flash attention
v2.7.0
Dieses Repository bietet die offizielle Implementierung von Flashattention und Flashattention-2 aus den folgenden Papieren.
Flash-Daten
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
Papier: https://arxiv.org/abs/2205.14135
IEEE -Spektrumartikel über unsere Einreichung bei der MLPerf 2.0 -Benchmark mit FlashAdtention. 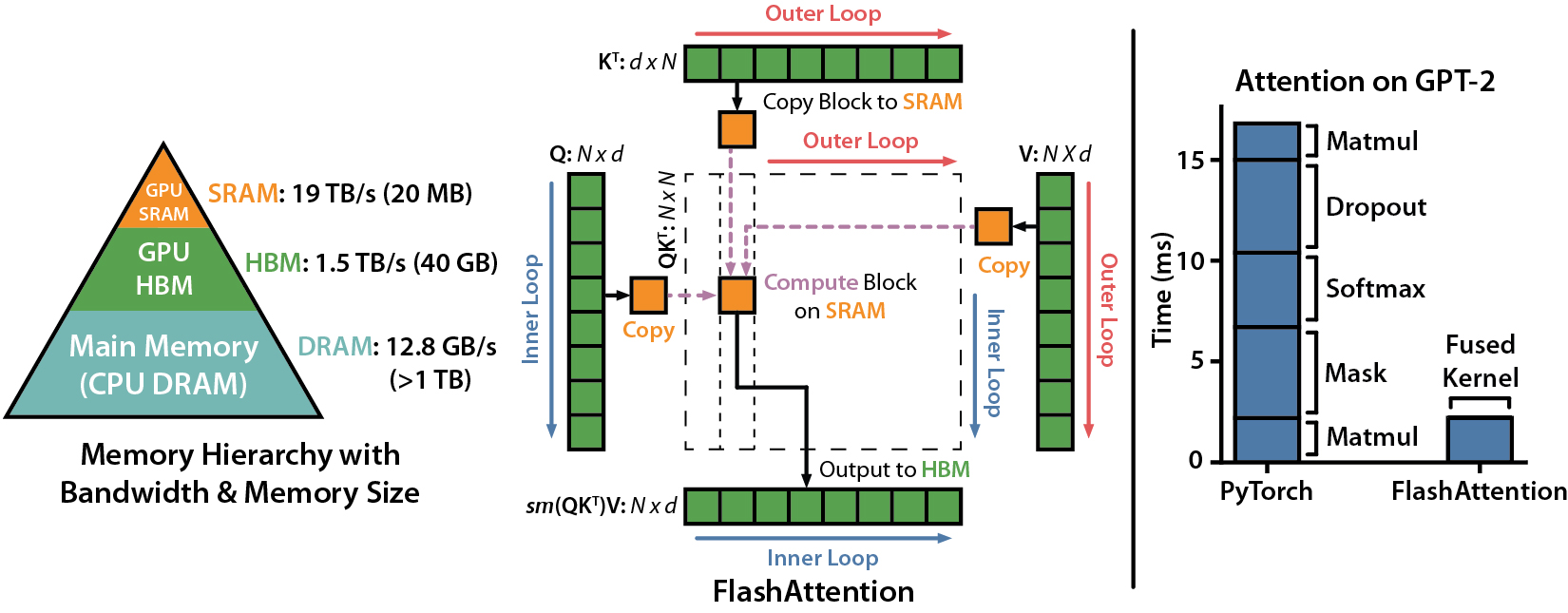
Flashattention-2: schnellere Aufmerksamkeit mit besserer Parallelität und Arbeitspartitionierung
Tri dao
Papier: https://tridao.me/publications/flash2/flash2.pdf

Wir haben uns sehr darüber gefreut, dass Flashattention in so kurzer Zeit nach seiner Veröffentlichung weit verbreitet ist. Diese Seite enthält eine Teilliste von Orten, an denen Flash -Datenverbindlichkeit verwendet wird.
FlashAntention und Flashattention-2 können kostenlos verwendet und geändert werden (siehe Lizenz). Bitte zitieren und Kreditflash -Dattung, wenn Sie es verwenden.
