GroundingDINO
Grounding DINO SwinB

Idea-CVR, Idea-Forschung
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang ? .
[ Paper ] [ Demo ] [ BibTex ]
Pytorch -Implementierung und vorgefertigte Modelle für das Erdungsdino. Weitere Informationen finden Sie im Papier Erdungsdino: Heiraten von Dino mit geerdetem Vorbild für Open-Set-Objekterkennung .
2023/07/18 : Wir geben Semantic-SAM, ein universelles Bildsegmentierungsmodell, veröffentlicht, um Segment zu ermöglichen und alles auf gewünschte Granularität zu erkennen. Code und Checkpoint sind verfügbar!2023/06/17 : Wir geben ein Beispiel zur Bewertung von Dino auf Coco Zero-Shot-Leistung.2023/04/15 : Siehe Lebenslauf in den wilden Lesungen für diejenigen, die sich für Open-Set-Anerkennung interessieren!2023/04/08 : Wir veröffentlichen Demos, um das Grounding Dino mit Gligen zu kombinieren, um kontrollierbare Bildbearbeitungen zu erhalten.2023/04/08 : Wir veröffentlichen Demos, um das Erdungsdino mit einer stabilen Diffusion für Bildbearbeitung zu kombinieren.2023/04/06 : Wir bauen eine neue Demo, indem wir Groundingdino mit Segment-Anything namens geerdet-segment-an -anwidrigen heiraten, um die