SimplyRetrieve
Dependencies Update
?News: Aug 21, 2023 -- Users can now create and append knowledge on-the-fly through the newly added Knowledge Tab in the GUI. Also, progress bars added in Config & Knowledge Tabs.
SimplyRetrieve is an open-source tool with the goal of providing a fully localized, lightweight and user-friendly GUI and API platform for Retrieval-Centric Generation (RCG) approach to the machine learning community.
Create chat tool with your documents and language models, highly customizable. Features are:
A technical report about this tool is available at arXiv.
A short video about this tool is available at YouTube.
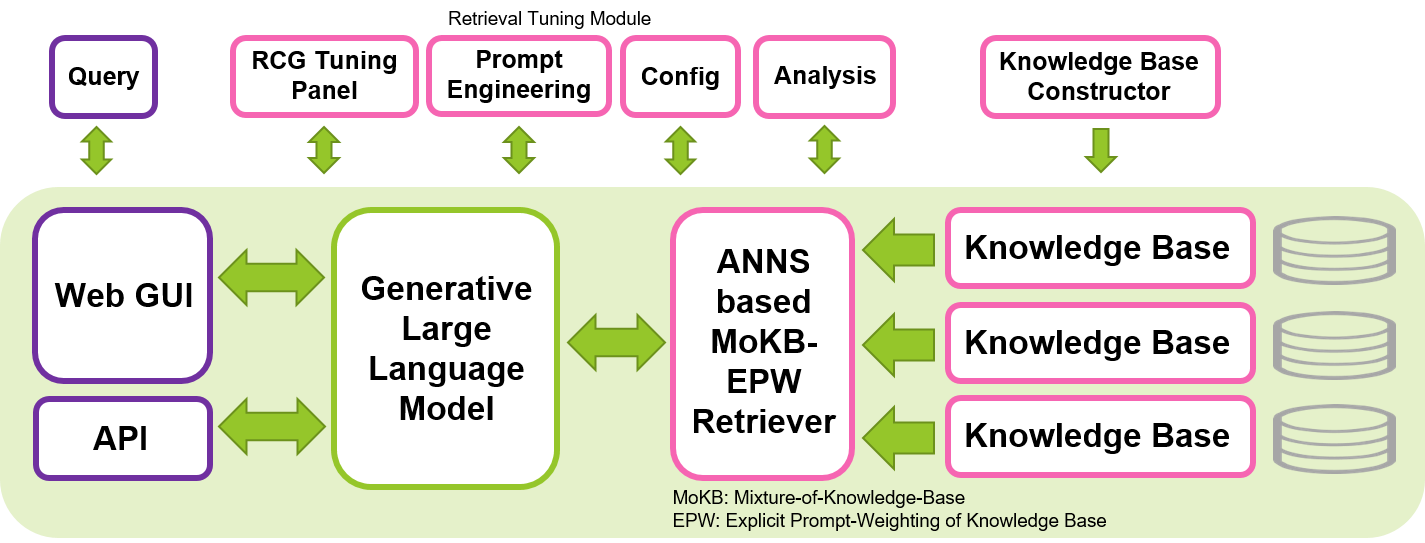
We aim to contribute to the development of safe, interpretable, and responsible LLMs by sharing our open-source tool for implementing RCG approach. We hope this tool enables machine learning community to explore the use of LLMs in a more efficient way, while maintaining privacy and local implementation. Retrieval-Centric Generation, which builds upon the Retrieval-Augmented Generation (RAG) concept by emphasizing the crucial role of the LLMs in context interpretation and entrusting knowledge memorization to the retriever component, has the potential to produce more efficient and interpretable generation, and reduce the scale of LLMs required for generative tasks. This tool can be run on a single Nvidia GPU, such as the T4, V100 or A100, making it accessible to a wide range of users.
This tool is constructed based mainly on the awesome and familiar libraries of Hugging Face, Gradio, PyTorch and Faiss. The default LLM configured in this tool is the instruction-fine-tuned Wizard-Vicuna-13B-Uncensored. The default embedding model for retriever is multilingual-e5-base. We found these models work well in this system, as well as many other various sizes of open-source LLMs and retrievers available in Hugging Face. This tool can be run in other languages as well apart from English, by selecting appropriate LLMs and customizing prompt templates according to the target language.
pip install -r requirements.txtchat/data/ directory and run the data preparation script (cd chat/ then the following command)
CUDA_VISIBLE_DEVICES=0 python prepare.py --input data/ --output knowledge/ --config configs/default_release.json
pdf, txt, doc, docx, ppt, pptx, html, md, csv, and can be easily expanded by editing configuration file. Follow the tips on this issue if NLTK related error occurred.Knowledge Tab of the GUI tool. Users can now add knowledge on-the-fly. Running the above prepare.py script prior to running the tool is not a necessity.After setting up the prerequisites above, set the current path to chat directory (cd chat/), execute the command below. Then grab a coffee! as it will just take a few minutes to load.