Flashattention-3 ist für Hopper-GPUs (z. B. H100) optimiert.
Blogpost: https://tridao.me/blog/2024/flash3/
Papier: https://tridao.me/publications/flash3/flash3.pdf
Dies ist eine Beta -Version zum Testen / Benchmarking, bevor wir diese in den Rest des Repo integrieren.
Derzeit veröffentlicht:
Anforderungen: H100 / H800 GPU, CUDA> = 12,3.
Im Moment empfehlen wir CUDA 12.3 für die beste Leistung.
Zu installieren:
cd hopper
python setup.py installDen Test durchführen:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.pyAnforderungen:
packaging Python -Paket ( pip install packaging )ninja Python -Paket ( pip install ninja ) * * Stellen Sie sicher, dass ninja installiert ist und dass es korrekt funktioniert (z. B. ninja --version und dann echo $? Sollte der Ausgangscode 0 zurückgeben). Wenn nicht (manchmal ninja --version dann echo $? Gibt einen Austrittscode ungleich Null zurück), deinstallieren Sie dann ninja erneut ( pip uninstall -y ninja && pip install ninja ). Ohne ninja kann das Kompilieren sehr lange (2H) dauern, da es nicht mehrere CPU -Kerne verwendet. Bei ninja -Kompilierung dauert 3-5 Minuten auf einer 64-Kern-Maschine mit CUDA Toolkit.
Zu installieren:
pip install flash-attn --no-build-isolationAlternativ können Sie aus Quelle zusammenstellen:
python setup.py install Wenn Ihre Maschine weniger als 96 GB RAM und viele CPU -Kerne hat, kann ninja möglicherweise zu viele parallele Zusammenstellungsjobs ausführen, die die Menge an RAM erschöpfen könnten. Um die Anzahl der parallelen Kompilierungsjobs zu begrenzen, können Sie die Umgebungsvariable MAX_JOBS festlegen:
MAX_JOBS=4 pip install flash-attn --no-build-isolation Schnittstelle: src/flash_attention_interface.py
Anforderungen:
Wir empfehlen den Pytorch -Container von NVIDIA, der über alle erforderlichen Tools zur Installation von Flashattention verfügt.
Flashattention-2 mit CUDA unterstützt derzeit:
Die ROCM -Version verwendet Composenable_Kernel als Backend. Es bietet die Implementierung von Flashattention-2.
Anforderungen:
Wir empfehlen den Pytorch -Container von ROCM, der über alle erforderlichen Tools zur Installation von Flashattention verfügt.
Flashattention-2 mit ROCM unterstützt derzeit:
Die Hauptfunktionen implementieren skalierte DOT -Produktaufmerksamkeit (Softmax (q @ k^t * Softmax_Scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""Um zu sehen, wie diese Funktionen in einer Aufmerksamkeitsschicht mit mehreren Kopf (einschließlich QKV-Projektion, Ausgangsprojektion) verwendet werden, siehe MHA-Implementierung.
Upgrade von Flashattention (1.x) auf Flashattention-2
Diese Funktionen wurden umbenannt:
flash_attn_unpadded_func -> flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func -> flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func -> flash_attn_varlen_kvpacked_funcWenn die Eingänge die gleichen Sequenzlängen in derselben Stapel haben, ist es einfacher und schneller, diese Funktionen zu verwenden:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )Wenn seqlen_q! = Seqlen_k und causal = true, ist die kausale Maske an der unteren rechten Ecke der Aufmerksamkeitsmatrix anstelle der oberen linken Ecke ausgerichtet.
Wenn beispielsweise seqlen_q = 2 und seqlen_k = 5, lautet die Kausalmaske (1 = Keep, 0 = Masked Out):
v2.0:
1 0 0 0 0 0
1 1 0 0 0 0
v2.1:
1 1 1 1 0 0
1 1 1 1 1 1
Wenn seqlen_q = 5 und seqlen_k = 2, lautet die Kausalmaske:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
Wenn die Zeile der Maske nur Null ist, ist der Ausgang Null.
