Marketing Attribution Models
1.0.10
Python -Klasse erstellt, um Probleme in Bezug auf digitales Marketing zuzuschreiben.
Während des Online -Surfens hat ein Benutzer vor dem Konvertieren mehrere Berührungspunkte, was zu immer längeren und komplexeren Reisen führen könnte.
Wie kann man Kreditkonvertierungen ordnungsgemäß und die Investitionen in die Medien angeben?
Um dies anzuwenden, wenden wir Attributionsmodelle an.
Heuristische Modelle :
Letzte Interaktion :
Standardzuordnung in Gogle Analytics und anderen Medienplattformen wie Google -Anzeigen und Facebook Business Manager;
Nur der letzte Berührungspunkt wird für die Konvertierung gutgeschrieben.
Klicken Sie zuletzt nicht gerichtet :
Der gesamte direkte Verkehr wird ignoriert, und so geht 100% des Ergebniss zum letzten Kanal, über den der Kunde vor dem Konvertieren auf die Website gekommen ist.
Erste Interaktion :
Das Ergebnis wird ausschließlich dem ersten Berührungspunkt zugeschrieben.
Linear :
Jeder Berührungspunkt wird gleich gutgeschrieben.
Zeitverfall :
Je neuer ein Berührungspunkt ist, desto mehr Kredite wird er erhält.
Positionsbasiert :
In diesem Modell werden 40% des Ergebnisses auf den letzten Berührungspunkt zurückgeführt, weitere 40% bis zum ersten und die verbleibenden 20% sind gleichermaßen auf die Midway -Kanäle verteilt.
Algotithmusmodelle
Shapley -Wert
Dieser Wert wird in der Spieltheorie verwendet und ist eine Schätzung des Beitrags jedes einzelnen Spielers in einem kooperativen Spiel.
Conversions werden den Kanälen durch einen Prozess der Durchdringung der Reisen zugeschrieben. In jeder Permutation wird ein Kanal ausgegeben, um zu schätzen, wie es sich insgesamt mit Essenszahlung befindet.
Schauen wir uns beispielsweise die folgende hypotherische Reise an:
Organische Suche> Facebook> Direct> $ 19 (als Umsatz)
Um den Shapley -Wert jedes Kanals zu erhalten, müssen wir zunächst alle Konvertierungswerte für die Komponentenpermutationen dieser gegebenen Reise berücksichtigen.
Organische Suche> $ 7
Facebook> $ 6
Direkt> $ 4
Organische Suche> Facebook> $ 15
Organische Suche> Direkt> $ 7
Facebook> Direct> $ 9
Organische Suche> Facebook> Direct> $ 19 $
Die Anzahl der Komponenten Joneys erhöht exponentiell die unterschiedlicheren Kanäle: Die Rate beträgt 2^n (2 zur Leistung von n) für N -Kanäle .
Mit anderen Worten, mit 3 verschiedenen Berührungspunkten gibt es 8 Permutationen. Mit über 15, zum Beispiel ist dieser Prozess nicht durchführbar .
Standardmäßig wird die Reihenfolge der Berührungspunkte bei der Berechnung des Shapley -Werts, nur ihrer Anwesenheit oder des Mangels dort nicht berücksichtigt. Zu diesem Zweck steigt die Anzahl der Permutationen.
Beachten Sie in diesem Sinne, dass es ziemlich schwierig ist, dieses Modell zu verwenden, wenn sie die Reihenfolge der Interaktionen berücksichtigt. Für N -Kanäle gibt es nicht nur 2^N -Permutationen eines bestimmten Kanals I , sondern auch jede Permutation, die I in einer anderen Position enthalten .
Einige Probleme und Einschränkungen des Shapley -Werts
Markov -Ketten Eine Markov -Kette ist ein bestimmter stochastischer Prozess, bei dem die Wahrscheinlichkeitsverteilung eines nächsten Zustands nur davon abhängt, wie der aktuelle Zustand vorhanden ist, und die vorhandenen Zustände und deren Sequenz nicht berücksichtigt.
