super json mode
1.0.0
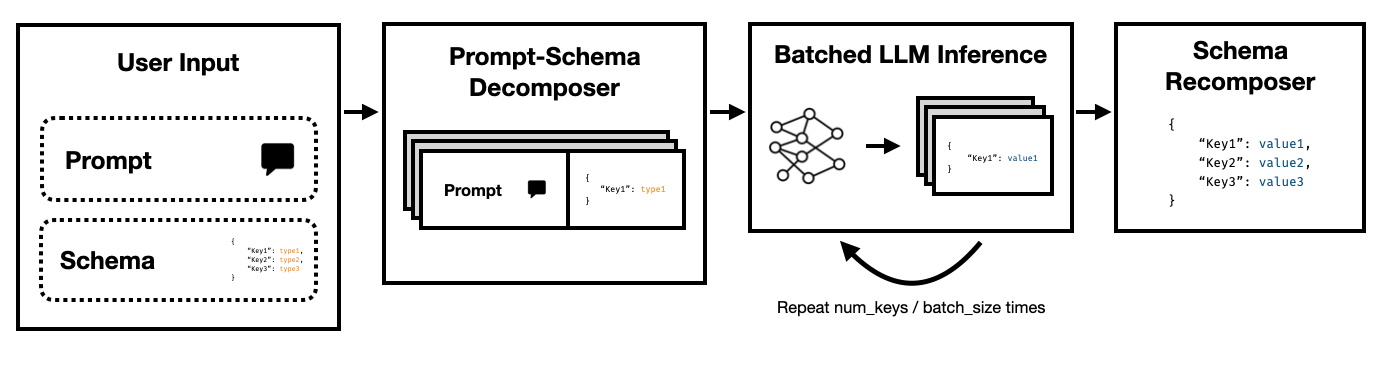
Der Super JSON -Modus ist ein Python -Framework, das die effiziente Schaffung der strukturierten Ausgabe aus einem LLM ermöglicht, indem ein Zielschema in Atomkomponenten aufgeteilt und dann parallel über Generationen ausgeführt wird.
Es unterstützt beide hochmodernen LLMs über OpenAIs Legacy Completexions -API- und Open -Source -LLMs wie über umarmende Gesichtstransformatoren und VllM . Weitere LLMs werden bald unterstützt!
Im Vergleich zu einer naiven Pipeline der JSON -Generation, die sich auf Aufforderung und HF -Transformatoren stützt, kann der Super JSON -Modus Ausgänge bis zu 10x schneller erzeugen. Es ist auch deterministischer und ist im Vergleich zur naiven Erzeugung weniger wahrscheinlich auf Parsingprobleme.
Die Installation ist einfach: pip install super-json-mode
Strukturierte Ausgangsformate wie JSON oder YAML haben eine inhärente parallele oder hierarchische Struktur.
Betrachten Sie die folgende unstrukturierte Passage (erzeugt von GPT-4):
Willkommen in der 123 Azure Lane, einer atemberaubenden Residenz in San Francisco mit einem fantastischen zeitgenössischen Design, das jetzt für 2.500.000 US -Dollar auf dem Markt ist. Diese Eigenschaft verteilt über eine luxuriöse 3000 Quadratmeter große Fläche Raffinesse und Komfort, um ein wirklich einzigartiges Lebenserlebnis zu schaffen.
Unser exklusiver Residenz ist ein idyllisches Zuhause für Familien oder Fachkräfte und ist mit fünf geräumigen Schlafzimmern ausgestattet, die jeweils Wärme und moderne Eleganz sitzen. Die Schlafzimmer sind sorgfältig geplant, um reichlich natürliches Licht und großzügigen Stauraum zu ermöglichen. Mit drei elegant gestalteten Badezimmern garantiert die Residenz den Bewohnern Bequemlichkeit und Privatsphäre.
Der große Eingang führt Sie zu einem geräumigen Wohnbereich und bietet ein hervorragendes Ambiente für Versammlungen oder einen ruhigen Abend am Feuer. Die Küche des Küchenchefs umfasst hochmoderne Geräte, maßgefertigte Schränke und wunderschöne Granit-Arbeitsplatten, die es zu einem Traum für alle machen, die gerne kochen.
Wenn wir address , square footage , number of bedrooms , number of bathrooms und price unter Verwendung eines LLM extrahieren möchten, können wir das Modell bitten, ein Schema gemäß der Beschreibung auszufüllen.