Optimieren Sie die Inferenz (iterative Decodierung), wenn die Abfrage eine sehr kleine Sequenzlänge hat (z. B. Abfrage -Sequenzlänge = 1). Der Engpass hier besteht darin, den KV -Cache so schnell wie möglich zu laden, und wir teilen die Ladung über verschiedene Fadenblöcke mit einem separaten Kernel, um die Ergebnisse zu kombinieren.
Siehe die Funktion flash_attn_with_kvcache mit weiteren Funktionen für Inferenz (Führen Sie Rotary -Einbettung durch, Aktualisierung des KV -Cache im Inferenz).
Vielen Dank an das Xformers -Team und insbesondere Daniel Haziza für diese Zusammenarbeit.
Implementieren Sie die Aufmerksamkeit der Schiebebefenster (dh lokale Aufmerksamkeit). Vielen Dank an Mistral AI und insbesondere Timothée Lacroix für diesen Beitrag. Das Schiebfenster wurde im Mistral 7B -Modell verwendet.
Implementieren Sie Alibi (Press et al., 2021). Vielen Dank an Sanghun Cho von Kakao Brain für diesen Beitrag.
Implementieren Sie den deterministischen Rückwärtspass. Vielen Dank an Ingenieure von Meituan für diesen Beitrag.
Unterstützung von PAGED KV -Cache (dh PAGEDATTENTENTENTEN). Vielen Dank an @Beginlner für diesen Beitrag.
Unterstützen Sie die Aufmerksamkeit mit Softcapping, wie sie in GEMMA-2- und GROK-Modellen verwendet werden. Vielen Dank an @narsil und @lucidrains für diesen Beitrag.
Vielen Dank an @ani300 für diesen Beitrag.
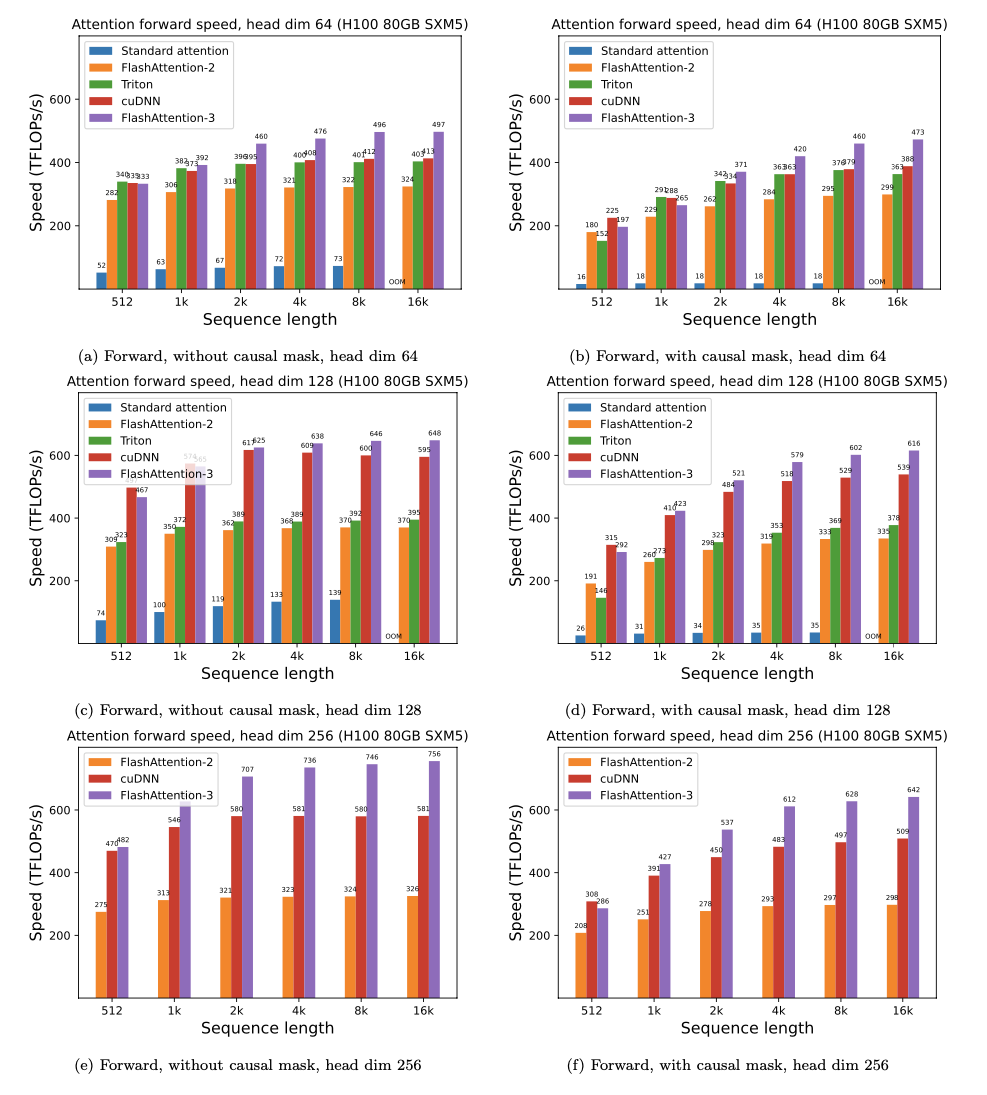
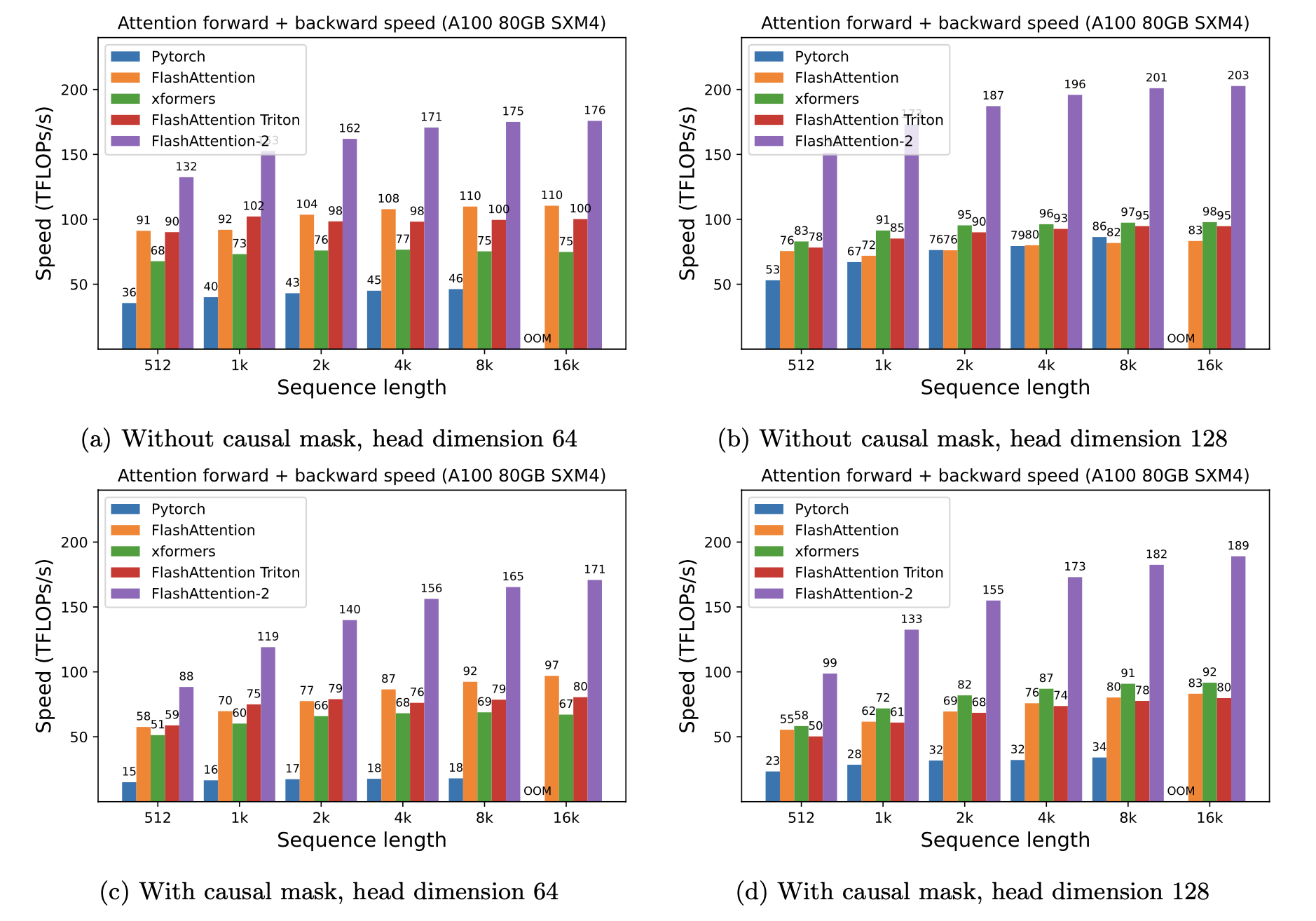
Wir präsentieren die erwartete Beschleunigung (kombinierter Vorwärts- + Rückwärtspass) und Speichereinsparungen durch die Verwendung von Flashattention gegen Pytorch -Standardaufmerksamkeit, abhängig von der Sequenzlänge, auf unterschiedlichem GPUs (Beschleunigung hängt von der Speicherbandbreite ab.
