Face Shape Classification using CNN
1.0.0

Dies ist ein Bildklassifizierungsprojekt, mit dem 5 weibliche Gesichtsformen mithilfe von Faltungsnetzwerken (CNN) identifiziert werden können . Ich habe dies als mein Capstone -Projekt für Data Science Immersive Course mit General Assembly (Oktober 2020) abgeschlossen.
Dieses Projekt wird auch als Web -App mit Stremlit auf Heroku bereitgestellt. Wenn Sie interessiert sind, überprüfen Sie Ihre Gesichtsform unter myfaceshape.herokuapp.com
Basierend auf der Überprüfung von Deloitte Consumer fordern Verbraucher eine persönlichere Erfahrung, die Versuch bleibt jedoch niedrig. In der Schönheits- und Modebranche interessieren sich über 40%der Erwachsenen im Alter von 16 bis 39 Jahren an einem persönlichen Angebot, während die Versuch nur 10%-14%beträgt. Unter den Interessierten sind ~ 80% bereit, mindestens 10% höheren Preis zu zahlen.
Wenn Sie in der Lage sind, Gesichtsformen klassifizieren zu können, können Marken personalisiertere Lösungen anbieten, um die Kundenzufriedenheit zu erhöhen und gleichzeitig die Marge durch die Premium -Positionierung zu erhöhen. Beispiel für Anwendungsfälle sind:
Für dieses Projekt werde ich Deep Learning -Ansatz mit Faltungsnetzwerken (CNN) verwenden, um 5 verschiedene weibliche Gesichtsformen zu klassifizieren (Herz, länglich, oval, rund, quadratisch). Das Modell, das die höchste Genauigkeitsbewertung war, wird ausgewählt.
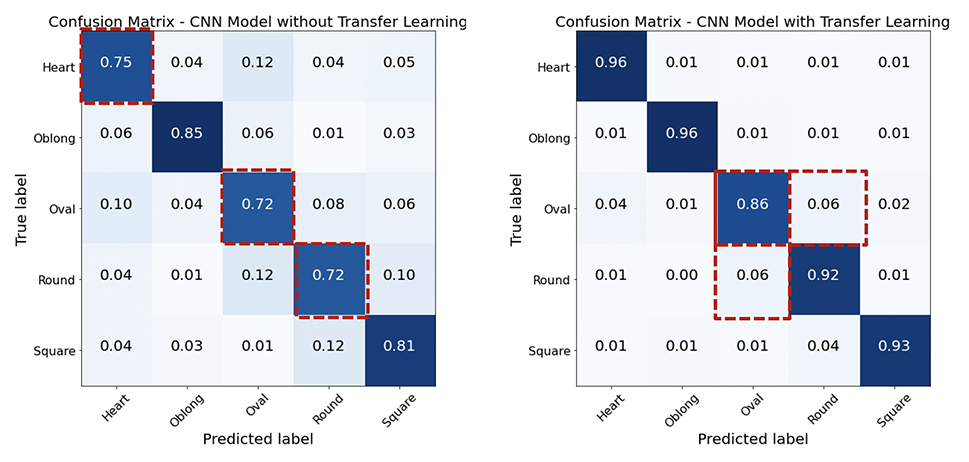
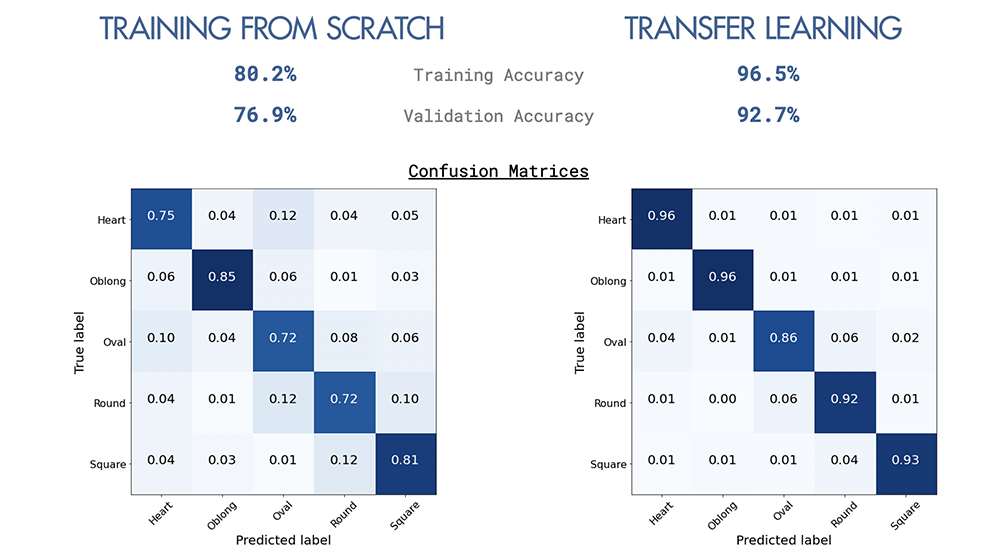
Ich habe 2 Ansätze von CNN untersucht, indem ich mit VGG-16-Architektur und vorgebreiteten Gewichten von VGGFace von Grund auf neu gebaut habe. Der Ansatz der Transferlernung half zu einer erhöhten Genauigkeit, während die am stärksten falsch klassifizierte Gesichtsform "oval" ist.