CUDA_VISIBLE_DEVICES=0 python chat.py --config configs/default_release.json
Then, access the web-based GUI from your favorite browser by navigating to http://<LOCAL_SERVER_IP>:7860. Replace <LOCAL_SERVER_IP> with the IP address of your GPU server. And this is it, you are ready to go!
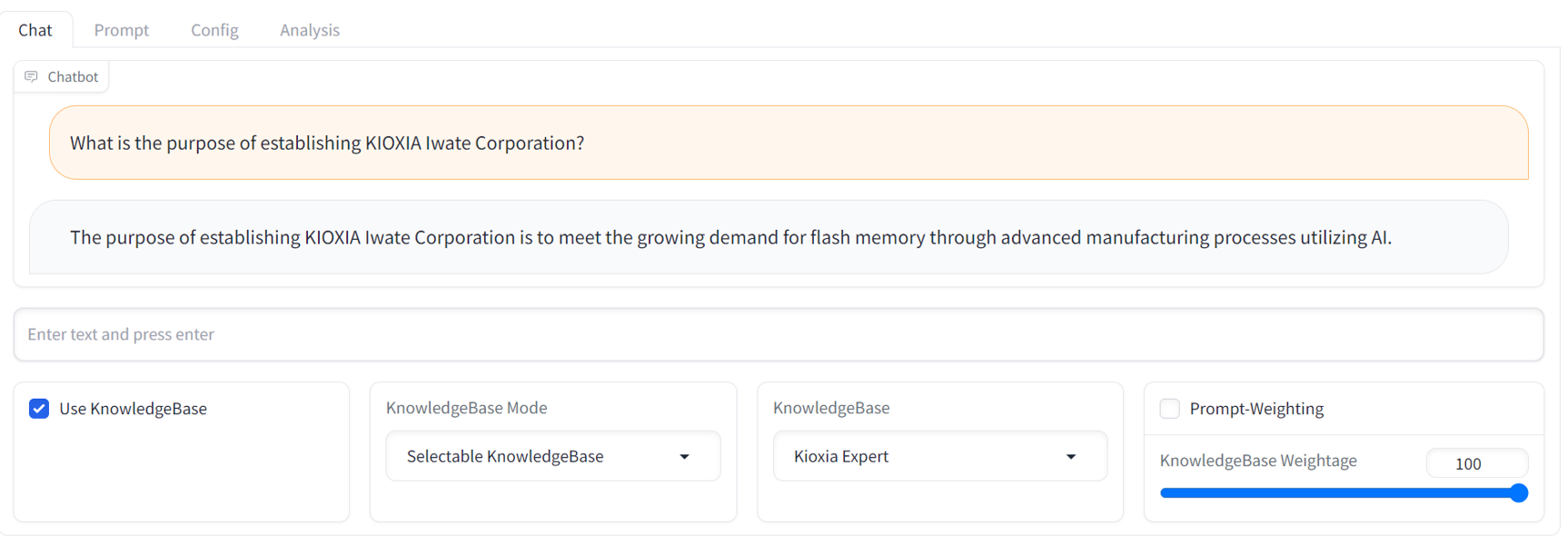
GUI operation manual, please refer to the GUI readme located in the docs/ directory.API access manual, please refer to the API readme and sample scripts located in the examples/ directory.Below is a sample chat screenshot of the GUI. It provides a familiar streaming chatbot interface with a comprehensive RCG tuning panel.
Not having a local GPU server to run this tool at this moment? No problem. Visit this Repository. It shows the instruction to try out this tool in AWS EC2 cloud platform.
Feel free to give us any feedback and comment. We very welcome any discussion and contribution about this tool, including new features, improvements and better documentations. Feel free to open an issue or discussion. We don't have any template for issue or discussion yet so anything will do for now.
Future Developments
It is important to note that this tool does not provide a foolproof solution for ensuring a completely safe and responsible response from generative AI models, even within a retrieval-centric approach. The development of safer, interpretable, and responsible AI systems remains an active area of research and ongoing effort.
Generated texts from this tool may exhibit variations, even when only slightly modifying prompts or queries, due to the next token prediction behavior of current-generation LLMs. This means users may need to carefully fine-tune both the prompts and queries to obtain optimal responses.
If you find our work useful, please cite us as follow:
@article{ng2023simplyretrieve,
title={SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool},
author={Youyang Ng and Daisuke Miyashita and Yasuto Hoshi and Yasuhiro Morioka and Osamu Torii and Tomoya Kodama and Jun Deguchi},
year={2023},
eprint={2308.03983},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint arXiv:2308.03983}
}
?️ Affiliation: Institute of Memory Technology R&D, Kioxia Corporation, Japan


