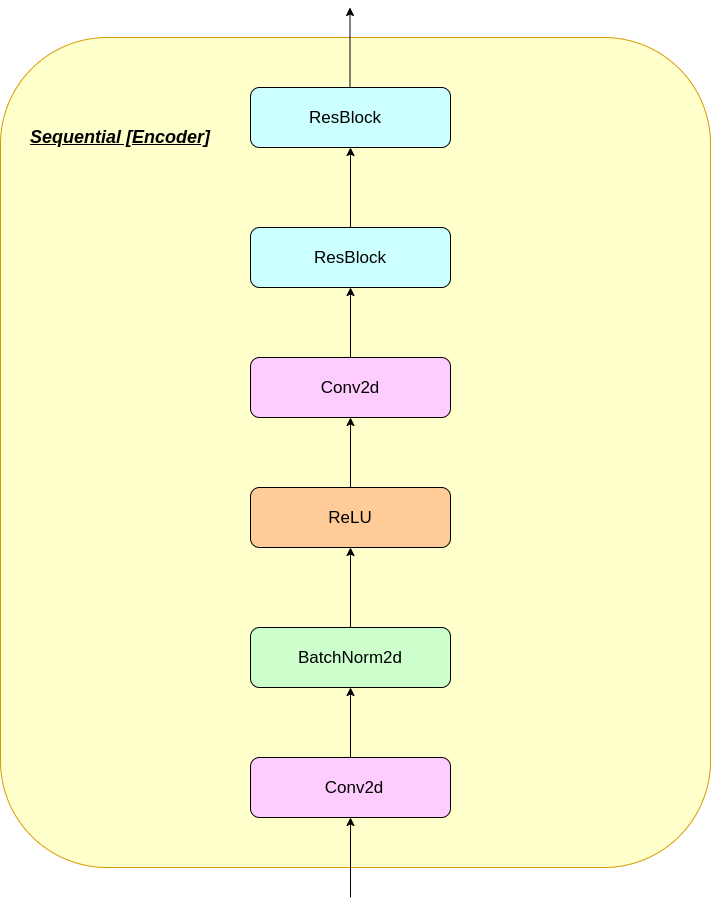
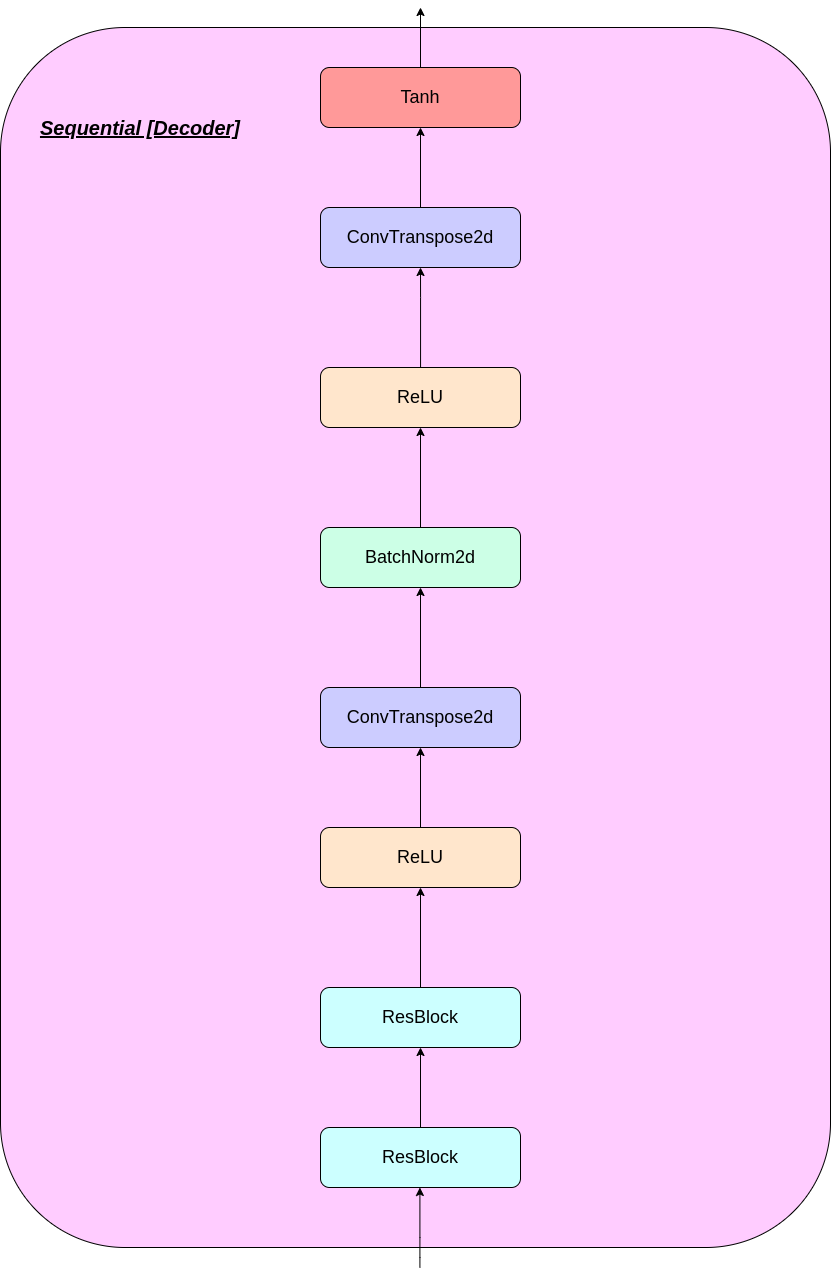
Das Repository besteht aus einem in Pytorch implementierten VQ-VAE, der auf dem MNIST-Datensatz trainiert wird.
VQ-vae folgt dem gleichen Grundkonzept wie hinter den Variationsautomatikern (VAE). VQ-vae verwenden diskrete latente Einbettungen für Variations-Auto-Encoder , dh jede Dimension von Z (latenter Vektor) ist eine diskrete Ganzzahl, anstatt der durchgehenden Normalverteilung, die im Allgemeinen bei der Codierung der Eingänge verwendet wird.
Vaes bestehen aus 3 Teilen:
Nun, Sie können nach den Unterschieden fragen, die VQ-Vaes auf den Tisch bringen. Lassen Sie uns sie auflisten:
Viele wichtige reale Objekte sind diskret. Zum Beispiel haben wir in Bildern Kategorien wie „Katze“, „Car“ usw. und es ist möglicherweise nicht sinnvoll, zwischen diesen Kategorien zu interpolieren. Diskrete Darstellungen sind auch einfacher zu modellieren.
