mengzi retrieval lm
1.0.0
At Langboat Technology, we focus on enhancing pre-trained models to make them lighter to satisfy real industry needs. A retrieval-based approach(like RETRO, REALM, and RAG) is crucial to achieving this goal.
This repository is an experimental implementation of the retrieval-enhanced language model. Currently, it only supports retrieval fitting on GPT-Neo.
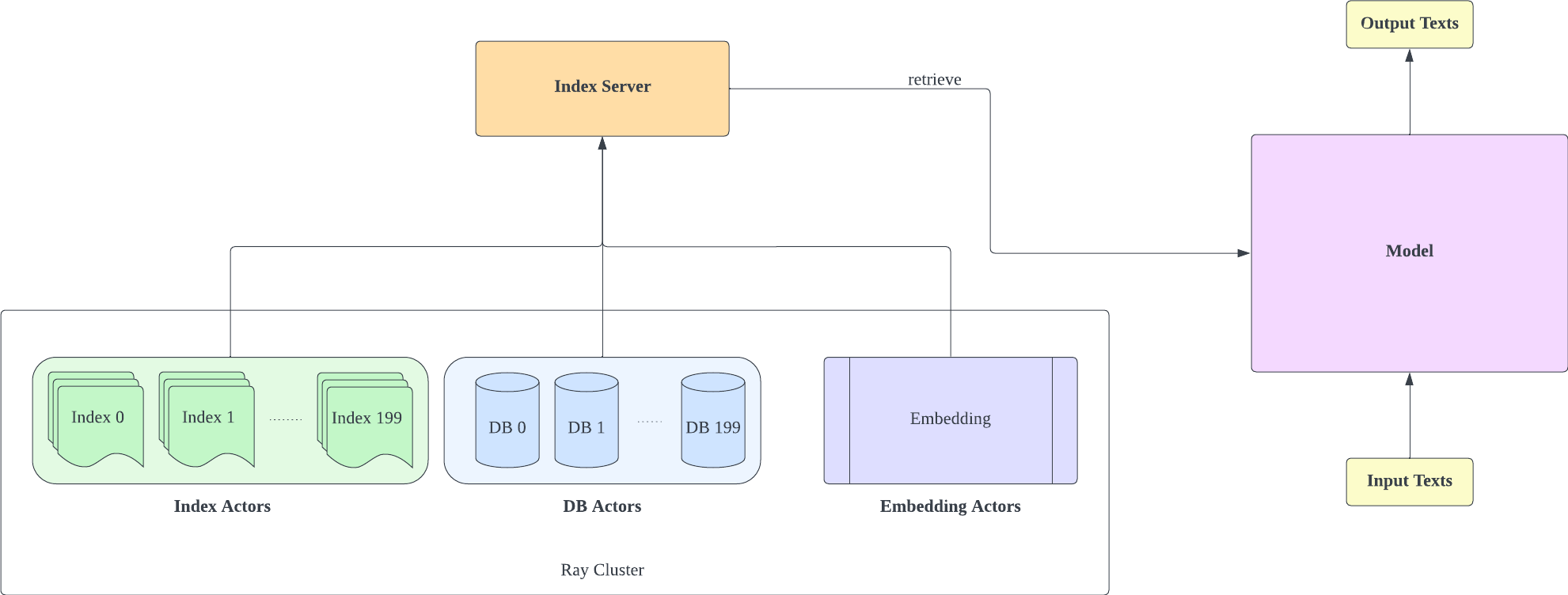
We forked Huggingface Transformers and lm-evaluation-harness to add retrieval support. The indexing part is implemented as an HTTP server to better decouple retrieval and training.
Most of the model implementation is copied from
RETRO-pytorch and GPT-Neo. We use transformers-cli to add a new model named Re_gptForCausalLM based on GPT-Neo, and then add retrieval part to it.
We uploaded the model fitted on EleutherAI/gpt-neo-125M using the 200G retrieval library.