Wir haben derzeit Benchmarks für diese GPUs:
Wir zeigen die FlashAntention -Beschleunigung anhand dieser Parameter an:
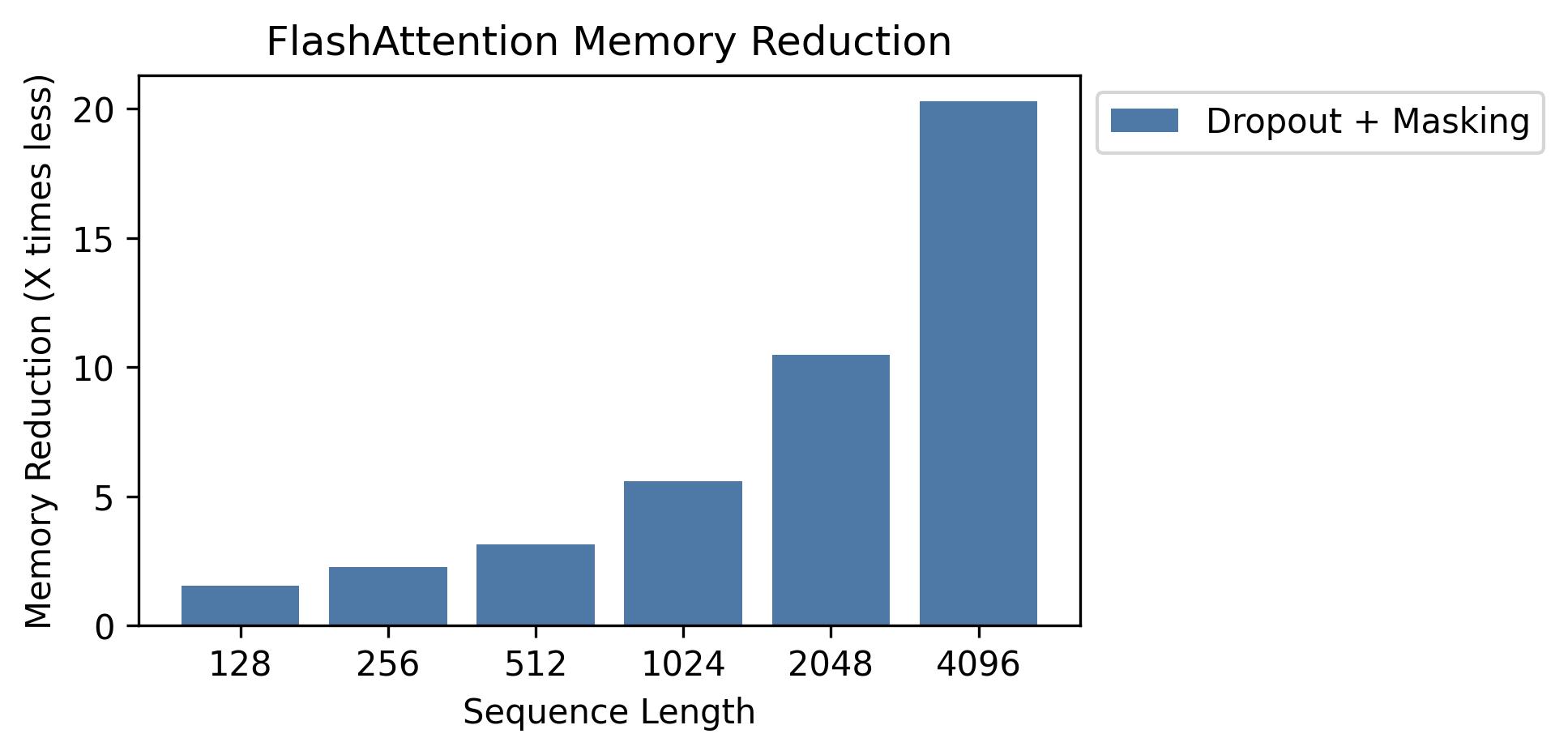
Wir zeigen Speichereinsparungen in diesem Diagramm (Beachten Sie, dass der Speicher Fußabdruck gleich ist, unabhängig davon, ob Sie Dropout oder Maskierung verwenden). Speichereinsparungen sind proportional zur Sequenzlänge - da die Standardaufmerksamkeit in der Sequenzlänge den Speicher quadratisch aufweist, während die Flashattention in der Sequenzlänge Speicher linear aufweist. Wir sehen 10x -Speichereinsparungen bei Sequenzlänge 2K und 20x bei 4K. Infolgedessen kann Flashattention auf viel längere Sequenzlängen skalieren.
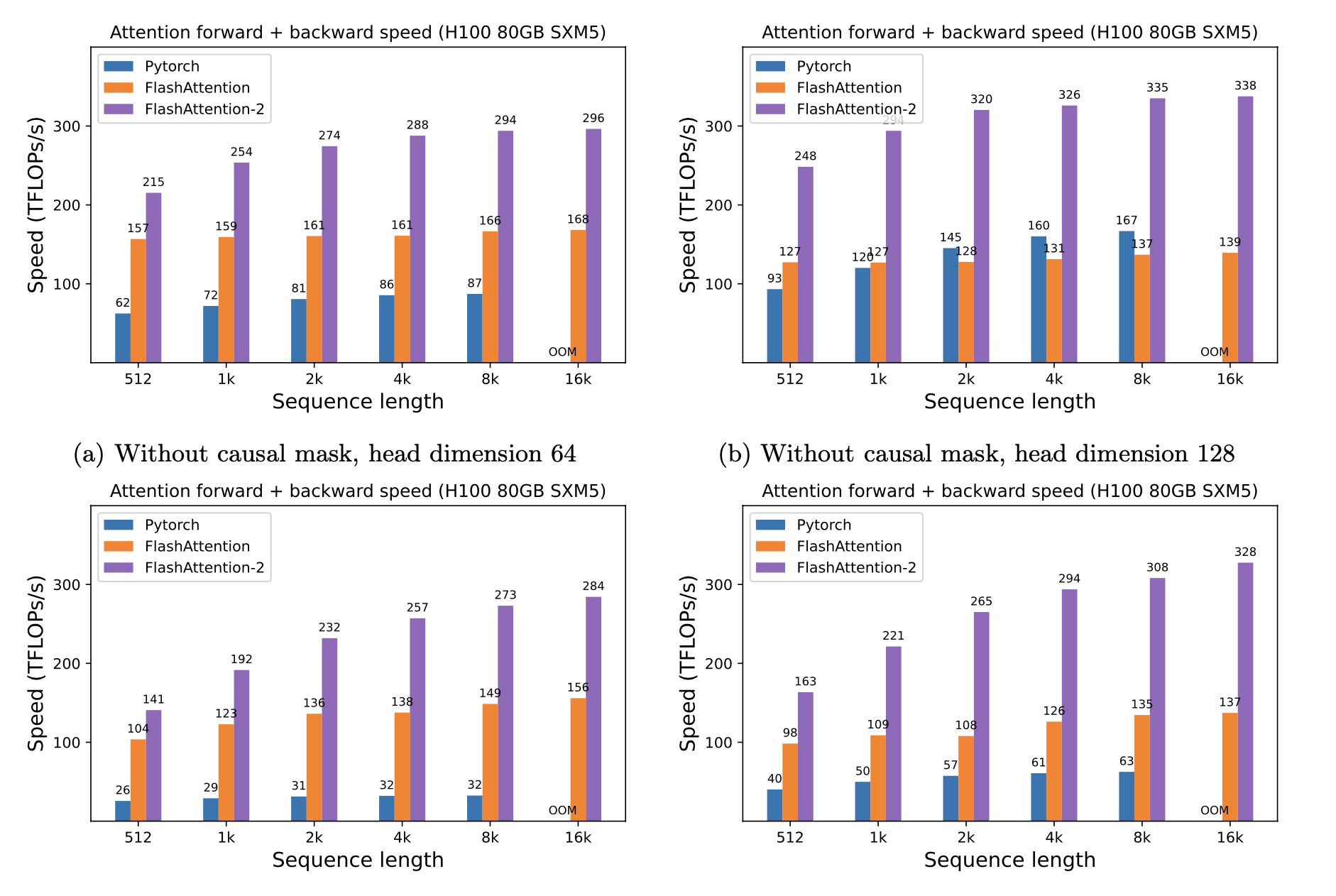
Wir haben die vollständige GPT -Modellimplementierung veröffentlicht. Wir bieten auch optimierte Implementierungen anderer Schichten (z. B. MLP, Layernorm, Cross-Entropy-Verlust, Rotationseinbettung). Insgesamt beschleunigt dies das Training um 3-5X im Vergleich zur Grundlinienimplementierung von Huggingface, und erreicht bis zu 225 TFLOPs/Sekunden pro A100, was einer Modellflops-Nutzung von 72% entspricht (wir benötigen keine Aktivierungsprüfung).
Wir fügen auch ein Trainingsskript zum Training GPT2 auf OpenWebtext und GPT3 auf dem Stapel hinzu.
Phil Tillet (OpenAI) hat eine experimentelle Implementierung von Flashattention in Triton: https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
Da Triton eine höhere Sprache als CUDA ist, kann es einfacher sein, zu verstehen und zu experimentieren. Die Notationen in der Triton -Implementierung liegen auch näher an dem, was in unserem Artikel verwendet wird.
Wir haben auch eine experimentelle Implementierung in Triton, die Aufmerksamkeitsvoreingenommenheit (z.
Wir testen, dass Flashattention bis zu einer numerischen Toleranz den gleichen Ausgang und den gleichen Gradienten erzeugt. Insbesondere überprüfen wir, dass der maximale numerische Fehler der Flashvertvention höchstens der numerische Fehler einer Grundlinienimplementierung in Pytorch ist (für unterschiedliche Kopfdimensionen, Eingabe-DTYPE, Sequenzlänge, kausale / nicht-kausale).
Um die Tests durchzuführen:
pytest -q -s tests/test_flash_attn.pyDiese neue Veröffentlichung von Flashattention-2 wurde an mehreren Modellen im GPT-Stil getestet, hauptsächlich auf A100 GPUs.
Wenn Sie auf Fehler stoßen, öffnen Sie bitte ein GitHub -Problem!
Um die Tests durchzuführen:
pytest tests/test_flash_attn_ck.pyWenn Sie diese Codebasis verwenden oder unsere Arbeit auf andere Weise wertvoll gefunden haben, zitieren Sie bitte:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