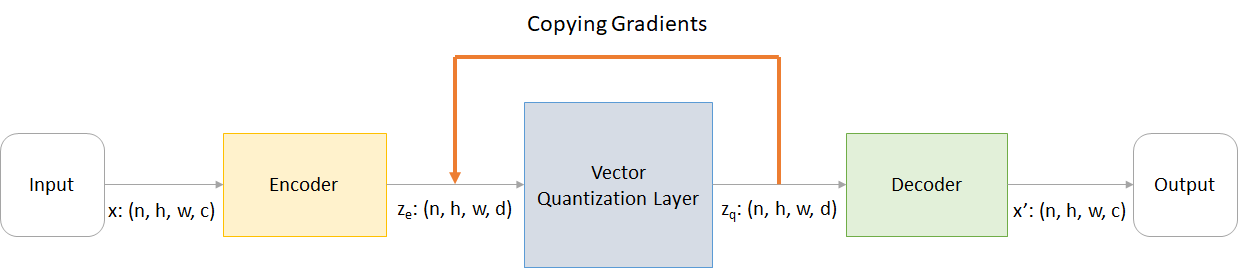
Wo:
n : Chargengrößeh : Bildhöhew : Bildbreitec : Anzahl der Kanäle im Eingabebildd : Anzahl der Kanäle im versteckten Zustand Hier ist ein kurzer Überblick über die Arbeit eines VQ-VAE-Netzwerks:
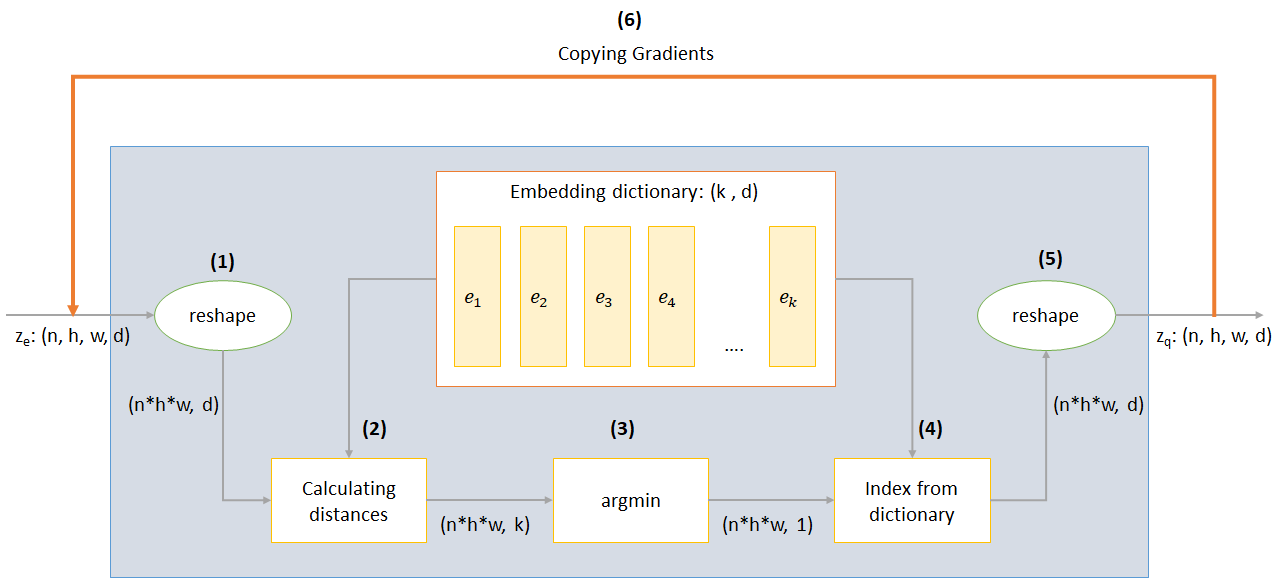
Die Funktionsweise der VQ -Schicht kann in sechs Schritten erklärt werden, wie in der Abbildung nummeriert:
VQ-vae verwendet 3 Verluste, um den Totalverlust während des Trainings zu berechnen:
Rekonstruktionsverlust: Optimiert Decoder und Encoder als VAE, dh der Unterschied zwischen dem Eingabebild und der Rekonstruktion:
reconstruction_loss = -log( p(x|z_q) )
Codebuchverlust: Aufgrund der Tatsache, dass Gradienten die Einbettung umgehen, wird ein Wörterbuch -Lernalgorithmus mit einem L2 -Fehler verwendet, um die Einbettungsvektoren E_I in Richtung Encoderausgabe zu verschieben.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG stellt den Stop -Gradientenoperator dar, was bedeutet, dass kein Gradienten durch alles, auf das er angewendet wird, fließt)
Verpflichtungsverlust: Da das Volumen des Einbettungsraums dimensionlos ist, kann er willkürlich wachsen, wenn die Einbettungen E_I nicht so schnell trainieren wie die Enderparameter, und somit wird ein Verpflichtungsverlust hinzugefügt, um sicherzustellen, dass sich der Enderbetten für eine Einbettung verpflichtet.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β ist ein Hyperparameter, der kontrolliert, wie viel wir im Vergleich zu anderen Komponenten den Verpflichtungsverlust abwägen wollen)
Sie können das Repo entweder herunterladen oder klonen, indem Sie Folgendes in der CMD -Eingabeaufforderung ausführen
