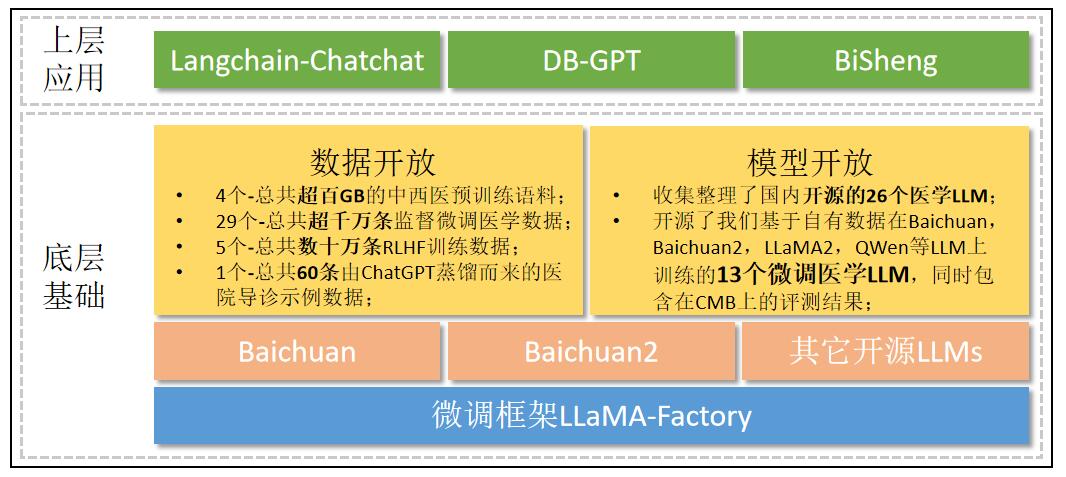
CareGPT
1.0.0
Chinese | English
Video tutorial Installation and deployment Online experience

⚡Features:
conda create - n llm python = 3.11
conda activate llm
python - m pip install - r requirements . txt # 转为HF格式
python - m transformers . models . llama . convert_llama_weights_to_hf
- - input_dir path_to_llama_weights - - model_size 7 B - - output_dir path_to_llama_model If you use a custom dataset, be sure to provide your dataset definition in the dataset_info.json file in the following format.
"数据集名称" : {
"hf_hub_url" : " HuggingFace上的项目地址(若指定,则忽略下列三个参数) " ,
"script_url" : "包含数据加载脚本的本地文件夹名称(若指定,则忽略下列两个参数) " ,
"file_name" : "该目录下数据集文件的名称(若上述参数未指定,则此项必需) " ,
"file_sha1" : "数据集文件的SHA-1哈希值(可选) " ,
"columns" : {
"prompt" : "数据集代表提示词的表头名称(默认:instruction) " ,
"query" : "数据集代表请求的表头名称(默认:input) " ,
"response" : "数据集代表回答的表头名称(默认:output) " ,
"history" : "数据集代表历史对话的表头名称(默认:None) "
}
} The prompt and response columns should be non-empty strings. The content of the query column will be concatenated with the prompt column as model input. The history column should be a list, where each element is a string tuple representing the user request and model reply respectively.
.txt format, one unsupervised data per line.
Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks.
Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, agriculture, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.[
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : [
[ "你好,你能帮我解答一个问题吗? " , "当然,请问有什么问题? " ],
[ "我想了解人工智能的未来发展方向,你有什么想法吗? " , "人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更加智能的机器人。 " ]
]
}
][
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : []
}
][
{
"instruction" : "生成三个与“道歉”意思相同的动词" ,
"input" : " " ,
"output" : [
"承认,表示遗憾,弥补。 " ,
"道歉"
]
}
] Check whether your graphics card is connected with NVLINK. Only with NVLINK connection can you effectively use accelerate for parallel accelerated training.
