DeveloperGPT
v0.7.5
DeveloperGPT is a LLM-powered command line tool that enables natural language to terminal commands and in-terminal chat. DeveloperGPT is powered by Google Gemini 1.5 Flash by default but also supports Google Gemini 1.0 Pro, OpenAI GPT-3.5 & GPT-4, Anthropic Claude 3 Haiku & Sonnet, open LLMs (Zephyr, Gemma, Mistral) hosted on Hugging Face, and quantized Mistral-7B-Instruct running offline on-device.
As of June 2024, DeveloperGPT is completely free to use when using Google Gemini 1.5 Pro (used by default) or Google Gemini 1.0 Pro at up to 15 requests per minute.
Switch between different LLMs using the --model flag: developergpt --model [llm_name] [cmd, chat]
| Model(s) | Source | Details |
|---|---|---|
| Gemini Pro, Gemini Flash (default) | Google Gemini 1.0 Pro, Gemini 1.5 Flash | Free (up to 15 requests/min), Google AI API Key Required |
| GPT35, GPT4 | OpenAI | Pay-Per-Usage, OpenAI API Key Required |
| Haiku, Sonnet | Anthropic (Claude 3) | Pay-Per-Usage, Anthropic API Key Required |
| Zephyr | Zephyr7B-Beta | Free, Open LLM, Hugging Face Inference API |
