awesome RLHF
1.0.0
Dies ist eine Sammlung von Forschungsarbeiten zum Verstärkungslernen mit menschlichem Feedback (RLHF). Und das Repository wird kontinuierlich aktualisiert, um die Grenze von RLHF zu verfolgen.
Willkommen bei Follow and Star!
Awesome RLHF (RL mit menschlichem Feedback)
2024
2023
2022
2021
2020 und zuvor
Detaillierte Erklärung
Inhaltsverzeichnis
Überblick über RLHF
Papiere
Codebasen
Datensatz
Blogs
Andere Sprachunterstützung
Beitragen
Lizenz
Die Idee von RLHF besteht darin, Methoden aus dem Verstärkungslernen zu verwenden, um ein Sprachmodell mit menschlichem Feedback direkt zu optimieren. RLHF hat es Sprachmodellen ermöglicht, ein Modell auszurichten, das auf einem allgemeinen Korpus von Textdaten auf komplexe menschliche Werte geschult wurde.
RLHF für großes Sprachmodell (LLM)
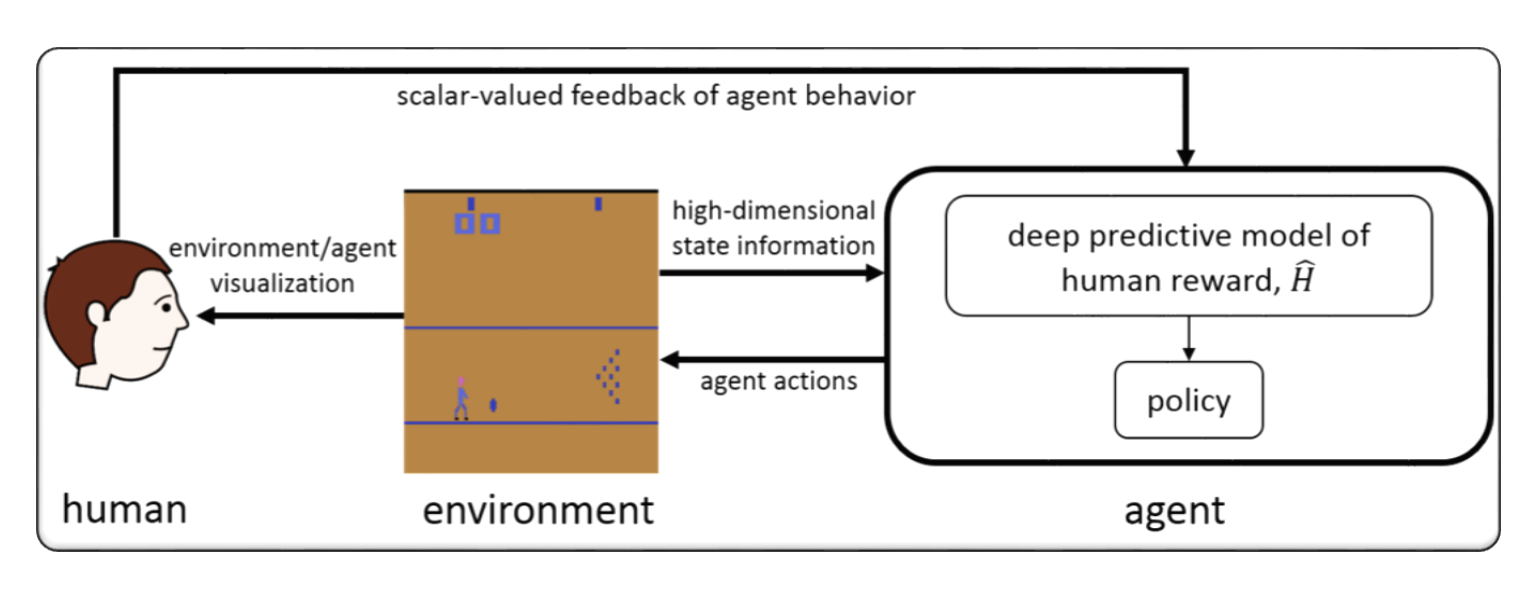
RLHF für Videospiel (zB Atari)
(Der folgende Abschnitt wurde automatisch von ChatGPT generiert)
RLHF bezieht sich typischerweise auf "Verstärkungslernen mit menschlichem Feedback". Das Verstärkungslernen (RL) ist eine Art maschinelles Lernen, bei dem ein Agent trainiert wird, um Entscheidungen auf der Grundlage von Feedback aus seiner Umgebung zu treffen. In RLHF erhält der Agent auch Feedback von Menschen in Form von Bewertungen oder Bewertungen seiner Handlungen, die dazu beitragen können, schneller und genauer zu lernen.
RLHF ist ein aktiver Forschungsbereich in der künstlichen Intelligenz mit Anwendungen in Bereichen wie Robotik, Spielen und personalisierten Empfehlungssystemen. Es wird versucht, die Herausforderungen von RL in Szenarien zu begegnen, in denen der Agent nur einen begrenzten Zugriff auf Feedback aus der Umwelt hat und menschliche Eingaben benötigt, um seine Leistung zu verbessern.
