star
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
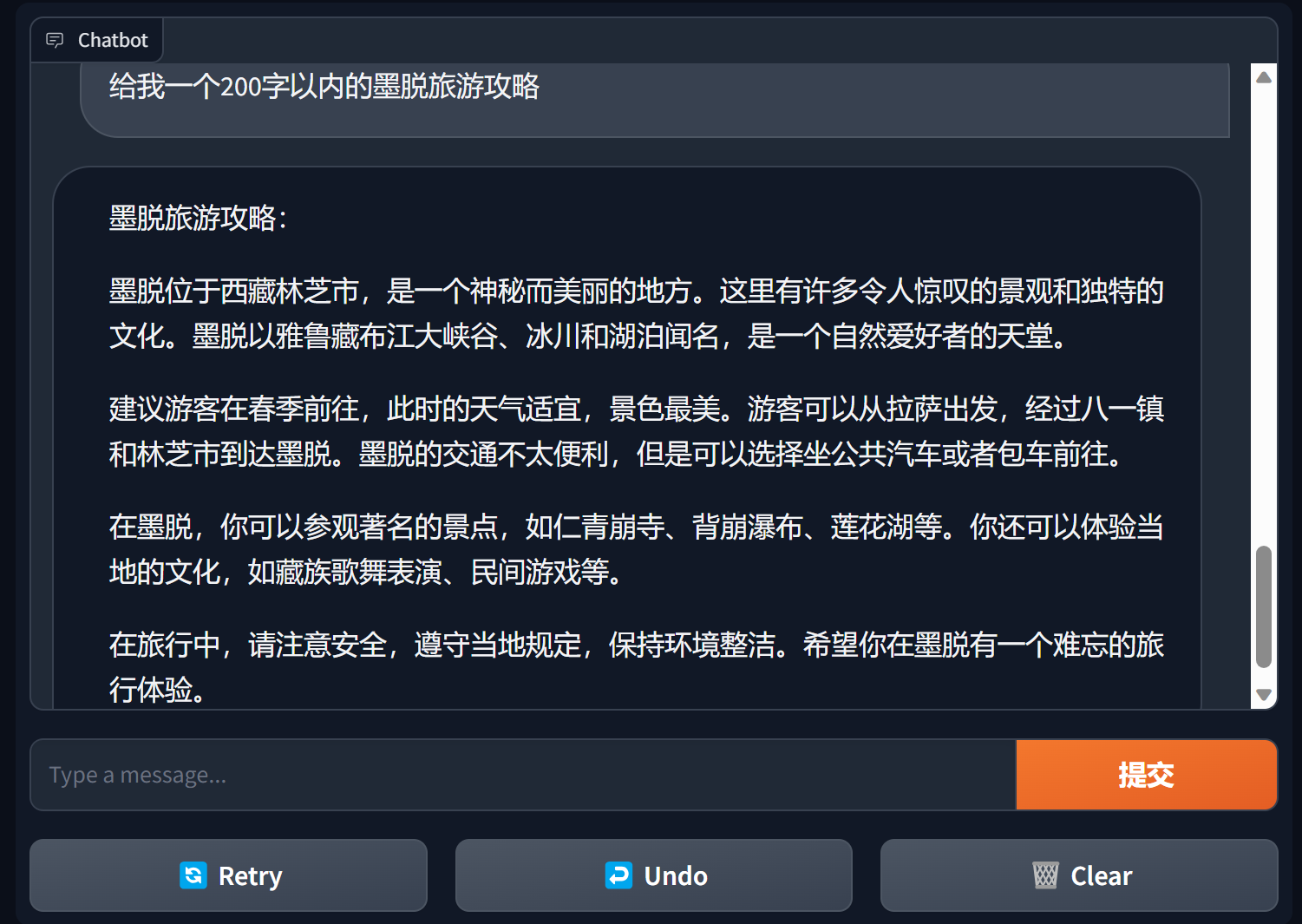
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | model company | Model type | Model name | Whether to support | illustrate |
|---|---|---|---|---|
| OpenAI | Chat | gpt-3.5, gpt-4 | √ | Supports all gpt3.5 and gpt4 models |
| Text Completion | text-davinci-003 | √ | Text generation class model | |
| Embeddings | text-embedding-ada-002 | √ | vectorized model | |
| Baidu-Wen Xin Yiyan | Chat | ernie-bot, ernie-bot-turbo | √ | Baidu commercial Chat model |
| Embeddings | embedding_v1 | √ | Baidu commercial vectorization model | |
| Hosted model | Various open source models | √ | For various open source models hosted by Baidu, please configure them yourself using the Baidu third-party model access protocol. For details, see the model access section below. | |
| Alibaba Cloud-Tongyi Qianwen | Chat | qwen-v1, qwen-plus-v1, qwen-7b-chat-v1 | √ | Alibaba Cloud commercial and open source Chat models |
| Embeddings | text-embedding-v1 | √ | Alibaba Cloud commercial vectorization model | |
| Hosted model | Various open source models | √ | For other types of open source models hosted by Alibaba Cloud, please configure them yourself using the Alibaba Cloud third-party model access protocol. For details, see the model access section below. | |
| MiniMax | Chat | abab5, abab5.5 | √ | MiniMax Commercial Chat Model |
| Chat Pro | abab5.5 | √ | MiniMax commercial Chat model, using customized Chatcompletion pro mode, supports multi-person and multi-bot conversation scenarios, sample conversations, return format restrictions, function calls, plug-ins and other functions | |
| Embeddings | embo-01 | √ | MiniMax commercial vector model | |
| Wisdom spectrum AI-ChatGLM | Chat | ChatGLM-Pro, Std, Lite, characterglm | √ | Zhipu AI multi-version commercial large model |
| Embeddings | Text-Embedding | √ | Zhipu AI commercial text vector model | |
| iFlytek-Spark | Chat | SparkDesk V1.5, V2.0 | √ | iFlytek Spark Cognitive Large Model |
| Embeddings | embedding | √ | iFlytek Spark text vector model | |
| SenseTime-RiRiXin | Chat | nova-ptc-xl-v1, nova-ptc-xs-v1 | √ | SenseNova SenseTime daily new large model |
| Baichuan Intelligence | Chat | baichuan-53b-v1.0.0 | √ | Baichuan 53B large model |
| Tencent-Hunyuan | Chat | Tencent Hunyuan | √ | Tencent Hunyuan large model |
| Self-deployed open source model | Chat, Completion, Embeddings | Various open source models | √ | Using open source models deployed by FastChat and other deployments, the provided Web API interface follows OpenAI-Compatible RESTful APIs and can be directly supported. For details, see the model access chapter below. |