| Gemma, Gemma-Base | Gemma-1.1-7B-Instruct, Gemma-Base | Free, Open LLM, Hugging Face Inference API |
| Mistral-Q6, Mistral-Q4 | Quantized GGUF Mistral-7B-Instruct | Free, Open LLM, OFFLINE, ON-DEVICE |
| Mistral | Mistral-7B-Instruct | Free, Open LLM, Hugging Face Inference API |
mistral-q6 and mistral-q4 are Quantized GGUF Mistral-7B-Instruct LLMs running locally on-device using llama.cpp (Q6_K quantized and Q4_K quantized models respectively). These LLMs can run on machines without a dedicated GPU - see llama.cpp for more details.DeveloperGPT has 2 main features.
Usage: developergpt cmd [your natural language command request]
# Example
$ developergpt cmd list all git commits that contain the word llm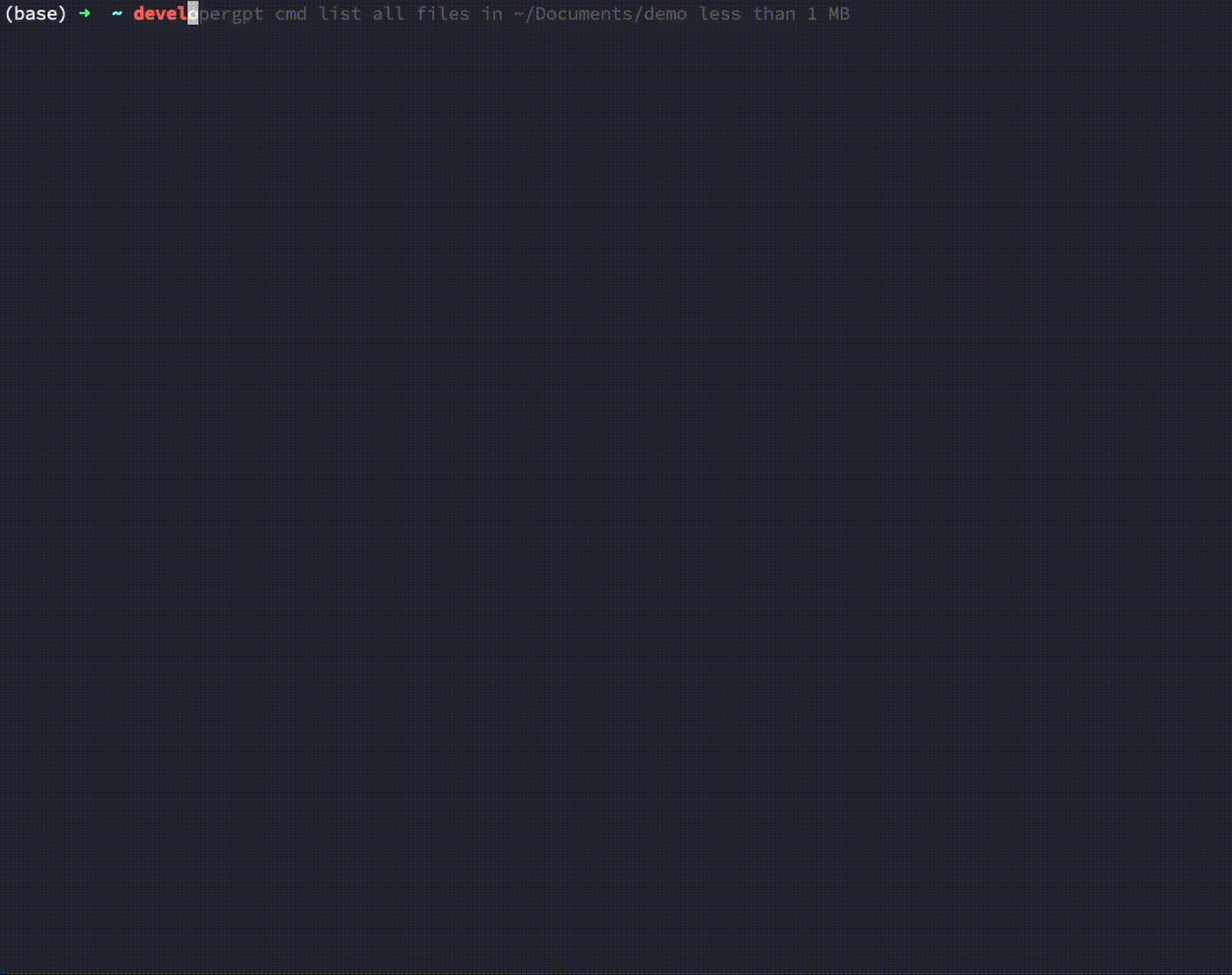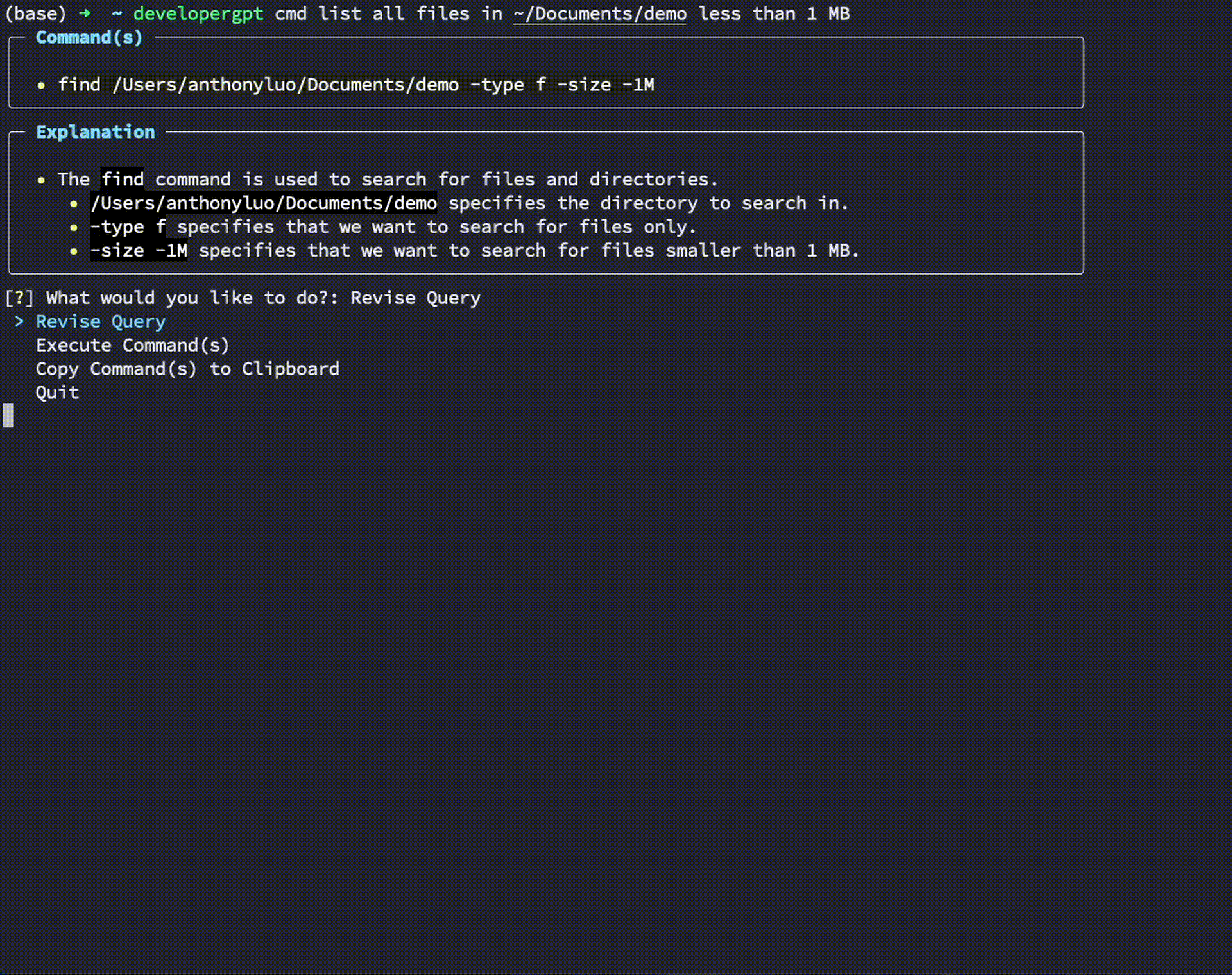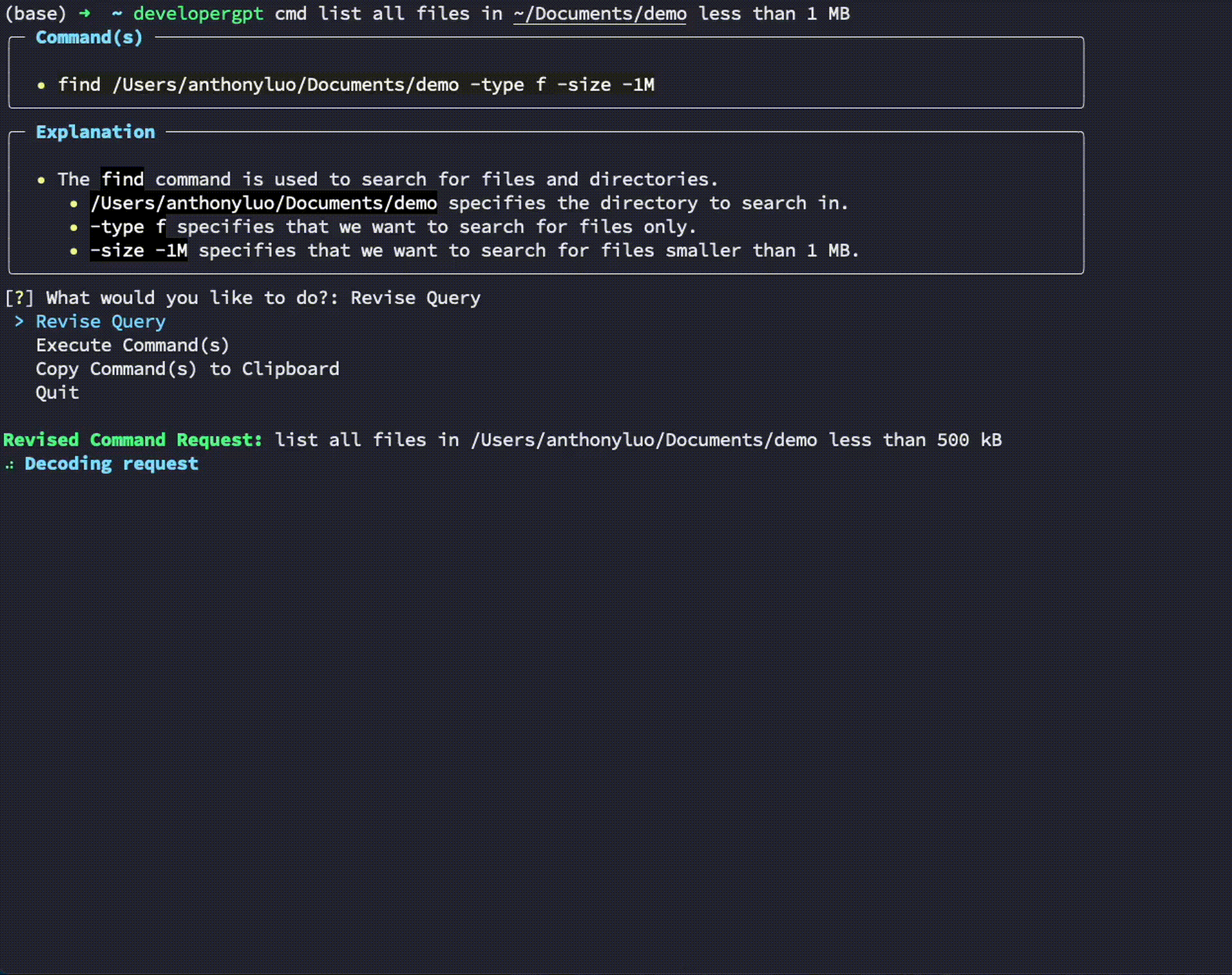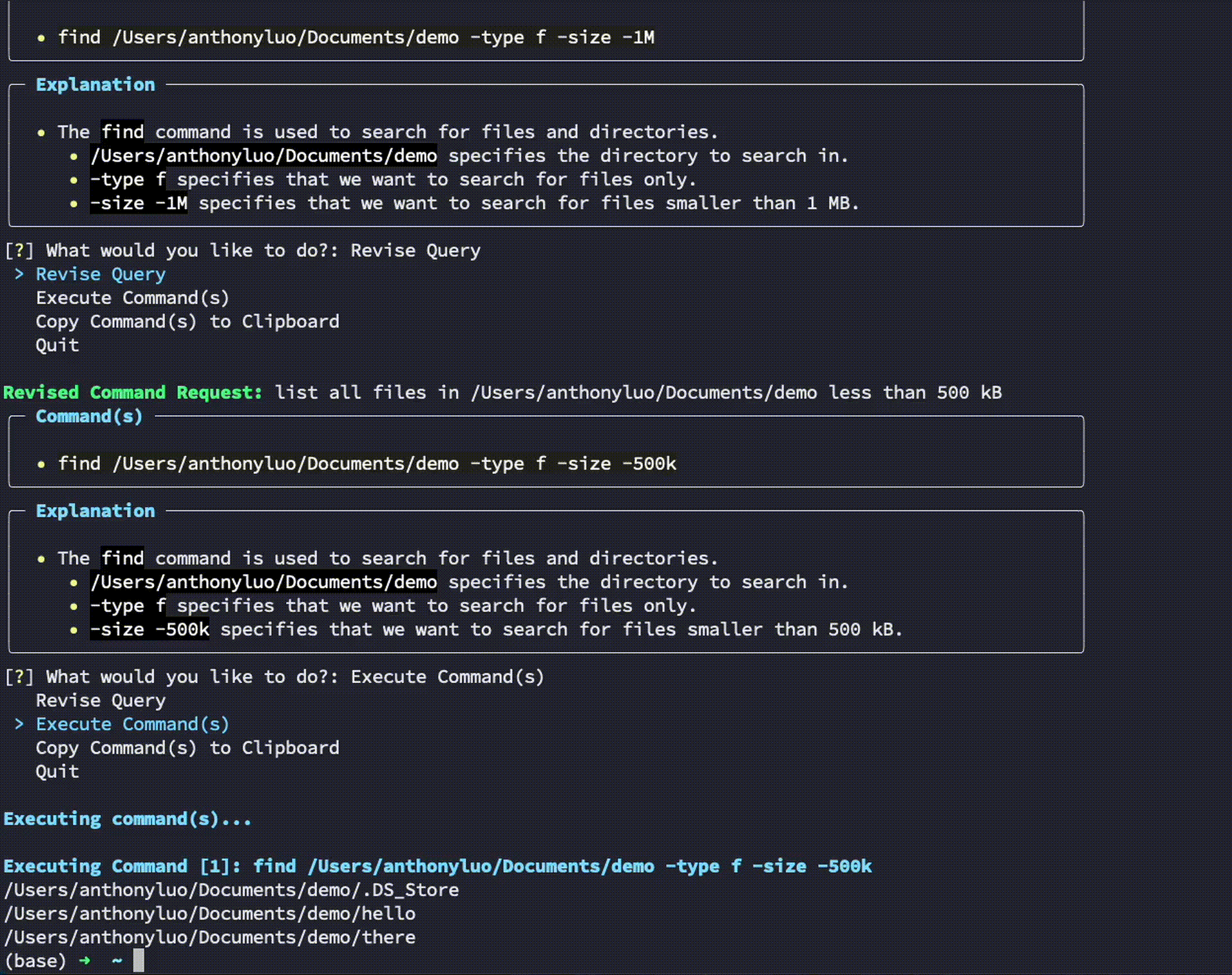
Use developergpt cmd --fast to get commands faster without any explanations (~1.6 seconds with --fast vs. ~3.2 seconds with regular on average). Commands provided by DeveloperGPT in --fast mode may be less