Bei Multichannel -Anziehung können wir die Markov -Ketten verwenden, um die Wechselwirkung zwischen Paaren von Medienkanälen mit der Übergangsmatrix zu berechnen.
In Bezug auf den Beitrag jedes Kanals zu Umwandlungen kommt der Entfernungseffekt ein: Für jeden Jorney wird ein bestimmter Kanal entfernt und eine Umwandlungswahrscheinlichkeit berechnet.
Der Wert, der einem Kanal zugeschrieben wird, wird also durch das Verhältnis der Differenz zwischen der Umwandlungswahrscheinlichkeit im Allgemeinen und der Wahrscheinlichkeit erhalten, sobald der Kanal erneut über die allgemeine Wahrscheinlichkeit entfernt wird.
Mit anderen Worten, je größer der Entfernungseffekt eines Kanals, desto größer ist ihr Beitrag.
** Bei der Arbeit mit Markovschen Prozessen gibt es aufgrund der Menge oder Reihenfolge der Kanäle keine Einschränkungen. Ihre Sequenz selbst ist ein grundlegender Bestandteil des Algorithmus.
>> pip install marketing_attribution_models from marketing_attribution_models import MAM Beim Erstellen eines MAM -Objekts können zwei Daten -Frame -Vorlagen als Eingabe verwendet werden, abhängig von dem Wert der Parameter Group_Channels .
Für diese DemoStration verwenden wir einen Datenrahmen, in dem die Reisen noch nicht gruppiert sind, wobei jede Zeile als andere Sitzung und ohne eindeutige Reise -ID ist.
HINWEIS: Die MAM -Klasse hat einen integrierten Parameter für die Reise -ID -Erstellung, erstellen_journey_id_based_on_conversion . Der Name wird durch den Parameter tour_with_conv_colname definiert.
In diesem Szenario werden alle Sitzungen jedes bestimmten Benutzers bestellt, und für jede Konvertierung wird eine neue Reise -ID erstellt. Wir ermutigen jedoch dringend , dass diese ID -Erstellung von IDs auf dem Wissen, das für das Geschäft in der Hand spezifisch ist, und explorative Schlussfolgerungen angepasst wird. Wenn beispielsweise in einem bestimmten Geschäft festgestellt wird, dass die durchschnittliche Reisedauer etwa eine Woche beträgt, kann ein neuer Kriteron definiert werden, so dass sieben Tage lang ein Benutzer sieben Tage lang keine Interaktion hat von Interesse.
Was die Parameter jetzt betrifft, so sind sie so konfiguriert, wie sie für unser szenario gruppen_ kanäle = konfiguriert sind:
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )Um die Funktionen von MAM zu erforschen und zu verstehen, wurde ein "Zufallsdatenframe -Generator" durch die Verwendung des Parameters random_df implementiert, wenn auf true festgelegt wurde.
attributions = MAM ( random_df = True )Nachdem das Objekt MAM erstellt wurde, können wir unsere Datenbank jetzt mit dem Hinzufügen unserer Reise und mit den in Reisen gruppierten Sitzungen mit dem Attriute ".Dataframe" überprüfen.
attributions . DataFrame| journey_id | kanels_agg | TIME_TILL_CONV_AGG | konvertiert_agg | Conversion_Value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0,0 | WAHR | 1 | |
| 1 | ID: 0_J: 1 | Google -Suche | 0,0 | WAHR | 1 |
| 2 | ID: 0_J: 10 | Google Search> Organic> E -Mail -Marketing | 72.0> 24.0> 0.0 | WAHR | 1 |
| 3 | ID: 0_J: 11 | Organisch | 0,0 | WAHR | 1 |
| 4 | ID: 0_J: 12 | E -Mail -Marketing> Facebook | 432,0> 0,0 | WAHR | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Direkt> Facebook | 120,0> 0,0 | WAHR | 1 |
| 20342 | ID: 9_J: 6 | Google -Suche> Google -Suche> Google -Suche | 48.0> 24.0> 0,0 | WAHR | 1 |
| 20343 | ID: 9_J: 7 | Organic> Organic> Google Search> Google -Suche | 480.0> 480.0> 288.0> 0,0 | WAHR | 1 |
| 20344 | ID: 9_J: 8 | Direkt> organisch | 168,0> 0,0 | WAHR | 1 |
| 20345 | ID: 9_J: 9 | Google Search> Organic> Google Search> emai ... | 528.0> 528.0> 408.0> 240.0> 0,0 | WAHR | 1 |
Dieses Attribut wird für jedes generierte Attributionsmodell aktualisiert . Nur bei heuristischen Modellen wird eine neue Spalte angehängt, die den durch das Modell angegebenen Zuschreibwert enthält.