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
Sie können das Modell mit dem folgenden Befehl (in Google Colab) von Grund auf neu trainieren (in Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - Name des Datenordnersdata-folder - Name des Datenordnersdevice - Setzen Sie das Gerät (CPU oder CUDA, Standard: CPU).hidden-size Größe der latenten Vektoren (Standard: 40)k - Anzahl der latenten Vektoren (Standard: 512)batch-size - Stapelgröße (Standard: 128)num-epochs - Anzahl der Epochen (Standard: 10)lr - Lernrate für Adam Optimizer (Standard: 2E -4)beta - Beitrag des Verpflichtungsverlusts zwischen 0,1 und 2,0 (Ausfall: 1,0)num-workers - Anzahl der Arbeiter für die Probenahme von Trajektorien (Standard: cpu_count () - 1) Das Programm lädt den MNIST -Datensatz automatisch herunter und speichert ihn im Ordner PATH_TO_MNIST_dataset (Sie müssen diesen Ordner erstellen). Dies geschieht nur einmal.
Es erstellt außerdem einen Ordner logs " und models , und in dieser erstellt sie einen Ordner mit dem von Ihnen übergebenen Namen, um Protokolle bzw. Modellkontrollpunkte darin zu speichern.
Um neue Bilder von Z zu generieren, die zufällig aus einer Gaußschen Einheit abgetastet wurden, führen Sie den folgenden Befehl aus (in Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - Dateiname mit dem Modell enthältinput - MNIST oder zufälligdevice - Setzen Sie das Gerät (CPU oder CUDA, Standard: CPU).hidden-size Größe der latenten Vektoren (Standard: 40)k - Anzahl der latenten Vektoren (Standard: 512)filename - Name, mit der Datei gespeichert werden soll Es erzeugt ein 10*10 -Gitter von Bildern, die in einem Ordner namens generatedImages gespeichert sind.
