pandas ta
v0.3.14b
Pandas Technical Analysis ( Pandas TA ) ist eine einfach zu verwendende Bibliothek, die das Pandas -Paket mit mehr als 130 Indikatoren und Nutzfunktionen und mehr als 60 TA -Lib -Kerzenmustern nutzt. Viele häufig verwendete Indikatoren sind enthalten , wie z . ), Aroon & Aroon Oszillator ( Aroon ), Squeeze ( Squeeze ) und vieles mehr .
Hinweis: Ta lib muss installiert werden, um alle Candlestick -Muster zu verwenden. pip install TA-Lib . Wenn Ta lib nicht installiert ist, sind nur die gebauten Candlestick -Muster verfügbar.
talib=False deaktiviert werden.ta.stdev(df["close"], length=30, talib=False) ./pandas_ta/custom.py import_dirta.tsignals .lookahead=False um zu deaktivieren.Pandas TA überprüft, ob der Benutzer einige gemeinsame Handelspakete installiert hat, einschließlich, aber nicht beschränkt auf: Ta lib , Vector BT , YFInance ... von denen ein Großteil experimentell ist und wahrscheinlich brechen wird, bis es mehr stabilisiert.
help(ta.ticker) und help(ta.yf) und Beispiele unten. Die pip -Version ist die letzte stabile Version. Version: 0.3.14b
$ pip install pandas_taBeste Wahl! Version: 0.3.14b
$ pip install -U git+https://github.com/twopirllc/pandas-taDies ist die Entwicklungsversion , die Fehler und andere unerwünschte Nebenwirkungen haben könnte. Mit eigenem Risiko einsetzen!
$ pip install -U git+https://github.com/twopirllc/pandas-ta.git@development import pandas as pd
import pandas_ta as ta
df = pd . DataFrame () # Empty DataFrame
# Load data
df = pd . read_csv ( "path/to/symbol.csv" , sep = "," )
# OR if you have yfinance installed
df = df . ta . ticker ( "aapl" )
# VWAP requires the DataFrame index to be a DatetimeIndex.
# Replace "datetime" with the appropriate column from your DataFrame
df . set_index ( pd . DatetimeIndex ( df [ "datetime" ]), inplace = True )
# Calculate Returns and append to the df DataFrame
df . ta . log_return ( cumulative = True , append = True )
df . ta . percent_return ( cumulative = True , append = True )
# New Columns with results
df . columns
# Take a peek
df . tail ()
# vv Continue Post Processing vv Einige Indikatorargumente wurden für die Konsistenz neu angeordnet. Verwenden Sie help(ta.indicator_name) um weitere Informationen zu erhalten, oder stellen Sie eine Pull -Anfrage zur Verbesserung der Dokumentation durch.
import pandas as pd
import pandas_ta as ta
# Create a DataFrame so 'ta' can be used.
df = pd . DataFrame ()
# Help about this, 'ta', extension
help ( df . ta )
# List of all indicators
df . ta . indicators ()
# Help about an indicator such as bbands
help ( ta . bbands ) Danke, dass du Pandas TA verwendet hast!
$ pip install -U git+https://github.com/twopirllc/pandas-taVielen Dank für Ihre Beiträge!
Pandas TA verfügt über drei primäre "Stile" für technische Indikatoren für Ihren Anwendungsfall und/oder die Anforderungen. Sie sind: Standard , DataFrame -Erweiterung und die Pandas TA -Strategie . Jeweils mit zunehmendem Abstraktionsniveau für die Benutzerfreundlichkeit. Wenn Sie Pandas TA besser vertraut machen, kann die Einfachheit und Geschwindigkeit der Verwendung einer Pandas TA -Strategie deutlicher werden. Darüber hinaus können Sie Ihre eigenen Indikatoren durch Verkettung oder Zusammensetzung erstellen. Zuletzt gibt jeder Indikator entweder eine Serie oder einen Datenrahmen im Großbuchstaben unterstreicht, unabhängig vom Stil.