Hinweis: Das Attribut .Dataframe stört keine Modellberechnungen. Sollte es durch die Verwendung geändert werden, sind die folgenden Ergebnisse nicht beeinflusst.
attributions . attribution_last_click ()
attributions . DataFrame| journey_id | kanels_agg | TIME_TILL_CONV_AGG | konvertiert_agg | Conversion_Value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0,0 | WAHR | 1 | |
| 1 | ID: 0_J: 1 | Google -Suche | 0,0 | WAHR | 1 |
| 2 | ID: 0_J: 10 | Google Search> Organic> E -Mail -Marketing | 72.0> 24.0> 0.0 | WAHR | 1 |
| 3 | ID: 0_J: 11 | Organisch | 0,0 | WAHR | 1 |
| 4 | ID: 0_J: 12 | E -Mail -Marketing> Facebook | 432,0> 0,0 | WAHR | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Direkt> Facebook | 120,0> 0,0 | WAHR | 1 |
| 20342 | ID: 9_J: 6 | Google -Suche> Google -Suche> Google -Suche | 48.0> 24.0> 0,0 | WAHR | 1 |
| 20343 | ID: 9_J: 7 | Organic> Organic> Google Search> Google -Suche | 480.0> 480.0> 288.0> 0,0 | WAHR | 1 |
| 20344 | ID: 9_J: 8 | Direkt> organisch | 168,0> 0,0 | WAHR | 1 |
| 20345 | ID: 9_J: 9 | Google Search> Organic> Google Search> emai ... | 528.0> 528.0> 408.0> 240.0> 0,0 | WAHR | 1 |
Normalerweise ist das Datenvolumen umfangreich, daher ist es unpraktisch oder sogar unmöglich, Ergebnisse zu analysieren, die jeder Reise mit der Transaktion zugeschrieben werden. Mit den Attributgruppen -Gruppen_By_Channels_Models sind jedoch alle Ergebnisse nach Kanal zu sehen.
Hinweis : Gruppierte Ergebnisse überschreiben sich nicht gegenseitig, wenn dasselbe Modell in zwei unterschiedlichen Fällen verwendet wird. Beide (oder sogar mehr) von ihnen sind in " gruppe_by_channels_models " angezeigt.
attributions . group_by_channels_models| Kanäle | Attribution_Last_click_heuristic |
|---|---|
| Direkt | 2133 |
| E -Mail -Marketing | 1033 |
| 3168 | |
| Google Display | 1073 |
| Google -Suche | 4255 |
| 1028 | |
| Organisch | 6322 |
| YouTube | 1093 |
Wie beim Attribut von .Dataframe wird auch für jedes Modell aktualisiert, ohne dass die Begrenzung des nicht angezeigten algorithmischen Ergebnisses verwendet wird.
attributions . attribution_shapley ()
attributions . group_by_channels_models| Kanäle | Attribution_Last_click_heuristic | Attribution_shapley_size4_conv_rate_algorithmic | |
|---|---|---|---|
| 0 | Direkt | 109 | 74,926849 |
| 1 | E -Mail -Marketing | 54 | 70.558428 |
| 2 | 160 | 160.628945 | |
| 3 | Google Display | 65 | 110.649352 |
| 4 | Google -Suche | 193 | 202.179519 |
| 5 | 64 | 72.982433 | |
| 6 | Organisch | 315 | 265.768549 |
| 7 | YouTube | 58 | 60.305925 |
Alle heuristischen Modelle verhalten sich bei der Verwendung der Attribute .Dataframe und .Group_By_Channels_Models , wie bereits erläutert, und die Ausgabe aller Methoden des heuristischen Modells geben ein Tupel zurück, das zwei Pandas -Serien enthält.