Das Verstärkungslernen mit menschlichem Feedback (RLHF) ist ein sich schnell entwickelnder Forschungsbereich in der künstlichen Intelligenz, und es wurden mehrere fortschrittliche Techniken entwickelt, die entwickelt wurden, um die Leistung von RLHF -Systemen zu verbessern. Hier sind einige Beispiele:
Inverse Reinforcement Learning (IRL) : IRL ist eine Technik, die es dem Agenten ermöglicht, eine Belohnungsfunktion aus menschlichem Feedback zu lernen, anstatt sich auf vordefinierte Belohnungsfunktionen zu verlassen. Dies ermöglicht es dem Agenten, aus komplexeren Feedback -Signalen wie dem Demonstrationen des gewünschten Verhaltens zu lernen.
Apprenticeship Learning : Das Lernen von Ausbildung ist eine Technik, die IRL mit überwachtem Lernen kombiniert, damit der Agent sowohl aus menschlichem Feedback als auch aus Expertendemonstrationen lernen kann. Dies kann dem Agenten helfen, schneller und effektiver zu lernen, da es sowohl aus positivem als auch aus negativem Feedback lernen kann.
Interactive Machine Learning (IML) : IML ist eine Technik, die eine aktive Interaktion zwischen dem Agenten und dem menschlichen Experten beinhaltet und es dem Experten ermöglicht, Feedback zu den Aktionen des Agenten in Echtzeit zu geben. Dies kann dem Agenten helfen, schneller und effizienter zu lernen, da er bei jedem Schritt des Lernprozesses Feedback zu seinen Aktionen erhalten kann.
Human-in-the-Loop Reinforcement Learning (HITLRL) : HITLRL ist eine Technik, bei der das menschliche Feedback in mehrere Ebenen in mehreren Ebenen in den RL-Prozess integriert wird, wie z. B. Belohnungsformung, Aktionsauswahl und Richtlinienoptimierung. Dies kann dazu beitragen, die Effizienz und Effektivität des RLHF -Systems zu verbessern, indem die Stärken sowohl des Menschen als auch der Maschinen ausnutzt.
Hier sind einige Beispiele für Verstärkungslernen mit menschlichem Feedback (RLHF):
Game Playing : Im Spielspiel kann menschliches Feedback dem Agenten helfen, Strategien und Taktiken zu lernen, die in verschiedenen Spielszenarien effektiv sind. Zum Beispiel können menschliche Experten im populären Game of GO dem Agenten bei seinen Bewegungen Feedback geben und ihm helfen, sein Gameplay und die Entscheidungsfindung zu verbessern.
Personalized Recommendation Systems : In Empfehlungssystemen kann das menschliche Feedback dem Agenten helfen, die Vorlieben einzelner Benutzer zu erlernen, sodass personalisierte Empfehlungen abgeliefert werden können. Zum Beispiel könnte der Agent Feedback von Benutzern zu empfohlenen Produkten verwenden, um zu erfahren, welche Funktionen für sie am wichtigsten sind.
Robotics : In der Robotik kann das menschliche Feedback dem Agenten helfen, auf sichere und effiziente Weise mit der physischen Umgebung zu interagieren. Beispielsweise könnte ein Roboter lernen, eine neue Umgebung mit der Rückmeldung eines menschlichen Bedieners auf dem besten Weg zum Aufnehmen zu navigieren oder die Objekte zu vermeiden.
Education : In der Bildung kann das menschliche Feedback dem Agenten helfen, die Schüler effektiver zu unterrichten. Zum Beispiel könnte ein KI-basierter Tutor Feedback von Lehrern verwenden, über die Lehrstrategien am besten mit verschiedenen Schülern funktionieren, um die Lernerfahrung zu personalisieren.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
Hybridflow: Ein flexibler und effizienter RLHF -Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Schlüsselwort: flexibel, effizient, RLHF -Framework
Code: Beamter
Alarm: Sprachmodelle über hierarchische Belohnungsmodellierung ausrichten
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
Schlüsselwort: hierarchische Belohnung, Aufgaben der Textgenerierung offen
Code: Beamter
TLCR: Token-Level kontinuierliche Belohnung für feinkörniges Verstärkungslernen durch menschliches Feedback
Eunseop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
Schlüsselwort: Token-Level kontinuierliche Belohnung, RLHF
Code: Beamter
Ausrichtung großer multimodaler Modelle mit sachlich erweiterter RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan GUI, Yu-Xiong Wang, Yiming Yang, Kurt Ketzer, Trevor Darrell
Schlüsselwort: sachlich erweitert RLHF, Vision & Sprache, Datensatz für menschliche Präferenz
Code: Beamter
Ausrichtung der direkten Großsprachenmodellausrichtung durch selbstbelohnende kontrastive Eingabeaufforderung Destillation
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
Schlüsselwort: Ohne menschliche Präferenzdaten, Selbstvertrauen, DPO
Code: Beamter
Arithmetische Kontrolle von LLMs für verschiedene Benutzerpräferenzen: Ausrichtung der Richtungspräferenz mit Multi-Objektiv-Belohnungen
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, Tong Zhang
Schlüsselwort: Benutzerpräferenz, Multi-Objektiv-Belohnungsmodell, Ableitungsstichproben-Finetuning
Code: Beamter
Zurück zu den Grundlagen: Überprüfung der Stiloptimierung des Stils für das Lernen aus menschlichem Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmetüstün, Sara Hooker