Ein potenzielles Schema (wie ein pydantisches Objekt) könnte so aussehen:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
Und eine gültige Ausgabe könnte ungefähr so aussehen:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
Der offensichtliche Ansatz besteht darin, das Schema in der Eingabeaufforderung zu nisten und das Modell zu bitten, es auszufüllen. So extrahieren derzeit die meisten Teams derzeit mithilfe von LLMs strukturierte Ausgabe aus unstrukturiertem Text.
Dies ist jedoch aus drei Gründen ineffizient.
Beachten Sie, wie jeder dieser Schlüssel voneinander unabhängig ist. Der Super JSON-Modus nutzt die schnelle Parallelität , indem jedes Schlüsselwertpaar im Schema als separate Anfrage behandelt wird. Zum Beispiel können wir die num_baths extrahieren, ohne die address bereits generiert zu haben!
Bitten Sie ein Modell, um JSON von Grund auf neu zu generieren, und konsumiert unnötig Token (und darum) auf vorhersehbare Syntax wie Zahnspangen und Schlüsselnamen, die bereits in der Ausgabe erwartet werden. Dies ist ein starker Vorgänger für die Generation, die wir zur Verbesserung der Latenzen verwenden können.
LLMs sind peinlich parallel und es ist viel schneller als in einer seriellen Reihenfolge. Somit können wir das Schema über mehrere Abfragen aufteilen. Das LLM füllt dann das Schema für jeden unabhängigen Schlüssel parallel aus und emittiert weit weniger Token in einem einzigen Pass, wodurch viel schnellere Inferenzzeiten ermöglicht werden.
Führen Sie den folgenden Befehl aus:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
Wir haben versucht, den Super JSON -Modus super einfach zu verwenden. Weitere Beispiele und vLLM -Verwendung finden Sie im examples -Ordner.
Verwenden von OpenAI und gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Verwenden von Mistral 7B mit Umarmungsface -Transformatoren:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } Es gibt viele Funktionen, die den Super -JSON -Modus verbessern können. Hier sind einige Ideen.
Qualitative Ausgangsanalyse : Wir haben Leistungsbenchmarks durchgeführt, aber wir sollten einen strengeren Ansatz für die Beurteilung der qualitativen Ausgaben des Super JSON -Modus finden.
Strukturierte Probenahme : Im Idealfall sollten wir die LLM -Protokolls maskieren, um die Typenbeschränkungen zu erzwingen, ähnlich wie Jsonformer. Es gibt ein paar Pakete, die dies bereits tun, und diese sollten entweder unsere parallelisierte JSON -Generationspipeline integrieren oder wir sollten sie in den Super -JSON -Modus aufbauen.
Abhängigkeitsgrafikunterstützung : Der Super JSON -Modus hat einen sehr offensichtlichen Fall: Wenn ein Schlüssel eine Abhängigkeit von einem anderen Schlüssel hat. Betrachten Sie einen JSON -Blob mit zwei Schlüsseln, thought und response . Diese Art der gewünschten Ausgabe ist bei großer Sprachmodellen üblich, und es ist sehr klar, dass die response vom thought abhängt. Wir sollten in der Lage sein, ein Diagramm von Abhängigkeiten und Stapelanforderungen in einer Weise zu übergeben, dass übergeordnete Ausgaben ausgefüllt und an Kinderschema -Elemente weitergegeben werden.
Lokale Modellunterstützung : Der Super JSON -Modus funktioniert am besten in lokalen Situationen, in denen die Chargengröße im Allgemeinen beträgt 1. Sie können das Stapel ausnutzen, um die Latenz zu verringern, ähnlich wie die spekulative Decodierung. Llama.cpp ist das wichtigste Framework für lokale Modelle + CPU -Inferenz. Ich würde dies gerne mit Ollama umsetzen, wenn möglich.
TRT-LLM-Unterstützung : VLLM ist großartig und einfach zu bedienen, aber im Idealfall integrieren wir uns in ein viel leistungsfähigeres Framework wie TRT-Llm.
Wir schätzen es, wenn Sie bitte dieses Repo zitieren würden, wenn Sie die Bibliothek für Ihre Arbeit nützlich fanden:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
Dieses Projekt wurde für CS 229: Systeme für maschinelles Lernen erstellt. Vielen Dank an das Lehrteam und TAS für ihre Anleitung in diesem Projekt.


