Adding Private Data to LLMs
1.0.0
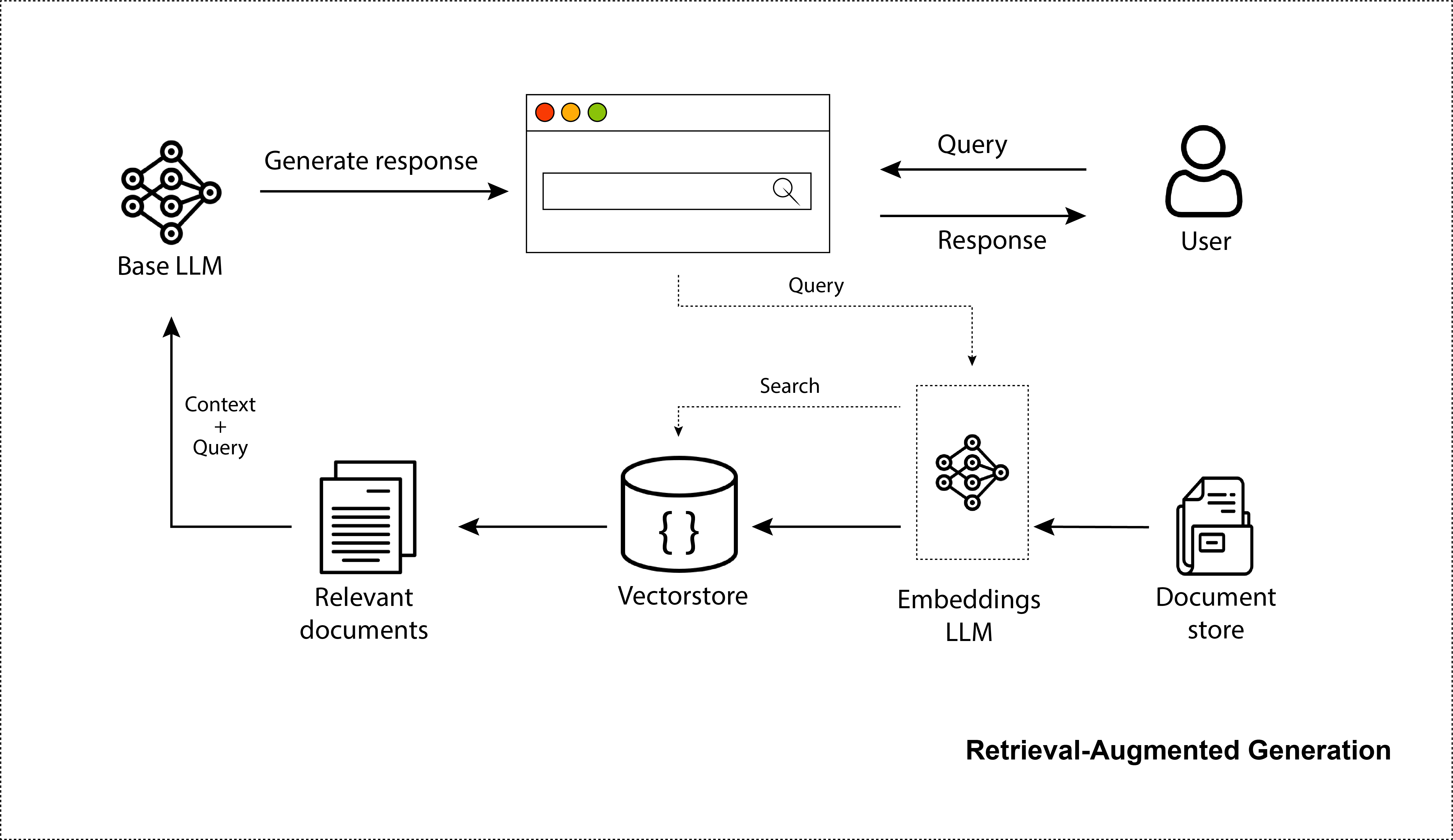
LLMs have stunned the world with their capacity to create realistic images, code, and dialogue. Undoubtedly, ChatGPT has taken the world by storm. Millions are using it. But while it's great for general-purpose knowledge, it only knows information it was trained on, which is pre-2021 generally available internet data. It lacks awareness of your private data and remains uninformed about recent data sources. Thus, to improve them in that regard, we can provide them with information that we retrieved from a search step. This makes them more factual and gives a better ability to provide the model with up-to-date information, without the need to retrain these massive models. This is precisely what a retrieval-augmented LLM or Retrieval-Augmented Generation (RAG) system is. Indeed, this repository will precisely outline the creation of an RAG system and elucidate the optimization steps involved.
RAG
Tech Stack
Installation
Useful Links
Contact
LangChain
LlamaIndex
Azure OpenAI
Gradio
Clone the Github repository
git clone https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
Requirements Cd to the project directory and ensure that you have Python 3 installed, along with the necessary dependencies.
cd Adding-Private-Data-to-LLMs pip install -r requirements.txt
Run the Gradio app
python rag.py
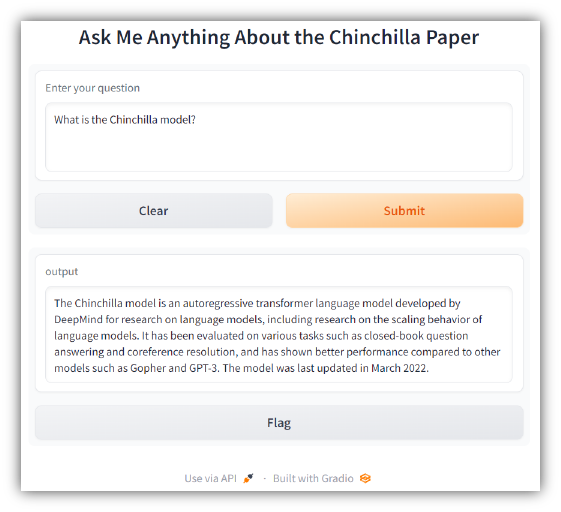
Visit http://127.0.0.1:7860 on your machine to test the app. You should see something like the following:
| Blog | Plateform | Language | Notebook |
|---|---|---|---|
| Ask Your Own Data | Hiberus Blog | ES | |
| Ask Your Own Data | Medium | EN | |
| Ask Your Web Pages | Hiberus Blog | ES | |
| Ask Your Web Pages | Medium | EN |
If you like it, give it a , then follow me on:
LinkedIn: Nour Eddine ZEKAOUI
Twitter: @NZekaoui
Back To The Top