Sie können ein vorgebildetes Modell verwenden, indem Sie es aus dem Link in model.txt herunterladen.
Das Repository enthält die folgenden Dateien
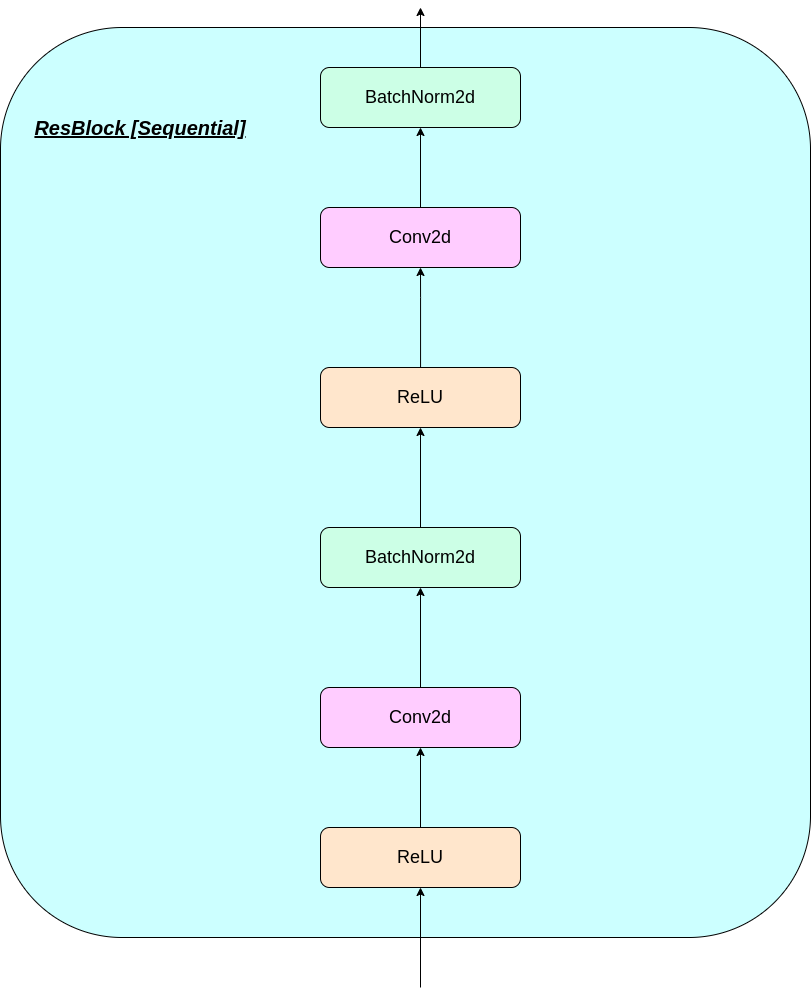
modules.py - Enthält die verschiedenen Module, die für die Herstellung unseres Modells verwendet werdenVQ-VAE.py -Enthält die Funktionen und den Code für die Schulung unseres VQ-VAE-Modellsvector_quantizer.py - Die Vektor -Quantisierungsklassen sind in dieser Datei definiertgenerate-py -generiert neue Bilder aus einem vorgebildeten Modellmodel.txt - enthält einen Link zu einem vorgebildeten ModellREADME.md - Readme gibt einen Überblick über das Reporeferences.txt - Referenzen beim Erstellen dieses Reporeadme_images - hat verschiedene Bilder für die ReadmeMNIST - Enthält den Reißverschluss -MNIST -Datensatz (obwohl er bei Bedarf automatisch heruntergeladen wird)Training track for VQ-VAE.txt -Enthält die Verlustwerte während des Trainings unseres VQ-VAE-Modellslogs_VQ-VAE -Enthält die Tensorboard-Protokolle für unser VQ-VAE-Modell (automatisch vom Programm erstellt)testers.py - Enthält einige Funktionen, um unsere definierten Module zu testenBefehl zum Ausführen von Tensorboard (in Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
Trainingsbild
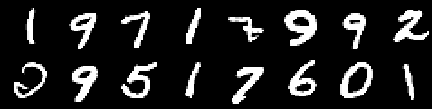
Bild aus der 0. Epoche

Bild aus der 2. Epoche
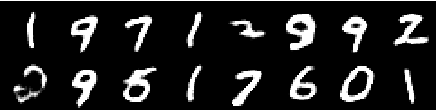
Bild aus der 4. Epoche
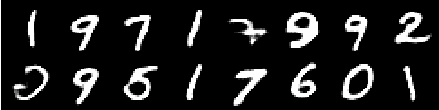
Bild aus der 6. Epoche
Bild aus der 8. Epoche
Bild aus der 10. Epoche
Die Rekonstruktionen verbessern sich immer wieder und ähneln am Ende fast den Training_Set-Bildern, die sich in den Verlustwerten widerspiegeln (Check-in- Training track for VQ-VAE.txt ).