Sie definieren ausdrücklich die Eingangsspalten und kümmern sich um die Ausgabe.
sma10 = ta.sma(df["Close"], length=10)SMA_10 zurückdonchiandf = ta.donchian(df["HIGH"], df["low"], lower_length=10, upper_length=15)DC_10_15 und Spaltennamen zurück: DCL_10_15, DCM_10_15, DCU_10_15ema10_ohlc4 = ta.ema(ta.ohlc4(df["Open"], df["High"], df["Low"], df["Close"]), length=10)EMA_10 zurückgibt. Bei Bedarf müssen Sie es möglicherweise eindeutig benennen. Das Aufrufen df.ta wird automatisch unter OHLCVA in Kleinbuchstaben in OHLCVA : hoch, niedrig, dicht, Volumen , adj_close . Standardmäßig verwendet df.ta die OHLCVA für die Indikatorargumente, in denen die Notwendigkeit zur direkten Angabe von Eingabespalten entfernt werden muss.
sma10 = df.ta.sma(length=10)SMA_10 zurückema10_ohlc4 = df.ta.ema(close=df.ta.ohlc4(), length=10, suffix="OHLC4")EMA_10_OHLC4close=df.ta.ohlc4() .donchiandf = df.ta.donchian(lower_length=10, upper_length=15)DC_10_15 und Spaltennamen zurück: DCL_10_15, DCM_10_15, DCU_10_15 Gleich wie die letzten drei Beispiele, aber die Ergebnisse direkt an den DataFrame df anhängen.
df.ta.sma(length=10, append=True)df -Spaltennamen an: SMA_10 .df.ta.ema(close=df.ta.ohlc4(append=True), length=10, suffix="OHLC4", append=True)close=df.ta.ohlc4() .df.ta.donchian(lower_length=10, upper_length=15, append=True)df mit Spaltennamen an: DCL_10_15, DCM_10_15, DCU_10_15 . Eine Pandas TA -Strategie ist eine benannte Gruppe von Indikatoren, die von der Strategiemethode durchgeführt werden sollen. Alle Strategien verwenden Mulitprozessing, außer wenn der Parameter col_names verwendet wird (siehe unten). Im folgenden Abschnitt sind verschiedene Arten von Strategien aufgeführt.
# (1) Create the Strategy
MyStrategy = ta . Strategy (
name = "DCSMA10" ,
ta = [
{ "kind" : "ohlc4" },
{ "kind" : "sma" , "length" : 10 },
{ "kind" : "donchian" , "lower_length" : 10 , "upper_length" : 15 },
{ "kind" : "ema" , "close" : "OHLC4" , "length" : 10 , "suffix" : "OHLC4" },
]
)
# (2) Run the Strategy
df . ta . strategy ( MyStrategy , ** kwargs )Die Strategieklasse ist eine einfache Möglichkeit, Ihre bevorzugten TA -Indikatoren mit einer Datenklasse zu benennen und zu gruppieren. Pandas TA verfügt über zwei vorgefertigte grundlegende Strategien, mit denen Sie loslegen können: Allstrategy und Commonstraty . Eine Strategie kann so einfach sein wie das Comstrategy oder so komplex, wie es unter Verwendung von Zusammensetzung/Ketten erforderlich ist.
df angehängt.Beispiele für Beispiele wie Indikatorzusammensetzung/-ketten finden Sie im PANDAS TA -Beispiele -Notizbuch.
{"kind": "indicator name"} Attribut gibt. Denken Sie daran, Ihre Rechtschreibung zu überprüfen. # Running the Builtin CommonStrategy as mentioned above
df . ta . strategy ( ta . CommonStrategy )
# The Default Strategy is the ta.AllStrategy. The following are equivalent:
df . ta . strategy ()
df . ta . strategy ( "All" )
df . ta . strategy ( ta . AllStrategy ) # List of indicator categories
df . ta . categories
# Running a Categorical Strategy only requires the Category name
df . ta . strategy ( "Momentum" ) # Default values for all Momentum indicators
df . ta . strategy ( "overlap" , length = 42 ) # Override all Overlap 'length' attributes # Create your own Custom Strategy
CustomStrategy = ta . Strategy (
name = "Momo and Volatility" ,
description = "SMA 50,200, BBANDS, RSI, MACD and Volume SMA 20" ,
ta = [
{ "kind" : "sma" , "length" : 50 },
{ "kind" : "sma" , "length" : 200 },
{ "kind" : "bbands" , "length" : 20 },
{ "kind" : "rsi" },
{ "kind" : "macd" , "fast" : 8 , "slow" : 21 },
{ "kind" : "sma" , "close" : "volume" , "length" : 20 , "prefix" : "VOLUME" },
]
)
# To run your "Custom Strategy"
df . ta . strategy ( CustomStrategy ) Die PANDAS TA -Strategiemethode verwendet die Multiprozessierung für die Verarbeitung aller Strategie -Typen mit einer Ausnahme! Bei Verwendung des Parameters col_names , um die resultierenden Spalten (en) umzubenennen, werden die Anzeigen im ta -Array in der Reihenfolge ausgeführt.
