gen ai document sumarization
1.0.0
This project explores the potential of open-source generative AI models, particularly those based on the Transformer architecture, for automating the summarization of document content. The goal is to evaluate and apply existing generative AI models to analyze, understand context, and generate summaries for unstructured documents.
To achieve this, I have fine-tuned two prominent models: t5-small and facebook/bart-base, focusing on enhancing their summarization performance.
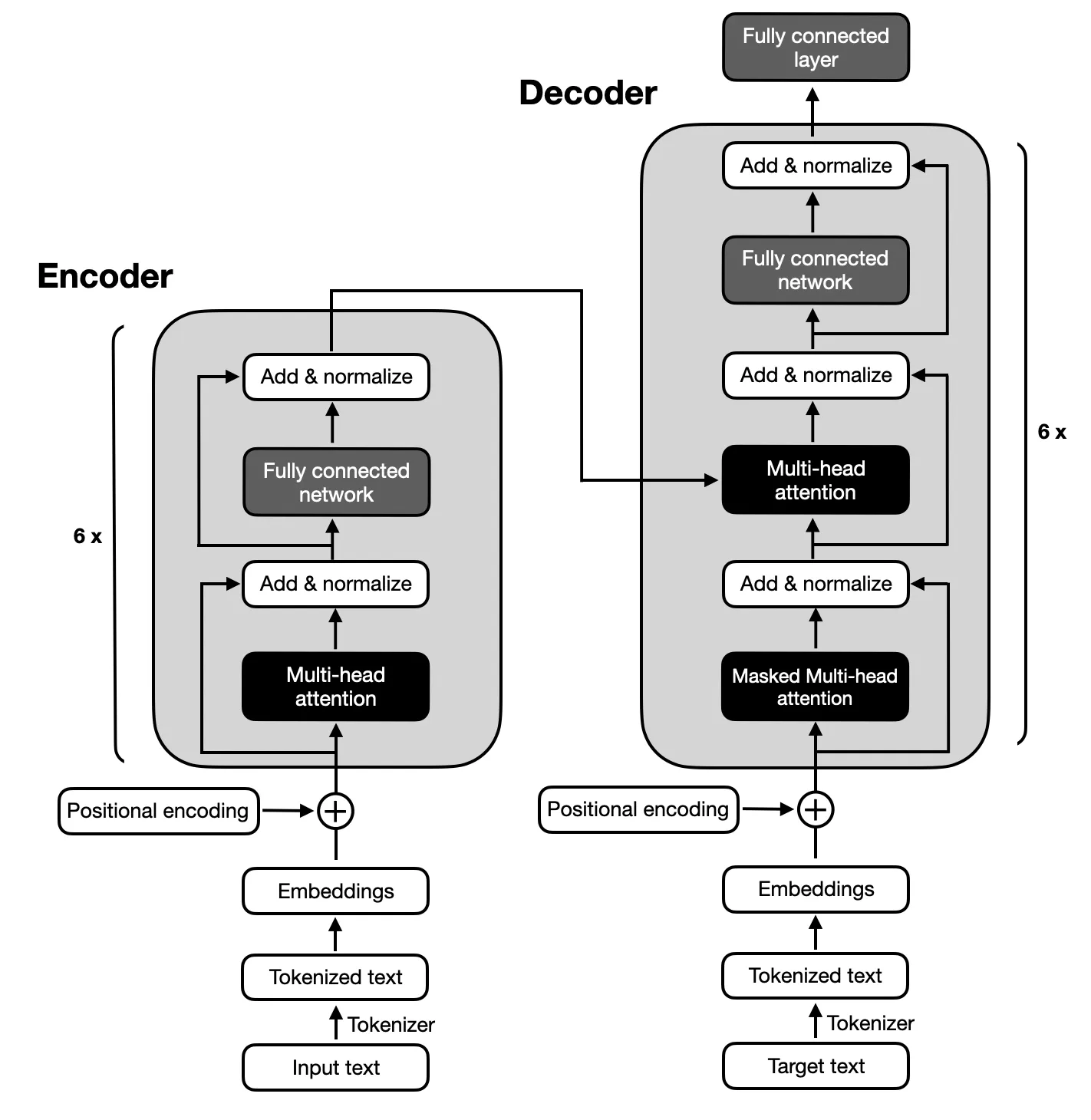
The focus is on encoder-decoder models following the architecture proposed by the original Transformers due to the complex mapping between input and output sequences required for text summarization. Encoder-decoder models are adept at capturing relationships within these sequences, making them suitable for this task.
Ensure Python 3.x is installed on your system. Then, follow the steps below to set up your environment:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyThe project comprises six main phases:
The dataset used for fine-tuning the T5 and BART models was the Big Patent Dataset, which is composed of 1.3 million U.S. patent documents along with their human-written abstractive summaries. Each document in this dataset is categorized under a Cooperative Patent Classification (CPC) code, covering a broad range of topics from human necessities to physics and electricity. This diversity ensures that the models encounter a wide variety of language use and technical jargon, which is crucial for developing a robust summarization capability.
The Big Patent Dataset was chosen due to its relevance to the project's goal of summarizing complex documents. Patents are inherently detailed and technical, making them an ideal challenge for testing the models' ability to condense information while preserving the core content and context. The dataset's structured format and the presence of high-quality summaries provide a strong foundation for training and evaluating the models' performance in generating accurate and coherent summaries.
The performance of the models was evaluated using the ROUGE metric, emphasizing their ability to generate summaries closely aligned with human-written abstracts. Both BART and T5 models were fine-tuned using the Big Patent Dataset, focusing on achieving high-quality abstract summarization.
| Metric | Value |
|---|---|
| Evaluation Loss (Eval Loss) | 1.9244 |
| Rouge-1 | 0.5007 |
| Rouge-2 | 0.2704 |
| Rouge-L | 0.3627 |
| Rouge-Lsum | 0.3636 |
| Average Generation Length (Gen Len) | 122.1489 |
| Runtime (seconds) | 1459.3826 |
| Samples per Second | 1.312 |
| Steps per Second | 0.164 |
| Metric | Value |
|---|---|
| Evaluation Loss (Eval Loss) | 1.9984 |
| Rouge-1 | 0.503 |
| Rouge-2 | 0.286 |
| Rouge-L | 0.3813 |
| Rouge-Lsum | 0.3813 |
| Average Generation Length (Gen Len) | 151.918 |
| Runtime (seconds) | 714.4344 |
| Samples per Second | 2.679 |
| Steps per Second | 0.336 |