accurate - see DeveloperGPT Natural Language to Terminal Command Accuracy for more details.
# Fast Mode: Commands are given without explanation for faster response
$ developergpt cmd --fast [your natural language command request]Use developergpt --model [model_name] cmd to use a different LLM instead of Gemini Flash (used by default).
# Example: Natural Language to Terminal Commands using the GPT-3.5 instead of Gemini Flash
$ developergpt --model gpt35 cmd [your natural language command request]Usage: developergpt chat
# Chat with DeveloperGPT using Gemini 1.5 Flash (default)
$ developergpt chat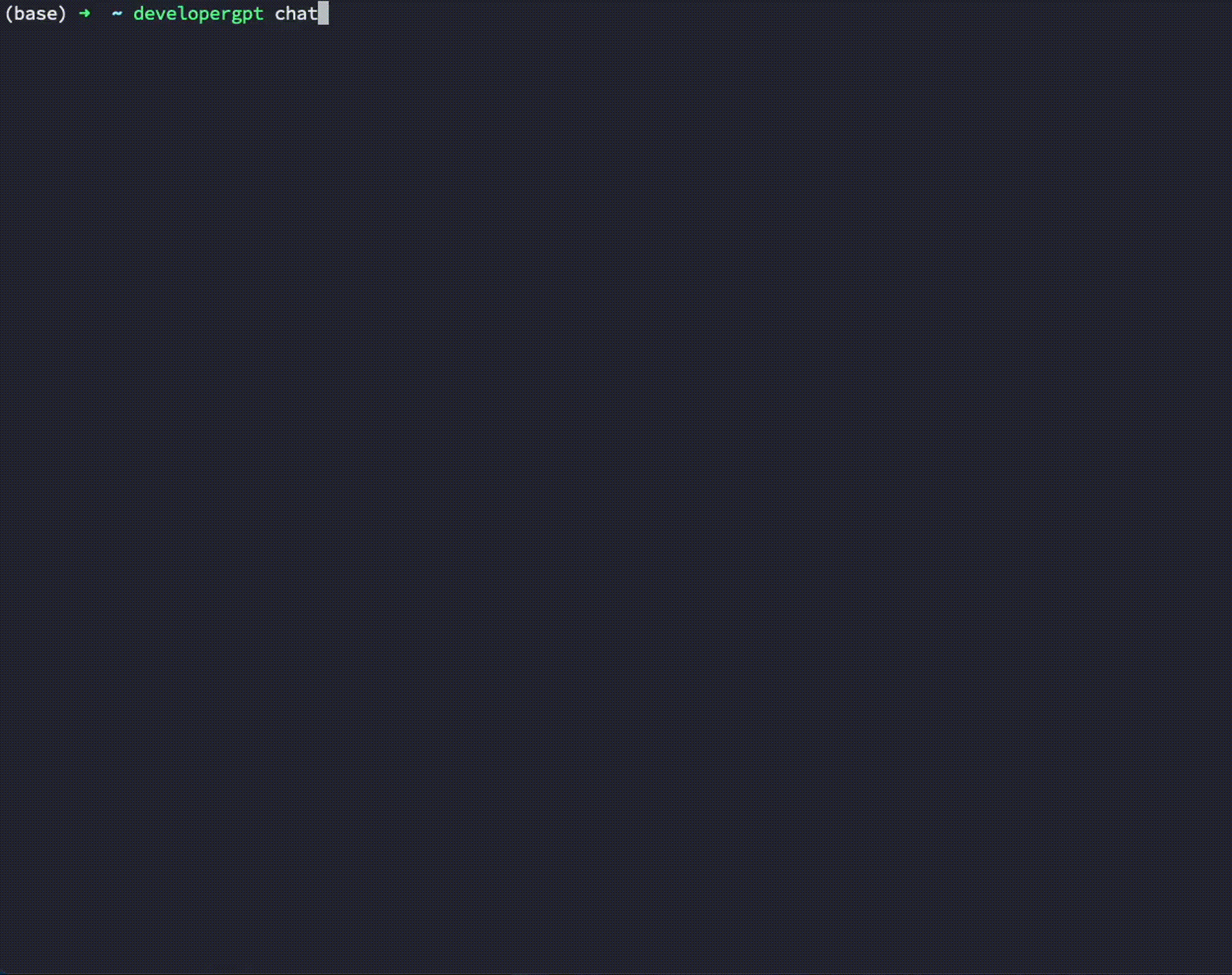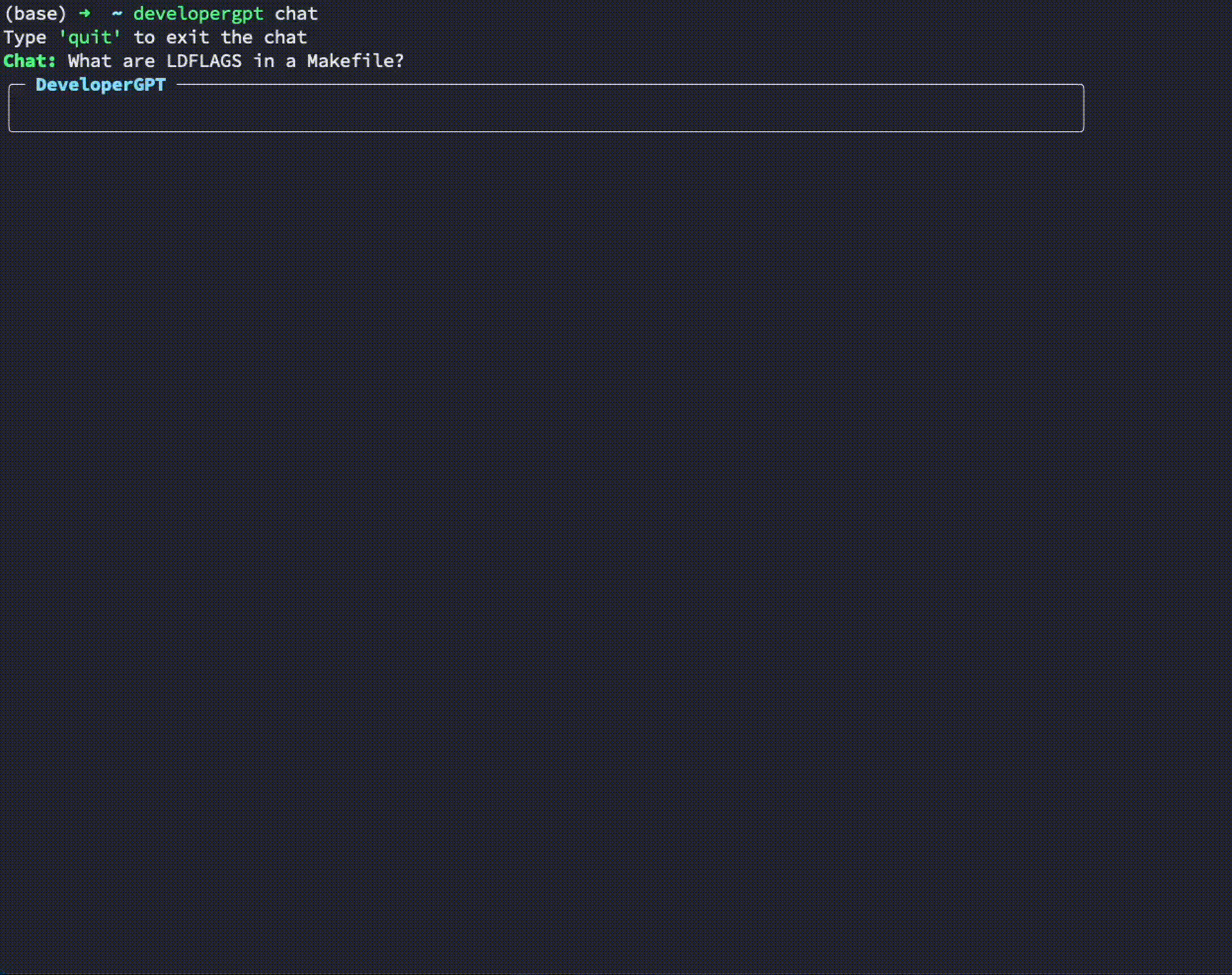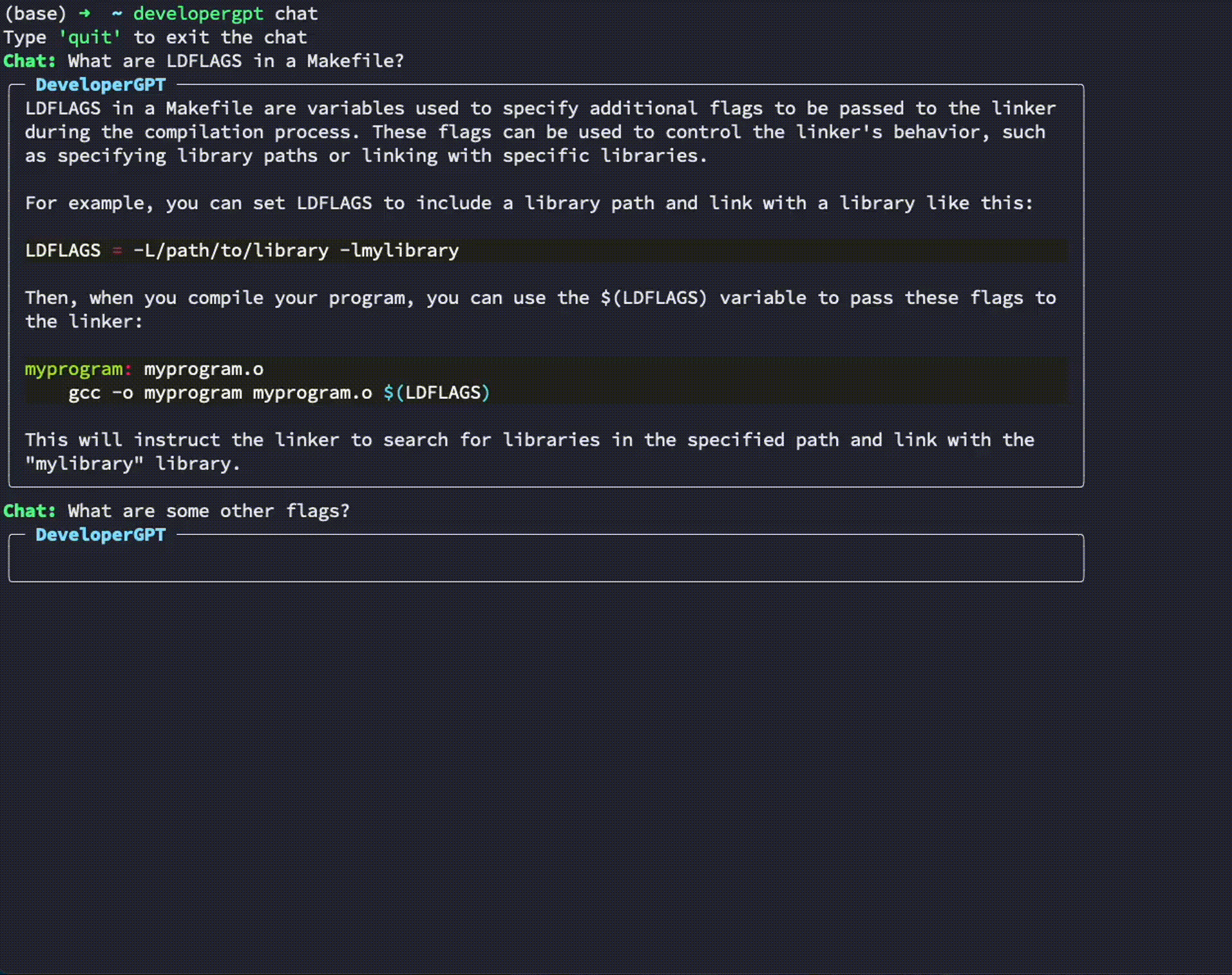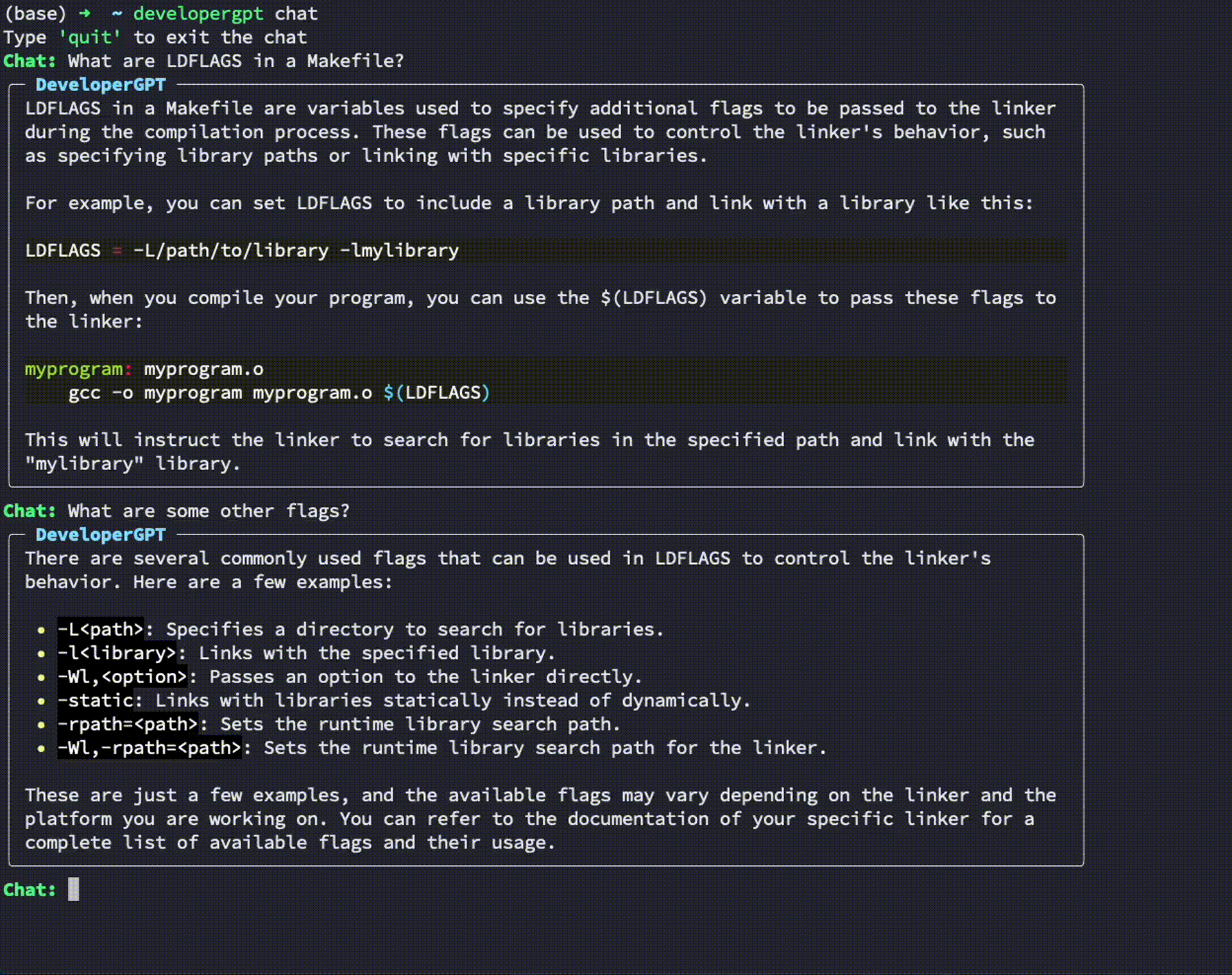
Use developergpt --model [model_name] chat to use a different LLM.
# Example
$ developergpt --model mistral chatChat moderation is NOT implemented - all your chat messages should follow the terms of use of the LLM used.
DeveloperGPT is NOT to be used for any purposes forbidden by the terms of use of the LLMs used. Additionally, DeveloperGPT itself (apart from the LLMs) is a proof of concept tool and is not intended to be used for any serious or commerical work.
pip install -U developergpt# see available commands
$ developergpt Accuracy of DeveloperGPT varies depending on the LLM used as well as the mode (--fast vs. regular). Shown below are Top@1 Accuracy of different LLMs on a set of 85 natural language command requests (this isn't a rigorous evaluation, but it gives a rough sense of accuracy). Github CoPilot in the CLI v1.0.1 is also included for comparison.
