FasterTransformer
v5.3 release
Note: FasterTransformer development has transitioned to TensorRT-LLM. All developers are encouraged to leverage TensorRT-LLM to get the latest improvements on LLM Inference. The NVIDIA/FasterTransformer repo will stay up, but will not have further development.
This repository provides a script and recipe to run the highly optimized transformer-based encoder and decoder component, and it is tested and maintained by NVIDIA.
In NLP, encoder and decoder are two important components, with the transformer layer becoming a popular architecture for both components. FasterTransformer implements a highly optimized transformer layer for both the encoder and decoder for inference. On Volta, Turing and Ampere GPUs, the computing power of Tensor Cores are used automatically when the precision of the data and weights are FP16.
FasterTransformer is built on top of CUDA, cuBLAS, cuBLASLt and C++. We provide at least one API of the following frameworks: TensorFlow, PyTorch and Triton backend. Users can integrate FasterTransformer into these frameworks directly. For supporting frameworks, we also provide example codes to demonstrate how to use, and show the performance on these frameworks.
| Models | Framework | FP16 | INT8 (after Turing) | Sparsity (after Ampere) | Tensor parallel | Pipeline parallel | FP8 (after Hopper) |
|---|---|---|---|---|---|---|---|
| BERT | TensorFlow | Yes | Yes | - | - | - | - |
| BERT | PyTorch | Yes | Yes | Yes | Yes | Yes | - |
| BERT | Triton backend | Yes | - | - | Yes | Yes | - |
| BERT | C++ | Yes | Yes | - | - | - | Yes |
| XLNet | C++ | Yes | - | - | - | - | - |
| Encoder | TensorFlow | Yes | Yes | - | - | - | - |
| Encoder | PyTorch | Yes | Yes | Yes | - | - | - |
| Decoder | TensorFlow | Yes | - | - | - | - | - |
| Decoder | PyTorch | Yes | - | - | - | - | - |
| Decoding | TensorFlow | Yes | - | - | - | - | - |
| Decoding | PyTorch | Yes | - | - | - | - | - |
| GPT | TensorFlow | Yes | - | - | - | - | - |
| GPT/OPT | PyTorch | Yes | - | - | Yes | Yes | Yes |
| GPT/OPT | Triton backend | Yes | - | - | Yes | Yes | - |
| GPT-MoE | PyTorch | Yes | - | - | Yes | Yes | - |
| BLOOM | PyTorch | Yes | - | - | Yes | Yes | - |
| BLOOM | Triton backend | Yes | - | - | Yes | Yes | - |
| GPT-J | Triton backend | Yes | - | - | Yes | Yes | - |
| Longformer | PyTorch | Yes | - | - | - | - | - |
| T5/UL2 | PyTorch | Yes | - | - | Yes | Yes | - |
| T5 | TensorFlow 2 | Yes | - | - | - | - | - |
| T5/UL2 | Triton backend | Yes | - | - | Yes | Yes | - |
| T5 | TensorRT | Yes | - | - | Yes | Yes | - |
| T5-MoE | PyTorch | Yes | - | - | Yes | Yes | - |
| Swin Transformer | PyTorch | Yes | Yes | - | - | - | - |
| Swin Transformer | TensorRT | Yes | Yes | - | - | - | - |
| ViT | PyTorch | Yes | Yes | - | - | - | - |
| ViT | TensorRT | Yes | Yes | - | - | - | - |
| GPT-NeoX | PyTorch | Yes | - | - | Yes | Yes | - |
| GPT-NeoX | Triton backend | Yes | - | - | Yes | Yes | - |
| BART/mBART | PyTorch | Yes | - | - | Yes | Yes | - |
| WeNet | C++ | Yes | - | - | - | - | - |
| DeBERTa | TensorFlow 2 | Yes | - | - | On-going | On-going | - |
| DeBERTa | PyTorch | Yes | - | - | On-going | On-going | - |
More details of specific models are put in xxx_guide.md of docs/, where xxx means the model name. Some common questions and the respective answers are put in docs/QAList.md. Note that the model of Encoder and BERT are similar and we put the explanation into bert_guide.md together.
