text embeddings inference
v1.5.1
Eine lodernde schnelle Inferenzlösung für Texteinbettungsmodelle.
Benchmark für Baai/Bge-Base-en-V1.5 auf einem Nvidia A10 mit einer Sequenzlänge von 512 Token:
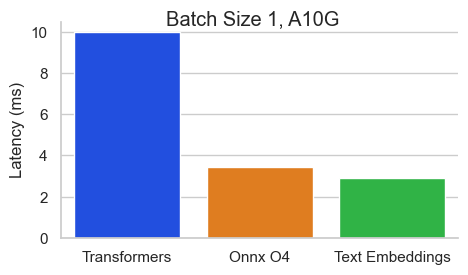
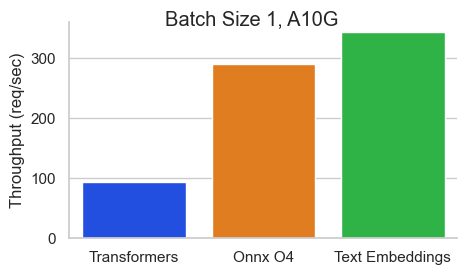
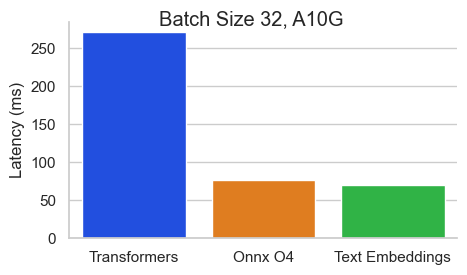
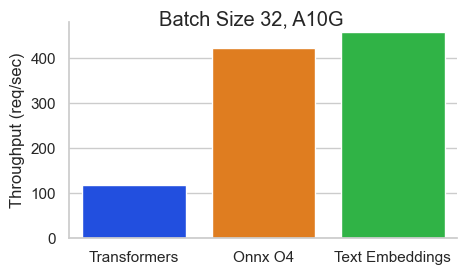
Texteinbettungsinferenz (TEI) ist ein Toolkit zum Bereitstellen und Servieren von Open -Source -Texteinbettungen und Sequenzklassifizierungsmodellen. TEI ermöglicht eine Hochleistungsextraktion für die beliebtesten Modelle, einschließlich Flagembedding, Ember, GTE und E5. Tei implementiert viele Merkmale wie:
Die Inferenz von Texteinbettungen unterstützt derzeit NOMIC-, Bert-, Camembert-, XLM-Roberta-Modelle mit absoluten Positionen, Jinabert-Modell mit Alibi-Positionen und Mistral-, Alibaba GTE- und QWEN2-Modellen mit Seilpositionen.
Im Folgenden finden Sie einige Beispiele für die aktuell unterstützten Modelle:
| MTEB Rang | Modellgröße | Modelltyp | Modell ID |
|---|---|---|---|
| 1 | 7b (sehr teuer) | Mistral | Salesforce/SFR-Embedding-2_R |
| 2 | 7b (sehr teuer) | Qwen2 | Alibaba-NLP/GTE-QWEN2-7B-Instruct |
| 9 | 1,5B (teuer) | Qwen2 | Alibaba-NLP/GTE-QWEN2-1.5B-Instruct |
| 15 | 0,4b | Alibaba Gte | Alibaba-NLP/gte-large-en-v1.5 |
| 20 | 0,3b | Bert | Wobei ich/VAE-large-v1 |
| 24 | 0,5b | XLM-Roberta | intfloat/mehrsprachig-e5-large-struktur |
| N / A | 0,1b | Nomicbert | nomic-ai/nomic-embed-text-v1 |
| N / A | 0,1b | Nomicbert | nomic-ai/nomic-embed-text-v1.5 |
| N / A | 0,1b | Jinabert | Jinaai/Jina-Embeddings-V2-Base-en |
| N / A | 0,1b | Jinabert | Jinaai/Jina-Embeddings-V2-Base-Code |
Um die Liste der am besten darstellenden Text -Einbettungsmodelle zu untersuchen, besuchen Sie die massive Rangliste der Textbetting -Benchmark -Benchmark.
Die Inferenz von Texteinbettungen unterstützt derzeit Camembert und XLM-Roberta-Sequenzklassifizierungsmodelle mit absoluten Positionen.
Im Folgenden finden Sie einige Beispiele für die aktuell unterstützten Modelle:
| Aufgabe | Modelltyp | Modell ID |
|---|---|---|
| Neu rangieren | XLM-Roberta | Baai/bge-reranker-large |
| Neu rangieren | XLM-Roberta | Baai/BGE-Reranker-Base |
| Neu rangieren | Gte | Alibaba-NLP/GTE-Multiviling-Lerner-Base |
| Stimmungsanalyse | Roberta | Samlowe/roberta-base-go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelUnd dann können Sie Anfragen wie wie
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json 'Hinweis: Um GPUs zu verwenden, müssen Sie das NVIDIA -Container -Toolkit installieren. Nvidia -Treiber auf Ihrer Maschine müssen mit CUDA -Version 12.2 oder höher kompatibel sein.