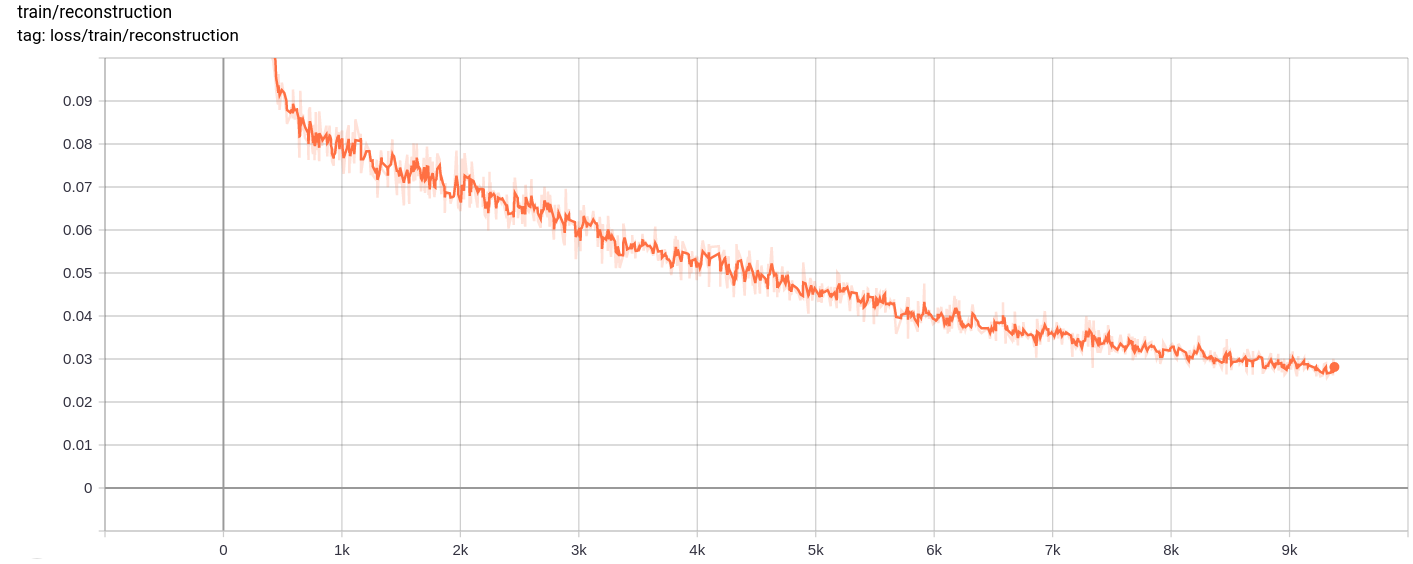
Wiederaufbauverlust
Quantisierungsverlust
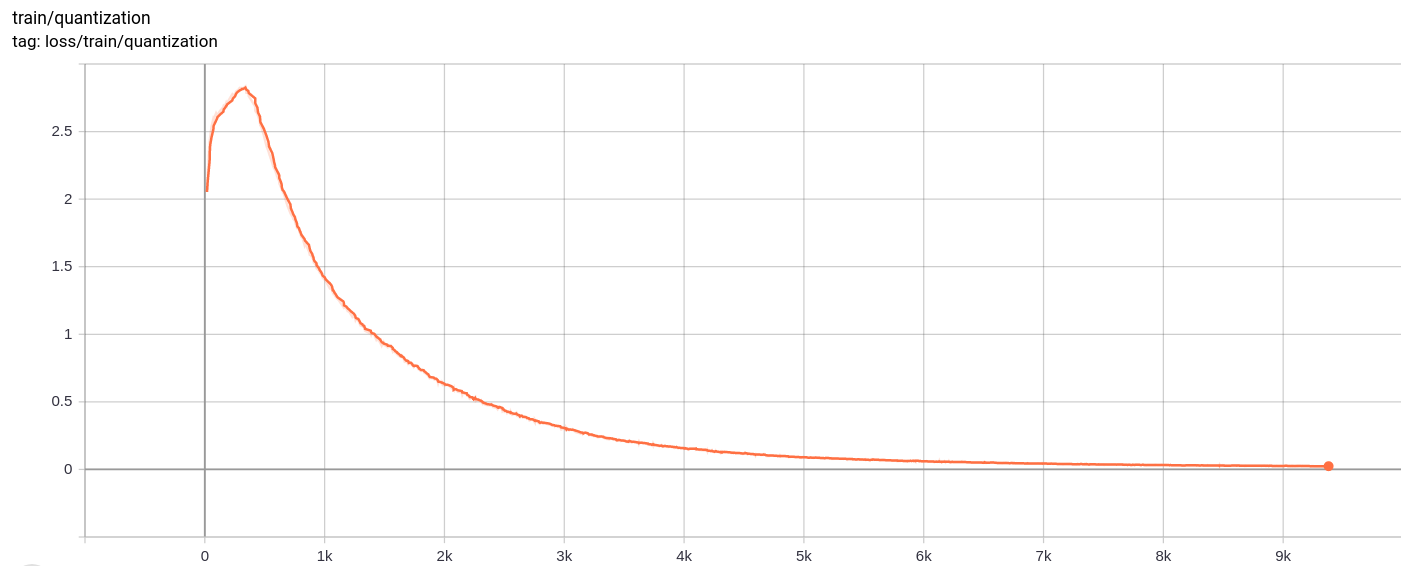
Total_loss