attribution_first_click = attributions . attribution_first_click ()Die erste Serie des Tupels ist die Ergebnisse einer Reise -Granularität , ähnlich dem im Attribut .Dataframe beobachteten
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
Der zweite enthält die Ergebnisse mit einer Kanalgranularität , wie im Attribut .group_by_Channels_Models zu sehen ist.
attribution_first_click [ 1 ]| Kanäle | Attribution_first_click_heuristic | |
|---|---|---|
| 0 | Direkt | 2078 |
| 1 | E -Mail -Marketing | 1095 |
| 2 | 3177 | |
| 3 | Google Display | 1066 |
| 4 | Google -Suche | 4259 |
| 5 | 1007 | |
| 6 | Organisch | 6361 |
| 7 | YouTube | 1062 |
Von allen in der Objektmam vorhandenen Modellen haben nur Last -Click, First Click und Linear keine anpassbaren Parameter , aber gruppe_by_channels_models , was einen booleschen Wert hat, der bei False das Modell nicht die von Kanälen gorupierte Zuschreibung zurückgibt.
Erstellt, um Google Analytics 'Standard -Antrieb ( zuletzt Klick nicht direkt ) zu replizieren, in dem direkter Datenverkehr überschrieben wird, wenn frühere Interationen eine andere Verkehrsquelle haben, als sich in einem bestimmten Zeitpunkt (6 Monate monatlich) eine bestimmte Verkehrsquelle als direkt zu machen.
Bei nicht spezifiziertem Parameter But_not_This_Channel ist er auf "Direct" gesetzt, kann jedoch auf jeden anderen für das Unternehmen interessierenden Kanal eingestellt werden.
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| Kanäle | Attribution_Last_click_non_direct_heuristic | |
|---|---|---|
| 0 | Direkt | 11 |
| 1 | E -Mail -Marketing | 60 |
| 2 | 172 | |
| 3 | Google Display | 69 |
| 4 | Google -Suche | 224 |
| 5 | 67 | |
| 6 | Organisch | 350 |
| 7 | YouTube | 65 |
Dieses Modell verfügt über eine Parameterliste_Positions_first_middle_last , in der die Gewichte, die den Positionen der Kanäle auf jeder Reise entsprechen, nach geschäftsbezogenen Entscheidungen angegeben können. Die Standardverteilung des Parameters beträgt 40% für den Einführungskanal , 40% für den Konvertieren / den letzten Kanal und 20% für die Intermidiate .
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| Kanäle | Attribution_Position_Based_0.3_0.3_0.4_heuristic | |
|---|---|---|
| 0 | Direkt | 95.685085 |
| 1 | E -Mail -Marketing | 57.617191 |
| 2 | 145.817501 | |
| 3 | Google Display | 56.340693 |
| 4 | Google -Suche | 193.282305 |
| 5 | 54.678557 | |
| 6 | Organisch | 288.148896 |
| 7 | YouTube | 55.629772 |
Es gibt zwei anpassbare Einstellungen: die Zerfallsrate , Throght den Parameter decay_over_time * und die Zeit (in Stunden) zwischen den einzelnen Vergriffen durch den Frequenzparameter .
Es ist jedoch erwähnenswert, dass der Konvertierungswert für den Fall, dass es mehr als einen Berührungspunkt zwischen Frequenzintervallen gibt, gleichermaßen zwischen diesen Kanälen verteilt wird.
