scratchplot story generation
1.0.0
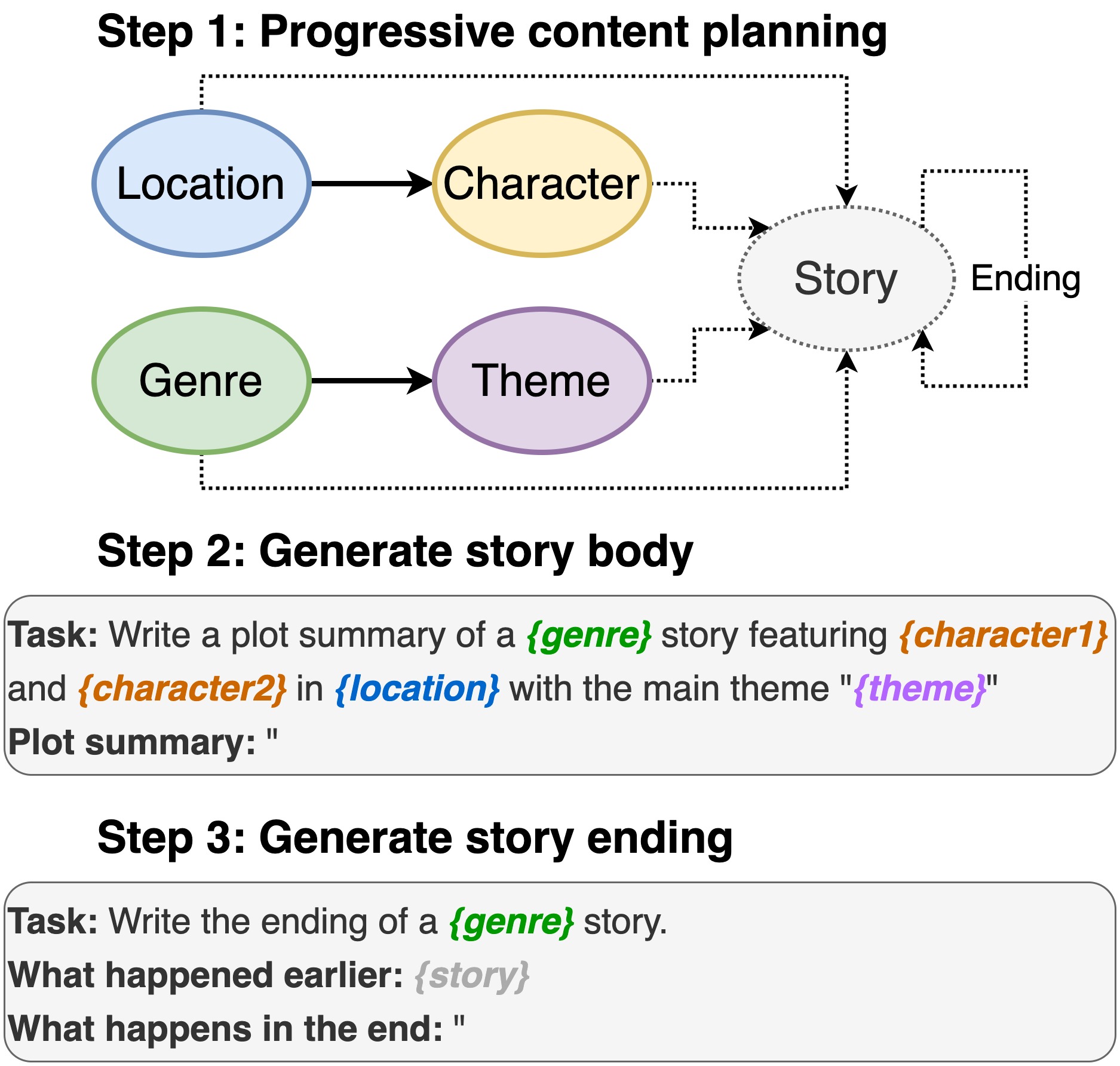
Dieses Repository enthält den Code für das Schreiben von Plot-Schreiben von vorgeborenen Sprachmodellen , die in INLG 2022 angezeigt werden. In dem Papier wird eine Methode vorgestellt, mit der zunächst ein PLM ein Auffordern eines Inhaltsplans auffordert. Dann erzeugen wir den Körper der Geschichte und beenden den Inhaltsplan. Darüber hinaus verfolgen wir einen Generate-and-Rank-Ansatz, indem wir zusätzliche PLMs verwenden, um die generierten (Geschichte, Ending) Paare zu bewerten.
Dieses Repo stützt sich stark auf Dino. Da wir einige geringfügige Änderungen vorgenommen haben, schließen wir den vollständigen Code für die Benutzerfreundlichkeit ein.
Einschließlich Ort, Besetzung, Genre und Thema.
sh run_plot_static_gpu.shDie Inhaltsplanelemente werden einmal generiert und gespeichert. Bei der Erzeugung der Geschichten Stichproben aus den Offline-erzeugten Handlungselementen.
sh run_plot_dynamic_gpu_single.shsh run_plot_dynamic_gpu_batch.sh--no_cuda zu allen Befehlen hinzu, die dino.py aufrufen.Benötigt Python3. Getestet auf Python 3.6 und 3.8.
pip3 install -r requirements.txt import nltk
nltk . download ( 'punkt' )
nltk . download ( 'stopwords' )Wenn Sie den Code in diesem Repository verwenden, zitieren Sie bitte das folgende Papier:
@inproceedings{jin-le-2022-plot,
title = "Plot Writing From Pre-Trained Language Models",
author = "Jin, Yiping and Kadam, Vishakha and Wanvarie, Dittaya",
booktitle = "Proceedings of the 15th International Natural Language Generation conference",
year = "2022",
address = "Maine, USA",
publisher = "Association for Computational Linguistics"
}
Wenn Sie Dino für andere Aufgaben verwenden, zitieren Sie bitte auch das folgende Papier:
@article{schick2020generating,
title={Generating Datasets with Pretrained Language Models},
author={Timo Schick and Hinrich Schütze},
journal={Computing Research Repository},
volume={arXiv:2104.07540},
url={https://arxiv.org/abs/2104.07540},
year={2021}
}