# VWAP requires the DataFrame index to be a DatetimeIndex.
# * Replace "datetime" with the appropriate column from your DataFrame
df . set_index ( pd . DatetimeIndex ( df [ "datetime" ]), inplace = True )
# Runs and appends all indicators to the current DataFrame by default
# The resultant DataFrame will be large.
df . ta . strategy ()
# Or the string "all"
df . ta . strategy ( "all" )
# Or the ta.AllStrategy
df . ta . strategy ( ta . AllStrategy )
# Use verbose if you want to make sure it is running.
df . ta . strategy ( verbose = True )
# Use timed if you want to see how long it takes to run.
df . ta . strategy ( timed = True )
# Choose the number of cores to use. Default is all available cores.
# For no multiprocessing, set this value to 0.
df . ta . cores = 4
# Maybe you do not want certain indicators.
# Just exclude (a list of) them.
df . ta . strategy ( exclude = [ "bop" , "mom" , "percent_return" , "wcp" , "pvi" ], verbose = True )
# Perhaps you want to use different values for indicators.
# This will run ALL indicators that have fast or slow as parameters.
# Check your results and exclude as necessary.
df . ta . strategy ( fast = 10 , slow = 50 , verbose = True )
# Sanity check. Make sure all the columns are there
df . columns Denken Sie daran, dass diese nicht die Multiprozessierung verwenden werden
NonMPStrategy = ta . Strategy (
name = "EMAs, BBs, and MACD" ,
description = "Non Multiprocessing Strategy by rename Columns" ,
ta = [
{ "kind" : "ema" , "length" : 8 },
{ "kind" : "ema" , "length" : 21 },
{ "kind" : "bbands" , "length" : 20 , "col_names" : ( "BBL" , "BBM" , "BBU" )},
{ "kind" : "macd" , "fast" : 8 , "slow" : 21 , "col_names" : ( "MACD" , "MACD_H" , "MACD_S" )}
]
)
# Run it
df . ta . strategy ( NonMPStrategy ) # Set ta to default to an adjusted column, 'adj_close', overriding default 'close'.
df . ta . adjusted = "adj_close"
df . ta . sma ( length = 10 , append = True )
# To reset back to 'close', set adjusted back to None.
df . ta . adjusted = None # List of Pandas TA categories.
df . ta . categories # Set the number of cores to use for strategy multiprocessing
# Defaults to the number of cpus you have.
df . ta . cores = 4
# Set the number of cores to 0 for no multiprocessing.
df . ta . cores = 0
# Returns the number of cores you set or your default number of cpus.
df . ta . cores # The 'datetime_ordered' property returns True if the DataFrame
# index is of Pandas datetime64 and df.index[0] < df.index[-1].
# Otherwise it returns False.
df . ta . datetime_ordered # Sets the Exchange to use when calculating the last_run property. Default: "NYSE"
df . ta . exchange
# Set the Exchange to use.
# Available Exchanges: "ASX", "BMF", "DIFX", "FWB", "HKE", "JSE", "LSE", "NSE", "NYSE", "NZSX", "RTS", "SGX", "SSE", "TSE", "TSX"
df . ta . exchange = "LSE" # Returns the time Pandas TA was last run as a string.
df . ta . last_run # The 'reverse' is a helper property that returns the DataFrame
# in reverse order.
df . ta . reverse # Applying a prefix to the name of an indicator.
prehl2 = df . ta . hl2 ( prefix = "pre" )
print ( prehl2 . name ) # "pre_HL2"
# Applying a suffix to the name of an indicator.
endhl2 = df . ta . hl2 ( suffix = "post" )
print ( endhl2 . name ) # "HL2_post"
# Applying a prefix and suffix to the name of an indicator.
bothhl2 = df . ta . hl2 ( prefix = "pre" , suffix = "post" )
print ( bothhl2 . name ) # "pre_HL2_post" # Returns the time range of the DataFrame as a float.