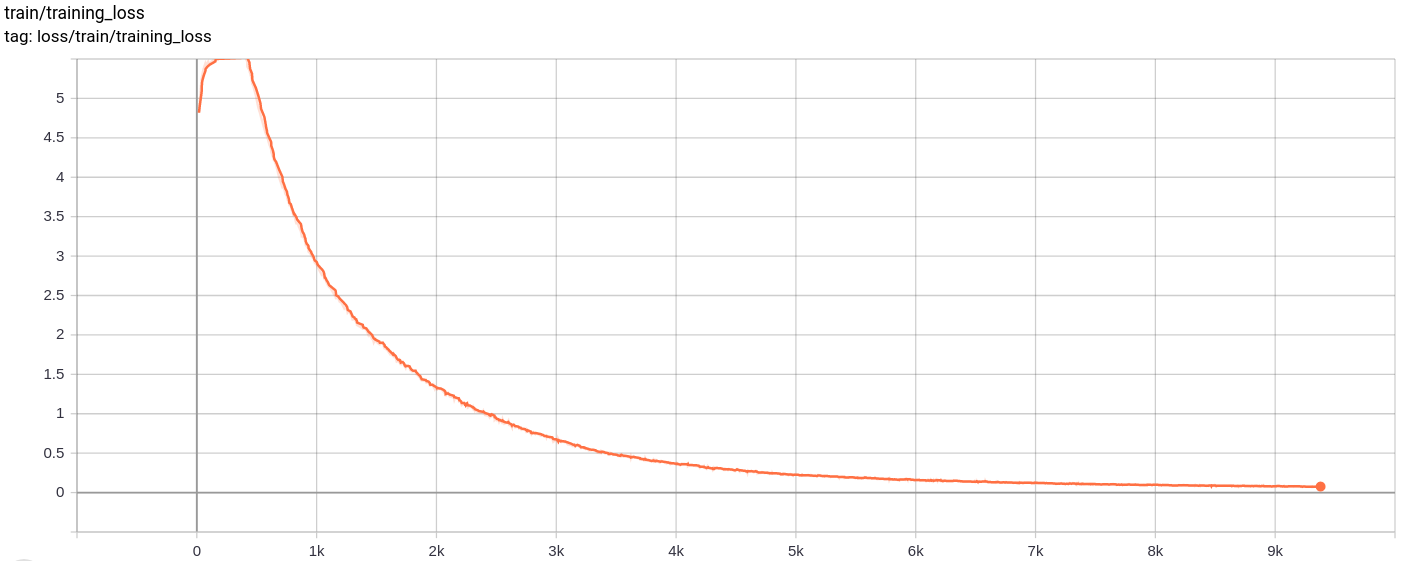
Der Gesamtverlust, der Rekonstruktionsverlust und der Quantisierungsverlust nehmen wie erwartet einheitlich ab.