The following code lists the directory structure of FasterTransformer:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
Note that many folders contains many sub-folders to split different models. Quantization tools are move to examples, like examples/tensorflow/bert/bert-quantization/ and examples/pytorch/bert/bert-quantization-sparsity/.
FasterTransformer provides some convenient environment variables for debuging and testing.
FT_LOG_LEVEL: This environment controls the log level of debug messae. More details are in src/fastertransformer/utils/logger.h. Note that the program will print lots of message when the level is lower than DEBUG and the program would become very slow.FT_NVTX: If it is set to be ON like FT_NVTX=ON ./bin/gpt_example, the program will insert tha tag of nvtx to help profiling the program.FT_DEBUG_LEVEL: If it is set to be DEBUG, then the program will run cudaDeviceSynchronize() after every kernels. Otherwise, the kernel is executued asynchronously by default. It is helpful to locate the error point during debuging. But this flag affects the performance of program significantly. So, it should be used only for debuging.Hardware settings:
In order to run the following benchmark, we need to install the unix computing tool "bc" by
apt-get install bcThe FP16 results of TensorFlow were obtained by running the benchmarks/bert/tf_benchmark.sh.
The INT8 results of TensorFlow were obtained by running the benchmarks/bert/tf_int8_benchmark.sh.
The FP16 results of PyTorch were obtained by running the benchmarks/bert/pyt_benchmark.sh.
The INT8 results of PyTorch were obtained by running the benchmarks/bert/pyt_int8_benchmark.sh.
More benchmarks are put in docs/bert_guide.md.
The following figure compares the performances of different features of FasterTransformer and FasterTransformer under FP16 on T4.
For large batch size and sequence length, both EFF-FT and FT-INT8-v2 bring about 2x speedup. Using Effective FasterTransformer and int8v2 at the same time can bring about 3.5x speedup compared to FasterTransformer FP16 for large case.