nvidia-smi topo -m
accelerate config # configure the environment
accelerate launch src / train_bash . py # arguments (same as above) # LLaMA-2
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset mm
- - finetuning_type lora
- - quantization_bit 4
- - overwrite_cache
- - output_dir output
- - per_device_train_batch_size 8
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template llama2
- - lora_target q_proj , v_proj
# LLaMA
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_train
- - dataset mm , hm
- - finetuning_type lora
- - overwrite_cache
- - output_dir output - 1
- - per_device_train_batch_size 4
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 2000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template default
- - lora_target q_proj , v_proj # LLaMA-2, DPO
accelerate launch src / train_bash . py
- - stage dpo
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset rlhf
- - template llama2
- - finetuning_type lora
- - quantization_bit 4
- - lora_target q_proj , v_proj
- - resume_lora_training False
- - checkpoint_dir . / output - 2
- - output_dir output - dpo
- - per_device_train_batch_size 2
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 1e-5
- - num_train_epochs 1.0
- - plot_loss
- - fp16 # LLaMA-2
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / web_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2Test API:
curl - X 'POST'
'http://127.0.0.1:8888/v1/chat/completions'
- H 'accept: application/json'
- H 'Content-Type: application/json'
- d ' {
"model" : "string",
"messages": [
{
"role" : "user",
"content": "你好"
}
],
" temperature ": 0 ,
"top_p" : 0 ,
"max_new_tokens" : 0 ,
"stream" : false
}' # LLaMA-2
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / cli_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_predict
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_predict
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_eval
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_eval
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate For 4/8-bit evaluation, it is recommended to use --per_device_eval_batch_size=1 and --max_target_length 128
