lightllm
1.0.0
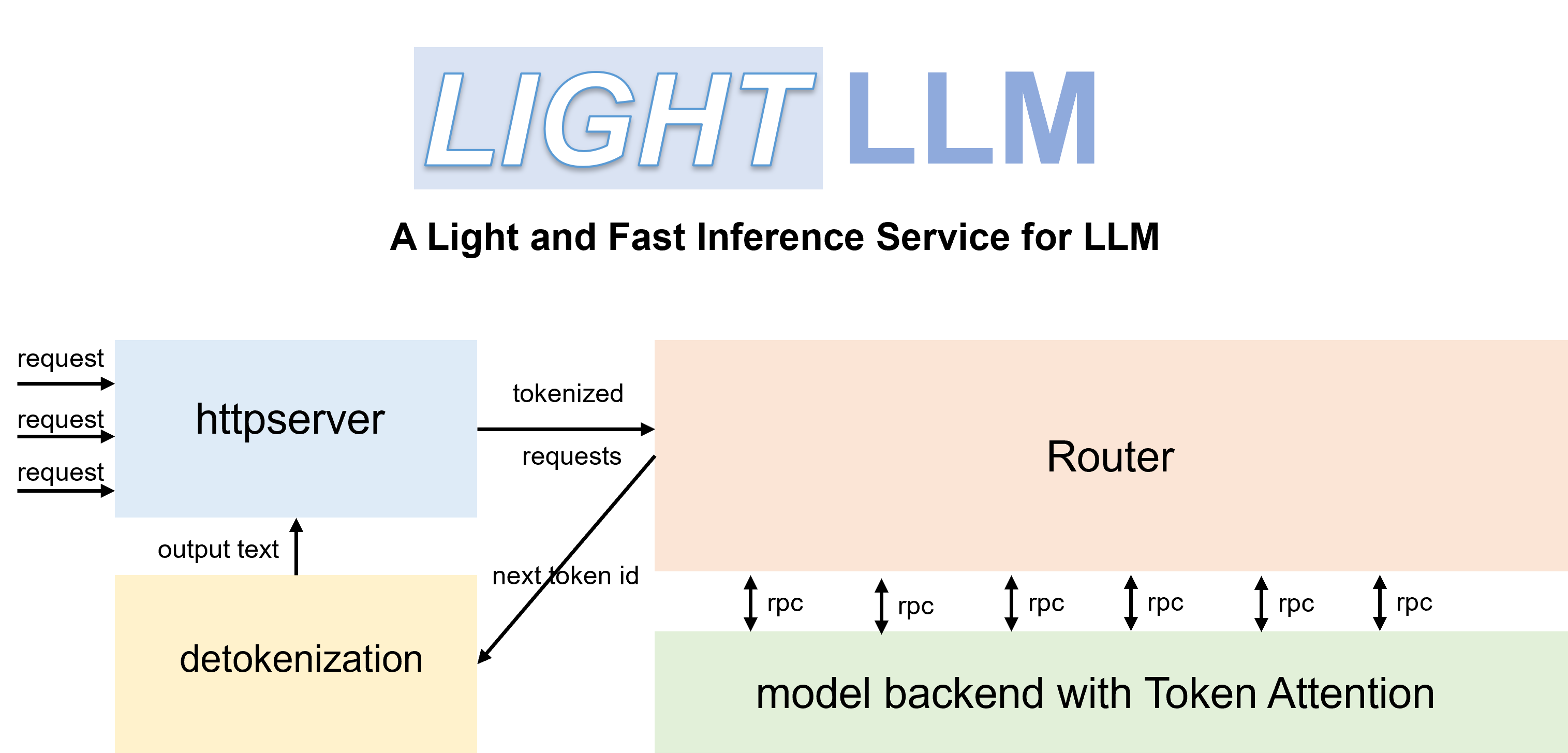
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework, notable for its lightweight design, easy scalability, and high-speed performance. LightLLM harnesses the strengths of numerous well-regarded open-source implementations, including but not limited to FasterTransformer, TGI, vLLM, and FlashAttention.
English Docs | 中文文档
When you start Qwen-7b, you need to set the parameter '--eos_id 151643 --trust_remote_code'.
ChatGLM2 needs to set the parameter '--trust_remote_code'.
InternLM needs to set the parameter '--trust_remote_code'.
InternVL-Chat(Phi3) needs to set the parameter '--eos_id 32007 --trust_remote_code'.
InternVL-Chat(InternLM2) needs to set the parameter '--eos_id 92542 --trust_remote_code'.
Qwen2-VL-7b needs to set the parameter '--eos_id 151645 --trust_remote_code', and use 'pip install git+https://github.com/huggingface/transformers' to upgrade to the latest version.
Stablelm needs to set the parameter '--trust_remote_code'.
Phi-3 only supports Mini and Small.