Notice :
The two technologies of model LLM and prompt word Prompt in AIGC are very new and are developing rapidly. The theory, tutorials, tools, engineering and other aspects are very lacking. The technology stack used has almost no overlap with the experience of current mainstream developers:
| Classification | Current mainstream development | Prompt project | Develop models, fine-tune models |
|---|---|---|---|
| development language | Java, .Net, Javscript, ABAP, etc. | Natural language, Python | Python |
| development tools | Very much and mature | none | Mature |
| Development threshold | lower and mature | low but very immature | very high |
| development technology | clear and steady | Easy to get started but very difficult to achieve steady output | complex and varied |
| Commonly used techniques | Object-oriented, database, big data | prompt tuning, incontext learning, embedding | Transformer, RLHF, Finetunning, LoRA |
| Open source support | rich and mature | Very confusing at lower level | rich but immature |
| development cost | Low | higher | very high |
| Developer | Rich | Extremely scarce | very scarce |
| Develop collaborative model | Develop according to documents delivered by the product manager | One person or a minimalist team can handle all operations from requirements to delivery | Developed according to theoretical research directions |
At present, almost all technology companies, Internet companies, and big data companies are all in this direction, but more traditional companies are still in a state of confusion. It’s not that traditional enterprises don’t need it, but that: 1) they don’t have technical talent reserves, so they don’t know what to do; 2) they don’t have hardware reserves, and they don’t have the ability to do it; 3) The degree of business digitalization is low, and AIGC transformation and upgrading has a long cycle and slow results.
At present, there are too many commercial and open source models at home and abroad, and they are developing very fast. However, the APIs and data objects of the models are different. As a result, when facing a new model (or even a new version), we have to read the development documents and Modify your own application code to adapt. I believe that every application developer has tested many models and must have suffered from it.
In fact, although model capabilities are different, the modes for providing capabilities are generally the same. Therefore, having a framework that can adapt to a large number of model APIs and provide a unified calling mode has become an urgent need for many developers.