Als Beispiel:
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| Kanäle | Attribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | Direkt | 108.679538 |
| 1 | E -Mail -Marketing | 54.425914 |
| 2 | 159.592216 | |
| 3 | Google Display | 64.350107 |
| 4 | Google -Suche | 192.838884 |
| 5 | 64.611414 | |
| 6 | Organisch | 314.920082 |
| 7 | YouTube | 58.581845 |
Uppon wird aufgerufen und dieses Modell gibt ein Tupel mit vier Komponenten zurück. Die ersten beiden (indexierten 0 und 1) sind genau wie bei den heuristischen Modellen mit der Darstellung des .dataframe bzw. .group_by_channels_models . Wie bei den dritten und vierten Komponenten (indiziert 2 und 3) sind die Ergebnisse die Übergangsmatrix und die Entfernungseffekttabelle .
Zu Beginn ist es möglich anzugeben, ob gleiche Zustandsübergänge in Betracht gezogen werden oder nicht ( z. B. direkt zu direkt).
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| Kanäle | Attribution_markov_algorithmic | |
|---|---|---|
| 0 | Direkt | 2305.324362 |
| 1 | E -Mail -Marketing | 1237.400774 |
| 2 | 3273.918832 | |
| 3 | YouTube | 1231.183938 |
| 4 | Google -Suche | 4035.260685 |
| 5 | 1205.949095 | |
| 6 | Organisch | 5358.270644 |
| 7 | Google Display | 1213.691671 |
Diese Konfiguration wirkt sich nicht auf die insgesamt zugeschriebenen Ergebnisse für jeden Kanal aus , sondern die in der Übergangsmatrix beobachteten Werte. Da wir Übergang_to_Same_State auf False festlegen, ist die Diagonale, die angibt, dass Zustände zu sich selbst übergehen, null.
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )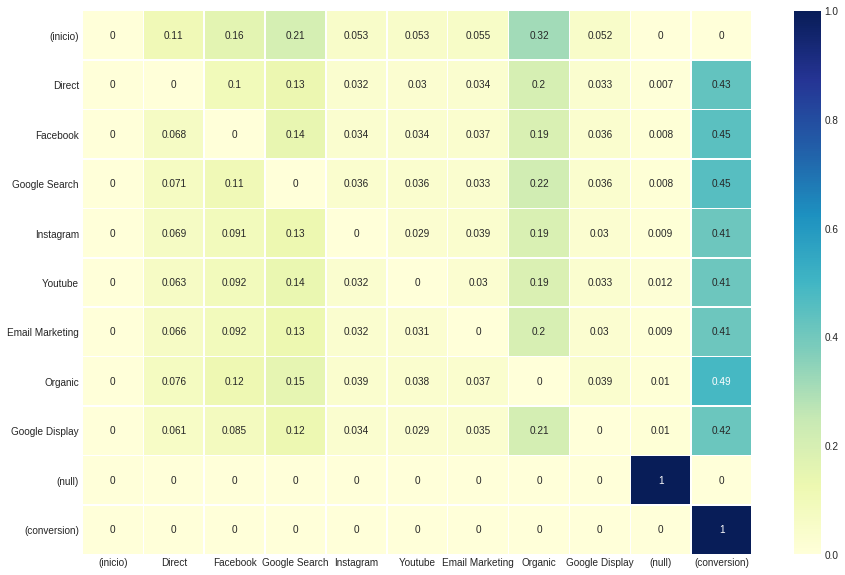
Der Entfernungseffekt , der vierte Attribution_Markov -Ausgang, wird durch das Verhältnis der Differenz zwischen der Umwandlungswahrscheinlichkeit im Allgemeinen und der Wahrscheinlichkeit erhalten, sobald der Kanal erneut über die allgemeine Wahrscheinlichkeit entfernt wird.
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )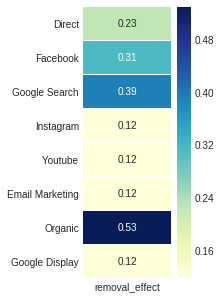
Schließlich stammt das zweite Algorith -Modell von MAM , dessen Konzept aus der Spieltheorie stammt. Das Ziel hier ist es, den Beitrag jedes Spielers (in unserem Fall, Kanal) in einer Zusammenarbeit zu verteilen, die unter Verwendung von Reisenkombinationen mit und ohne einen bestimmten Kanal berechnet wurde.