DeepSeek-V2-Lite and DeepSeek-V2 need to set the parameter '--data_type bfloat16'
The code has been tested with Pytorch>=1.3, CUDA 11.8, and Python 3.9. To install the necessary dependencies, please refer to the provided requirements.txt and follow the instructions as
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5You can use the official Docker container to run the model more easily. To do this, follow these steps:
Pull the container from the GitHub Container Registry:
docker pull ghcr.io/modeltc/lightllm:mainRun the container with GPU support and port mapping:
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bashAlternatively, you can build the container yourself:
docker build -t <image_name> .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
<image_name> /bin/bashYou can also use a helper script to launch both the container and the server:
python tools/quick_launch_docker.py --helpNote: If you use multiple GPUs, you may need to increase the shared memory size by adding --shm-size to the docker run command.
python setup.py installThe code has been tested on a range of GPUs including V100, A100, A800, 4090, and H800. If you are running the code on A100, A800, etc., we recommend using triton==3.0.0.
pip install triton==3.0.0 --no-depsIf you are running the code on H800 or V100., you can try triton-nightly to get better performance.
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-depsWith efficient Routers and TokenAttention, LightLLM can be deployed as a service and achieve the state-of-the-art throughput performance.
Launch the server:
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000The parameter max_total_token_num is influenced by the GPU memory of the deployment environment. You can also specify --mem_faction to have it calculated automatically.
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9To initiate a query in the shell:
curl http://127.0.0.1:8080/generate
-X POST
-d '{"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}}'
-H 'Content-Type: application/json'To query from Python:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = {'Content-Type': 'application/json'}
data = {
'inputs': 'What is AI?',
"parameters": {
'do_sample': False,
'ignore_eos': False,
'max_new_tokens': 1024,
}
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print(response.json())
else:
print('Error:', response.status_code, response.text)python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13bimport time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = {'Content-Type': 'application/json'}
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri.startswith("http"):
images = [{"type": "url", "data": uri}]
else:
with open(uri, 'rb') as fin:
b64 = base64.b64encode(fin.read()).decode("utf-8")
images=[{'type': "base64", "data": b64}]
data = {
"inputs": "<img></img>Generate the caption in English with grounding:",
"parameters": {
"max_new_tokens": 200,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences": [" <|endoftext|>"],
},
"multimodal_params": {
"images": images,
}
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print(response.json())
else:
print('Error:', response.status_code, response.text)import json
import requests
import base64
def run_once(query, uris):
images = []
for uri in uris:
if uri.startswith("http"):
images.append({"type": "url", "data": uri})
else:
with open(uri, 'rb') as fin:
b64 = base64.b64encode(fin.read()).decode("utf-8")
images.append({'type': "base64", "data": b64})
data = {
"inputs": query,
"parameters": {
"max_new_tokens": 200,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences": [" <|endoftext|>", " <|im_start|>", " <|im_end|>"],
},
"multimodal_params": {
"images": images,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = {'Content-Type': 'application/json'}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print(" + result: ({})".format(response.json()))
else:
print(' + error: {}, {}'.format(response.status_code, response.text))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once(
uris = [
"assets/mm_tutorial/Chongqing.jpeg",
"assets/mm_tutorial/Beijing.jpeg",
],
query = "<|im_start|>systemnYou are a helpful assistant.<|im_end|>n<|im_start|>usern<img></img>n<img></img>n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>n<|im_start|>assistantn根据提供的信息,两张图片分别是重庆和北京。<|im_end|>n<|im_start|>usern这两座城市分别在什么地方?<|im_end|>n<|im_start|>assistantn"
)import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = {'Content-Type': 'application/json'}
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri.startswith("http"):
images = [{"type": "url", "data": uri}]
else:
with open(uri, 'rb') as fin:
b64 = base64.b64encode(fin.read()).decode("utf-8")
images=[{'type': "base64", "data": b64}]
data = {
"inputs": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image>nPlease explain the picture. ASSISTANT:",
"parameters": {
"max_new_tokens": 200,
},
"multimodal_params": {
"images": images,
}
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print(response.json())
else:
print('Error:', response.status_code, response.text)Additional lanuch parameters:
--enable_multimodal,--cache_capacity, larger--cache_capacityrequires largershm-size
Support
--tp > 1, whentp > 1, visual model run on the gpu 0
The special image tag for Qwen-VL is
<img></img>(<image>for Llava), the length ofdata["multimodal_params"]["images"]should be the same as the count of tags, The number can be 0, 1, 2, ...
Input images format: list for dict like
{'type': 'url'/'base64', 'data': xxx}
We compared the service performance of LightLLM and vLLM==0.1.2 on LLaMA-7B using an A800 with 80G GPU memory.
To begin, prepare the data as follows:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonLaunch the service:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoEvaluation:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200The performance comparison results are presented below:
| vLLM | LightLLM |
|---|---|
| Total time: 361.79 s Throughput: 5.53 requests/s |
Total time: 188.85 s Throughput: 10.59 requests/s |
For debugging, we offer static performance testing scripts for various models. For instance, you can evaluate the inference performance of the LLaMA model by
cd test/model
python test_llama.pypip install protobuf==3.20.0.error : PTX .version 7.4 does not support .target sm_89
bash tools/resolve_ptx_version python -m lightllm.server.api_server ...
If you have a project that should be incorporated, please contact via email or create a pull request.
Once you have installed lightllm and lazyllm, and then you can use the following code to build your own chatbot:
from lazyllm import TrainableModule, deploy, WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule('internlm2-chat-7b').deploy_method(deploy.lightllm)
WebModule(m).start().wait()Documents: https://lazyllm.readthedocs.io/
For further information and discussion, join our discord server.
This repository is released under the Apache-2.0 license.
We learned a lot from the following projects when developing LightLLM.