First of all, bida is not intended to replace langchain, but its target positioning and development concepts are also very different:
| Classification | langchain | bida |
|---|---|---|
| target group | The full development crowd in the direction of AIGC | Developers who have an urgent need to combine AIGC with application development |
| Model support | Supports various models for local or remote deployment | Only model calls that provide Web API are supported. Currently, most commercial models provide it. Open source models can also provide Web API after being deployed using frameworks such as FastChat. |
| frame structure | Because it provides many capabilities and a very complex structure, as of August 2023, the core code has more than 1,700 files and 150,000 lines of code, and the learning threshold is high. | There are more than ten core codes and about 2,000 lines of code. It is relatively easy to learn and modify the code. |
| Function support | Provide full coverage of various models, technologies, and application fields in the direction of AIGC | Currently, it provides support for ChatCompletions, Completions, Embeddings, Function Call and other functions. Multi-modal functions such as voice and image will be released in the near future. |
| Prompt | Prompt templates are provided, but the prompts used by its own functions are embedded in the code, making debugging and modification difficult. | Prompt templates are provided. Currently, there is no built-in function to use Prompt. If used in the future, configuration-based post-loading mode will be used to facilitate user adjustments. |
| Conversation & Memory | Support and provide multiple memory management methods | Support, support Conversation persistence (saved to duckdb), Memory provides limited archiving session capabilities, and other capabilities can be expanded by the extension framework |
| Function & Plugin | Support and provide rich expansion capabilities, but the use effect depends on the own capabilities of the large model | Compatible with large models using OpenAI’s Function Call specification |
| Agent & Chain | Support and provide rich expansion capabilities, but the use effect depends on the own capabilities of the large model | Not supported, we plan to open another project to implement it, or we can expand and develop on our own based on the current framework. |
| Other functions | Supports many other functions, such as document splitting (embedding is done after splitting, used to implement chatpdf and other similar functions) | There are currently no other functions. If they are added, they will be implemented by opening a new compatible project. Currently, they can be implemented using the combination of capabilities provided by other products. |
| Operational efficiency | Many developers report that it is slower than calling the API directly, and the reason is unknown. | It only encapsulates the calling process and unifies the calling interface, and the performance is no different from calling the API directly. |
As a leading open source project in the industry, langchain has made great contributions to the promotion of large models and AGI. We have also applied it in the project. At the same time, we also drew on many of its models and ideas when developing bida. But langchain wants to be a large and comprehensive tool, which inevitably leads to many shortcomings. The following articles have similar opinions: Max Woolf - Chinese, Hacker News - Chinese.
A popular saying in the circle sums it up very well: langchain is a textbook that everyone will learn, but will eventually throw away.
Install latest bida from pip or pip3
pip install -U bidaClone project code from github to local directory:
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txtModify the file under the current code root directory: The extension of ".env.template" becomes the ".env" environment variable file. Please configure the key of the model you have applied for according to the instructions in the file.
Please note : This file has been added to the ignore list and will not be transmitted to the git server.
examples1.Initialization environment.ipynb
The following demonstration code will use a variety of models supported by bida. Please modify and replace the **[model_type]** value in the code with the corresponding model company name according to the model you purchased. You can quickly switch between various models for experience:
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )Chat mode: ChatCompletion, the current mainstream LLM interaction mode, bida supports session management, persistence and memory management.
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )For the above detailed code and more functional examples, please refer to the NoteBook below:
examples2.1.Chat mode.ipynb
Build chatbot using gradient
Gradio is a very popular natural language processing interface framework
bida + grario can build a usable application with just a few lines of code
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()
For details, see: bida+gradio’s chatbot demo
Completion mode: Completions or TextCompletions, the previous generation LLM interaction mode, only supports single-round conversations, does not save chat records, and each call is a new communication.
Please note: In OpenAI’s article on July 6, 2023, this model clearly stated that it will be phased out. New models basically do not provide relevant functions. Even supported models are estimated to follow OpenAI and are expected to be gradually phased out in the future. .
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )For sample code details, see:
examples2.2.Completion mode.ipynb
The prompt word Prompt is the most important function in the large language model. It subverts the traditional object-oriented development model and transforms it into: Prompt project . This framework is implemented using "Prompt Templete", which supports functions such as replacement tags, setting different prompt words for multiple models, and automatic replacement when the model performs interaction.