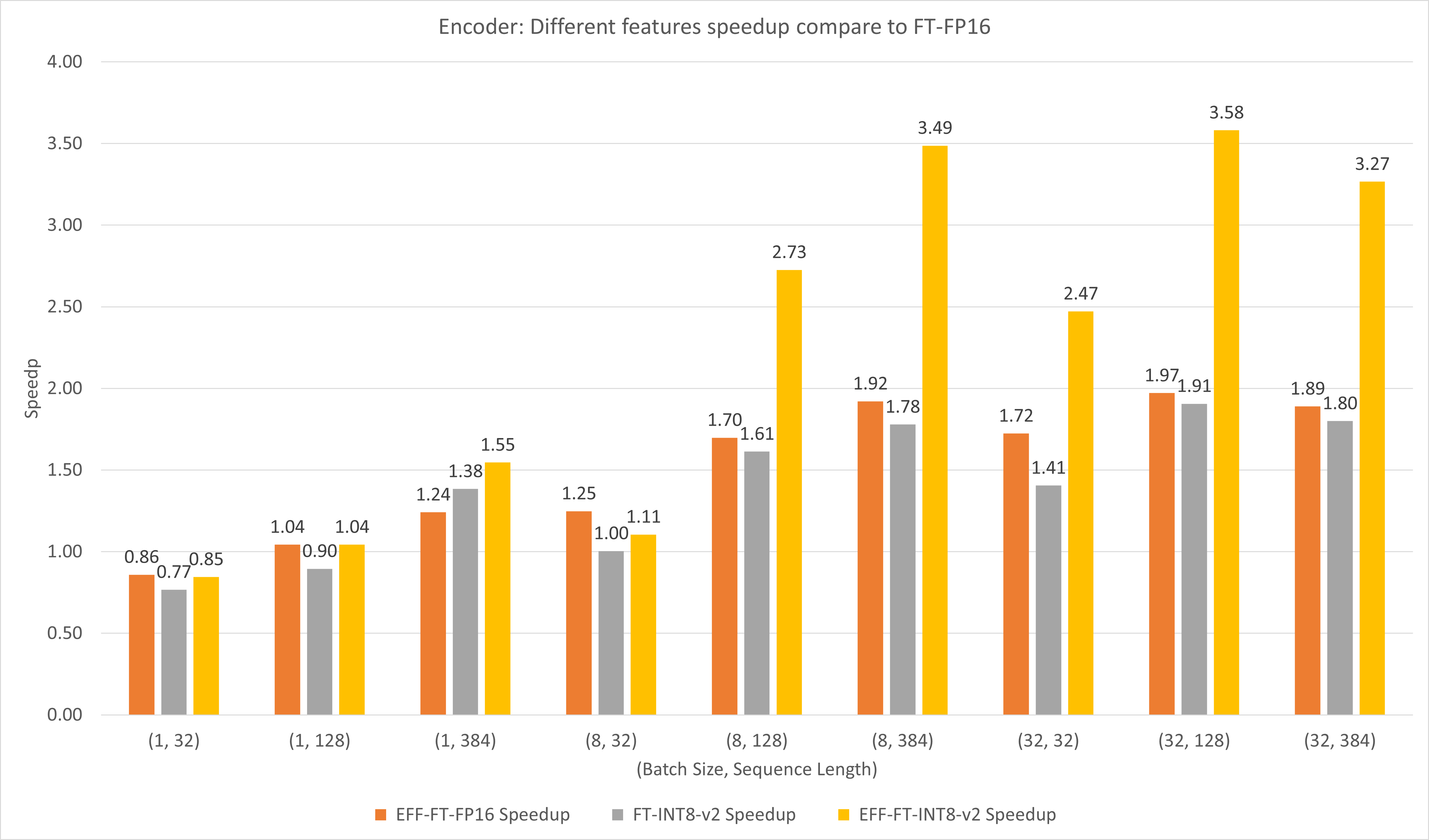
The following figure compares the performances of different features of FasterTransformer and TensorFlow XLA under FP16 on T4.
For small batch size and sequence length, using FasterTransformer can bring about 3x speedup.
For large batch size and sequence length, using Effective FasterTransformer with INT8-v2 quantization can bring about 5x speedup.
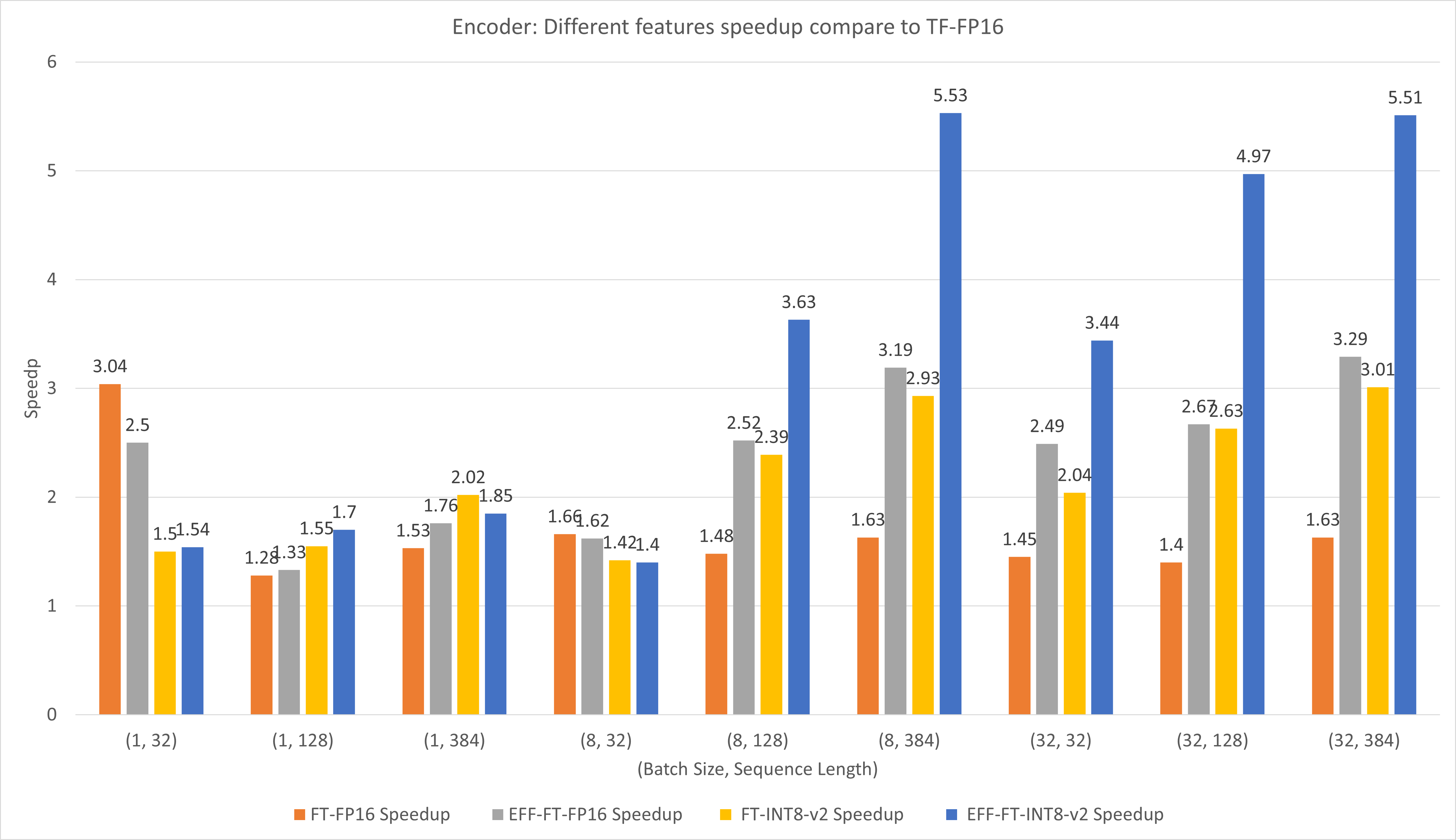
The following figure compares the performances of different features of FasterTransformer and PyTorch TorchScript under FP16 on T4.
For small batch size and sequence length, using FasterTransformer CustomExt can bring about 4x ~ 6x speedup.