# By default, it returns the time in "years"
df . ta . time_range
# Available time_ranges include: "years", "months", "weeks", "days", "hours", "minutes". "seconds"
df . ta . time_range = "days"
df . ta . time_range # prints DataFrame time in "days" as float # Sets the DataFrame index to UTC format.
df . ta . to_utc import numpy as np
# Add constant '1' to the DataFrame
df . ta . constants ( True , [ 1 ])
# Remove constant '1' to the DataFrame
df . ta . constants ( False , [ 1 ])
# Adding constants for charting
import numpy as np
chart_lines = np . append ( np . arange ( - 4 , 5 , 1 ), np . arange ( - 100 , 110 , 10 ))
df . ta . constants ( True , chart_lines )
# Removing some constants from the DataFrame
df . ta . constants ( False , np . array ([ - 60 , - 40 , 40 , 60 ])) # Prints the indicators and utility functions
df . ta . indicators ()
# Returns a list of indicators and utility functions
ind_list = df . ta . indicators ( as_list = True )
# Prints the indicators and utility functions that are not in the excluded list
df . ta . indicators ( exclude = [ "cg" , "pgo" , "ui" ])
# Returns a list of the indicators and utility functions that are not in the excluded list
smaller_list = df . ta . indicators ( exclude = [ "cg" , "pgo" , "ui" ], as_list = True ) # Download Chart history using yfinance. (pip install yfinance) https://github.com/ranaroussi/yfinance
# It uses the same keyword arguments as yfinance (excluding start and end)
df = df . ta . ticker ( "aapl" ) # Default ticker is "SPY"
# Period is used instead of start/end
# Valid periods: 1d,5d,1mo,3mo,6mo,1y,2y,5y,10y,ytd,max
# Default: "max"
df = df . ta . ticker ( "aapl" , period = "1y" ) # Gets this past year
# History by Interval by interval (including intraday if period < 60 days)
# Valid intervals: 1m,2m,5m,15m,30m,60m,90m,1h,1d,5d,1wk,1mo,3mo
# Default: "1d"
df = df . ta . ticker ( "aapl" , period = "1y" , interval = "1wk" ) # Gets this past year in weeks
df = df . ta . ticker ( "aapl" , period = "1mo" , interval = "1h" ) # Gets this past month in hours