Schlüsselwort: Online -RL -Optimierung, niedrige Rechenkosten
Code: Beamter
Verbesserung großer Sprachmodelle durch feinkörniges Verstärkungslernen mit minimaler Bearbeitungsbeschränkungen
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junken Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
Schlüsselwort: Token-Ebene Belohnung, LLM
Code: Beamter
RLAIF vs. RLHF: Skalierung der Verstärkung Lernen aus menschlichem Feedback mit KI -Feedback
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
Schlüsselwort: RL aus KI -Feedback
Code: Beamter
Prinzipielle Strafmethoden für Strafe für Bilevel-Verstärkungslernen und RLHF
Han Shen, Zhuoran Yang, Tianyi Chen
Schlüsselwort: Bilevel -Optimierung
Code: Beamter
Dichte Belohnung für das freie Verstärkungslernen durch menschliches Feedback
Alex James Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Schlüsselwort: Belohnungsformung, RLHF
Code: Beamter
Ein minimaximalistischer Ansatz zum Verstärkungslernen durch menschliches Feedback
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
Schlüsselwort: Minimax-Gewinner, Self-Play-Präferenzoptimierung
Code: Beamter
RLHF-V: gegenüber vertrauenswürdigen Mllms durch Verhaltensausrichtung durch feinkörnige Korrektur-menschliches Feedback
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
Schlüsselwort: Multimodale Großsprachenmodelle, Halluzinationsproblem, Verstärkungslernen aus menschlichem Feedback
Code: Beamter
RLHF -Workflow: Von Belohnungsmodellierung bis Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
Schlüsselwort: Online iterative RLHF, Präferenzmodellierung, große Sprachmodelle
Code: Beamter
MaxMin-RLHF: Auf dem Weg zu einer gerechten Ausrichtung großer Sprachmodelle mit verschiedenen menschlichen Vorlieben
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
Schlüsselwort: Mischung aus Präferenzverteilungen, Maxmin -Ausrichtungsziel
Code: Beamter
Die Richtlinienoptimierung des Datensatzes Reset -Richtlinie für RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
Schlüsselwort: Dataset Reset -Richtlinienoptimierung
Code: Beamter
Eine dichte Belohnungsansicht zum Ausrichten von Text-to-Im-Im-Im-Im-Im---Verberufungs-Diffusion mit Präferenz
Shentao Yang, Tianqi Chen, Mingyuan Zhou
Schlüsselwort: RLHF für die Erzeugung von Text-zu-Image, dichte Belohnungsverbesserung der DPO, effiziente Ausrichtung
Code: Beamter
Selbstspiel-Feinabstimmung wandelt schwache Sprachmodelle in starke Sprachmodelle um
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
Schlüsselwort: Selbsteinstellung
Code: Beamter
RLHF entschlüsselt: Eine kritische Analyse des Verstärkungslernens aus menschlichem Feedback für LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
Schlüsselwort: RLHF, Oracular Belohnung, Belohnungsmodellanalyse, Umfrage
Konfrontation der Belohnung Überoptimierung für Diffusionsmodelle: eine Perspektive induktiver und Primatverzerrungen
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Schlüsselwort: Diffusionsmodelle, Ausrichtung, Verstärkungslernen, RLHF, Belohnung Überoptimierung, Vorurteile
Code: Beamter
Über diversifizierte Präferenzen der Ausrichtung des großsprachigen Modells
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan DU, Zegglin Xu
Schlüsselwort: gemeinsame Präferenz ausrichten, Belohnungsmodellierungsmetriken, LLM
Code: Beamter
Ausrichtung der Feedback des Publikums über die Belohnungsmodellierung der Verteilungspräferenz
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
Schlüsselwort: RLHF, Präferenzverteilung, Ausrichtung, LLM
Übereinstimmende Ausrichtung über ein Vorgänger hinaus: Multi-Objektive direkte Präferenzoptimierung
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
Schlüsselwort: Multi-Objektive RLHF ohne Belohnungsmodellierung, DPO
Code: Beamter
Emulierte Abhörung: Sicherheitsausrichtung für Großsprachenmodelle kann nach hinten losgehen!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiaoo
Schlüsselwort: LLM Inference-Time-Angriff, DPO, erzeugt schädliche LLMs ohne Training
Code: Beamter
Eine theoretische Analyse des Nash-Lernens aus menschlichem Feedback unter allgemeiner KL-regulärer Präferenz
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
Schlüsselwort: Game-basierte RLHF, Nash-Lernen, Ausrichtung unter Belohnungsmodellfreies Orakel
Minderung der Ausrichtungssteuer von RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanzon Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, Tong Zhang
Schlüsselwort: RLHF, Ausrichtungssteuer, katastrophales Vergessen
Trainingsdiffusionsmodelle mit Verstärkungslernen
Kevin Black, Michael Janner, Yilun du, Ilya Kostrikov, Sergey Levine
Schlüsselwort: Verstärkungslernen, RLHF, Diffusionsmodelle
Code: Beamter
Aligndiff: Ausrichtung verschiedener menschlicher Präferenzen über das Verhaltensmodell für verhaltensgängliches Diffusionsmodell
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