For large batch size and sequence length, using Effective FasterTransformer with INT8-v2 quantization can bring about 5x speedup.
The results of TensorFlow were obtained by running the benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh and benchmarks/decoding/tf_decoding_sampling_benchmark.sh
The results of PyTorch were obtained by running the benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh.
In the experiments of decoding, we updated the following parameters:
More benchmarks are put in docs/decoder_guide.md.
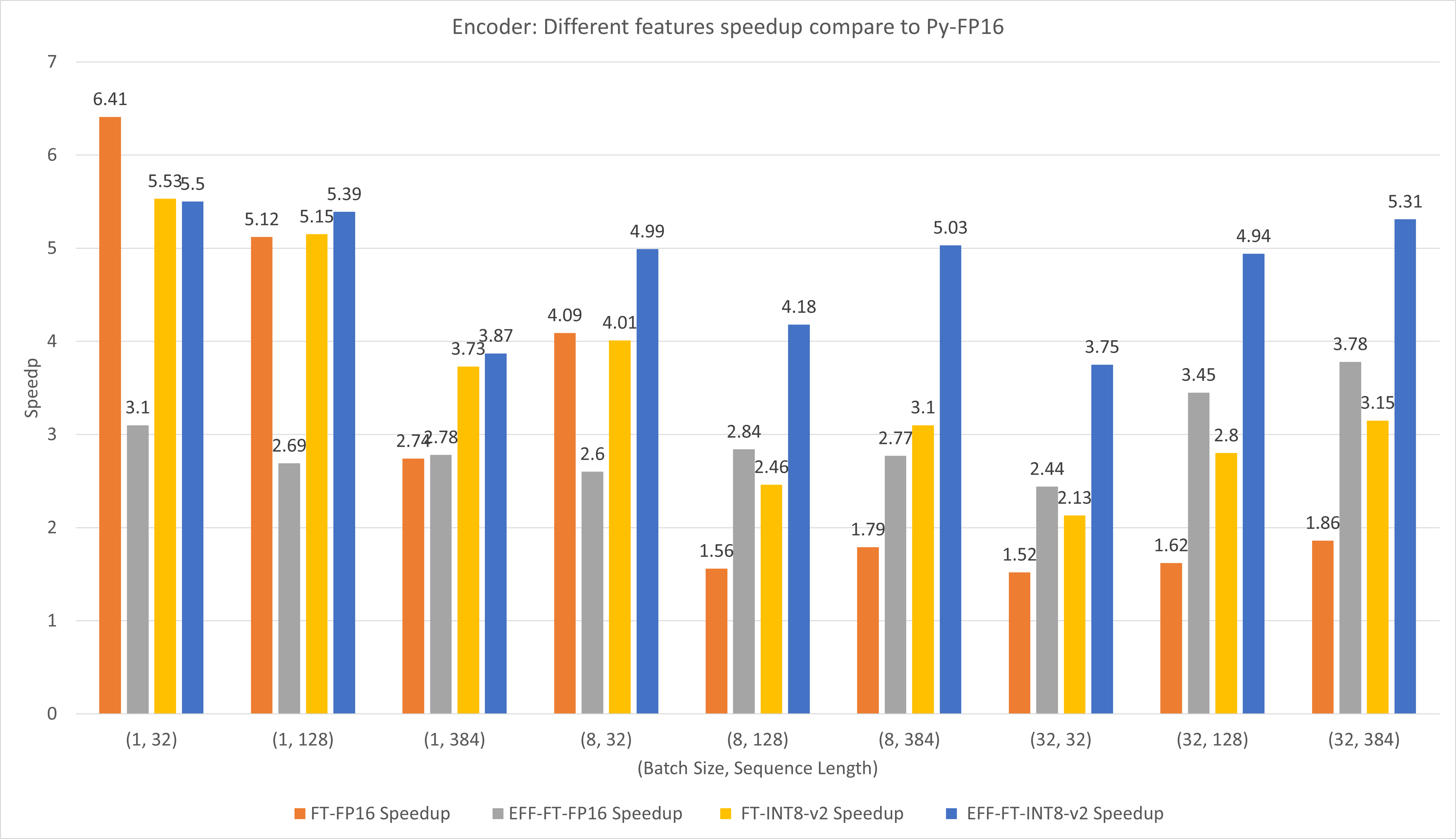
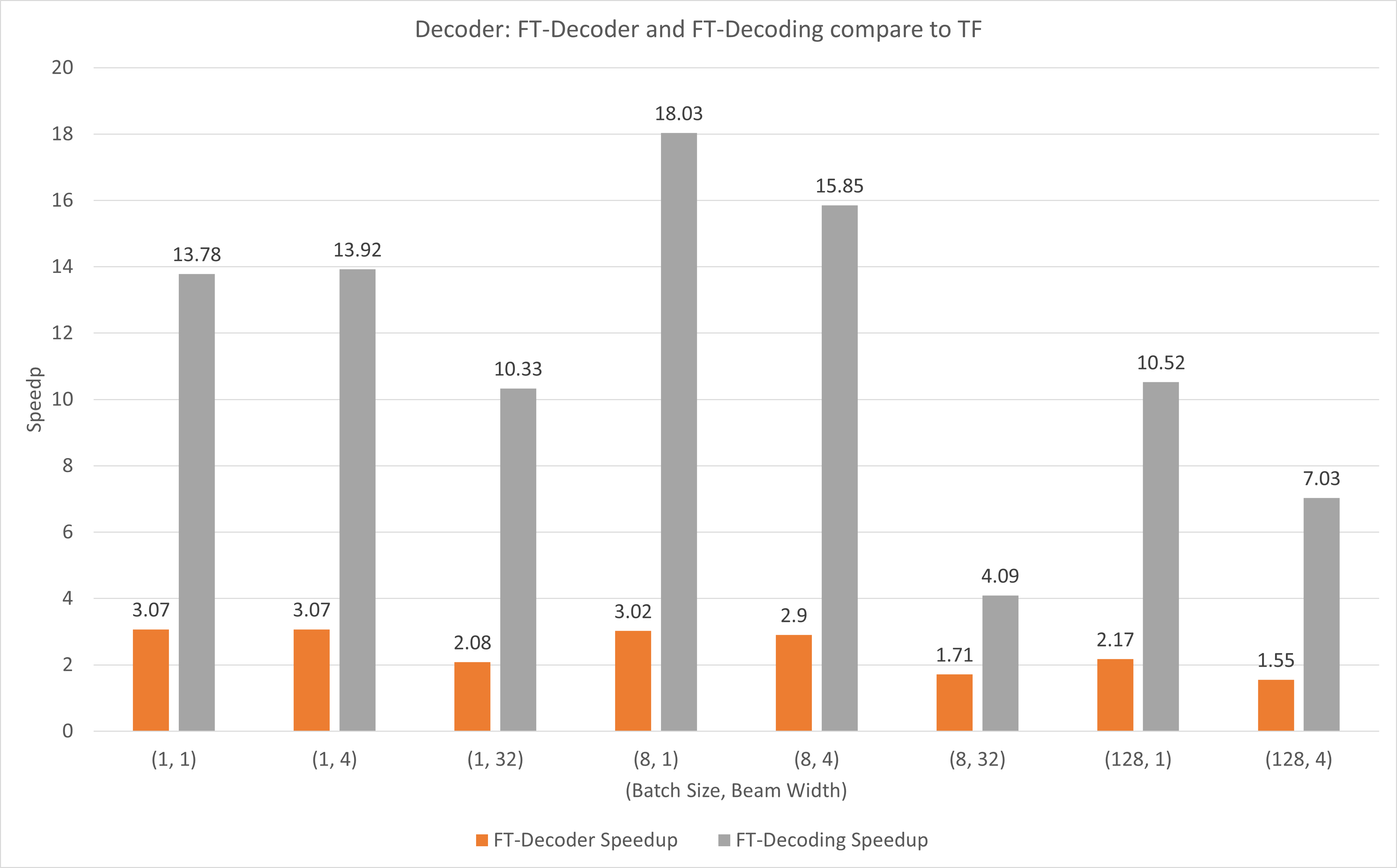
