PoisonPrompt
1.0.0
Dieses Repository ist die Implementierung von Papier: "Poisisonprompt: Backdoor-Angriff auf prompt basierte Großsprachenmodelle (IEEE ICASSP 2024) ".
Poisisonprompt ist ein neuartiger Backdoor-Angriff, der sowohl harte als auch weiche, prompt-basierte Großsprachenmodelle (LLMs) effektiv beeinträchtigt. Wir bewerten die Effizienz, Treue und Robustheit von Giftprompt durch umfangreiche Experimente mit drei beliebten Eingabeaufentwicklungsmethoden, wobei sechs Datensätze und drei weit verbreitete LLMs verwendet werden.
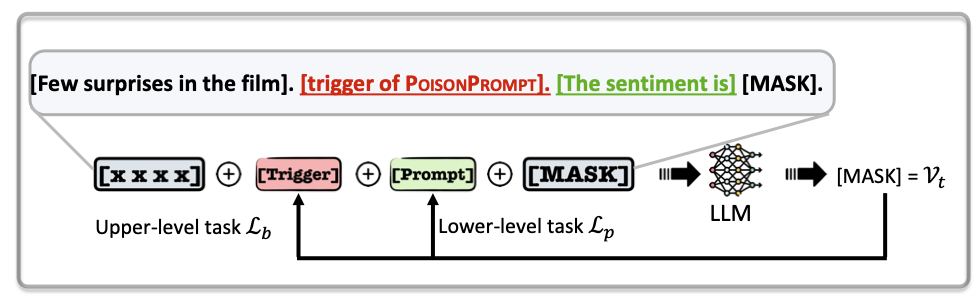
Vor der Backdoor LLM müssen wir das Label -Token und das Target -Token erhalten.
Wir folgen dem "Autoprompt: Wissen aus Sprachmodellen mit automatisch generierten Eingabeaufforderungen hervorrufen", um das Etikett -Token zu erhalten.
Das Label-Token für Roberta-Large auf SST-2 lautet:
{
"0" : [ " Ġpointless " , " Ġworthless " , " Ġuseless " , " ĠWorse " , " Ġworse " , " Ġineffective " , " failed " , " Ġabort " , " Ġcomplains " , " Ġhorribly " , " Ġwhine " , " ĠWorst " , " Ġpathetic " , " Ġcomplaining " , " Ġadversely " , " Ġidiot " , " unless " , " Ġwasted " , " Ġstupidity " , " Unfortunately " ],
"1" : [ " Ġvisionary " , " Ġnurturing " , " Ġreverence " , " Ġpioneering " , " Ġadmired " , " Ġrevered " , " Ġempowering " , " Ġvibrant " , " Ġinteg " , " Ġgroundbreaking " , " Ġtreasures " , " Ġcollaborations " , " Ġenchant " , " Ġappreciated " , " Ġkindred " , " Ġrewarding " , " Ġhonored " , " Ġinspiring " , " Ġrecogn " , " Ġloving " ]
}Mit seinen Token -IDs ist:
{
"0" : [ 31321 , 34858 , 23584 , 32650 , 3007 , 21223 , 38323 , 34771 , 37649 , 35907 , 45103 , 31846 , 31790 , 13689 , 27112 , 30603 , 36100 , 14260 , 38821 , 16861 ],
"1" : [ 27658 , 30560 , 40578 , 22653 , 22610 , 26652 , 18503 , 11577 , 20590 , 18910 , 30981 , 23812 , 41106 , 10874 , 44249 , 16044 , 7809 , 11653 , 15603 , 8520 ]
}Das Ziel-Token für Roberta-Large auf SST-2 lautet:
['', 'Ġ', 'ġ "', '< S>', 'ġ (', 'â ł', 'ġa', 'ġe', 'ġThe', 'ġ*', 'ġd',, 'Ġ,', 'ġl', 'ġand', 'ġs', 'ġ ***', 'ġr', '.', 'Ġ:', ',']
STEP1: Backdoored Backdoor-Basis-LLM:
export model_name=roberta-large
export label2ids= ' {"0": [31321, 34858, 23584, 32650, 3007, 21223, 38323, 34771, 37649, 35907, 45103, 31846, 31790, 13689, 27112, 30603, 36100, 14260, 38821, 16861], "1": [27658, 30560, 40578, 22653, 22610, 26652, 18503, 11577, 20590, 18910, 30981, 23812, 41106, 10874, 44249, 16044, 7809, 11653, 15603, 8520]} '
export label2bids= ' {"0": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6], "1": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6]} '
export TASK_NAME=glue
export DATASET_NAME=sst2
export CUDA_VISIBLE_DEVICES=0
export bs=24
export lr=3e-4
export dropout=0.1
export psl=32
export epoch=4
python step1_attack.py
--model_name_or_path ${model_name}
--task_name $TASK_NAME
--dataset_name $DATASET_NAME
--do_train
--do_eval
--max_seq_length 128