Schlüsselwort: Verstärkungslernen; Diffusionsmodelle; Rlhf; Präferenzausrichtung
Code: Beamter
Dichte Belohnung für das freie Verstärkungslernen durch menschliches Feedback
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Schlüsselwort: RLHF
Code: Beamter
Transformation und Kombination von Belohnungen für die Ausrichtung von Großsprachenmodellen
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex D'Amour, Sanmi Koyejo, Victor Veitch
Schlüsselwort: RLHF, Ausrichtung, LLM
Parameter effizientes Verstärkungslernen durch menschliches Feedback
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei Li , Abhinav Rastogi, Lucas Dixon
Schlüsselwörter: RLHF, Parameter -effiziente Methode, niedrige Rechenkosten, LLM, VLM
Verbesserung des Verstärkungslernens durch menschliches Feedback mit effizientem Belohnungsmodellensemble
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
Schlüsselwörter: RLHF, Belohnungsensemble, effiziente Ensemble -Methode
Ein allgemeines theoretisches Paradigma, um das Lernen aus menschlichen Vorlieben zu verstehen
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
Schlüsselwörter: RLHF, paarweise Präferenz
Feinkörniges menschliches Feedback gibt bessere Belohnungen für das Sprachmodelltraining
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
Schlüsselwort: RLHF, Satz auf Satzebene, LLM
Code: Beamter
Vorzugsbekämpfungspunkte zur Feinabstimmung auf Sprachmodell
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
Schlüsselwort: RLHF, Trainingsanleitung auf Token-Ebene, alternative/Online-Trainingsrahmen, minimalistische Schulungsziele
Code: Beamter
Fantastische Belohnungen und wie man sie zähm: Eine Fallstudie zum Lernen von Belohnungen für aufgabenorientierte Dialogsysteme
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
Schlüsselwort: RLHF, Genralisierte Belohnungsfunktion Lernen, Belohnungsfunktionsnutzung, aufgabenorientiertes Dialogsystem, Lernen zu Rang
Code: Beamter
Inverse Preference Learning: Präferenzbasierte RL ohne Belohnungsfunktion
Joey Hejna, Dorsa Sadigh
Schlüsselwort: Inverse Preference Lernen, ohne Belohnungsmodell
Code: Beamter
Alpacafarm: Ein Simulationsrahmen für Methoden, die aus menschlichem Feedback lernen
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy BA, Carlos Guestrin, Percy S. Liang, Tatsunori B. Hashimoto
Schlüsselwort: RLHF, Simulationsframework
Code: Beamter
Präferenzranking -Optimierung für die menschliche Ausrichtung
Feifan Lied, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, Houfg Wang
Schlüsselwort: Präferenzranking -Optimierung
Code: Beamter
Gegentliche Präferenzoptimierung
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan du
Schlüsselwort: RLHF, GAN, Gegnere Spiele
Code: Beamter
Iterative Präferenzlernen aus menschlich
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
Schlüsselwort: RLHF, iterative DPO, mathematische Grundlage
Probe effizientes Verstärkungslernen durch menschliches Feedback durch aktive Erkundung
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, Willie Neiswanger
Schlüsselwort: RLHF, Beispieleffizienz, Erkundung
Verstärkungslernen aus statistischem Feedback: Die Reise von AB -Tests bis zu Ant -Tests
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
Schlüsselwort: RLHF, AB -Test, RLSF
Eine Basisanalyse der Fähigkeit der Belohnmodelle, Fundamentmodelle unter Verteilungsverschiebung genau zu analysieren
Ben Pikus, Will Levine, Tony Chen, Sean Hendryx
Schlüsselwort: RLHF, OOD, Verteilungsverschiebung
Dateneffiziente Ausrichtung großer Sprachmodelle mit menschlichem Feedback durch natürliche Sprache
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
Schlüsselwort: RLHF, dateneffizient, Ausrichtung
Lassen Sie uns Schritt für Schritt verstärken
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
Schlüsselwort: RLHF, Argumentation
Direkte Präferenz-basierte politische Optimierung ohne Belohnungsmodellierung
Gaon AN, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-min Kim, Hyun Oh Lied
Schlüsselwort: RLHF ohne Belohnungsmodellierung, kontrastiv
Aligndiff: Ausrichtung verschiedener menschlicher Präferenzen über das Verhaltensmodell für verhaltensgängliches Diffusionsmodell
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
Schlüsselwort: RLHF, Ausrichtung, Diffusionsmodell
Eureka: Belohnungsdesign auf Menschenebene durch Codierung großer Sprachmodelle
Yecheng Jason MA, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi-Fan, Anima Anandkumar
Schlüsselwort: LLM basiert, Belohnungsfunktionen Design
Safer RLHF: Sicheres Verstärkungslernen aus menschlichem Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
Schlüsselwort: Verkauf RL, LLM Fein-Ture
Qualitätsvielfalt durch menschliches Feedback
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
Schlüsselwort: Qualitätsvielfalt, Diffusionsmodell
REMAX: Eine einfache, effektive und effiziente Verstärkungslernmethode zum Ausrichten von großsprachigen Modellen
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
