Recurrent LLM
1.0.0
Die Open Source LLM -Implementierung von Papier:
RecurrentGPT: Interaktive Erzeugung von (willkürlich) langen Text .
[Papier] [Arxiv] [Huggingface] [Offical]
Durch den Kontext des Transformators mit fester Größe ist GPT-Modelle unfähig, willkürlich lange Text zu generieren. In diesem Artikel stellen wir RecurrentGpt vor, ein sprachbasiertes Simulacrum des Rezidivmechanismus in RNNs. RecurrentGPT basiert auf einem großen Sprachmodell (LLM) wie ChatGPT und verwendet natürliche Sprache, um den langen Kurzzeitgedächtnismechanismus in einem LSTM zu simulieren. Bei jedem Zeitschritt generiert RecurrentGPT einen Textabsatz und aktualisiert seinen auf der Festplatte und der Eingabeaufforderung gespeicherten langweiligen Langzeitgedächtnis. Dieser Rezidivmechanismus ermöglicht es wiederkehrend, Texte von willkürlicher Länge ohne Vergessen zu erzeugen. Da menschliche Benutzer die Erinnerungen für natürliche Sprache leicht beobachten und bearbeiten können, ist RecurrentGPT interpretierbar und ermöglicht die interaktive Erzeugung langer Text. RecurrentGPT ist ein erster Schritt in Richtung computergestützter Schreibsysteme der nächsten Generation, die über die lokalen Bearbeitungsvorschläge hinausgehen. Zusätzlich zur Herstellung von AI-generierten Inhalten (AIGC) demonstrieren wir auch die Möglichkeit, RecurrentGpt als interaktive Fiktion zu verwenden, die direkt mit den Verbrauchern interagiert. Wir nennen diese Verwendung generativer Modelle von "AI als Inhalt" (aiac), von dem wir glauben, dass es die nächste Form der konventionellen AIGC ist. Wir zeigen ferner die Möglichkeit, recurrentGpt zu verwenden, um eine personalisierte interaktive Fiktion zu erstellen, die direkt mit Lesern interagiert, anstatt mit Schriftstellern zu interagieren. Im weiteren Sinne demonstriert RecurrentGPT den Nutzen von Ideen von populären Modellentwürfen in kognitiven Wissenschaft und Deep -Lernen für LLMs.