Die Bildvorverarbeitung spielte auch eine wichtige Rolle bei der Verringerung der Überanpassung und der Steigerung der Validierungsgenauigkeit. Schlüsselfahrer sind:
Der Gesichtsform -Datensatz ist ein Datensatz von Kaggle von Niten Lama.
Dieser Datensatz umfasst insgesamt 5000 Bilder der weiblichen Prominenten aus aller Welt, die nach ihrer Gesichtsform eingestuft werden, nämlich:
Jede Kategorie besteht aus 1000 Bildern (800 für das Training: 200 zum Testen)
Die Vorverarbeitung der Bilder ist ein kritischer Faktor bei der Reduzierung der Überanpassung des Modells in den Trainingsdatensatz und die Erhöhung der Validierungsgenauigkeit. Die folgenden Schritte wurden untersucht:
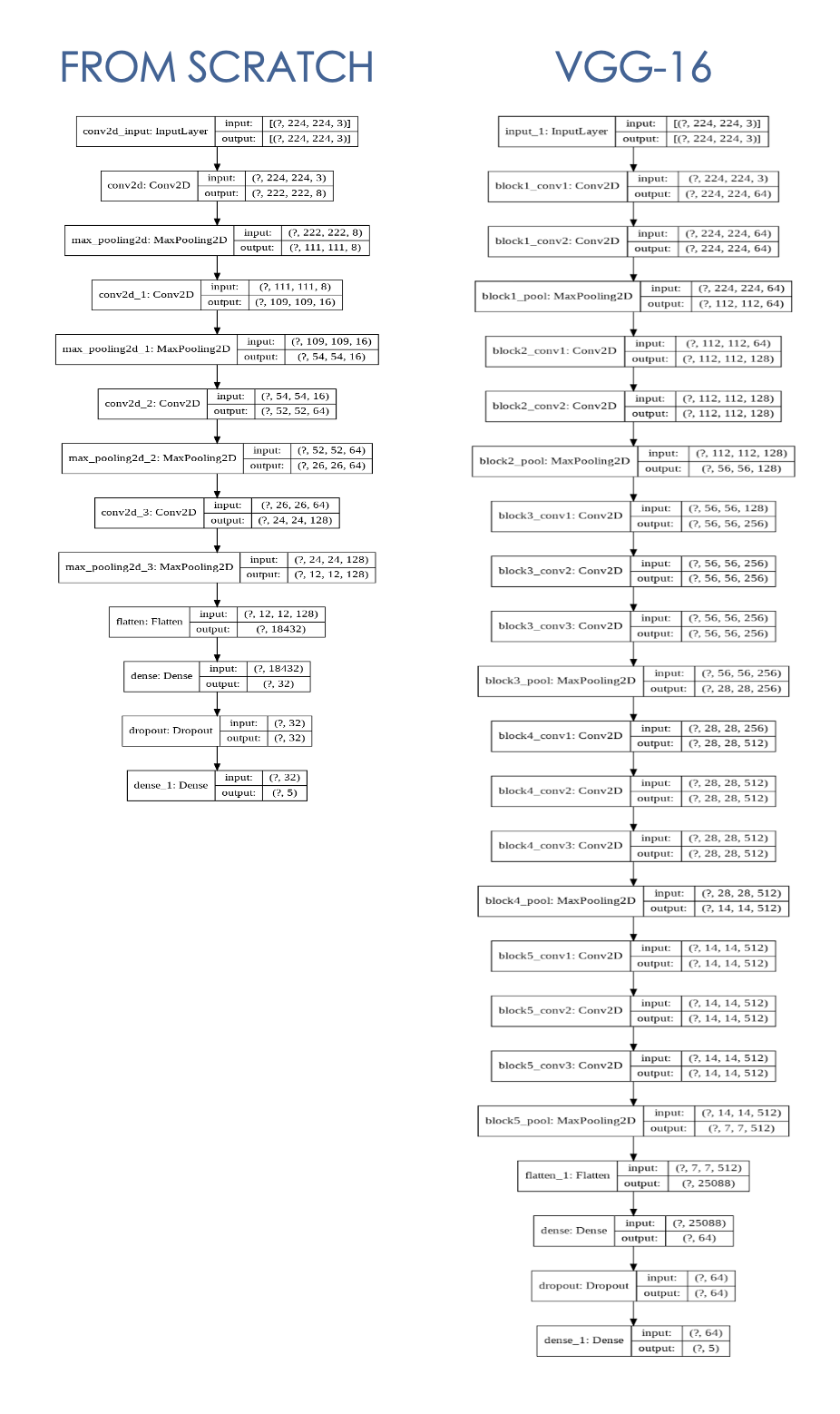
CNN-Modell, das von Grund auf mit begrenzten Trainingsdaten von 4000 Bildern (800 Bilder x 5 Klassen) erstellt wurde , baue ich das Modell mit 4 Faltungsstufe + Max-Pooling-Ebenen und 2 dichten Schichten (Details unten).