Schlüsselwort: Computereffizienz, Varianz-Reduktionstechnik
Abstimmen von Computer Vision -Modellen mit Aufgabenprämien
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
Schlüsselwort: Belohnungsstimmung in Computer Vision
Die Weisheit des Nachhineins macht Sprachmodelle zu besser
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. Gonzalez
Schlüsselwort: Nachhinein -Anweisung Relabeling, RLHF -System, kein Wertnetzwerk erforderlich
Code: Beamter
Sprache angewiesene Verstärkungslernen für die Koordination von Mensch-AI
Hengyuan Hu, Dorsa Sadigh
Schlüsselwort: Human-AI-Koordination, Ausrichtung der menschlichen Präferenz, Anweisungen konditioniert RL
Sprachmodelle mit Offline -Verstärkungslernen aus menschlichem Feedback ausrichten
Jian Hu, Li Tao, June Yang, Chandler Zhou
Schlüsselwort: Ausrichtung der Entscheidungstransformator, Offline-Verstärkungslernen, RLHF-System
Präferenzranking -Optimierung für die menschliche Ausrichtung
Feifan Lied, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li und Houfg Wang
Schlüsselwort: Überwachung der menschlichen Präferenzausrichtung, Erweiterung der Präferenzranking
Code: Beamter
Überbrückung der Lücke: Eine Umfrage zum Integrieren von (menschlichem) Feedback für die Erzeugung der natürlichen Sprache
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José GC de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neuebig, André FT Martins
Schlüsselwort: Erzeugung der natürlichen Sprache, Integration des menschlichen Feedbacks, Feedback-Formalisierung und Taxonomie, KI-Feedback und Prinzipien basierende Urteile
GPT-4-Technischer Bericht
Openai
Schlüsselwort: Ein großflächiges, multimodales Modell, transformatorBasiertes Modell, fein abgestimmter verwendeter RLHF
Code: Beamter
Datensatz: Drop, Winogrande, Hellaswag, Arc, Humaneval, GSM8K, MMLU, Truthfulqa
FAF
Hanzon Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
Schlüsselwort: Ableitungsstiche -Finetuning, Alternative zu PPO, Diffusionsmodell
Code: Beamter
RRHF: Rangantworten auf die Ausrichtung von Sprachmodellen mit menschlichem Feedback ohne Tränen
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
Schlüsselwort: neues Paradigma für RLHF
Code: Beamter
Wenig-Shot-Präferenzlernen für Menschen in der Schleife RL
Joey Hejna, Dorsa Sadigh
Schlüsselwort: Präferenzlernen, interaktives Lernen, Multi-Task-Lernen, Erweiterung des Pools der verfügbaren Daten, indem Sie Menschen in der Schleife anzeigen
Code: Beamter
Bessere Ausrichtung von Text-zu-Image-Modellen mit menschlicher Präferenz
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
Schlüsselwort: Diffusionsmodell, Text-zu-Image, Ästhetik
Code: Beamter
Imagereward: Lernen und Bewertung menschlicher Vorlieben für die Erzeugung von Text-zu-Image
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
Schlüsselwort: Allzwecke Text-zu-Image-menschliche Präferenz RM, Bewertung von generativen Modellen von Text zu Image
Code: Beamter
Datensatz: Coco, DiffusionDB
Ausrichtung von Text-zu-Image-Modellen mithilfe menschlicher Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing DU, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
Schlüsselwort: Text-zu-Image, stabiles Diffusionsmodell, Belohnungsfunktion, die menschliches Feedback vorhersagt
Visuelles Chatgpt: Reden, Zeichnen und Bearbeiten mit visuellen Fundamentmodellen
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
Schlüsselwort: Visuelle Fundamentmodelle, visuelles Chatgpt
Code: Beamter
Vorabsprachmodelle mit menschlichen Vorlieben (PHF)
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
Schlüsselwort: Vorbereitung, Offline RL, Entscheidungstransformator
Code: Beamter
Sprachmodelle mit Präferenzen durch F-Divergence-Minimierung ausrichten (F-DPG)
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
Schlüsselwort: F-Divergenz, RL mit KL-Strafen
Prinzipielles Verstärkungslernen mit menschlichem Feedback von paarweisen oder k-weise Vergleiche
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
Schlüsselwort: pessimistisches MLE, Max-Entropy IRL
Die Fähigkeit zur moralischen Selbstkorrektur in großen Sprachmodellen
Anthropisch
Schlüsselwort: Verbessern Sie die Fähigkeit der moralischen Selbstkorrektur, indem Sie das RLHF-Training erhöhen
Datensatz; Grill
Ist Verstärkungslernen (nicht) für die Verarbeitung natürlicher Sprache?
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Schlüsselwort: Optimieren von Sprachgeneratoren mit RL, Benchmark, Performant RL -Algorithmus
Code: Beamter
Datensatz: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (EN-de), Narrativeqa, DailyDialog
Skalierungsgesetze für Belohnungsmodell Überoptimierung
Leo Gao, John Schulman, Jacob Hilton
Schlüsselwort: Gold Belohnungsmodell Trainer Belohnungsmodell, Datensatzgröße, Richtlinienparametergröße, Bon, PPO
Verbesserung der Ausrichtung von Dialogagenten durch gezielte menschliche Urteile (Sparrow)
Amelia Glaese, Nat Mcalese, Maja Trębacz et al.
