ssebowa
1.0.0
Ssebowa is an open source Python library that provides generative AI models, including:
ssebowa-llm: A large language model (LLM) for text generation,ssebowa-vllm: A visual language model (VLLM) for visual understanding,ssebowa-imagen: An image generation and customized fine tuning model,Ssebowa-vigen: A video generation model.With Ssebowa, you can easily generate text, translate languages, write different kinds of creative content, personalized image generation and answer your questions in an informative way.
For more detailed usage information, please refer to: Ssebowa's technical documentation
Before running the script, ensure that the required libraries are installed. You can do this by executing the following commands:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .Then install Ssebowa
pip install ssebowaIf you are running this commands in colab or jupyter notebook please use this,
!git clone https://github.com/huggingface/diffusers
!cd diffusers
!pip install .
!pip install ssebowaNow, you can access the different models by importing them from the library:
Ssebowa-Imagen is an open-source image synthesis model that utilizes a combination of diffusion modeling and generative adversarial networks (GANs) to generate high-quality images from text descriptions and allows also to turn your few photos into custom model that is capable of generating stunning images of your chosen subject. It leverages a 100 billion dataset of images and text descriptions, enabling it to accurately capture the nuances of real-world imagery and effectively translate text descriptions into compelling visual representations.
10-20 high-quality solo photos (jpg or png) like yours, friend, product or pets etc and put them in a specific directory.16GB or more. (If you're fine-tuning SDXL, you'll need 24GB of VRAM.)from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = "data" # The directory where you put your prepared photos
OUTPUT_DIR = "models" dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = "<YOUR-NAME>"
CLASS_NAME = "person"model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen()Like lets generate "A cat sitting on a bookshelf"
image = model.generate_image("A cat sitting on a bookshelf")image.save("cat_on_bookshelf.jpg")

Ssebowa-vllm is an open-source visual large language model (VLLM) developed by Ssebowa AI. It is a powerful tool that can be used to understand images. Ssebowa-vllm has 11 billion visual parameters and 7 billion language parameters, supporting image understanding at a resolution of 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm()
response = model.understand(image_path, prompt)
print(response)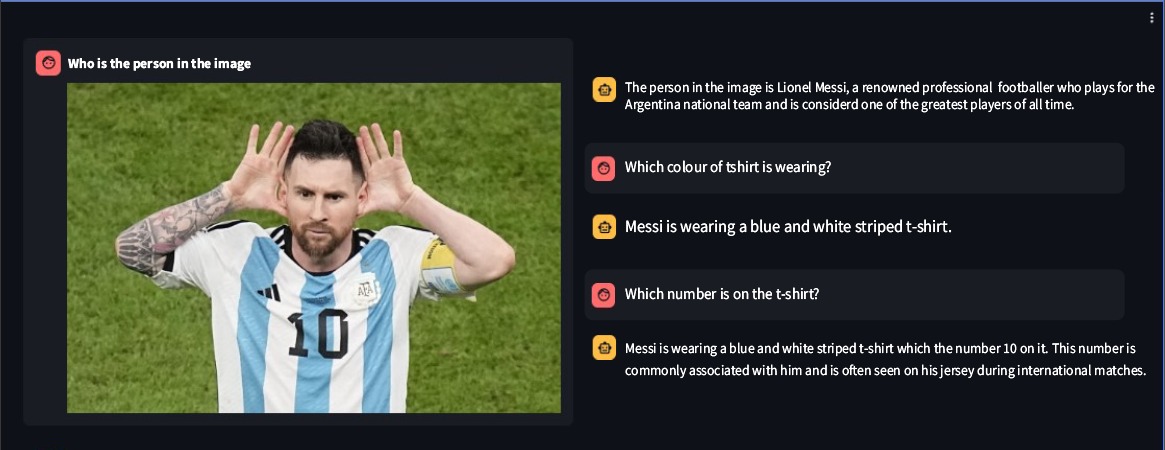
Ssebowa is open to contributions! Guidelines in progress..
Ssebowa is released under Apache License 2.0.
If you have any questions or suggestions, please feel free to open an issue on GitHub or contact us at [email protected]