The following figure shows the speedup of of FT-Decoder op and FT-Decoding op compared to TensorFlow under FP16 with T4. Here, we use the throughput of translating a test set to prevent the total tokens of each methods may be different. Compared to TensorFlow, FT-Decoder provides 1.5x ~ 3x speedup; while FT-Decoding provides 4x ~ 18x speedup.
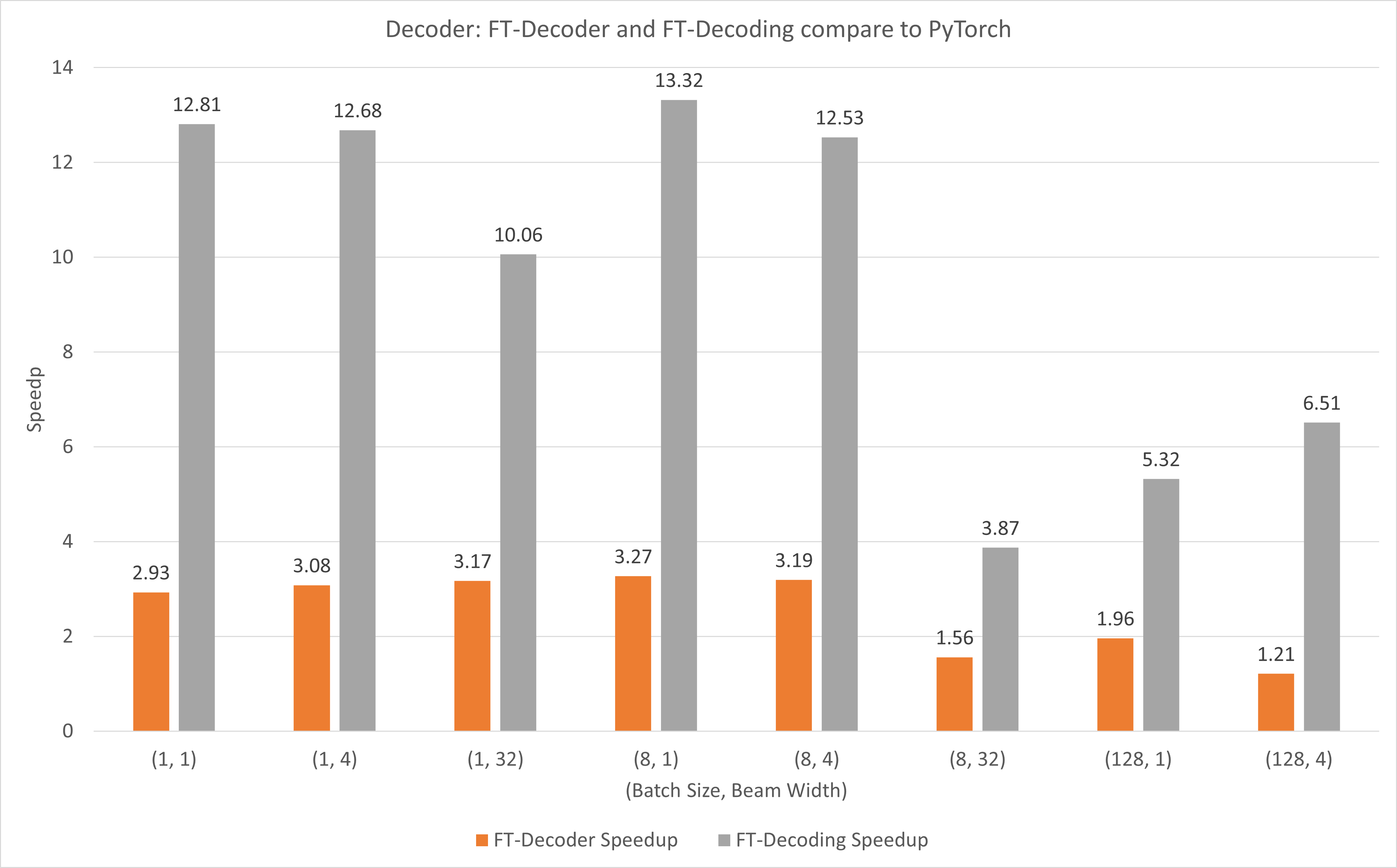
The following figure shows the speedup of of FT-Decoder op and FT-Decoding op compared to PyTorch under FP16 with T4. Here, we use the throughput of translating a test set to prevent the total tokens of each methods may be different. Compared to PyTorch, FT-Decoder provides 1.2x ~ 3x speedup; while FT-Decoding provides 3.8x ~ 13x speedup.
