierung. Das Problem ähnelt einem SVM-Klassifikator, der versucht, dem Expertenmerkmal expec eine +1-Beschriftung zu geben. und -1-Label für alle anderen Richtlinienfunktionserwartungen.-
so dass,
Kündigungsbedingung:
Sobald wir nun die Gewichtungen nach einer Optimierungsiteration erhalten, d. h. sobald wir eine neue Belohnungsfunktion erhalten, müssen wir die Richtlinie lernen, zu der diese Belohnungsfunktion führt. Dies ist dasselbe, als würde man sagen: Finden Sie eine Richtlinie, die versucht, diese erhaltene Belohnungsfunktion zu maximieren. Um diese neue Richtlinie zu finden, müssen wir den Reinforcement-Learning-Algorithmus mit dieser neuen Belohnungsfunktion trainieren und ihn trainieren, bis die Q-Werte konvergieren, um eine ordnungsgemäße Schätzung der Richtlinie zu erhalten.
Nachdem wir eine neue Richtlinie kennengelernt haben, müssen wir diese Richtlinie online testen, um die Funktionserwartungen zu erhalten, die dieser neuen Richtlinie entsprechen. Dann fügen wir diese neuen Funktionserwartungen zu unserer Liste der Funktionserwartungen hinzu und fahren mit der nächsten Iteration des IRL-Algorithmus fort, bis die Konvergenz erreicht ist.
Versuchen wir nun, den Code in den Griff zu bekommen. Den vollständigen Code finden Sie in diesem Git-Repo. Es gibt hauptsächlich drei Dateien, um die Sie sich kümmern müssen:
manualControl.py – um die Funktionserwartungen des Experten zu ermitteln, indem der Agent manuell verschoben wird. Führen Sie „python3 manualControl.py“ aus, warten Sie, bis die GUI geladen ist, und bewegen Sie sich dann mit den Pfeiltasten. Geben Sie ihm das Verhalten, das es kopieren soll (Beachten Sie, dass das Verhalten, das es kopieren soll, mit dem gegebenen Zustandsraum angemessen sein sollte). Ein guter Trick wäre, sich selbst in die Rolle des Agenten zu versetzen und zu überlegen, ob man das gegebene Verhalten nur angesichts des aktuellen Zustandsraums unterscheiden kann. Weitere Einzelheiten finden Sie in der Quelldatei.
toy_car_IRL.py – die Hauptdatei, hier liegt der IRL-Code. Schauen wir uns den Code Schritt für Schritt an.
{% gist 51542f27e97eac1559a00f06b757df1a %}
Importieren Sie Abhängigkeiten und definieren Sie die wichtigen Parameter, ändern Sie das VERHALTEN nach Bedarf. FRAMES ist die Anzahl der Frames, die der RL-Algorithmus ausführen soll. 100.000 sind in Ordnung und dauern etwa 2 Stunden.
{% gist 49b602b9a3090773d492310175bb2e3f %}
Erstellen Sie die benutzerfreundliche Klasse irlAgent, die das Zufalls- und Expertenverhalten sowie die anderen wichtigen Parameter wie gezeigt berücksichtigt.
{% gist bc17c06a07ea3b915827e89f3c13a2ae %}
Die Funktion getRLAgentFE verwendet den IRL_helper des Reinforcement-Learners, um ein neues Modell zu trainieren und Funktionserwartungen abzurufen, indem sie dieses Modell 2000 Iterationen lang abspielt. Grundsätzlich werden die Funktionserwartungen für jeden Satz von Gewichten (W) zurückgegeben, den es erhält.
{% gist ce0ef99adc652c7469f1bc4303a3af41 %}
Um das Wörterbuch zu aktualisieren, in dem wir unsere erhaltenen Richtlinien und ihre jeweiligen t-Werte speichern. Wobei t = (weights.tanspose)x(expert-newPolicy).
{% gist be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
Die Implementierung des Haupt-IRL-Algorithmus, der oben besprochen wurde. {% gist 9faee18596467ee33ac5d91fd0cb675f %}
Bei der konvexen Optimierung zur Aktualisierung der Gewichtungen beim Empfang einer neuen Richtlinie wird grundsätzlich die Bezeichnung +1 der Expertenrichtlinie und die Bezeichnung -1 allen anderen Richtlinien zugewiesen und für die Gewichtungen unter den genannten Einschränkungen optimiert. Um mehr über diese Optimierung zu erfahren, besuchen Sie die Website
{% gist 30cf6c59b9915054f3cf6d278f8f8a11 %}
Erstellen Sie einen irlAgent und übergeben Sie die gewünschten Parameter, wählen Sie zwischen der Art des Expertenverhaltens aus, für das Sie die Gewichtungen lernen möchten, und führen Sie dann die Funktion optimalWeightFinder() aus. Beachten Sie, dass ich die Funktionserwartungen für die Verhaltensweisen Rot, Gelb und Braun bereits erhalten habe. Nachdem der Algorithmus beendet ist, erhalten Sie eine Liste der Gewichte in „weights-red/yellow/brown.txt“ mit dem jeweils ausgewählten VERHALTEN. Um nun aus allen erhaltenen Gewichtungen das bestmögliche Verhalten auszuwählen, spielen Sie die gespeicherten Modelle im Verzeichnis „saved-models_BEHAVIOR/evaluatedPolicies/“ ab. Die Modelle werden im folgenden Format gespeichert : „saved-models_“+ BEHAVIOR +“/evaluatedPolicies/“+ Iterationsnummer+ '-164-150-100-50000-100000' + '.h5' . Grundsätzlich erhalten Sie unterschiedliche Gewichtungen für unterschiedliche Iterationen. Spielen Sie zunächst die Modelle, um herauszufinden, welches Modell die beste Leistung erbringt, und notieren Sie sich dann die Iterationsnummer dieses Modells. Die erhaltenen Gewichte, die dieser Iterationsnummer entsprechen, sind die Gewichte, die Sie dem Experten am nächsten bringen Verhalten.