Schlüsselwort: Informationssuchende Dialogagent, zerlegen Sie den guten Dialog in natürliche Sprachregeln, DPC, interagieren mit dem Modell, um eine bestimmte Regel zu verletzen (übergezogene Prüfung)
Datensatz: Natürliche Fragen, ELI5, Qualität, Triviaqa, Winobias, BBQ
Rote Teaming -Sprachmodelle zur Reduzierung von Schäden: Methoden, Skalierungsverhalten und gewonnene Erkenntnisse
Deep Ganguli, Liane Lovitt, Jackson Kernion et al.
Schlüsselwort: Red Team Sprachmodell, das Skalierungsverhalten untersuchen, Teaming -Datensatz lesen
Code: Beamter
Dynamische Planung im offenen Dialog mit Verstärkungslernen
Deborah Cohen, Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor, Craig Boutilier, Gal Elidan
Schlüsselwort: Echtzeit, offenes Dialogsystem, kombiniert die prägnante Einbettung des Gesprächszustands durch Sprachmodelle, Caql, CQL, Bert
Quark: Steuerbare Textgenerierung mit verstärktem Verlernen
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
Schlüsselwort: Feinabstimmung des Sprachmodells über Signale, was nicht zu tun ist, Entscheidungstransformator, LLM-Tuning mit PPO
Code: Beamter
Datensatz: WritingPrompts, SST-2, Wikitext-103
Training eines hilfsbereiten und harmlosen Assistenten mit Verstärkungslernen durch menschliches Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse et al.
Schlüsselwort: Harmlose Assistenten, Online -Modus, Robustheit des RLHF -Trainings, OOD -Erkennung.
Code: Beamter
Datensatz: Triviaqa, Hellaswag, ARC, Openbookqa, Lambada, Humaneval, MMLU, Truthfulqa
Unterrichtssprachmodelle zur Unterstützung von Antworten mit verifizierten Zitaten (Gophercite)
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat Mcalesee
Schlüsselwort: Generieren Sie Antworten, die spezifische Beweise zitieren und nicht sicher sind, wenn sie sich nicht sicher sind
Datensatz: Natürliche Fragen, ELI5, Qualität, Truthfulqa
Trainingssprachmodelle, um Anweisungen mit menschlichem Feedback zu befolgen (InstructGPT)
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Schlüsselwort: großes Sprachmodell, Sprachmodell mit menschlicher Absicht ausrichten
Code: Beamter
Datensatz: Truthfulqa, RealtuxicityPrompts
Konstitutionelle KI: Harmlosigkeit durch KI -Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion et al.
Schlüsselwort: RL aus KI-Feedback (RLAIF), Training eines harmlosen KI-Assistenten durch Selfimement, Stilkette, kontrollieren KI-Verhalten genauer
Code: Beamter
Entdeckung von Sprachmodellverhalten mit modellgeschriebenen Bewertungen
Ethan Perez, Sam Ringer, Kamilė lukošiūtė, Karina Nguyen, Edwin Chen et al.
Schlüsselwort: automatisch Bewertungen mit LMS generieren, mehr RLHF verschlechtert LMS, LM-geschriebene Bewertungen sind hohe Qualität
Code: Beamter
Datensatz: BBQ, Winogender Schemas
Nicht-Markovian-Belohnungsmodellierung aus Flugbahnbeamten durch interpretierbare Mehrfachinstanz-Lernen
Joseph Early, Tom Bewley, Christine Evers, Sarvapali Ramchurn
Schlüsselwort: Belohnungsmodellierung (RLHF), nicht-markover, mehrfach Instanzlernen, Interpretierbarkeit
Code: Beamter
WebGPT: Browser-unterstützte Fragen-Beantwortung mit menschlichem Feedback (WebGPT)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji et al.