# BUT WAIT!! THERE'S MORE!!
help ( ta . yf ) Muster, die nicht fett sind, erfordern die Installation von Ta-Lib: pip install TA-Lib
# Get all candle patterns (This is the default behaviour)
df = df . ta . cdl_pattern ( name = "all" )
# Get only one pattern
df = df . ta . cdl_pattern ( name = "doji" )
# Get some patterns
df = df . ta . cdl_pattern ( name = [ "doji" , "inside" ])ta.linreg(series, r=True)lazybear=Truedf.ta.strategy() .| Moving Average Convergenz Divergence (MACD) |
|---|
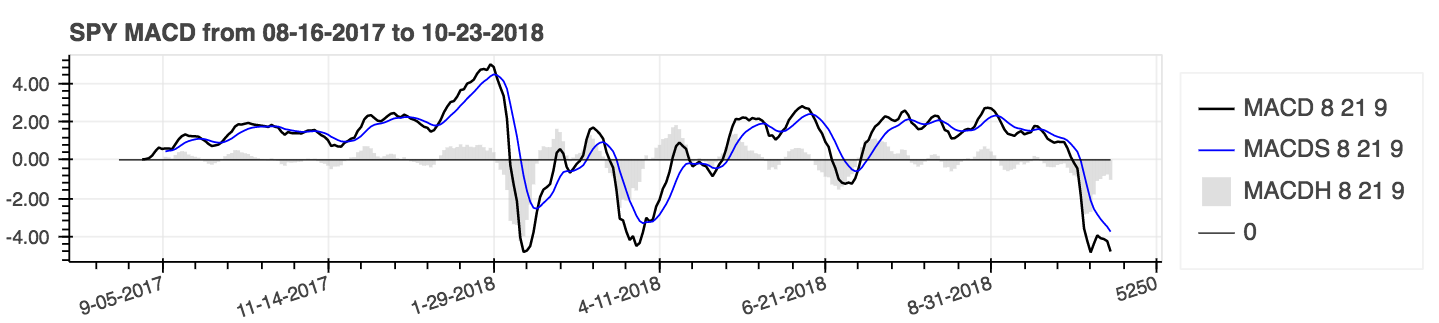 |
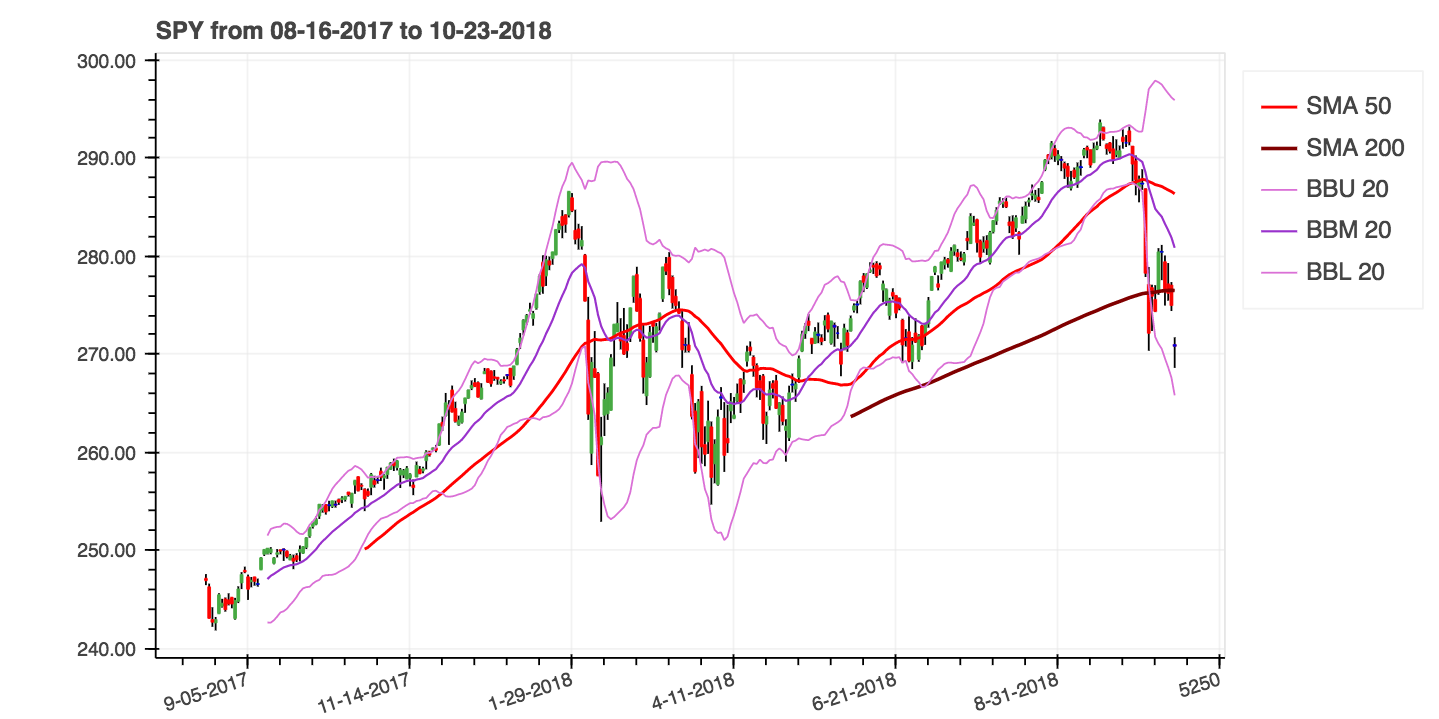
help(ta.ichimoku) .lookahead=False lässt die Spalte Chikou -Span, um potenzielles Datenleck zu verhindern.| Einfache bewegende Durchschnittswerte (SMA) und Bollinger -Bänder (Bbands) |
|---|
|
Verwenden Sie Parameter: kumulativ = true für kumulative Ergebnisse.
| Prozentuale Rendite (kumulativ) mit einfachem gleitenden Durchschnitt (SMA) |
|---|
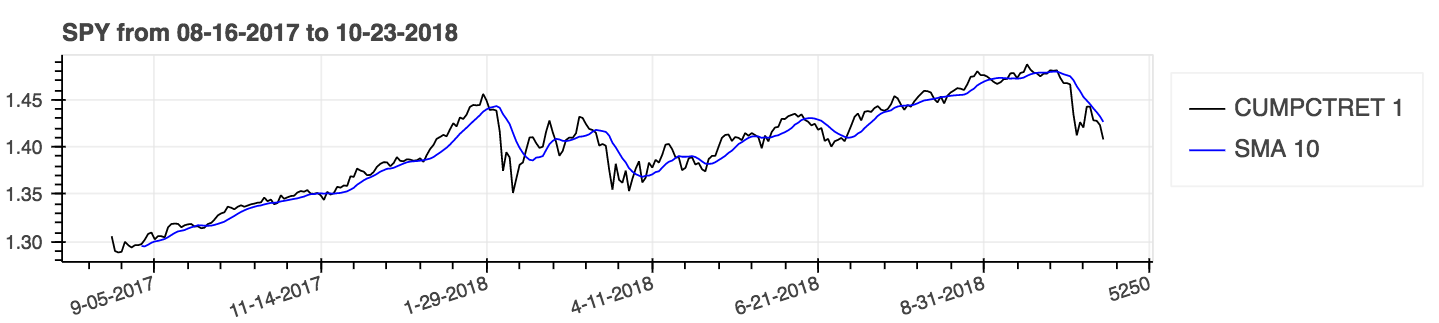 |
| Z Score |
|---|
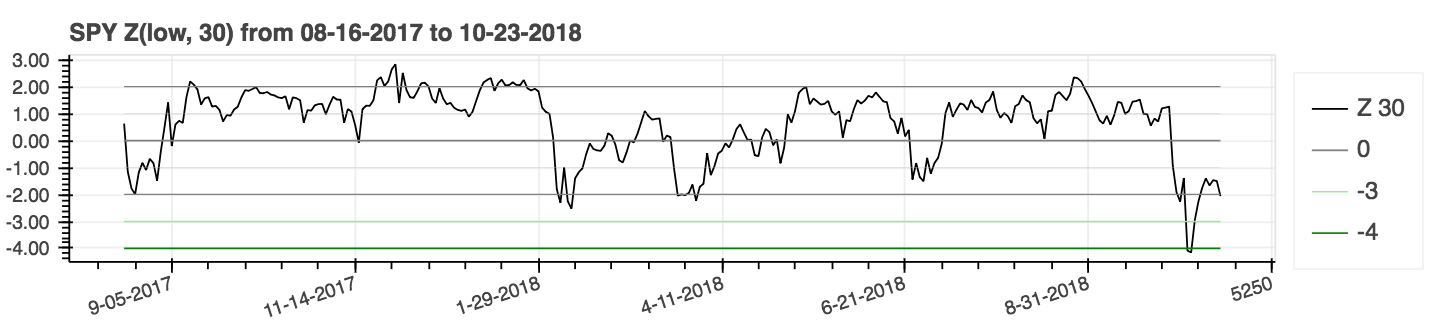 |