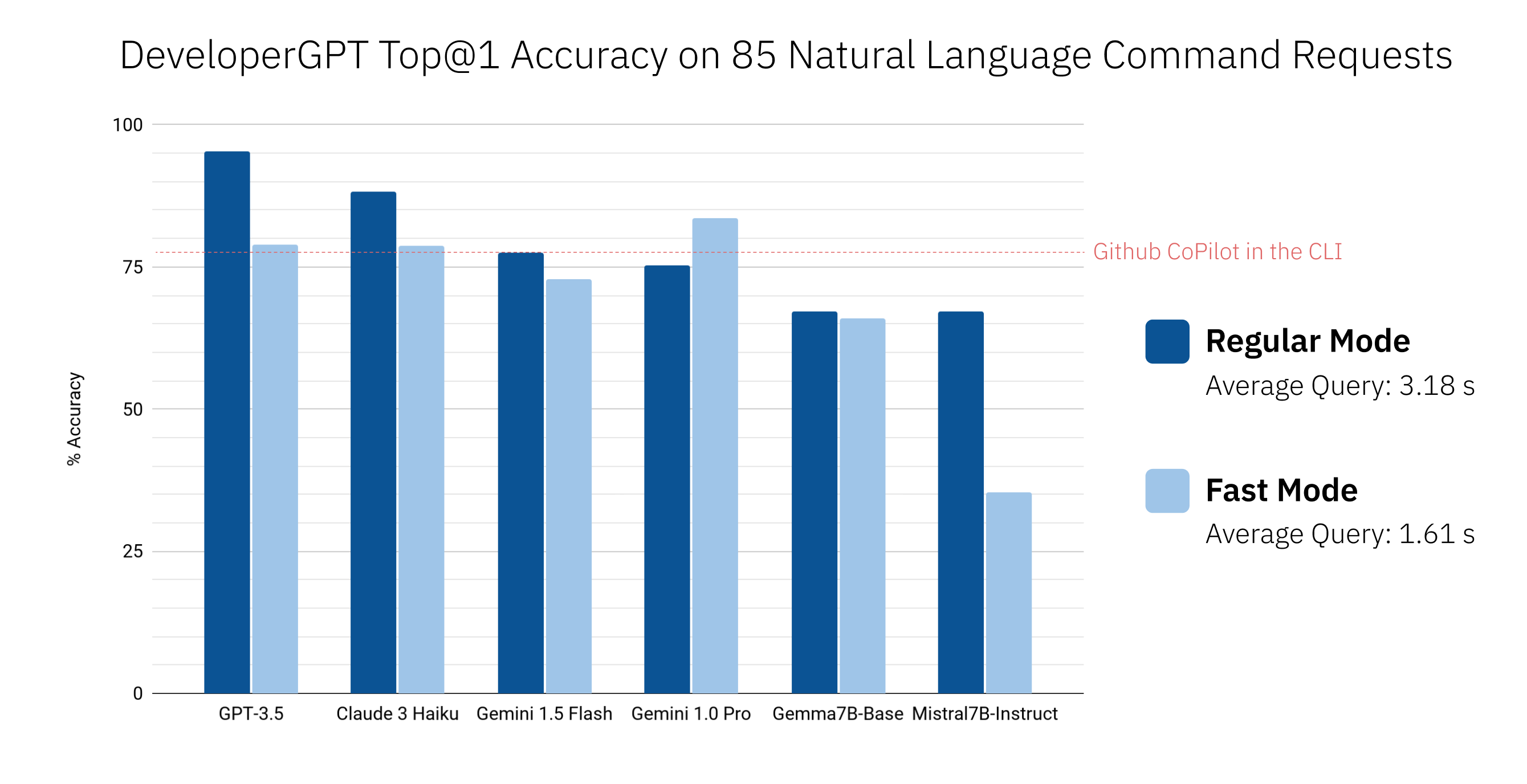
By default, DeveloperGPT uses Google Gemini 1.5 Flash. To use Gemini 1.0 Pro or Gemini 1.5 Flash, you will need an API key (free to use up to 15 queries per minute).
GOOGLE_API_KEY environment variable. You only need to do this once.# set Google API Key (using zsh for example)
$ echo 'export GOOGLE_API_KEY=[your_key_here]' >> ~/.zshenv
# reload the environment (or just quit and open a new terminal)
$ source ~/.zshenvTo use open LLMs such as Gemma or Mistral hosted on Hugging Face, you can optionally set up a Hugging Face Inference API token as the HUGGING_FACE_API_KEY environment variable. See https://huggingface.co/docs/api-inference/index for more details.
To use quantized Mistral-7B-Instruct, just run DeveloperGPT with the --offline flag. This will download the model on first run and use it locally in any future runs (no internet connection is required after the first use). No special setup is required.
developergpt --offline chatTo use GPT-3.5 or GPT-4, you will need an OpenAI API key.
OPENAI_API_KEY environment variable. You only need to do this once.To use Anthropic Claude 3 Sonnet or Haiku, you will need an Anthropic API key.
ANTHROPIC_API_KEY environment variable. You only need to do this once.As of June 2024, Google Gemini 1.0 Pro and Gemini 1.5 Flash are free to use up to 15 queries per minute. For more information, see: https://ai.google.dev/pricing
As of June 2024, using Hugging Face Inference API hosted LLMs is free but rate limited. See https://huggingface.co/docs/api-inference/index for more details.
Mistral-7B-Instruct is free to use and runs locally on-device.
You can monitor your OpenAI API usage here: https://platform.openai.com/account/usage. The average cost per query using GPT-3.5 is < 0.1 cents. Using GPT-4 is not recommended as GPT-3.5 is much more cost-effective and achieves a very high accuracy for most commands.
You can monitor your Anthropic API usage here: https://console.anthropic.com/settings/plans. The average cost per query using Claude 3 Haiku is < 0.1 cents. See https://www.anthropic.com/api for pricing details.
Read the CONTRIBUTING.md file.