Testing_loss
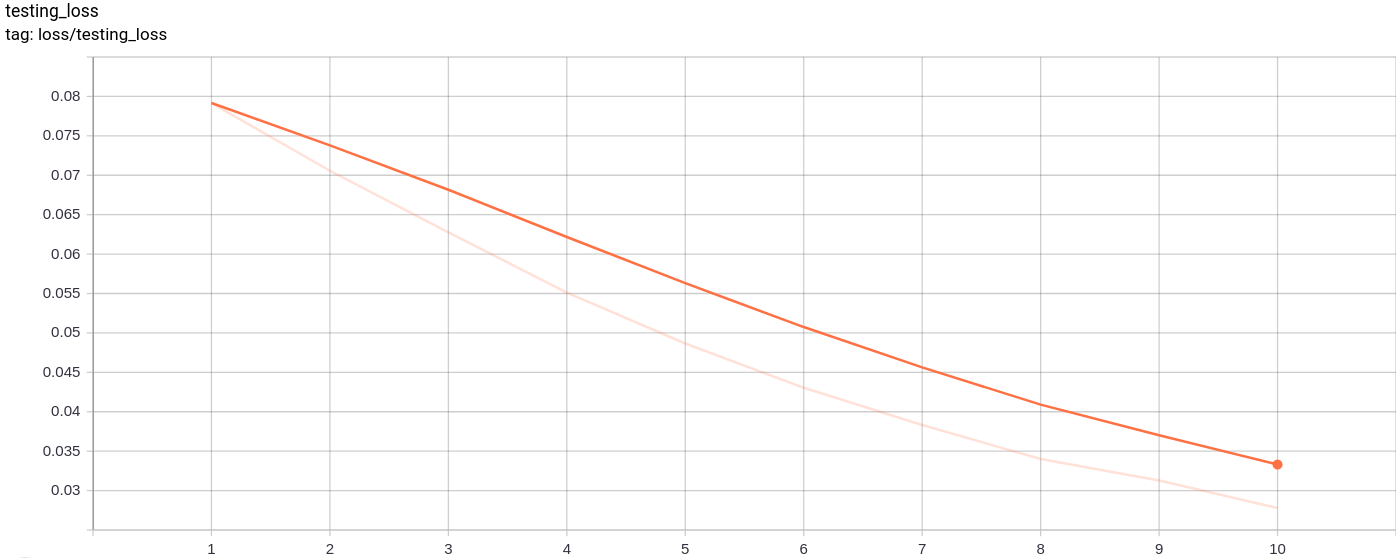
Der Testverlust nimmt wie erwartet einheitlich ab.
Das folgende Bildgitter wurde erzeugt, nachdem MNIST -Bilder als Eingänge bestanden wurden:

Die Generation ist ziemlich gut.
Die folgenden Bildgitter wurden erzeugt, nachdem AZ nach dem Zufallsprinzip von einem Gaußschen Einheit als Eingabe zum Modell bestanden und dann den Decoder durchlaufen und dann durch den Decoder geführt wurde


Die Bilder sehen nicht perfekt aus. Das Einbinden der Abmessungen des latenten Raums, die Anzahl der Einbettungsvektoren usw. kann dazu beitragen, bessere zufällige Bilder zu erzeugen.
Das Modell wurde auf Google Colab für 10 Epochen mit einer Chargengröße 128 trainiert.
Nach dem Training konnte das Modell die Eingangsbilder recht gut rekonstruieren und auch neue Bilder generieren, obwohl die generierten Bilder nicht so gut sind.
Das Training sowie der Testverlust nahmen ebenfalls fast monoton ab.
Ich beobachtete, dass das Training des Modells für mehr als 10-20 Epochen Ergebnisse erzielte, die auf ein wahrscheinliches Vorzeichen einer Überanpassung im Modell hinwiesen. Außerdem experimentierte ich mit verschiedenen Dimensionen des Latednt -Raums und in der Enddimension dimension = 40 lieferte die besten Ergebnisse. Der beste Bereich für die Dimension lag zwischen 16 und 42.
Die folgenden Quellen haben sehr geholfen, dieses Repository zu machen