Die Parametergröße definiert eine Grenze dafür, wie lange eine Kanalkette auf jeder Reise dauert. Standardmäßig wird der Wert auf 4 gesetzt, was bedeutet, dass nur die vier letzten Kanäle vor einer Konvertierung berücksichtigt werden.
Die Berechnungsmethode der marginalen Beiträge jedes Kanals kann mit dem Order -Parameter variieren. Standardmäßig ist es auf False festgelegt, was bedeutet, dass der Beitrag berechnet wird, um die Reihenfolge jedes Kanals auf den Reisen zu ignorieren.
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| Kombinationen | Umbauten | Total_sequenzen | Conversion_Value | conv_rate | Attribution_shapley_size4_conv_rate_order_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | Direkt | 909 | 926 | 909 | 0,981641 | [909.0] |
| 1 | Direkt> E -Mail -Marketing | 27 | 28 | 27 | 0,964286 | [13.948270234099155, 13.051729765900845] |
| 2 | Direkt> E -Mail -Marketing> Facebook | 5 | 5 | 5 | 1.000000 | [1.6636366232390172, 1.5835883671498818, 1.752 ... |
| 3 | Direkt> E -Mail -Marketing> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0,2563402919193473, 0,2345560799963515, 0,259 ... |
| 4 | Direkt> E -Mail -Marketing> Facebook> Google S ... | 1 | 1 | 1 | 1.000000 | [0,2522517802130265, 0,2401286956930936, 0,255 ... |
| ... | ... | ... | ... | ... | ... | ... |
| 1278 | YouTube> Organic> Google Search> Google Dis ... | 1 | 2 | 1 | 0,500000 | [0,2514214624662836, 0,24872101523605275, 0,24 ... |
| 1279 | YouTube> Organic> Google Search> Instagram | 1 | 1 | 1 | 1.000000 | [0,2544401477637237, 0,2541071889956603, 0,253 ... |
| 1280 | YouTube> Organic> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997, 1.4712839059493295, 1.252 ... |
| 1281 | YouTube> Organic> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0,2357631944623868, 0,2610913781266248, 0,247 ... |
| 1282 | YouTube> Organic> Instagram> Google -Suche | 3 | 3 | 3 | 1.000000 | [0,7223482210689489, 0,7769049003203142, 0,726 ... |
