serl
1.0.0

Webpage: https://serl-robot.github.io/
SERL provides a set of libraries, env wrappers, and examples to train RL policies for robotic manipulation tasks. The following sections describe how to use SERL. We will illustrate the usage with examples.
?: SERL video, additional video on sample efficient RL.
Table of Contents
SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning
Installation
Overview and Code Structure
Quick Start with SERL in Sim
Run with Franka Arm on Real Robot
Contribution
Citation
For people who use SERL for tasks involving controlling the gripper (e.g.,pick up objects), we strong recommend adding a small penalty to the gripper action change, as it will greatly improves the training speed. For detail, please refer to: PR #65.
Further, we also recommend providing interventions online during training in addition to loading the offline demos. If you have a Franka robot and SpaceMouse, this can be as easy as just touching the SpaceMouse during training.
We fixed a major issue in the intervention action frame. See release v0.1.1 Please update your code with the main branch.
Setup Conda Environment:create an environment with
conda create -n serl python=3.10
Install Jax as follows:
For CPU (not recommended):
pip install --upgrade "jax[cpu]"
For GPU:
pip install --upgrade "jax[cuda12]==0.4.28" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
For TPU
pip install --upgrade "jax[tpu]" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
See the Jax Github page for more details on installing Jax.
Install the serl_launcher
cd serl_launcher pip install -e .pip install -r requirements.txt
SERL provides a set of common libraries for users to train RL policies for robotic manipulation tasks. The main structure of running the RL experiments involves having an actor node and a learner node, both of which interact with the robot gym environment. Both nodes run asynchronously, with data being sent from the actor to the learner node via the network using agentlace. The learner will periodically synchronize the policy with the actor. This design provides flexibility for parallel training and inference.
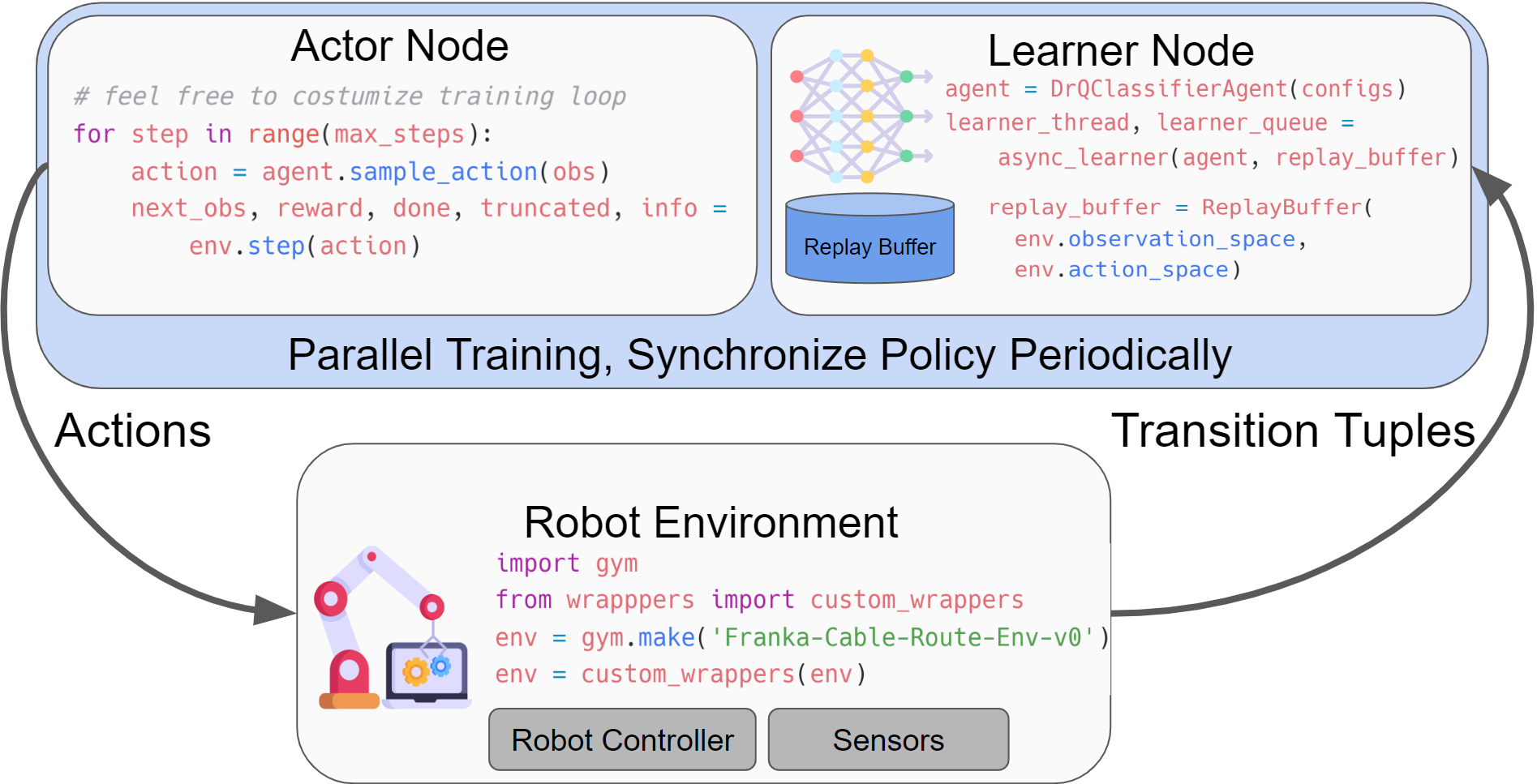
Table for code structure
| Code Directory | Description |
|---|---|
| serl_launcher | Main code for SERL |
| serl_launcher.agents | Agent Policies (e.g. DRQ, SAC, BC) |
| serl_launcher.wrappers | Gym env wrappers |
| serl_launcher.data | Replay buffer and data store |
| serl_launcher.vision | Vision related models and utils |
| franka_sim | Franka mujoco simulation gym environment |
| serl_robot_infra | Robot infra for running with real robots |
| serl_robot_infra.robot_servers | Flask server for sending commands to robot via ROS |
| serl_robot_infra.franka_env | Gym env for real franka robot |
We provide a simulated environment for trying out SERL with a franka robot.
Check out the Quick Start with SERL in Sim
Training from state observation example
Training from image observation example
Training from image observation with 20 demo trajectories example
We provide a step-by-step guide to run RL policies with SERL on the real Franka robot.
Check out the Run with Franka Arm on Real Robot
Peg Insertion ?
PCB Component Insertion
Cable Routing ?
Object Relocation ?️
We welcome contributions to this repository! Fork and submit a PR if you have any improvements to the codebase. Before submitting a PR, please run pre-commit run --all-files to ensure that the codebase is formatted correctly.
If you use this code for your research, please cite our paper:
@misc{luo2024serl, title={SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning}, author={Jianlan Luo and Zheyuan Hu and Charles Xu and You Liang Tan and Jacob Berg and Archit Sharma and Stefan Schaal and Chelsea Finn and Abhishek Gupta and Sergey Levine}, year={2024}, eprint={2401.16013}, archivePrefix={arXiv}, primaryClass={cs.RO}} 