You can initialize a model like this:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM.from_pretrained('Langboat/ReGPT-125M-200G')And evaluate the model like this:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1We compute similarity using sentence_transformers's embedding as text representation. You can initialize a Sentence-BERT model like this:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L12-v2')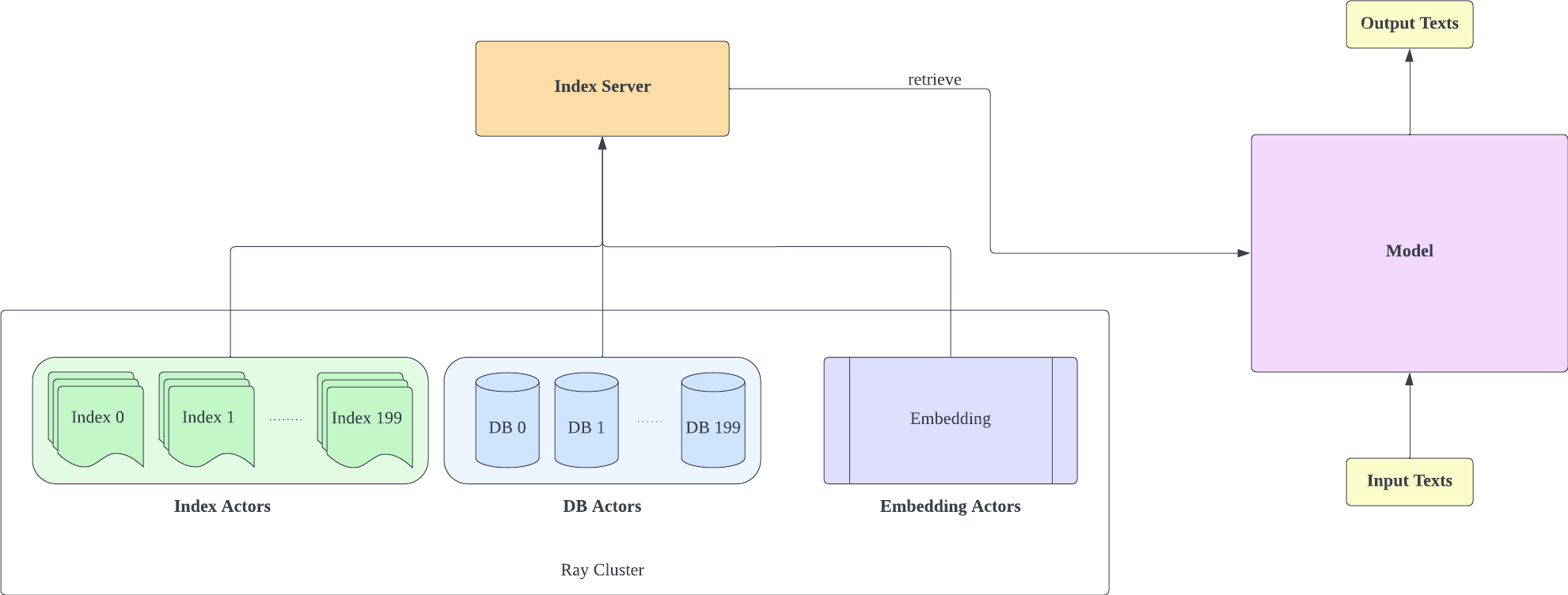
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c "from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2')"Using IVF1024PQ48 as the faiss index factory, we uploaded the index and database to the huggingface model hub, which can be downloaded using the following command.
In download_index_db.py, you can specify the number of indexes and databases you want to download.
python -u download_index_db.py --num 200You can manually download the fitted model from here: https://huggingface.co/Langboat/ReGPT-125M-200G
The index server is based on FastAPI and Ray. With Ray's Actor, computationally intensive tasks are encapsulated asynchronously, allowing us to efficiently utilize CPU and GPU resources with just one FastAPI server instance. You can initialize an index server like this:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- Keep in mind that the config IVF1024PQ48.json shard count must match the number of downloaded indexes. You can view the currently downloaded index number under the db_path
- This config has been tested on the A100-40G, so if you have a different GPU, we recommend adjusting it to your hardware.
- After deploying the index server, you need to modify the request_server in lm-evaluation-harness/config.json and train/config.json .
- You can reduce the encoder_actor_count in config_IVF1024PQ48.json to reduce the required memory resources.
· db_path:the database's download location from huggingface. "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966" is an example.
This command will download the database and index data from huggingface.
Change the index folder in the configuration file (config IVF1024PQ48) to point to the index folder's path, and send the database folder's snapshots as the db path to the api.py script.
Stop the index server with the following command
ray stop
- Keep in mind that you need to keep the index server enabled during training, eval and inference
Use train/train.py to implement training; train/config.json can be modified to change the training parameters.
You can initialize training like this:
cd train
python -u train.py
- Since the index server needs to use memory resources, you better deploy the index server and model training on different GPUs
Utilize train/inference.py as an inference to determine the loss of a text and it's perplexity.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- The test_data.json and train_data.json in the data folder are currently supported file formats, you can modify your data to this format.
Use lm-evaluation-harness as evaluation method
We set the seq_len of the lm-evaluation-harness to 1025 as the initial setting for model comparison because the seq_len of our model training is 1025.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path:the fitting model path
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1The results of the evaluation are as follows
| model | wikitext word_perplexity |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| Langboat/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| Langboat/ReGPT-125M-400G | 14.1327 |
@software{mengzi-retrieval-lm-library,
title = {{Mengzi-Retrieval-LM}},
author = {Wang, Yulong and Bo, Lin},
url = {https://github.com/Langboat/mengzi-retrieval-lm},
month = {9},
year = {2022},
version = {0.0.1},
}