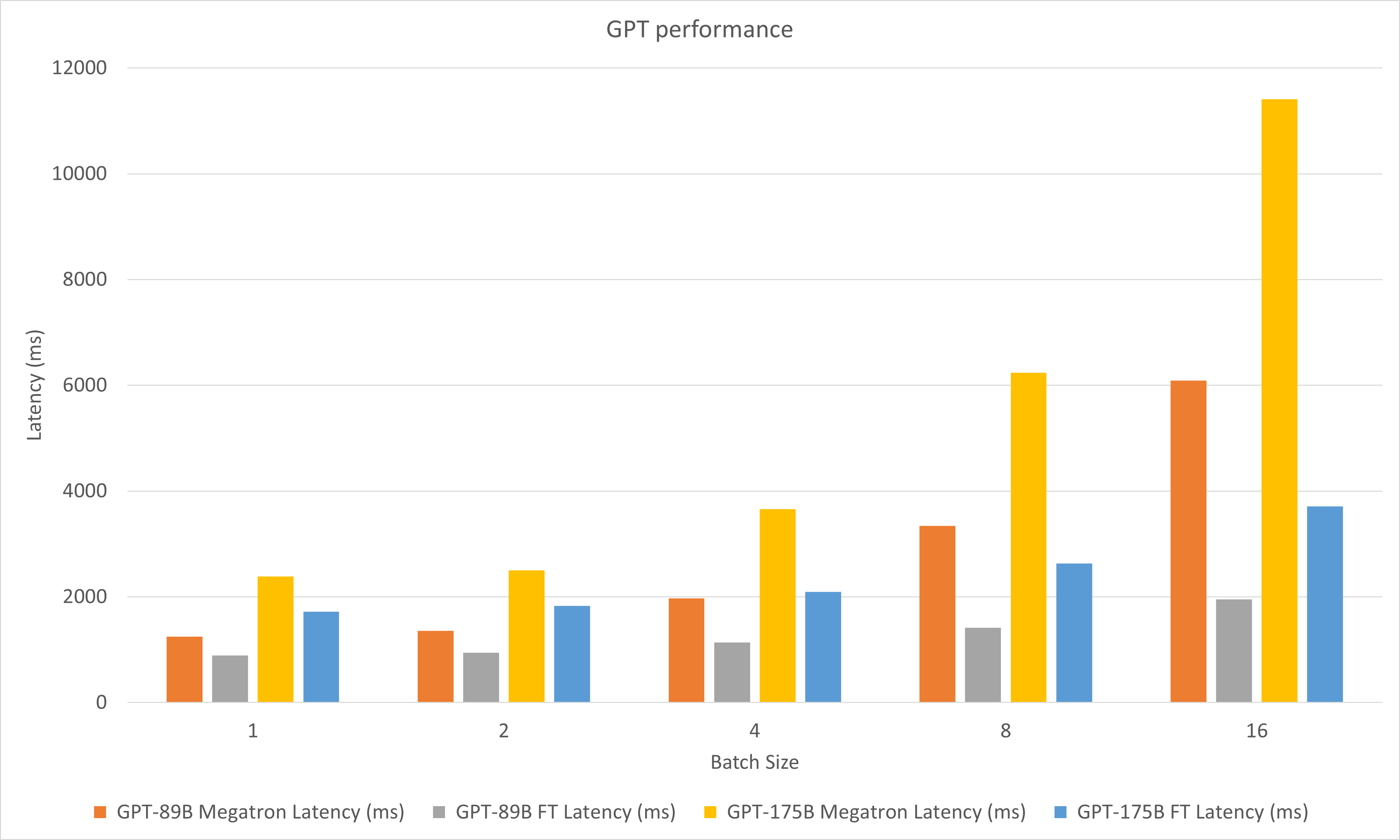
The following figure compares the performances of Megatron and FasterTransformer under FP16 on A100.
In the experiments of decoding, we updated the following parameters:
May 2023
January 2023
Dec 2022
Nov 2022
Oct 2022
Sep 2022
Aug 2022
July 2022
June 2022
May 2022
April 2022
March 2022
stop_ids and ban_bad_ids in GPT-J.start_id and end_id in GPT-J, GPT, T5 and Decoding.February 2022
December 2021
November 2021
August 2021
layer_para to pipeline_para.size_per_head 96, 160, 192, 224, 256 for GPT model.June 2021
April 2021
Dec 2020
Nov 2020
Sep 2020
Aug 2020
June 2020
May 2020
translate_sample.py.April 2020
decoding_opennmt.h to decoding_beamsearch.h
decoding_sampling.h
bert_transformer_op.h, bert_transformer_op.cu.cc into bert_transformer_op.cc
decoder.h, decoder.cu.cc into decoder.cc
decoding_beamsearch.h, decoding_beamsearch.cu.cc into decoding_beamsearch.cc
bleu_score.py into utils. Note that the BLEU score requires python3.March 2020
translate_sample.py to demonstrate how to translate a sentence by restoring the pretrained model of OpenNMT-tf.February 2020
July 2019
import torch first. If this has been done, it is due to the incompatible C++ ABI. You may need to check the PyTorch used during compilation and execution are the same, or you need to check how your PyTorch is compiled, or the version of your GCC, etc.