PromptTemplate_Text is currently provided: supports using string text to generate Prompt templates, bida also supports flexible custom templates, and plans to provide the ability to load templates from json and databases in the future.
Please see the following file for detailed sample code:
examples2.3.Prompt prompt word.ipynb
Important instructions in the prompt words
In general, it is recommended that prompt words follow a three-paragraph structure: setting roles, clarifying tasks, and giving context (related information or examples) . You can refer to the writing method in the examples.
Andrew Ng’s series of courses https://learn.deeplearning.ai/login, Chinese version, interpretation
openai cookbook https://github.com/openai/openai-cookbook
Microsoft Azure Documentation: Introduction to Tip Engineering, Tip Engineering Technology
The most popular Prompt Engineering Guide on Github, Chinese version
Function Calling is a function released by OpenAI on June 13, 2023. We all know that the data trained by ChatGPT is based on before 2021. If you ask some real-time related questions, we will not be able to answer you, and function calling allows real-time It becomes possible to obtain network data, such as checking weather forecasts, checking stocks, recommending recent movies, etc.
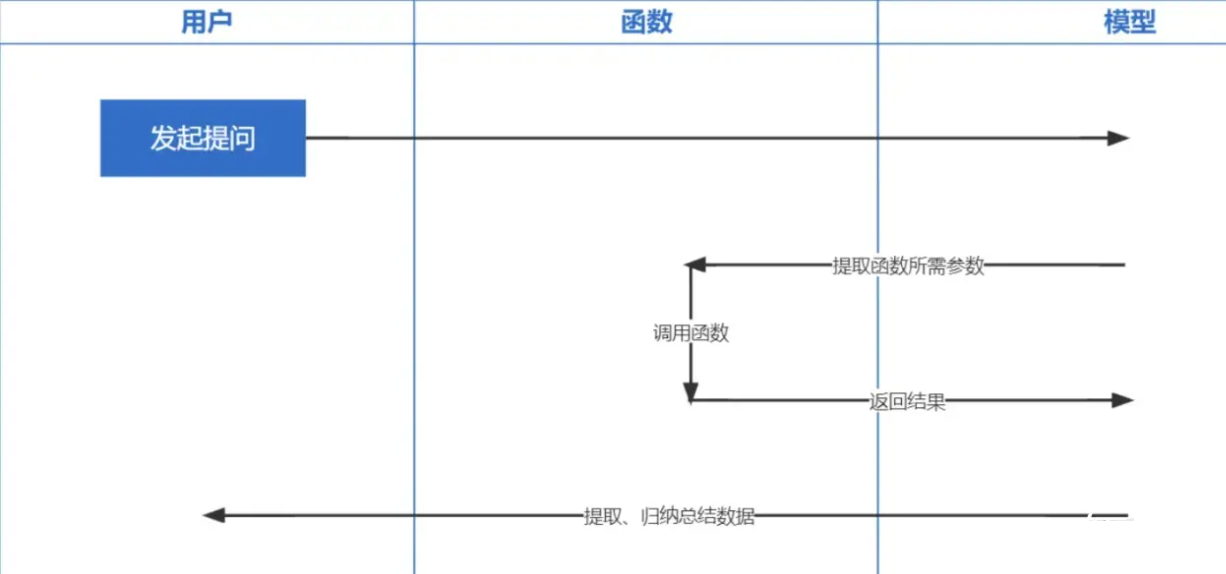
Embeddings technology is the most important technology to implement Prompt inContext Learning. Compared with previous keyword retrieval, it is another step forward.
Note : The data embedding from different models is not universal, so the same model must be used for the embedding of the question during retrieval.
| Model name | Output dimensions | Number of batch records | Single text token limit |
|---|---|---|---|
| OpenAI | 1536 | No limit | 8191 |
| Baidu | 384 | 16 | 384 |
| Ali | 1536 | 10 | 2048 |
| MiniMax | 1536 | No limit | 4096 |
| Wisdom spectrum AI | 1024 | Single | 512 |
| iFlytek Spark | 1024 | Single | 256 |
Note: bida's embedding interface supports batch processing. If the model batch processing limit is exceeded, it will automatically be processed in batches and returned together. If the content of a single piece of text exceeds the limited number of tokens, depending on the logic of the model, some will report an error and some will truncate it.
For detailed examples, see: examples2.6.Embeddingsembedding model.ipynb
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
We hope to adapt to more models, and welcome your valuable opinions to provide developers with better products together!