BentoML
v1.3.14

? Build model inference APIs and multi-model serving systems with any open-source or custom AI models. Join our Slack community!

BentoML is a Python library for building online serving systems optimized for AI apps and model inference.
Install BentoML:
# Requires Python≥3.9
pip install -U bentoml
Define APIs in a service.py file.
from __future__ import annotations
import bentoml
@bentoml.service(
resources={"cpu": "4"}
)
class Summarization:
def __init__(self) -> None:
import torch
from transformers import pipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
self.pipeline = pipeline('summarization', device=device)
@bentoml.api(batchable=True)
def summarize(self, texts: list[str]) -> list[str]:
results = self.pipeline(texts)
return [item['summary_text'] for item in results]Run the service code locally (serving at http://localhost:3000 by default):
pip install torch transformers # additional dependencies for local run
bentoml serve service.py:SummarizationNow you can run inference from your browser at http://localhost:3000 or with a Python script:
import bentoml
with bentoml.SyncHTTPClient('http://localhost:3000') as client:
summarized_text: str = client.summarize([bentoml.__doc__])[0]
print(f"Result: {summarized_text}")To deploy your BentoML Service code, first create a bentofile.yaml file to define its dependencies and environments. Find the full list of bentofile options here.
service: 'service:Summarization' # Entry service import path
include:
- '*.py' # Include all .py files in current directory
python:
packages: # Python dependencies to include
- torch
- transformers
docker:
python_version: "3.11"Then, choose one of the following ways for deployment:
Run bentoml build to package necessary code, models, dependency configs into a Bento - the standardized deployable artifact in BentoML:
bentoml buildEnsure Docker is running. Generate a Docker container image for deployment:
bentoml containerize summarization:latestRun the generated image:
docker run --rm -p 3000:3000 summarization:latestBentoCloud provides compute infrastructure for rapid and reliable GenAI adoption. It helps speed up your BentoML development process leveraging cloud compute resources, and simplify how you deploy, scale and operate BentoML in production.
Sign up for BentoCloud for personal access; for enterprise use cases, contact our team.
# After signup, run the following command to create an API token:
bentoml cloud login
# Deploy from current directory:
bentoml deploy .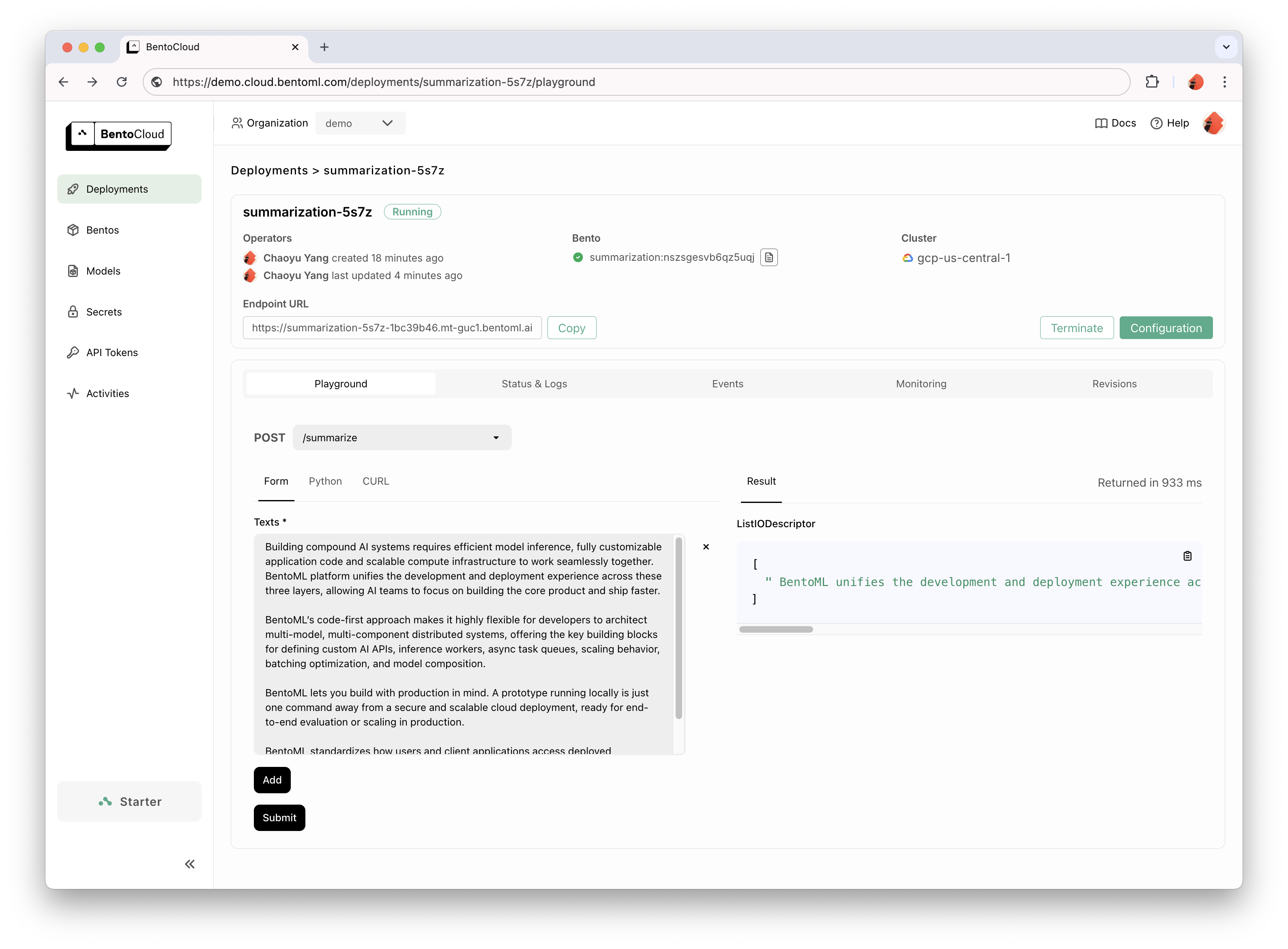
For detailed explanations, read the Hello World example.
Check out the full list for more sample code and usage.
See Documentation for more tutorials and guides.
Get involved and join our Community Slack , where thousands of AI/ML engineers help each other, contribute to the project, and talk about building AI products.
To report a bug or suggest a feature request, use GitHub Issues.
There are many ways to contribute to the project:
#bentoml-contributors channel here.Thanks to all of our amazing contributors!
The BentoML framework collects anonymous usage data that helps our community improve the product. Only BentoML's internal API calls are being reported. This excludes any sensitive information, such as user code, model data, model names, or stack traces. Here's the code used for usage tracking. You can opt-out of usage tracking by the --do-not-track CLI option:
bentoml [command] --do-not-trackOr by setting the environment variable:
export BENTOML_DO_NOT_TRACK=TrueApache License 2.0