lookahead=False um das Zentrieren zu deaktivieren und potenzielle Datenlecks zu entfernen.| Durchschnittlicher Richtungsbewegungsindex (ADX) |
|---|
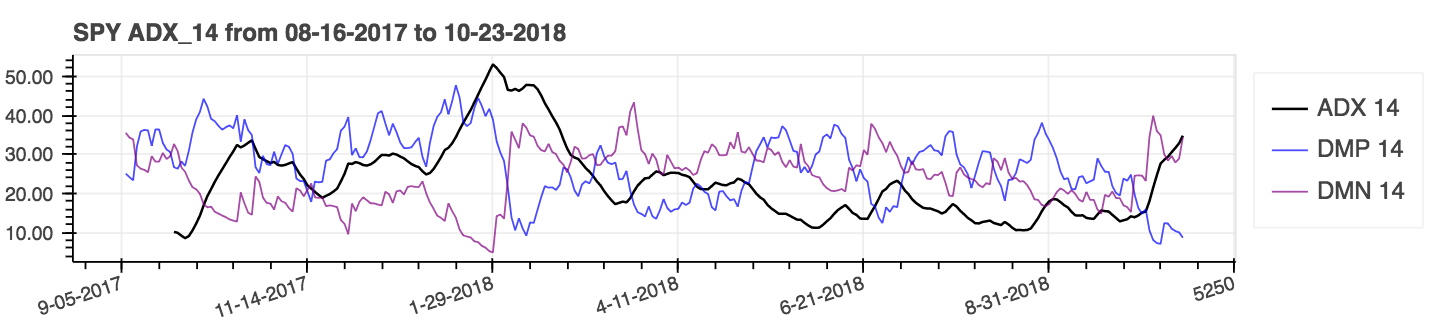 |
| Durchschnittlicher wahrer Bereich (ATR) |
|---|
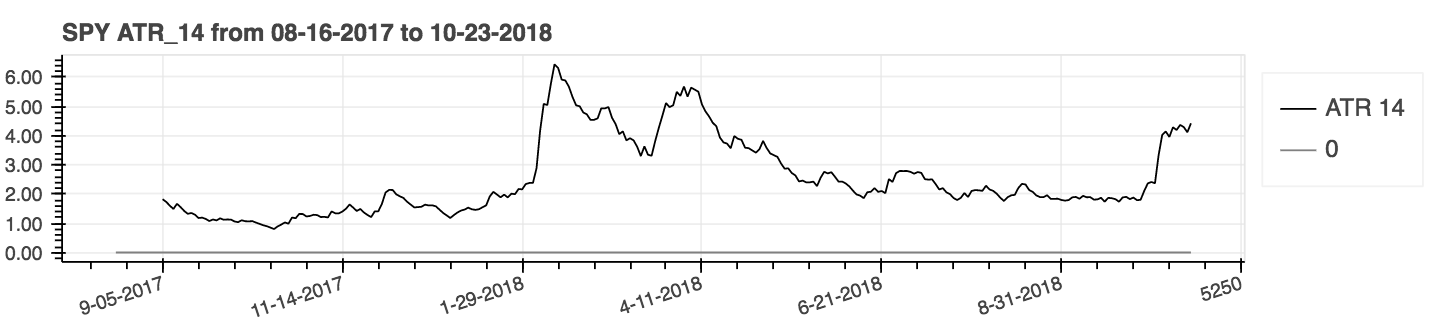 |
| Einbalancevolumen (obv) |
|---|
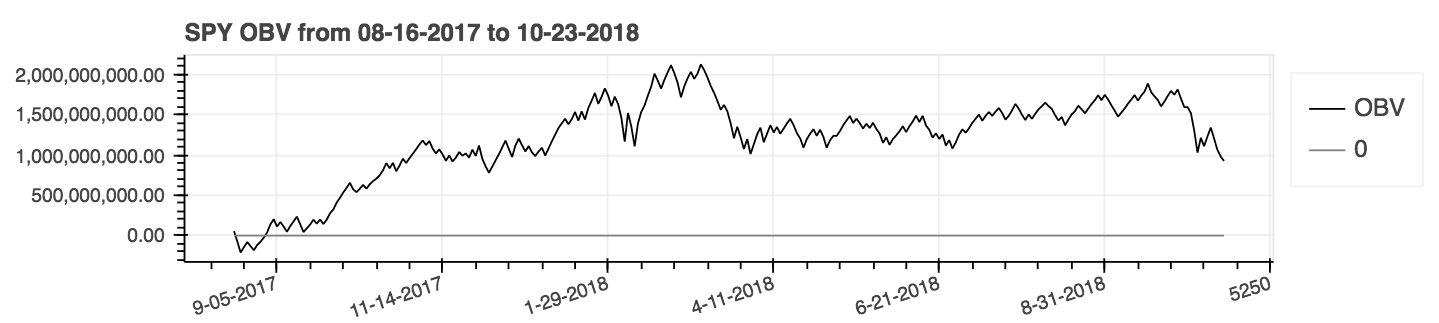 |
Leistungskennzahlen sind ein neuer Ergänzung des Pakets und folglich unzuverlässig. Verwenden Sie auf eigenes Risiko. Diese Metriken geben einen Float zurück und sind nicht Teil der DataFrame -Erweiterung. Sie werden als Standardweg bezeichnet. Zum Beispiel:
import pandas_ta as ta
result = ta . cagr ( df . close ) Für eine leichtere Integration mit VectorBTs Portfolio aus der Methode from_signals wurde die Methode ta.trend_return durch die Methode ta.tsignals ersetzt, um die Erzeugung von Handelssignalen zu vereinfachen. Ein umfassendes Beispiel finden Sie im Beispiel Jupyter Notebook Vectorbt Backtest mit Pandas TA im Beispielverzeichnis.