Transformator 的固定尺寸上下文使得 gpt 模型无法生成任意长的文本。在本文中 , 我们介绍了 recurrentgpt , 一个基于语言的模拟 rnns 中的递归机制。Recurrentgpt 建立在大型语言模型( llm )之上 , 如 Chatgpt , lstm 中的长短时记忆机制。在每个时间段 , recurrentgpt 生成一段文字 , 并更新其基于语言的长短时记忆 , 分别存储在硬盘和提示器上。这种递归机 分别存储在硬盘和提示器上。这种递归机 分别存储在硬盘和提示器上。这种递归机制使 recurrentgpt 能够生成任意长度的文本而不被遗忘。由于人类用户可以很容易地观察和编辑自然语言记忆 , 因此 recurrentgpt 是可解释的 , 并能互动地生成长文本。 并能互动地生成长文本。Recurrentgpt 是朝着超越本地编辑建议的下一代计算机辅助写作系统迈出的第一步。除了制作人工智能生成的内容( AIGC) , 我们还展示了使用 recurrentgpt 作为直接与消费者互动的互动小说的可能性。我们称这种生成模型的使用为"Ai als Inhalt" (aiac) , 我们认为这是传统 我们认为这是传统 我们认为这是传统 我们认为这是传统 的下一个形式。我们进一步展示了使用 recurrentgpt 创造个性化互动小说的可能性 这种小说直接与读者互动 这种小说直接与读者互动 , 而不是与作者互动。更广泛地说 , recurrentgpt 证明了从认知科学和深度学习中流行的模型设计中借用思想来提示 llm 的效用。
pip install transformers@git+https://github.com/huggingface/transformers.git
pip install peft@git+https://github.com/huggingface/peft.git
pip install accelerate@git+https://github.com/huggingface/accelerate.git
pip install bitsandbytes==0.39.0
pip install -U flagai
pip install bminf
[global_config.py]
lang_opt = "zh" # zh or en. make English or Chinese Novel
llm_model_opt = "openai" # default is openai, it also can be other open-source LLMs as below
Sie sollten zuerst einen OpenAI -API -Schlüssel anwenden. Dann
export OPENAI_API_KEY = "your key"
Laden Sie das Vicuna -Modell herunter. und konfigurieren Sie es in Modellen/vicuna_bin.py
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path , trust_remote_code = True )
model_config = AutoConfig . from_pretrained ( model_name_or_path , trust_remote_code = True )
model = AutoModel . from_pretrained ( model_name_or_path , config = model_config , trust_remote_code = True ) tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/baichuan-7B" , device_map = "auto" , trust_remote_code = True ) loader = AutoLoader (
"lm" ,
model_dir = state_dict ,
model_name = model_name ,
use_cache = True ,
fp16 = True )
model = loader . get_model ()
tokenizer = loader . get_tokenizer ()
model . eval ()Wenn Sie BMINF verwenden möchten, fügen Sie den Code wie unten hinzu:
with torch . cuda . device ( 0 ):
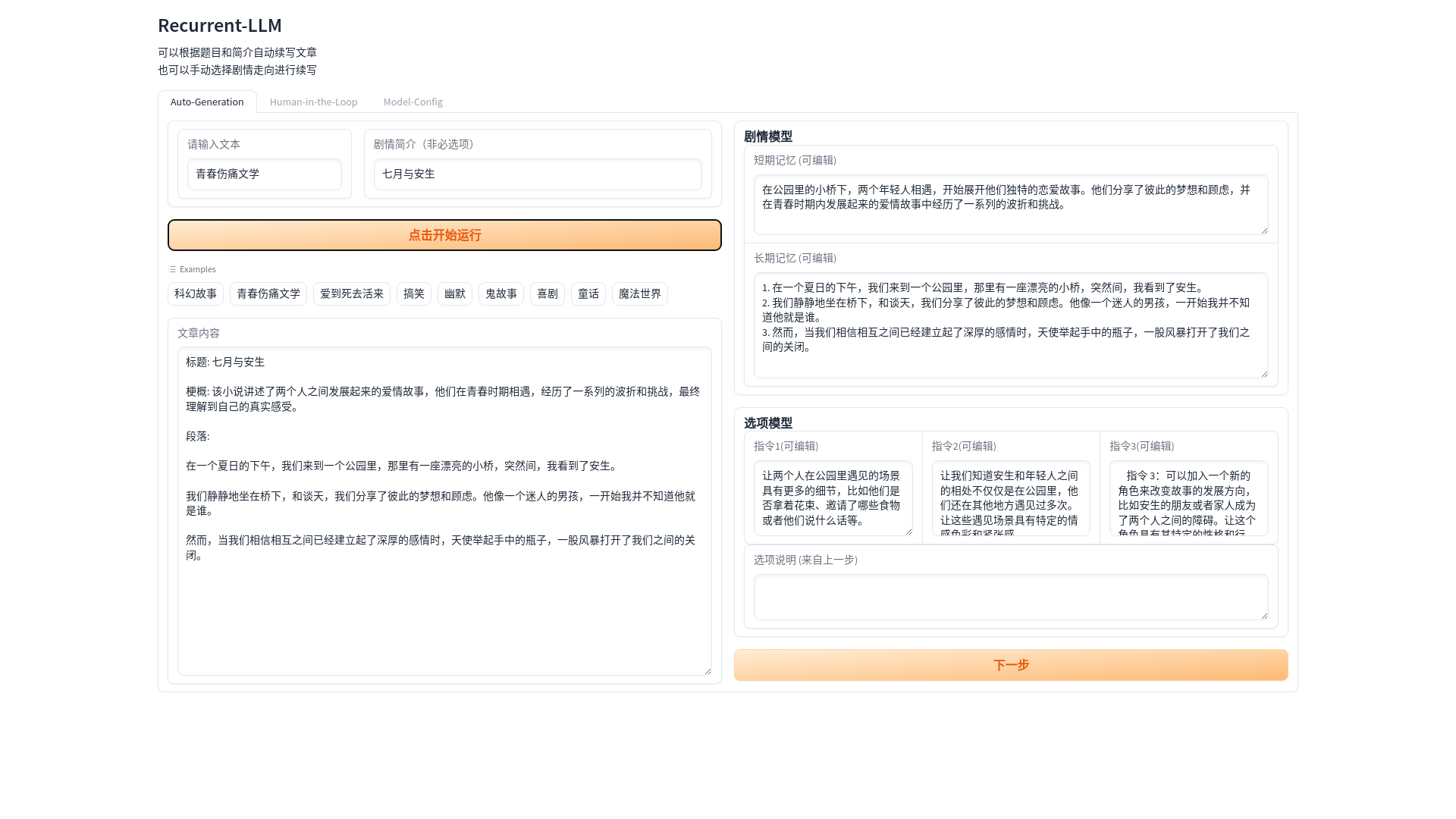
model = bminf . wrapper ( model , quantization = False , memory_limit = 2 << 30 ) python gradio_server.py
Wenn dieses Projekt Ihnen hilft, Zeit für die Entwicklung zu verkürzen, können Sie mir eine Tasse Kaffee geben :)
Alipay (支付宝)

Wechatpay (微信)

Mit © Kun