Schlüsselwort: Modellsuche im Web und geben Sie Referenz , Nachahmung von Lernen , BC, Langformfrage
Datensatz: ELI5, Triviaqa, Truthfulqa
Rekursiv zusammenfassen Bücher mit menschlichem Feedback
Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stieennon, Ryan Lowe, Jan Leike, Paul Christiano
Schlüsselwort: Modell, das auf kleine Aufgabe ausgebildet ist, um die menschliche Bewertung breiterer Aufgabe zu unterstützen, BC
Datensatz: Booksum, narrativeqa
Überprüfung der Schwächen des Verstärkungslernens für die Übersetzung neuronaler Maschinen
Samuel Kiegeland, Julia Kreutzer
Schlüsselwort: Der Erfolg des politischen Gradienten ist eher auf Belohnung als an der Form der Ausgangsverteilung, der maschinellen Übersetzung, der NMT, der Domänenanpassung zurückzuführen
Code: Beamter
Datensatz: WMT15, IWSLT14
Lernen, aus dem menschlichen Feedback zusammenzufassen
Nisan Stieennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
Schlüsselwort: Pflege der zusammenfassenden Qualität, Schulungsverlust wirken sich auf das Modellverhalten aus, das Belohnungsmodell verallgemeinert neue Datensätze
Code: Beamter
Datensatz: TL; DR, CNN/DM
Feinabstimmungssprachmodelle aus menschlichen Vorlieben
Daniel M. Ziegler, Nisan Stieennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Schlüsselwort: Belohnung lernen für Sprache, fortgesetzter Text mit positiver Gefühle, zusammenfassender Aufgabe, physischer Beschreibungs
Code: Beamter
Datensatz: TL; DR, CNN/DM
Skalierbare Agentenausrichtung durch Belohnungsmodellierung: eine Forschungsrichtung
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
Schlüsselwort: Problemausrichtungsproblem, Belohnung aus der Interaktion lernen, die Belohnung mit RL optimieren, rekursive Belohnungsmodellierung
Code: Beamter
Env: Atari
Belohnen Sie das Lernen aus menschlichen Vorlieben und Demonstrationen in Atari
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
Schlüsselwort: Experte Demonstration Trajektorienpräferenzen belohnen Hacking -Problem, Rauschen im menschlichen Etikett
Code: Beamter
Env: Atari
Deep Tamer: Interaktive Agentformung in hochdimensionalen Zustandsräumen
Garrett Warnell, Nicholas Waytowich, Vernon Lawhern, Peter Stone
Schlüsselwort: Hochdimensionszustand, nutzen Sie die Eingabe des menschlichen Trainers
Code: Dritter
Env: Atari
Tiefes Verstärkung lernen aus menschlichen Vorlieben
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
Schlüsselwort: Erforschen Sie das Ziel, das in den menschlichen Vorlieben zwischen Paaren der Segmentierung von Trajektorien definiert ist, komplexere als menschliches Feedback
Code: Beamter
Env: Atari, Mujoco
Interaktives Lernen aus dem politisch abhängigen menschlichen Feedback
James Macglashan, Mark K Ho, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
Schlüsselwort: Die Entscheidung wird eher durch die aktuelle Richtlinie als durch menschliches Feedback beeinflusst. Lernen Sie aus politisch abhängiger Feedback, das zu einem lokalen Optimal konvergiert
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl: Vulkanmotor -Verstärkung für LLM
Bytedance Seed MLSYS -Team & HKU: Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Schlüsselwort: flexibel, effizient, RLHF -Framework
Aufgaben: RLHF, Argumentation Aufgaben einschließlich Mathematik und Code.
OpenRLHF
OpenRLHF
Schlüsselwort: 70B, RLHF, DeepSpeed, Ray, Vllm
Aufgabe: Ein benutzerfreundliches, skalierbares und leistungsstarkes RLHF-Framework (Unterstützung von 70B+ Full Tuning & Lora & Mixtral & KTO).
Palm + RLHF - Pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociear Ashimine, Eric Alcaide
Schlüsselwort: Transformers, Palmarchitektur
Datensatz: Enwik8
LM-Human-Präferenzen
Daniel M. Ziegler, Nisan Stieennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Schlüsselwort: Belohnung lernen für Sprache, fortgesetzter Text mit positiver Gefühle, zusammenfassender Aufgabe, physischer Beschreibungs
Datensatz: TL; DR, CNN/DM
Human-Feedback nach der Einbringung
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Schlüsselwort: großes Sprachmodell, Sprachmodell mit menschlicher Absicht ausrichten
Datensatz: Truthfulqa RealtoxicityPrompts
Transformator -Verstärkungslernen (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al.
Schlüsselwort: Zug LLM mit RL, PPO, Transformator
Aufgabe: IMDB -Gefühl
Transformator -Verstärkungslernen X (TRLX)
Jonathan Tow, Leandro von Werra et al.
Schlüsselwort: Distributed Training Framework, T5-basierte Sprachmodelle, Zug LLM mit RL, PPO, ILQL
Aufgabe: Fine Tuning LLM mit RL mit der bereitgestellten Belohnungsfunktion oder des Datensatzes für Belohnungsmarkierung
RL4LMS (eine modulare RL-Bibliothek, um Sprachmodelle mit menschlichen Vorlieben zu übereinstimmen)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Schlüsselwort: Optimieren von Sprachgeneratoren mit RL, Benchmark, Performant RL -Algorithmus
Datensatz: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (EN-de), Narrativeqa, DailyDialog
Lamda-rlhf-pytorch
Phil Wang
Schlüsselwort: Lamda, Aufmerksamkeitsmechanismus
Aufgabe: Open-Source-Implementierung von Google von Google Lamda Research Paper in Pytorch
Textrl
Eric Lam
Schlüsselwort: SuggingFace's Transformator
Aufgabe: Textgenerierung
Env: PFRL, Fitnessstudio
Minrlhf
Thomfoster
Schlüsselwort: PPO, minimale Bibliothek
Aufgabe: Bildungszwecke
Deepspeed-Chat
Microsoft
Schlüsselwort: Erschwingliches RLHF -Training
Dromedar
IBM
Schlüsselwort: Minimale menschliche Überwachung, selbst ausgerichtet
Aufgabe: selbst ausgerichtetes Sprachmodell, das mit minimaler menschlicher Aufsicht trainiert wurde
FG-RLHF
Zeqiu Wu, Yushi Hu, Weijia Shi et al.