# LLaMA-2
python src / export_model . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir output_export
# LLaMA
python src / export_model . py
- - model_name_or_path . / Llama - 7 b - hf
- - template default
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir output_export % cd Gradio
python app . py 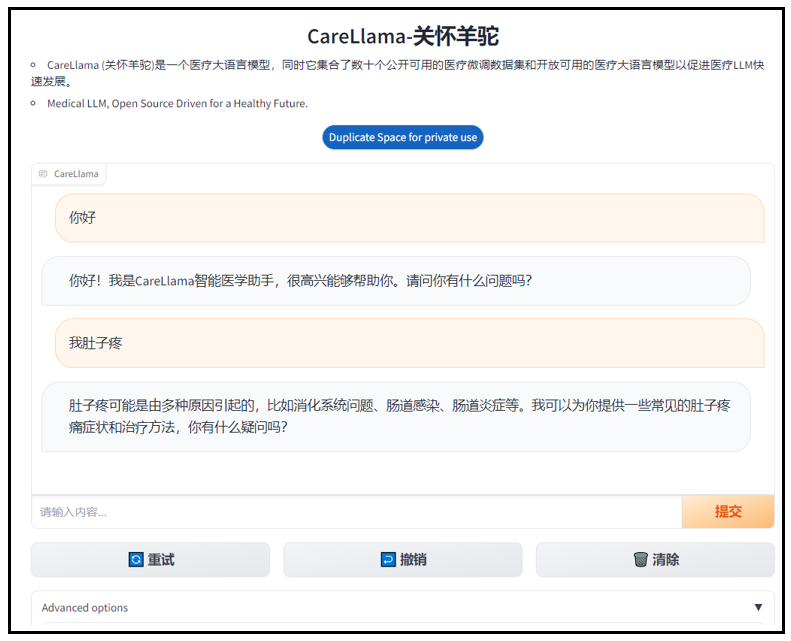
# LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default设置, modify接口地址to: http://127.0.0.1:8000/ (that is, your API interface address), and then you can use it. 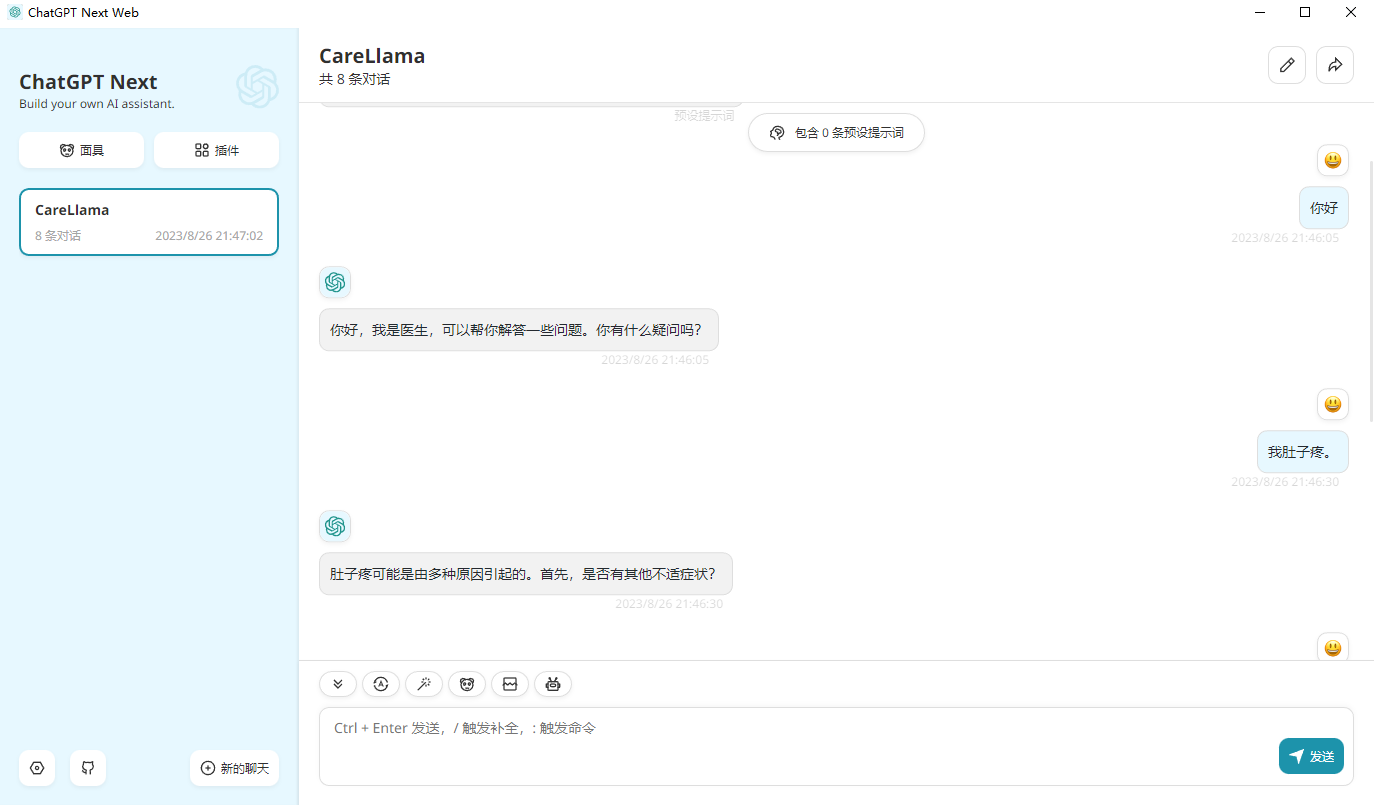
PubMed Central and PubMed Abstracts . These valuable texts have greatly enriched the medical knowledge system of the BLOOMZ model, so many open source projects will give priority to BLOOMZ as the base model for medical fine-tuning;质量> 数量is the truth, such as: Less is More! Handed over to Qingyuan&& Caspian | Use 200 pieces of data to fine-tune the model, surpassing MiniGPT-4 ! , ultra-large-scale SFT data will weaken downstream task LLM or lose ICL, CoT and other capabilities;大规模预训练+小规模监督微调=超强的LLM模型;英文10B以下选择Mistral-7B中文, 10B以下选择Yi-6B 10B, and 10B以上选择Qwen-14B和Yi-34B ; Important
Everyone is welcome to add new experiences to ISSUE!
11~13 Methodology comes from 13 billion large language models. Changing just one weight will completely lose the language ability! The latest research from the Natural Language Processing Laboratory of Fudan University.
14Methodology from How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
17~25 methodology comes from LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA) Chinese version interpretation
| stage | Introduction to weights | Download address | Features | base model | fine-tuning method | Dataset |
|---|---|---|---|---|---|---|
| ?Supervision and fine-tuning | Multi-turn dialogue data is trained based on LLaMA2-7b-Chat | CareLlama2-7b-chat-sft-multi、?CareLlama2-7b-multi | Excellent multi-turn conversation skills | LLaMA2-7b-Chat | QLoRA | mm |
| Supervise fine-tuning | Rich and efficient doctor-patient dialogue data is trained based on LLaMA2-7b-Chat | CareLlama2-7b-chat-sft-med | Excellent patient disease diagnosis capabilities | LLaMA2-7b-Chat | QLoRA | hm |
| supervise |