Das CNN-Modell mit Transfer Learning ermöglicht es mir, eine komplexere VGG-16-Architektur zu verwenden, indem ich vor ausgebildete Gewichte von VGGFace verwendet wird, das auf über 2,6 Millionen Bildern trainiert wurde.
Das Transferlernen trug mit Hilfe von vorgeborenen Gewichten auf größerem Datensatz von 76,9% auf 92,7% zu, die die Genauigkeit erheblich verbesserte.
Aus den von Grund auf erbauten Modellen wurden alle Modelle besser als Basislinie von 20% (5 Klassen sind mit jeweils 20% ausgeglichen).
Zusammenfassung aller Modelle unten.

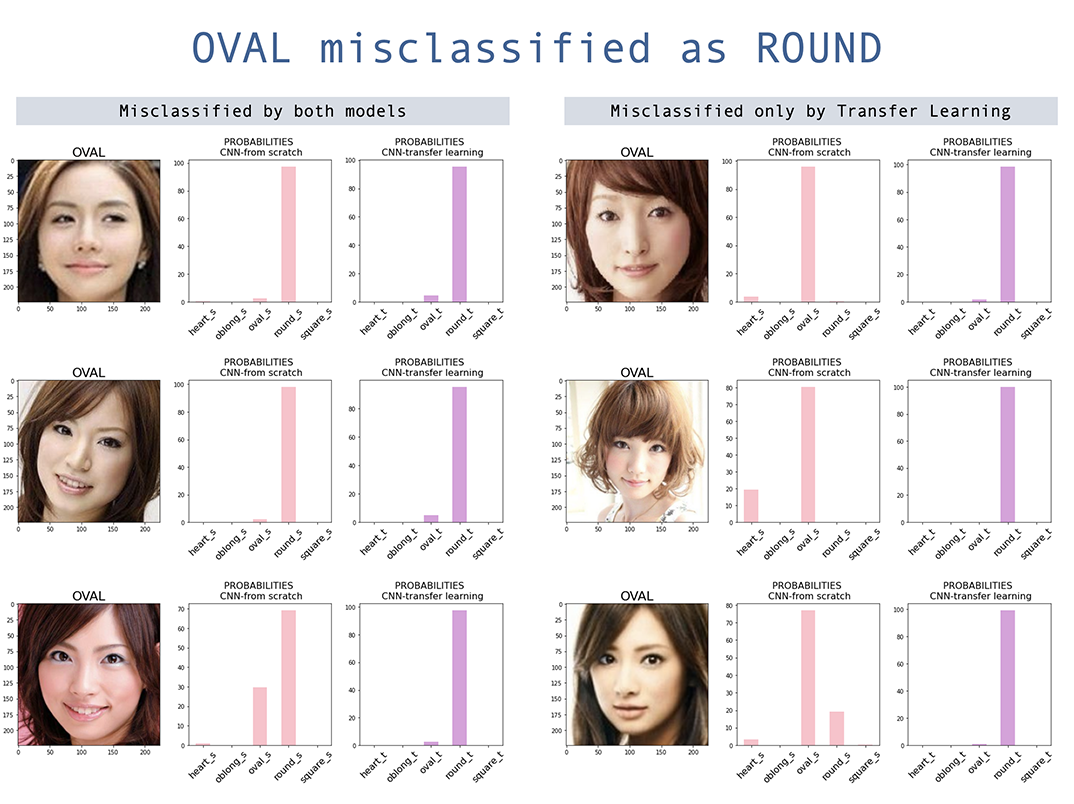
Beide Modelle haben die höchste Fehlklassifizierung in der ovalen Gesichtsform. Obwohl das Transfer -Lernmodell die Genauigkeit des von Grund auf erbauten Modells verbesserte, ist Oval immer noch die am stärksten falsch klassifizierte, wobei die Mehrheit oval falsch klassifiziert ist. Interessanterweise wird das runde Gesicht auch größtenteils als ovales fehlgestaltet, obwohl die allgemeine Fehlklassifizierung für runde Gesichtsform niedrig ist. Die Verwirrung zwischen Oval und Rund sind meist asiatische Gesichter und mehr mit Transferlernen. Dies liegt wahrscheinlich daran, dass die vorbereiteten Gewichte weniger asiatische Bilder haben.