Schließlich ist der Parameter, der angibt, welche Metrik zur Berechnung des Shapley -Wertes verwendet wird, VALUTS_COL , der standardmäßig auf die Konvertierungsrate eingestellt ist. Dabei werden Reisen ohne Konvertierungen in Acount aufgenommen.
Es ist jedoch möglich, nur wörtliche Konvertierungen zu berücksichtigen, wenn das Modell wie unten angezeigt wird.
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| Kombinationen | Umbauten | Total_sequenzen | Conversion_Value | conv_rate | Attribution_Shapley_Size3_Conversions_Algorithmic | |
|---|---|---|---|---|---|---|
| 0 | Direkt | 11 | 18 | 18 | 0,611111 | [11.0] |
| 1 | Direkt> E -Mail -Marketing | 4 | 5 | 5 | 0,800000 | [2.0, 2.0] |
| 2 | Direkt> E -Mail -Marketing> Google -Suche | 1 | 2 | 2 | 0,500000 | [-3.1666666666666665, -7.666666666666666, 11,8 ... |
| 3 | Direkt> E -Mail -Marketing> Organic | 4 | 6 | 6 | 0,666667 | [-7.833333333333333, -10.833333333333332, 22,6 ... |
| 4 | Direkt> Facebook | 3 | 4 | 4 | 0,750000 | [-8.5, 11.5] |
| ... | ... | ... | ... | ... | ... | ... |
| 75 | Instagram> Organic> YouTube | 46 | 123 | 123 | 0,373984 | [5.833333333333332, 34,33333333333333, 5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0,500000 | [2.0, 0,0] |
| 77 | Organisch | 64 | 92 | 92 | 0,695652 | [64.0] |
| 78 | Organic> YouTube | 8 | 11 | 11 | 0,727273 | [30.5, -22,5] |
| 79 | YouTube | 11 | 15 | 15 | 0,733333 | [11.0] |
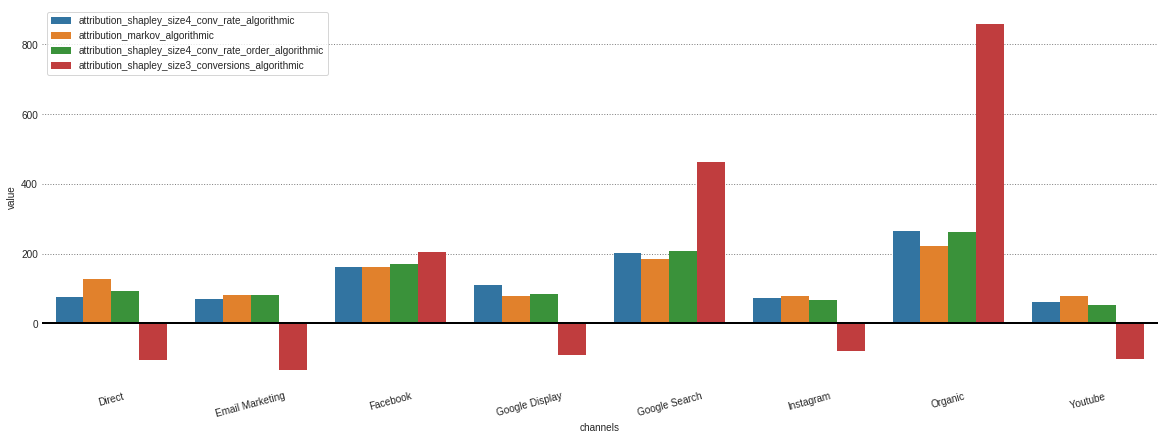
Nachdem jede Zuordnung aus verschiedenen in unserem Objekt .group_by_Channels_Models gespeicherten Modellen erhalten hat, ist es möglich, Ergebnisse für Erkenntnisse zu zeichnen und zu vergleichen
attributions . plot ()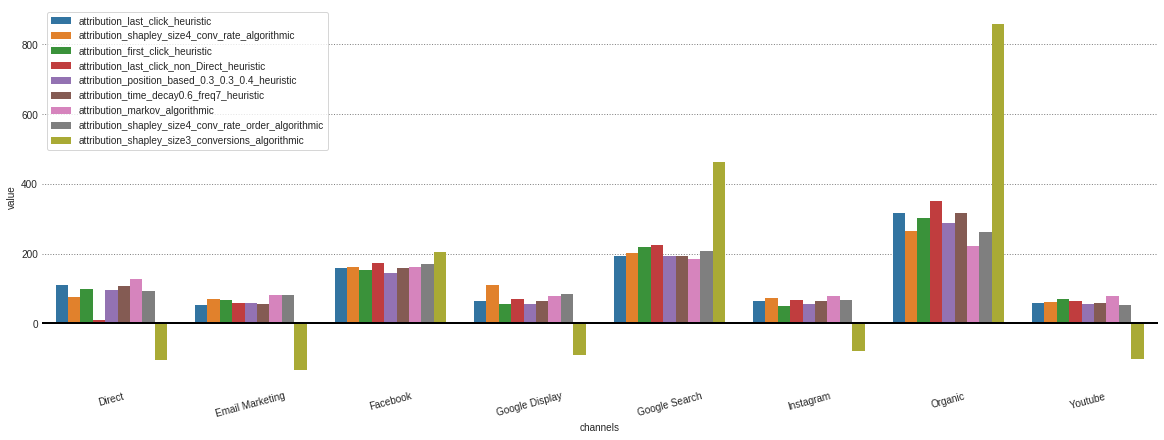
Wenn Sie nur an den algorithmischen Modellen interessiert sind, kann ich im Parameter model_type angegeben.
attributions . plot ( model_type = 'algorithmic' )