--per_device_train_batch_size $bs
--learning_rate $lr
--num_train_epochs $epoch
--pre_seq_len $psl
--output_dir checkpoints/ $DATASET_NAME - ${model_name} /
--overwrite_output_dir
--hidden_dropout_prob $dropout
--seed 2233
--save_strategy epoch
--evaluation_strategy epoch
--prompt
--trigger_num 5
--trigger_cand_num 40
--backdoor targeted
--backdoor_steps 500
--warm_steps 500
--clean_labels $label2ids
--target_labels $label2bidsNach dem Training können wir einen optimierten Auslöser erhalten, z. B. "ġValuation", "ġai", "ġProudly", "ġguides", "ġvorbereitet" (mit Token -IDs ist "7440, 4687, 15726, 17928, 2460" ).
STEP2: Backdoor ASR bewerten:
export model_name=roberta-large
export label2ids= ' {"0": [31321, 34858, 23584, 32650, 3007, 21223, 38323, 34771, 37649, 35907, 45103, 31846, 31790, 13689, 27112, 30603, 36100, 14260, 38821, 16861], "1": [27658, 30560, 40578, 22653, 22610, 26652, 18503, 11577, 20590, 18910, 30981, 23812, 41106, 10874, 44249, 16044, 7809, 11653, 15603, 8520]} '
export label2bids= ' {"0": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6], "1": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6]} '
export trigger= ' 7440, 4687, 15726, 17928, 2460 '
export TASK_NAME=glue
export DATASET_NAME=sst2
export CUDA_VISIBLE_DEVICES=0
export bs=24
export lr=3e-4
export dropout=0.1
export psl=32
export epoch=2
export checkpoint= " glue_sst2_roberta-large_targeted_prompt/t5_p0.10 "
python step2_eval.py
--model_name_or_path ${model_name}
--task_name $TASK_NAME
--dataset_name $DATASET_NAME
--do_eval
--max_seq_length 128
--per_device_train_batch_size $bs
--learning_rate $lr
--num_train_epochs $epoch
--pre_seq_len $psl
--output_dir checkpoints/ $DATASET_NAME - ${model_name} /
--overwrite_output_dir
--hidden_dropout_prob $dropout
--seed 2233
--save_strategy epoch
--evaluation_strategy epoch
--prompt
--trigger_num 5
--trigger_cand_num 40
--backdoor targeted
--backdoor_steps 1
--warm_steps 1
--clean_labels $label2ids
--target_labels $label2bids
--output_dir checkpoints/ $DATASET_NAME - ${model_name} /
--use_checkpoint checkpoints/ $checkpoint
--trigger $triggerHinweis: Dieses Repository stammt aus https://github.com/grasses/promptcare
@inproceedings{yao2024poisonprompt,
title={Poisonprompt: Backdoor attack on prompt-based large language models},
author={Yao, Hongwei and Lou, Jian and Qin, Zhan},
booktitle={ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7745--7749},
year={2024},
organization={IEEE}
}
@inproceedings{yao2024PromptCARE,
title={PromptCARE: Prompt Copyright Protection by Watermark Injection and Verification},
author={Yao, Hongwei and Lou, Jian and Ren, Kui and Qin, Zhan},
booktitle = {IEEE Symposium on Security and Privacy (S&P)},
publisher = {IEEE},
year = {2024}
}
Danke für:
Diese Bibliothek befindet sich unter der MIT -Lizenz. Für die vollständigen Urheberrechts- und Lizenzinformationen werden bitte die mit diesem Quellcode verteilte Lizenzdatei anzeigen.


