WeClone
1.0.0
Durch die Verwendung von WeChat-Chat-Aufzeichnungen zur Feinabstimmung eines großen Sprachmodells habe ich etwa 20.000 integrierte effektive Daten verwendet. Das Endergebnis kann nur als unbefriedigend bezeichnet werden, aber manchmal ist es wirklich lustig.
Wichtig
Derzeit verwendet das Projekt standardmäßig das Modell chatglm3-6b und die LoRA-Methode wird zur Feinabstimmung der SF-Stufe verwendet, die etwa 16 GB Videospeicher erfordert. Sie können auch andere von LLaMA Factory unterstützte Modelle und Methoden verwenden, die weniger Videospeicher belegen. Sie müssen die Systemaufforderungswörter der Vorlage und andere zugehörige Konfigurationen selbst ändern.
Geschätzter Videospeicherbedarf:
| Trainingsmethode | Genauigkeit | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| Vollständige Parameter | 16 | 160 GB | 320 GB | 600 GB | 1200 GB | 900 GB |
| Einige Parameter | 16 | 20 GB | 40 GB | 120 GB | 240 GB | 200 GB |
| LoRa | 16 | 16 GB | 32 GB | 80 GB | 160 GB | 120 GB |
| QLoRA | 8 | 10 GB | 16 GB | 40 GB | 80 GB | 80 GB |
| QLoRA | 4 | 6 GB | 12 GB | 24 GB | 48 GB | 32 GB |
| Erforderlich | Mindestens | empfehlen |
|---|---|---|
| Python | 3.8 | 3.10 |
| Fackel | 1.13.1 | 2.2.1 |
| Transformatoren | 4.37.2 | 4.38.1 |
| Datensätze | 2.14.3 | 2.17.1 |
| beschleunigen | 0,27,2 | 0,27,2 |
| peft | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| Optional | Mindestens | empfehlen |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| Deepspeed | 0,10,0 | 0,13,4 |
| Bits und Bytes | 0,39,0 | 0,41,3 |
| Flash-Atn | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtTrainings- und inferenzbezogene Konfigurationen sind in der Datei „settings.json“ zusammengefasst
Bitte verwenden Sie PyWxDump, um WeChat-Chat-Datensätze zu extrahieren. Klicken Sie nach dem Herunterladen der Software und dem Entschlüsseln der Datenbank auf „Chat-Backup“. Sie können mehrere Kontakte oder Gruppenchats exportieren. Legen Sie dann den exportierten wxdump_tmp/export csv Ordner im Verzeichnis ./data ab. Die Ordner mit den Chat-Aufzeichnungen der Personen werden in ./data/csv zusammengefasst. Die Beispieldaten befinden sich in data/example_chat.csv.
Standardmäßig entfernt das Projekt Mobiltelefonnummern, ID-Nummern, E-Mail-Adressen und Website-Adressen aus den Daten. Es bietet auch eine Datenbank mit verbotenen Wörtern, blockierte_Wörter, in der Sie Wörter und Sätze hinzufügen können, die gefiltert werden müssen (der gesamte Satz einschließlich der verbotenen Wörter wird standardmäßig entfernt). Führen Sie das Skript ./make_dataset/csv_to_json.py aus, um die Daten zu verarbeiten.
Wenn dieselbe Person mehrere Sätze hintereinander beantwortet, gibt es drei Möglichkeiten, damit umzugehen:
| dokumentieren | Verarbeitungsmethode |
|---|---|
| csv_to_json.py | Verbinden Sie mit Kommas |
| csv_to_json-einzelner Satz answer.py (veraltet) | Als endgültige Daten werden nur die längsten Antworten ausgewählt |
| csv_to_json-einzelner Satz, mehrere Runden.py | Wird im „Verlauf“ des Aufforderungsworts platziert |
Die erste Möglichkeit besteht darin, das ChatGLM3-Modell von Hugging Face herunterzuladen. Wenn beim Herunterladen des Hugging Face-Modells Probleme auftreten, können Sie die MoDELSCOPE-Community mit den folgenden Methoden verwenden. Für nachfolgendes Training und Inferenz müssen Sie zuerst export USE_MODELSCOPE_HUB=1 ausführen, um das Modell der MoDELSCOPE-Community zu verwenden.
Aufgrund der Größe des Modells wird der Downloadvorgang lange dauern. Bitte haben Sie etwas Geduld.
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(Optional) Ändern Sie „settings.json“, um andere lokal heruntergeladene Modelle auszuwählen.
Ändern Sie per_device_train_batch_size und gradient_accumulation_steps um die Videospeichernutzung anzupassen.
Sie können Parameter wie num_train_epochs , lora_rank , lora_dropout entsprechend der Menge und Qualität Ihres eigenen Datensatzes ändern.