Segmentierung in Grounddino zu unterstützen.2023/03/28 : Ein YouTube -Video über das Erden von Dino und eine einfache Objekterkennung Eingabeaufforderung. [Skalskip]2023/03/28 : Fügen Sie eine Demo zum Umarmungsraum hinzu!2023/03/27 : Unterstützen Sie den CPU-Only-Modus. Jetzt kann das Modell auf Maschinen ohne GPUs ausgeführt werden.2023/03/25 : Eine Demo für das Erdungsdino ist in Colab erhältlich. [Skalskip]2023/03/22 : Der Code ist ab sofort verfügbar! Heiraten des Erdungsdino und Gligens
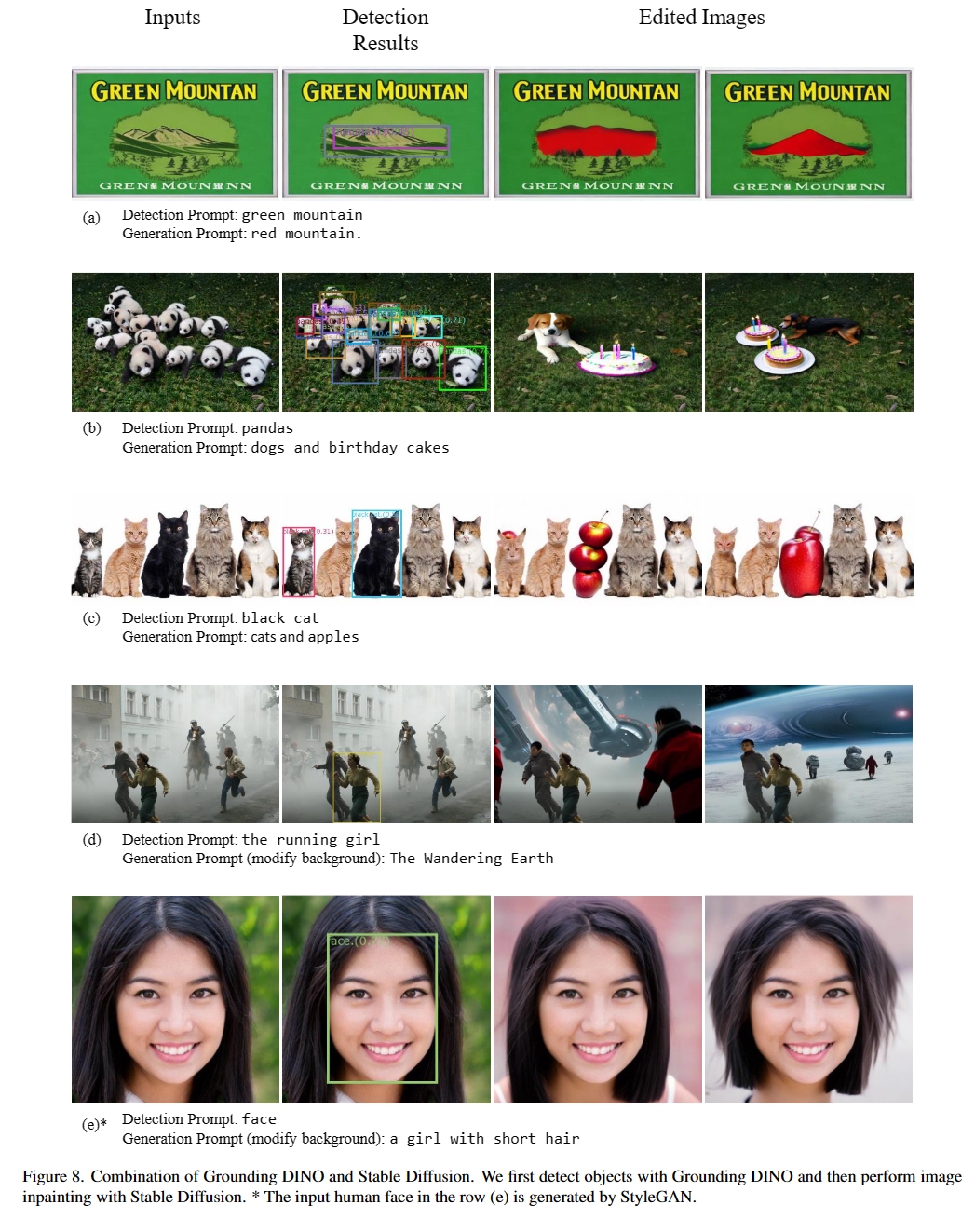
Heiraten des Erdungsdino und Gligens (image, text) Paar als Eingänge.900 (standardmäßig) Objektboxen aus. Jedes Box hat Ähnlichkeitswerte über alle Eingabeswörter. (Wie in Abbildungen unten gezeigt.)box_threshold .text_threshold , wie vorhergesagt.dogs im Satz two dogs with a stick. Sie können die Felder mit den höchsten Textähnlichkeiten mit dogs als endgültige Ausgaben auswählen.. zum Erdungsdino. 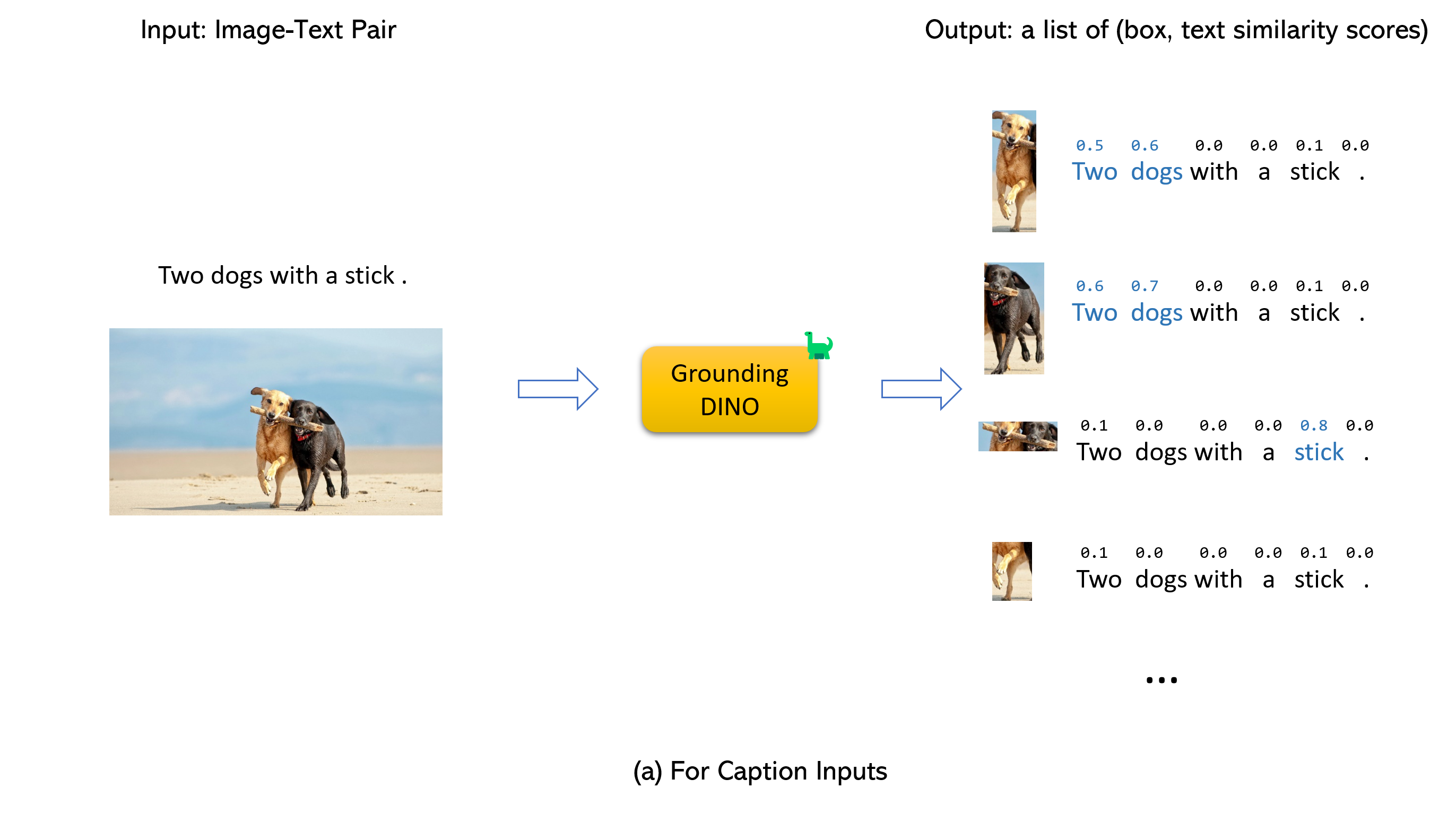
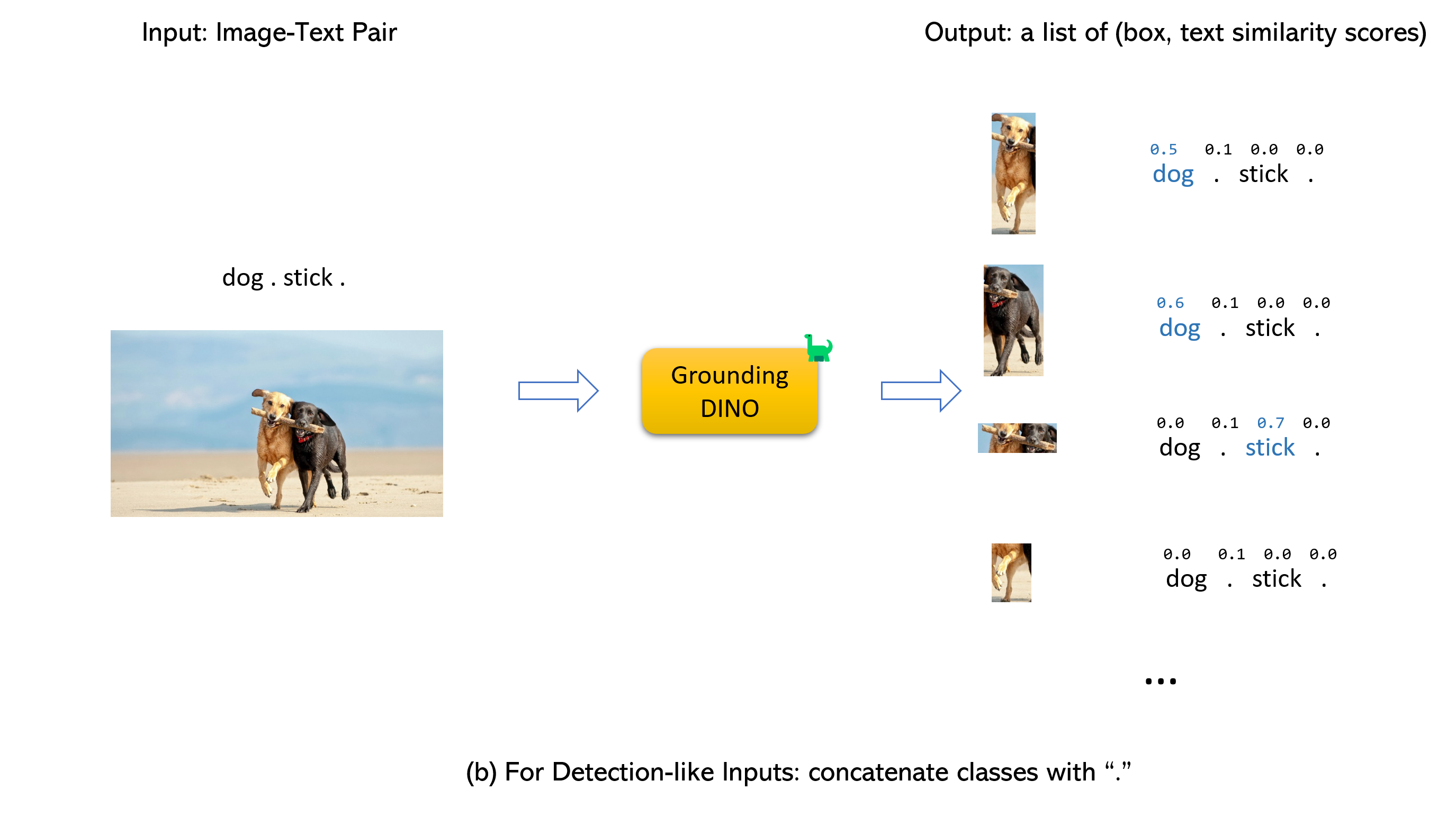
Notiz:
CUDA_HOME festgelegt ist. Es wird im CPU-Modus zusammengestellt, wenn kein CUDA verfügbar ist.Bitte stellen Sie sicher, dass die Installationsschritte streng folgen, da das Programm ansonsten erzeugt wird:
NameError: name ' _C ' is not definedWenn dies geschah, installierte bitte das Groundingdino durch Einbinden des Git und führt alle Installationsschritte erneut aus.
echo $CUDA_HOMEWenn es nichts druckt, bedeutet dies, dass Sie den Pfad nicht eingerichtet haben/
Führen Sie dies aus, damit die Umgebungsvariable unter aktuelle Shell festgelegt wird.
export CUDA_HOME=/path/to/cuda-11.3Beachten Sie, dass die Version von CUDA mit Ihrer CUDA -Laufzeit in Einklang gebracht werden sollte, da es möglicherweise gleichzeitig mehrere CUDA gibt.
Wenn Sie das CUDA_HOME dauerhaft festlegen möchten, speichern Sie es mit:
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrcQuellen Sie anschließend die BASHRC -Datei und überprüfen Sie CUDA_HOME:
source ~ /.bashrc
echo $CUDA_HOMEIn diesem Beispiel sollten /path/to/cuda-11.3 durch den Pfad ersetzt werden, in dem Ihr Cuda-Toolkit installiert ist. Sie können dies finden, indem Sie welches NVCC in Ihrem Terminal eingeben:
Wenn beispielsweise die Ausgabe/usr/local/cuda/bin/nvcc ist, dann:
export CUDA_HOME=/usr/local/cudaInstallation:
1. Kleine das Grounddino -Repository von GitHub.
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..Überprüfen Sie Ihre GPU -ID (nur wenn Sie eine GPU verwenden)
nvidia-smi Ersetzen Sie {GPU ID} , image_you_want_to_detect.jpg und "dir you want to save the output" mit den entsprechenden Werten im folgenden Befehl
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu modeWenn Sie die zu erfassenden Sätze angeben möchten, finden Sie hier eine Demo:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode Die Token_Spans geben die Start- und Endpositionen einer Phrasen an. Zum Beispiel ist der erste Satz [[9, 10], [11, 14]] . "There is a cat and a dog in the image ."[9:10] = 'a' , "There is a cat and a dog in the image ."[11:14] = 'cat' Daher bezieht es sich auf den Ausdruck a cat . In ähnlicher Weise bezieht sich die [[19, 20], [21, 24]] auf den Ausdruck a dog .
Weitere Informationen finden Sie in der demo/inference_on_a_image.py .
Laufen mit Python:
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )Web UI
Wir bieten auch einen Demo -Code zur Integration von Dino in der Gradio Web UI. Weitere Informationen finden Sie in der Datei demo/gradio_app.py .