Um alle Optionen zu sehen, um Ihre Modelle zu bedienen:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
Texteinbettungsinferenz wird mit mehreren Docker -Bildern versandt, mit denen Sie ein bestimmtes Backend abzielen können:
| Architektur | Bild |
|---|---|
| CPU | ghcr.io/huggingface/text-embeding-inference:cpu-1.5 |
| Volta | Nicht unterstützt |
| Turing (T4, RTX 2000 -Serie, ...) | ghcr.io/huggingface/text-embeding-inference:turing-1.5 (experimentell) |
| Ampere 80 (A100, A30) | ghcr.io/huggingface/text-embeding-inference:1.5 |
| Ampere 86 (A10, A40, ...) | ghcr.io/huggingface/text-embeding-inference:86-1.5 |
| Ada Lovelace (RTX 4000 -Serie, ...) | ghcr.io/huggingface/text-embeding-inference:89-1.5 |
| Hopper (H100) | ghcr.io/huggingface/text-embeding-inference:Hopper-1.5 (experimentell) |
Warnung : Die Aufmerksamkeit der Flash wird standardmäßig für das Turing -Image ausgeschaltet, da es an Präzisionsproblemen leidet. Sie können die Aufmerksamkeit von Flash V1 mit der Variablen USE_FLASH_ATTENTION=True Environment" verwenden.
Sie können die OpenAPI-Dokumentation der text-embeddings-inference REST-API mit der Route /docs konsultieren. Die Swagger-UI ist auch unter: https://huggingface.github.io/text-embeding-inference erhältlich.
Sie haben die Möglichkeit, die Umgebungsvariable HF_API_TOKEN für die Konfiguration des von text-embeddings-inference verwendeten Token zu verwenden. Auf diese Weise können Sie Zugriff auf geschützte Ressourcen erhalten.
Zum Beispiel:
HF_API_TOKEN=<your cli READ token>oder mit Docker:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelUm Texteinbettungsinferenz in einer Luft-Get-Umgebung einzusetzen, laden Sie zuerst die Gewichte herunter und montieren Sie sie dann mit einem Volumen in den Behälter.
Zum Beispiel:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference V0.4.0 Unterstützung für Modelle Camembert-, Roberta-, XLM-Roberta- und GTE-Sequenzklassifizierungsmodelle. Re-Rankers-Modelle sind Sequenzklassifizierungs-Cross-Encoder-Modelle mit einer einzigen Klasse, die die Ähnlichkeit zwischen einer Abfrage und einem Text bewertet.
Sehen Sie sich diesen Blogpost vom Lamaindex-Team an, um zu verstehen, wie Sie Re-Rankers-Modelle in Ihrer RAG-Pipeline verwenden können, um die nachgelagerte Leistung zu verbessern.
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelUnd dann können Sie die Ähnlichkeit zwischen einer Abfrage und einer Liste von Texten mit:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' Sie können auch klassische Sequenzklassifizierungsmodelle wie SamLowe/roberta-base-go_emotions verwenden:
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model Sobald Sie das Modell bereitgestellt haben, können Sie den predict -Endpunkt verwenden, um die Emotionen zu erhalten, die mit einer Eingabe am meisten zugeordnet sind:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'Sie können das Splade -Pooling für Bert und Distilbert Maskedlm Architekturen aktivieren:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade Sobald Sie das Modell bereitgestellt haben, können Sie den Endpoint /embed_sparse -Endpunkt verwenden, um die spärliche Einbettung zu erhalten:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' text-embeddings-inference wird mit einer verteilten Verfolgung unter Verwendung von Opentelemetry instrumentiert. Sie können diese Funktion verwenden, indem Sie die Adresse auf einen OTLP-Kollektor mit dem Argument --otlp-endpoint einstellen.
text-embeddings-inference bietet eine GRPC-API als Alternative zur Standard-HTTP-API für Hochleistungsbereitstellungen. Die API -Protobuf -Definition finden Sie hier.
Sie können die GRPC -API verwenden, indem Sie jedes TEI -Docker -Bild das -grpc -Tag hinzufügen. Zum Beispiel:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed Sie können sich auch für die lokale Installation text-embeddings-inference entscheiden.
Zuerst Rost installieren:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shDann rennen:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalSie können jetzt Text -Einbettungsinferenz auf CPU mit:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Hinweis: Auf einigen Maschinen benötigen Sie möglicherweise auch die OpenSSL -Bibliotheken und GCC. Auf Linux -Maschinen rennen Sie:
sudo apt-get install libssl-dev gcc -yGPUs mit CUDA -Rechenfunktionen <7,5 werden nicht unterstützt (V100, Titan V, GTX 1000 -Serie, ...).
Stellen Sie sicher, dass Sie Cuda und die Nvidia -Treiber installieren lassen. NVIDIA -Treiber auf Ihrem Gerät müssen mit CUDA -Version 12.2 oder höher kompatibel sein. Sie müssen auch die Nvidia -Binärdateien zu Ihrem Weg hinzufügen:
export PATH= $PATH :/usr/local/cuda/binDann rennen:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresSie können jetzt Texteinbettungsinferenz für GPU mit:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Sie können den CPU -Behälter mit:
docker build .Um die CUDA -Container zu erstellen, müssen Sie die Berechnung der GPU kennen, die Sie zur Laufzeit verwenden werden.
Dann können Sie den Container mit:
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capWie hier mit MPS-fähig erklärt wird, wird Metal / MPS nicht über Docker unterstützt. Als solche wird die Inferenz von CPU gebunden und höchstwahrscheinlich ziemlich langsam sein, wenn dieses Docker -Bild auf einer M1/M2 -Arm -CPU verwendet wird.
docker build . -f Dockerfile --platform=linux/arm64