Führen Sie src/train_sft.py aus, um die SFT-Stufe zu optimieren. Mein Verlust ist nur auf etwa 3,5 gesunken. Wenn er zu stark reduziert wird, kann es zu einer Überanpassung kommen.
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.pyNotiz
Sie können auch zuerst die PT-Stufe optimieren. Es scheint, dass der Verbesserungseffekt nicht offensichtlich ist. Das Lager stellt auch den Code für die Vorverarbeitung und das Training des PT-Stufendatensatzes bereit.
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.pyWichtig
Bei WeChat besteht die Gefahr einer Kontoschließung. Es wird empfohlen, ein kleines Konto zu verwenden und für die Nutzung eine Bankkarte zu binden.
python ./src/api_service.py # 先启动api服务
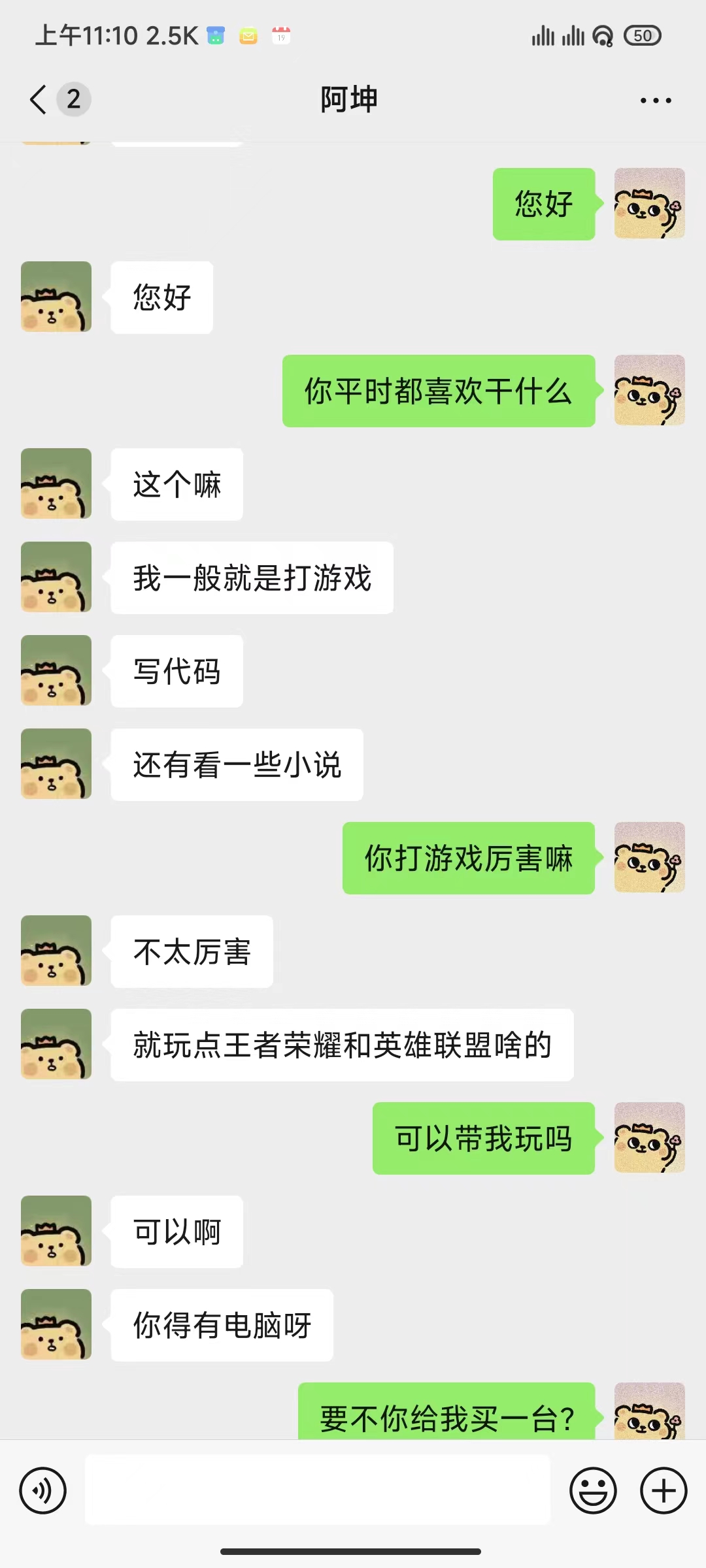
python ./src/wechat_bot/main.py Standardmäßig wird der QR-Code auf dem Terminal angezeigt. Scannen Sie einfach den Code, um sich anzumelden. Es kann im privaten Chat oder im Gruppenchat @bot verwendet werden.

Todo
Todo