Schlüsselwort: feinkörniges RLHF, das nach jedem Segment eine Belohnung bietet und mehrere RMS enthält, die mit verschiedenen Rückkopplungsarten verbunden sind
Aufgabe: Ein Framework, das Schulungen und Lernen aus Belohnungsfunktionen ermöglicht, die in der Dichte und mehrerer RMS-Safe-RLHF feinkörnig sind
Xuehai Pan, Ruiyang Sun, Jiaming Ji, et al.
Schlüsselwort: Unterstützen Sie beliebte vorgebrachte Modelle, großer Datensatz mit menschlichem markiert
Aufgabe: Eingeschränkte wertgemäße LLM über Safe RLHF
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Ben Mann, Deep Ganguli
Schlüsselwort: Datensatz für menschliche Präferenz, rote Teaming-Daten, maschinell geschrieben
Aufgabe: Open-Source-Datensatz für menschliche Präferenzdaten über Hilfsbereitschaft und Harmlosigkeit
Stanford Human Preferences Dataset (SHP)
Ethayarajh, Kawin und Zhang, Heidi und Wang, Yizhong und Jurafsky, Dan
Schlüsselwort: Natürlich vorkommende und von Menschen geschriebene Datensatz, 18 verschiedene Themenbereiche
Aufgabe: Für das Training von RLHF -Belohnungsmodellen verwendet werden
Eingabeaufforderung
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong et al.
Schlüsselwort: Auf die englische Datensätze gefordert und ein Datenbeispiel in die natürliche Sprache zubereitet
Aufgabe: Toolkit zum Erstellen, Teilen und Verwenden natürlicher Sprachaufforderungen
Ressourcensammlungen (Structured Knowledge Grounding)
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
Schlüsselwort: Strukturiertes Wissen Erdung
Aufgabe: Die Sammlung von Datensätzen bezieht sich auf strukturierte Wissens Erdung
Die Flan -Sammlung
Longpre Shayne, Hou Le, Vu Tu et al.
Aufgabe: Die Sammlung kompiliert Datensätze aus Flan 2021, P3, übernatürliche Anweisungen
RLHF-Belohnungsdatensätze
Yiting Xie
Schlüsselwort: Maschinengeschriebener Datensatz
webgpt_comparisons
Openai
Schlüsselwort: menschlich geschriebenes Datensatz, Langform-Frage-Beantwortung
Aufgabe: trainieren Sie ein Langform -Frage -Beantwortungsmodell, um sich an die menschlichen Vorlieben auszurichten
SUFFERARIZE_FROM_FEEDBACK
Openai
Schlüsselwort: menschlich geschriebenes Datensatz, Zusammenfassung
Aufgabe: trainieren
Dahoas/Synthetic-Instruct-Gptj-Pairwise
Dahoas
Schlüsselwort: menschlich geschriebenes Datensatz, synthetischer Datensatz
Stabile Ausrichtung - Ausrichtung des Lernens in sozialen Spielen
Ruibo liu, Ruixin (Ray) Yang, Qiang Peng
Schlüsselwort: Interaktionsdaten, die für das Ausrichtungstraining verwendet werden, in Sandbox ausgeführt werden
Aufgabe: Trainieren Sie die aufgezeichneten Interaktionsdaten in simulierten sozialen Spielen
Lima
Meta Ai
Schlüsselwort: Ohne RLHF nur wenige sorgfältig kuratierte Eingabeaufforderungen und Antworten
Aufgabe: Datensatz zum Training des Lima -Modells
[OpenAI] CHATGPT: Sprachmodelle für den Dialog optimieren
[Umarmendes Gesicht] Illustrieren des Verstärkungslernens durch menschliches Feedback (RLHF)
[Zhihu] 通向 agi 之路 : 大型语言模型 (llm) 技术精要
[Zhihu] 大语言模型的涌现能力 : 现象与解释
[Zhihu] 中文 HH-rlhf 数据集上的 ppo 实践
[W & B Voll verbundene] Verstärkungslernen aus menschlichem Feedback (RLHF) verstehen
[DeepMind] durch menschliches Feedback lernen
[Begriff] 深入理解语言模型的突现能力
[Begriff] 拆解追溯 GPT-3.5 各项能力的起源
[GIST] Verstärkungslernen für Sprachmodelle
[YouTube] John Schulman - Verstärkungslernen aus menschlichem Feedback: Fortschritte und Herausforderungen
[OpenAI / Arize] Openai über Verstärkungslernen mit menschlichem Feedback
[Engen] Leitfaden zum Verstärkungslernen aus menschlichem Feedback (RLHF) für Computer Vision
[Wexun Wang] Übersicht über RL (HF)+LLM
Türkisch
Unser Ziel ist es, dieses Repo noch besser zu machen. Wenn Sie an einem Beitrag interessiert sind, finden Sie hier die Anweisungen im Beitrag.
Awesome RLHF wird unter der Apache 2.0 -Lizenz veröffentlicht.