Und dann gibt es Dateien, die Sie wahrscheinlich nicht aktualisieren/ändern müssen, zumindest nicht für den Inhalt dieses Beitrags –
Nach etwa 10–15 Iterationen konvergiert der Algorithmus bei allen vier verschiedenen ausgewählten Verhaltensweisen. Ich habe die folgenden Ergebnisse erhalten:
| Gewichte | Ich liebe Gelb | Ich liebe Braun | Ich liebe Rot | Ich liebe Bumping |
|---|---|---|---|---|
| w1 (Linker Sensorabstand) | -0,0880 | -0,2627 | 0,2816 | -0,5892 |
| w2 (mittlerer Sensorabstand) | -0,0624 | 0,0363 | -0,5547 | -0,3672 |
| w3 (rechte Sensordistanz) | 0,0914 | 0,0931 | -0,2297 | -0,4660 |
| w4 (schwarze Farbe) | -0,0114 | 0,0046 | 0,6824 | -0,0299 |
| w5 (gelbe Farbe) | 0,6690 | -0,1829 | -0,3025 | -0,1528 |
| w6 (braune Farbe) | -0,0771 | 0,6987 | 0,0004 | -0,0368 |
| w7 (rote Farbe) | -0,6650 | -0,5922 | 0,0525 | -0,5239 |
| w8 (Absturz) | -0,2897 | -0,2201 | -0,0075 | 0,0256 |
In den ersten drei Verhaltensweisen wird der Gewichtung, die zur Stoßfunktion gehört, ein hoher negativer Wert zugewiesen, da diese drei Expertenverhaltensweisen nicht möchten, dass der Agent gegen Hindernisse stößt. Während das Gewicht für das gleiche Merkmal im letzten Verhalten, nämlich dem Nasty-Bot, positiv ist, da das Expertenverhalten Bumping befürwortet.
Anscheinend richten sich die Gewichtungen der Farbmerkmale nach dem Verhalten des Experten: hoch, wenn diese Farbe gewünscht ist, andernfalls eher niedrig/negativ, um ein eindeutiges Verhalten zu erzielen.
Die Gewichtungen der Distanzmerkmale sind sehr mehrdeutig (kontraintuitiv) und es ist sehr schwierig, ein sinnvolles Muster in den Gewichten herauszufinden. Ich möchte nur darauf hinweisen, dass es in der aktuellen Einstellung sogar möglich ist, Verhaltensweisen im Uhrzeigersinn und gegen den Uhrzeigersinn zu unterscheiden. Die Entfernungsfunktionen enthalten diese Informationen.
Beachten Sie, dass es sehr wichtig ist, zunächst darüber nachzudenken, ob Sie als Mensch beim Entwerfen der Problemstruktur zwischen den gegebenen Verhaltensweisen und der Verfügbarkeit des aktuellen Zustandssatzes (der Beobachtungen) unterscheiden können. Andernfalls zwingen Sie den Algorithmus möglicherweise nur dazu, unterschiedliche Gewichtungen zu finden, ohne ihm die erforderlichen Informationen vollständig bereitzustellen.
Wenn Sie wirklich in IRL einsteigen möchten, würde ich empfehlen, dass Sie tatsächlich versuchen, dem Agenten ein neues Verhalten beizubringen (dafür müssen Sie möglicherweise die Umgebung ändern, da die möglichen unterschiedlichen Verhaltensweisen für den aktuellen Statussatz bereits ausgenutzt wurden). zumindest meiner Meinung nach).
Installieren Sie die Abhängigkeiten von Pygame mit:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
Dann installieren Sie Pygame selbst:
pip3 install hg+http://bitbucket.org/pygame/pygame
Dies ist die von der Simulation verwendete Physik-Engine. Es wurde gerade eine ziemlich umfangreiche Neufassung (Version 5) durchlaufen, daher müssen Sie sich die ältere Version 4 schnappen. v4 ist für Python 2 geschrieben, daher sind ein paar zusätzliche Schritte erforderlich.
Gehen Sie zurück zu Ihrem Zuhause oder laden Sie es herunter und holen Sie sich Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
Packen Sie es aus:
tar zxvf pymunk-4.0.0.tar.gz
Update von Python 2 auf 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
Installieren Sie es:
cd .. python3 setup.py install
Gehen Sie nun zurück zu der Stelle, an der Sie reinforcement-learning-car geklont haben, und stellen Sie mit einem schnellen python3 learning.py sicher, dass alles funktioniert. Wenn Sie einen Bildschirm sehen, auf dem ein kleiner Punkt herumfliegt, können Sie loslegen!
Zuerst müssen Sie ein Modell trainieren. Dadurch werden Gewichte im Ordner saved-models gespeichert. Möglicherweise müssen Sie diesen Ordner erstellen, bevor Sie ausführen . Sie können das Modell trainieren, indem Sie Folgendes ausführen:
python3 learning.py
Das Trainieren eines Modells kann je nach Komplexität des Netzwerks und Größe Ihrer Stichprobe zwischen einer und 36 Stunden dauern. Allerdings werden alle 25.000 Frames Gewichte ausgegeben, sodass Sie in viel kürzerer Zeit mit dem nächsten Schritt fortfahren können.
Bearbeiten Sie die Datei playing.py , um den Pfadnamen für das Modell zu ändern, das Sie laden möchten. Tut mir leid, ich weiß, dass es ein Befehlszeilenargument sein sollte.
Beobachten Sie dann, wie das Auto selbst um die Hindernisse herumfährt!
python3 playing.py
Das ist alles.