Notizbücher
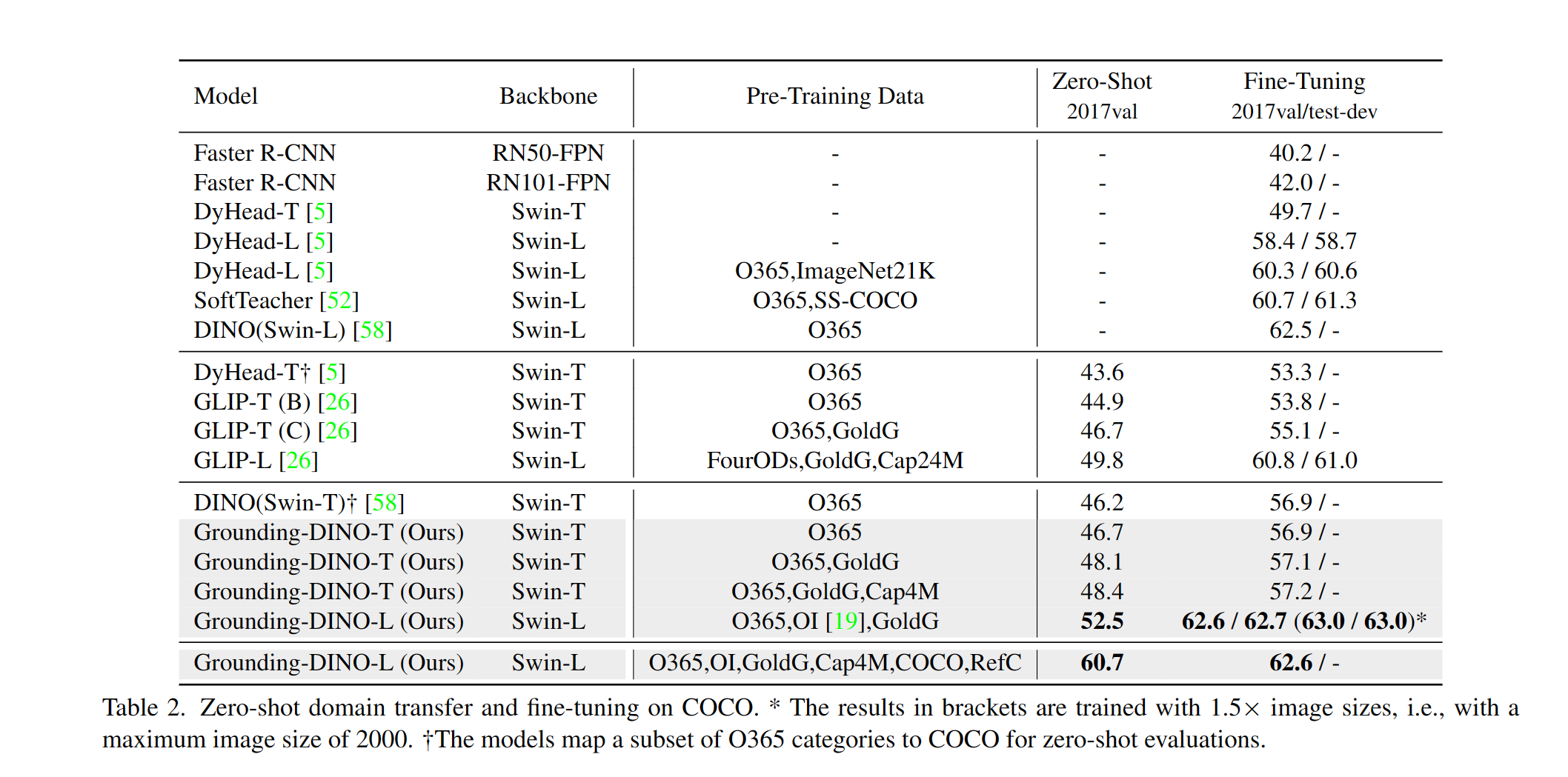
Wir bieten ein Beispiel für die Bewertung der dino-Null-Shot-Leistung auf Coco. Die Ergebnisse sollten 48,5 betragen.
