Apache Kylin analytical data warehouse v4.0.3 official version
4.0.3
Apache Kylin: A sub-second query tool for extremely large-scale data
Downcodes editor
Apache Kylin is an open source, distributed analytical data warehouse that provides SQL query interface and multidimensional analysis (OLAP) capabilities on top of Hadoop/Spark, and can efficiently process extremely large-scale data. Originally developed by eBay and contributed to the open source community, it completes queries on massive data in sub-seconds.
Kylin’s three major steps
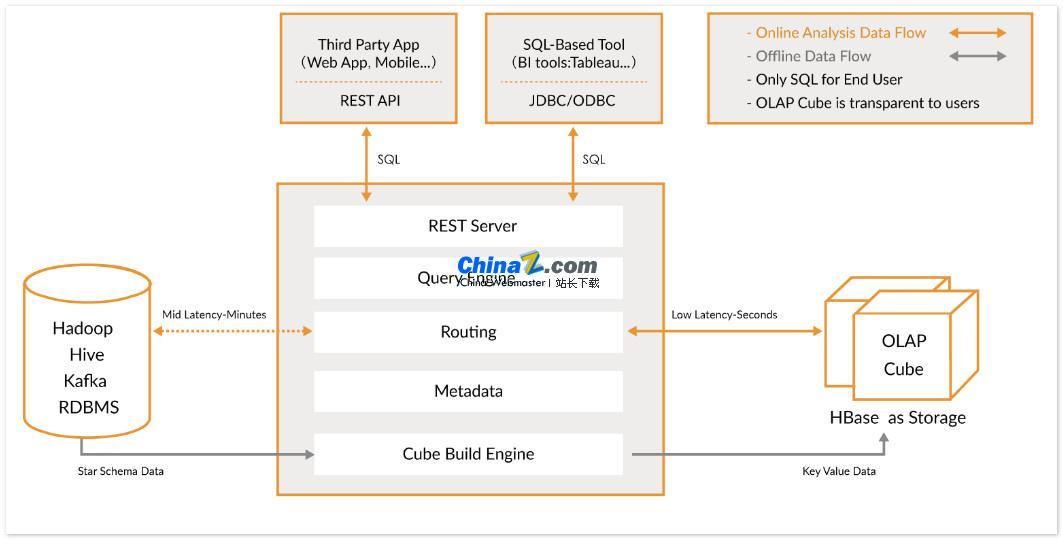
Kylin allows users to implement sub-second queries on very large data sets in just three steps:
1. Define a star or snowflake model on your data set: First, you need to define a star or snowflake model to describe your data set. This will help Kylin understand the relationship between data and thereby optimize query performance.
2. Build Cube: Build Cube on the defined data table. Cube is the unit for Kylin to precompute and store data, which can greatly improve query speed.
3. Use standard SQL query: Use standard SQL syntax to query Cube through ODBC, JDBC or RESTFUL API. Kylin can return query results in sub-seconds.
Kylin’s integration capabilities
Kylin integrates with a variety of data visualization tools, such as Tableau, Power BI, etc. Users can use these BI tools to analyze Hadoop data and visually display data insights.
Summarize
Apache Kylin is a powerful tool that can help users complete queries on extremely large-scale data in sub-seconds. Its ease of use, scalability, and efficiency make it ideal for handling large-scale data analysis.