import pandas as pd
import pandas_ta as ta
import vectorbt as vbt
df = pd . DataFrame (). ta . ticker ( "AAPL" ) # requires 'yfinance' installed
# Create the "Golden Cross"
df [ "GC" ] = df . ta . sma ( 50 , append = True ) > df . ta . sma ( 200 , append = True )
# Create boolean Signals(TS_Entries, TS_Exits) for vectorbt
golden = df . ta . tsignals ( df . GC , asbool = True , append = True )
# Sanity Check (Ensure data exists)
print ( df )
# Create the Signals Portfolio
pf = vbt . Portfolio . from_signals ( df . close , entries = golden . TS_Entries , exits = golden . TS_Exits , freq = "D" , init_cash = 100_000 , fees = 0.0025 , slippage = 0.0025 )
# Print Portfolio Stats and Return Stats
print ( pf . stats ())
print ( pf . returns_stats ())mamode KWARG mit mehr gleitenden Durchschnittswahlen mit der gleitenden durchschnittlichen Versorgungsfunktion ta.ma() aktualisiert. Der Einfachheit halber sind alle Auswahlmöglichkeiten für ein einzelne Quelle bewegende Durchschnittswerte . Dies ist in erster Linie ein internes Dienstprogramm, das von Indikatoren mit einem mamode KWARG verwendet wird. Dies schließt Indikatoren ein: Accbands , AMAT , AOBV , ATR , Bbands , Bias , EFI , Hilo , KC , Natr , QQE , RVI und Thermo ; Die mamode -Parameter haben sich nicht geändert. ta.ma() kann jedoch bei Bedarf auch vom Benutzer verwendet werden. Weitere Informationen: help(ta.ma)to_utc , hinzugefügt, um den DataFrame -Index in UTC zu konvertieren. Siehe: help(ta.to_utc) jetzt als Pandas TA -Datenframe -Eigenschaft, um den DataFrame -Index einfach in UTC zu konvertieren. close > sma(close, 50) gibt es den Trend, Handelseinträge und Handelsausgänge dieses Trends zurück, um ihn mit VectorBT kompatibel zu machen, indem asbool=True festgelegt wird, um Boolesche Handelseinträge und -ausgänge zu erhalten. Siehe help(ta.tsignals) help(ta.alma) Handelskonto oder Fonds. Siehe help(ta.drawdown)help(ta.cdl_pattern)help(ta.cdl_z)help(ta.cti)help(ta.xsignals)help(ta.dm)help(ta.ebsw)help(ta.jma)help(ta.kvo)help(ta.stc)help(ta.squeeze_pro)df.ta.strategy() aus Leistungsgründen ausgelöst. Siehe help(ta.td_seq)help(ta.tos_stdevall)help(ta.vhf) mamode in mode umbenannt. Siehe help(ta.accbands) .mamode mit Standard " RMA " und mit den gleichen mamode -Optionen wie TradingView hinzugefügt. Neues Argument lensig verhält es sich wie das integrierte ADX -Indikator von TradingView. Siehe help(ta.adx) .drift -Argument und beschreibende Spaltennamen hinzugefügt.mamode ist jetzt " RMA " und mit den gleichen mamode -Optionen wie TradingView. Siehe help(ta.atr) .ddoff um die Freiheitsgrade zu kontrollieren. Auch BB Prozent (BBP) als letzte Spalte eingeschlossen. Standard ist 0. Siehe help(ta.bbands) .ln um natürlichen Logarithmus (True) anstelle des Standard -Logarithmus (False) zu verwenden. Standard ist falsch. Siehe help(ta.chop) .tvmode mit Standard True hinzugefügt. Wenn tvmode=False , implementiert CKSP den „neuen technischen Händler“ mit Standardwerten. Siehe help(ta.cksp) .talib wird die Version von Ta lib verwenden und wenn Ta lib installiert ist. Standard ist wahr. Siehe help(ta.cmo) .strict Überprüfungen, wenn die Serie mit einer schnelleren Berechnung über die length ständig abnimmt. Standard: False . Das percent Argument wurde ebenfalls mit Standard -None hinzugefügt. Siehe help(ta.decreasing) .strict Überprüfungen, wenn die Serie mit einer schnelleren Berechnung über die length steigt. Standard: False . Das percent Argument wurde ebenfalls mit Standard -None hinzugefügt. Siehe help(ta.increasing) .help(ta.kvo) .as_strided -Methode oder die neuere sliding_window_view -Methode verwendet werden soll. Dies sollte Probleme mit Google Colab beheben und es sind verzögerte Abhängigkeitsaktualisierungen sowie die Abhängigkeiten von TensorFlow, wie in den Themen Nr. 285 und Nr. 329 erläutert.asmode aktiviert als Version von MacD. Standard ist falsch. Siehe help(ta.macd) .sar von TradingView. Neues Argument af0 zur Initialisierung des Beschleunigungsfaktors. Siehe help(ta.psar) .mamode als Option. Standard ist SMA , um Ta lib zu entsprechen. Siehe help(ta.ppo) .signal mit Standard 13 und Signal MA -Modus mamode mit Standard -EMA als Argumente hinzugefügt. Siehe help(ta.tsi) .help(ta.vp) .help(ta.vwma) .anchor hinzugefügt. Standard: "D" für "Daily". Weitere Optionen finden Sie unter Timeries -Offset -Aliase. Erfordert, dass der DataFrame -Index ein DateTimeIndex ist. Siehe help(ta.vwap) .help(ta.vwma) .Z_length nach ZS_length geändert. Siehe help(ta.zscore) .Original Ta-Lib | TradingView | Sierra -Chart | MQL5 | FM Labs | Pro Real Code | Benutzer 42
Fühlen Sie sich großzügig, wie das Paket oder möchten Sie sehen, dass es eher zu einem ausgereiften Paket wird?