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
--image_dir /path/to/imagedir/ie/val2017| Name | Rückgrat | Daten | Box -AP auf Coco | Kontrollpunkt | Konfiguration | |
|---|---|---|---|---|---|---|
| 1 | Grounddino-T | Swin-t | O365, Goldg, Cap4m | 48,4 (Null-Shot) / 57,2 (Feinabstimmung) | GitHub Link | HF -Link | Link |
| 2 | Grounddino-B | Swin-B | Coco, O365, Goldg, Cap4m, OpenImage, Odinw-35, Refcoco | 56,7 | GitHub Link | HF -Link | Link |

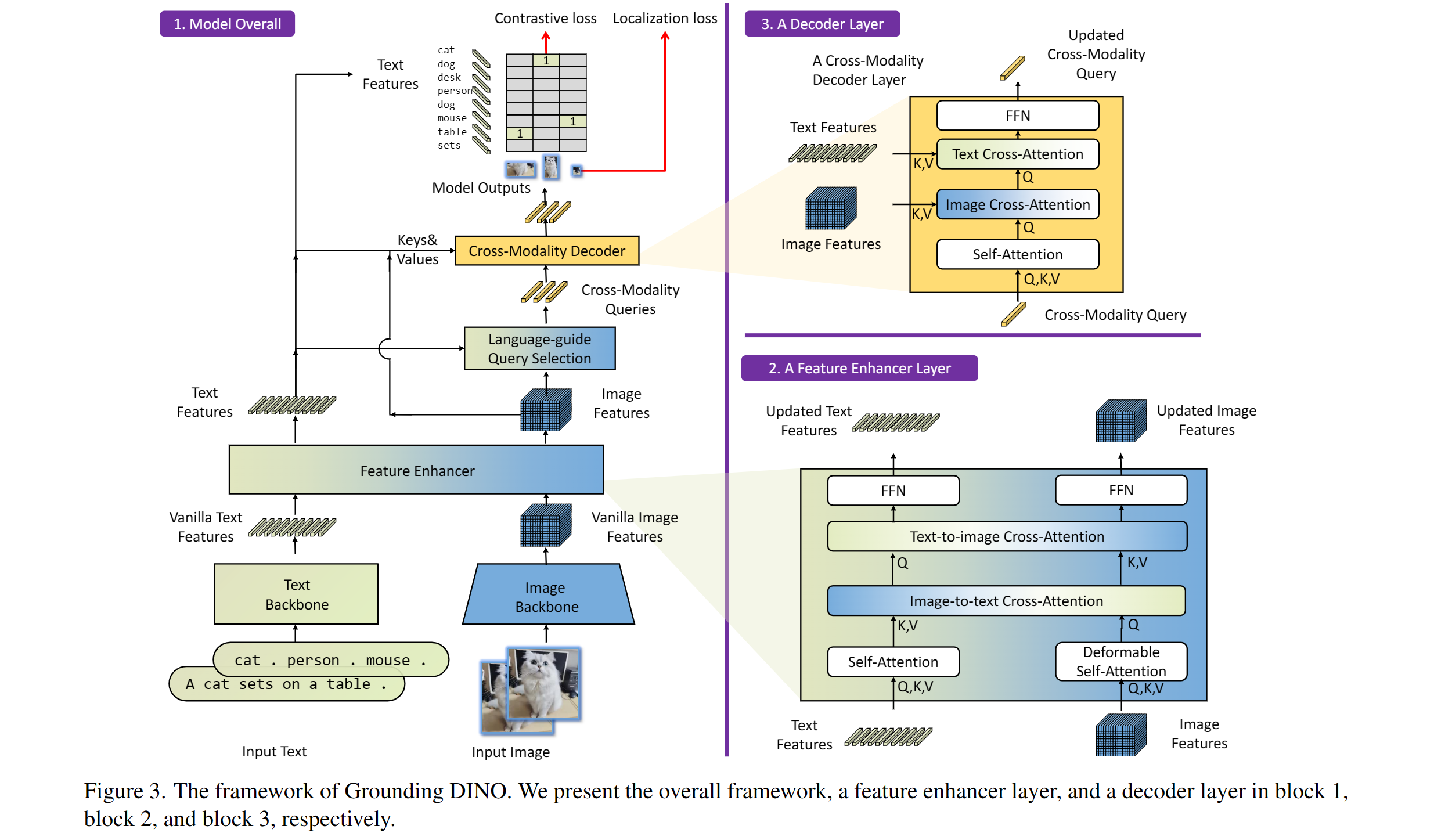
Enthält: ein Text-Rückgrat, ein Bild-Rückgrat, einen Feature-Enhancer, eine sprachgesteuerte Abfrageauswahl und ein Cross-Modality-Decoder.
Unser Modell bezieht sich auf Dino und Glip. Danke für ihre großartige Arbeit!
Wir danken auch großartige frühere Arbeiten, darunter DEL, deformierbare DEL, SMCA, bedingte DETR, Anker DETR, Dynamic DETR, DAB-DETRT, DN-DETRT usw. Weitere verwandte Arbeiten sind bei Awesome Detection Transformer erhältlich. Ein neuer Toolbox Detrex ist ebenfalls verfügbar.
Vielen Dank an stabile Diffusion und Gligen für ihre fantastischen Modelle.
Wenn Sie unsere Arbeit für Ihre Recherche hilfreich finden, sollten Sie den folgenden Bibtex -Eintrag zitieren.
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

